中小企业财务预警与信用评分研究
2021-11-09张钰
张钰


摘 要:根据中小板市场998家企业的财务指标数据构建财务预警与信用评分指标体系,运用相关性与机器学习决策树对指标进行二次筛选,并通过逻辑回归计算各样本的信用分值,再根据模型评估和实证结果可以推知:逻辑模型对中小企业具有较好的财务预警能力,能够准确衡量企业信用风险水平。同时可发现,存货周转率等12个财务指标是衡量中小企业信用风险的重要指标。
关键词:信用评分;中小企业;逻辑回归;财务预警
中图分类号:F276.3 文獻标志码:A 文章编号:1673-291X(2021)30-0063-03
引言
随着我国从经济体量到经济发展质量的转变,中小企业成为我国经济发展的重要推动力量,在我国的经济发展中,逐渐出现了企业体系中资金配置的两极分化,这是我国异于他国的金融体系框架所导致的。但从根本上来说,中小企业发展最主要的问题是其自身财务状况导致的融资难问题,中小企业的资金规模、技术、产品、服务都严重制约了其发展,且自有资金相对匮乏。此外,易受到外界多种因素的影响,在内部管理、决策水平、风险控制等方面的能力也较为薄弱,管理的风险也相对较高,从而使得中小企业发展受到各个方面的制约,导致其经营风险、管理风险、信用风险不断加大。
在我国经济发展改革和经济体系转变的过程中,中小企业要想扮演好自身的角色,要想有效地提高自身的经营能力和财务能力,要想有效地从根本上或者是一定程度地解决中小企业的融资问题,最重要的是解决企业信用风险量化问题和建立良好的财务预警体系,从根本上解决金融机构和市场主体对中小企业投资信心的问题。为较好地解决市场外部环境和中小企业与银行之间的信息不对称的问题,本文旨在建立一套健全的财务指标体系,较为准确地衡量中小企业的信用风险,并形成评分卡。
一、文献综述
在对于中小企业信用指标体系的研究中,我国许多学者都致力于寻找最合理的方法来衡量企业风险。如于善丽和迟国泰(2017)通过Fisherscore值建立了服务业小企业债信评价体系,并对1 077家企业的数据进行实证分析;孟斌等(2019)根据组合系数构建建筑企业信用评价模型,研究表明,与单一赋权结果相比,组合赋权模型特异度和灵敏度更高;迟国泰等(2019)利用1 814家工业企业的贷款数据实证分析了其所建立的小型工业企业债信评级模型,结果表明,该指标体系能够显著区分该类企业的违约状态;张传新和王光伟(2012)运用Logit模型实证分析基于主成分的信用风险体系的有效性;郭林(2020)用两阶段逻辑回归构建了敏感性更强、判别力更大的信用评价指标体系,并使用3 111个小企业的信贷数据实证分析了其指标体系的有效性等。
为建立较为准确的指标体系,本文基于企业财务指标,构建指标体系,运用随机森林和决策树筛选指标变量,并建立逻辑回归判别指标模型,最后得出信用分值。
二、指标变量选择和数据处理
(一)特征变量选择和数据预处理
本文选择了六大类共19个财务指标,具体包括营运能力指标、偿债能力指标、盈利能力指标、财务杠杆指标、流动性指标以及发展能力指标。这六大类指标都是与企业信用风险的高低有着较高的相关性的。本文数据来源于同花顺网站中小板市场中988家公司的财务指标数据,其中ST企业违约风险为1,非ST违约风险为0。而后对数据样本进行了描述性统计和初步的处理。
(二)缺失值与异常值处理
从下页表1可知,样本数据缺失严重,且样本量为988个,所以本文采用众数、均值、随机森林模型来填补样本缺失值,对于较为重要的特征变量,可根据样本其他特征变量,用随机森林模型预测缺失特征的值来补充样本。此外,通过箱线图寻找异常值并剔除,所得样本数为491个。
三、特征变量筛选
(一)相关性检验
根据数据的初步处理,得到491个样本,19个特征变量,由于本文所采用的数据为财务指标数据,数据指标中可能存在多重共线性,所以本文可根据变量之间的相关系数,初步剔除相关性较强的指标,将相关系数大于0.5的指标进行剔除,共删除流动资产周转率、速动比率、权益负债比、净资产收益率、成本费用利润率等5个指标。
(二)决策树深度筛选特征变量
决策树是一个通过树状结构模拟人进行决策的过程的方法,根节点后的每个分枝代表一个新的决策事件,而每个叶子代表一个最终判定所属的类别。而决策事件的多少即为深度,不同的深度确定不同特征的重要性,本文基于改变决策树深度(max_depth=3-20)以确定特征变量对信用违约的贡献程度,从而得出存货周转率、资产现金率、流动比率等12个特征。
四、逻辑回归模型与评估
(一)特征变量分箱,计算WOE
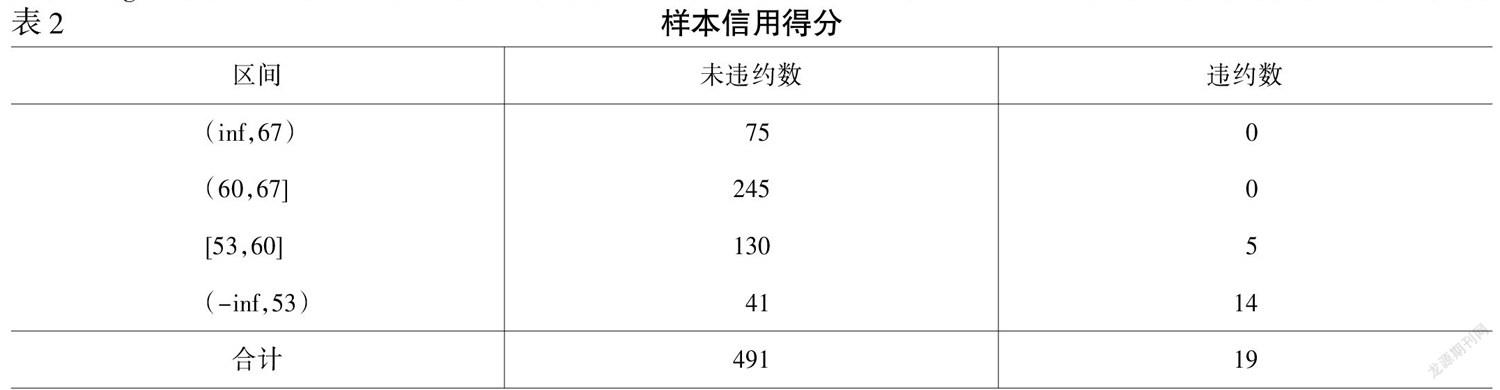
要得出企业的信用分值,首先要知道每一特征在不同区间上所对应的分值,即分箱,根据特征变量的取值,将不同样本分成不同的区间。本文为简化算法,特将每一个特征变量等距分成5个区间,即5个箱子,且区间长度相同,并将区间扩展到正无穷和负无穷。此外,为计算各箱的WOE值,必须保证每个箱中标签均包含0和1,将无0和1的箱子与上一箱子合并,直到箱子中均含0和1为止。在每一个特征分箱后的每一个箱,将WOE计算完毕后,将其映射到数据样本中,进行模型判别。
(二)逻辑回归函数
将上述样本数带入逻辑回归函数,回归结果显示,截距-3.12895206,特征变量系数为-0.290402、-0.5816、0.19818等12个系数。
(三)模型评估
基于该模型为机器学习所训练的模型,应检验其模型的好坏。准确度等于预测值与真实值相同的个数比上预测样本数,根据模型结果显出正确度为96.6%,从准确得分来说,该模型具有较好的预测能力,但是由于样本的不均衡,如果更想知道的是模型对于信用风险较大企业的预测能力,那么应该选择ROC曲线,其能较好地评估这一能力。ROC曲线是在不同命中和不同错误率下所绘制而成的。AUC指ROC曲线下方的面积,面积越大,模型效果越好。一般来说,AUC值大于0.75就意味着可以接受模型,大于0.85就表示模型效果好。图1中,AUC值为0.79,说明模型可以接受。
