基于双通道双向长短时记忆网络的铁路行车事故文本分类
2021-11-04王明明郑海青孙晓云
韩 广,卜 桐,王明明,郑海青,孙晓云,金 龙
(1.石家庄铁道大学 电气与电子工程学院,河北 石家庄 050000;2.国家铁路局 装备技术中心, 北京 100844)
铁路作为国家重要的基础设施和关键性民生工程,有力地促进了社会和经济的发展。为确保铁路运输安全,铁路行业积累了大量铁路行车安全主题的业务信息,这些信息数据多采用文本、语音、图像等非结构化数据储存[1]。其中,文本是铁路事故分类的主要手段,为后续进行适当的处理提供依据。但是,目前铁路事故主要由人工进行定级,受主观因素影响较大,其等级分类的准确性有待提高。
近年来,学者们针对铁路事故文本展开了分析和研究。杨兰[2]通过设计事故树对黑龙江“1.28”道口事故进行原因分析,提出了预防道口事故的措施;上官伟等[3]采用基于粒子群优化的支持向量机算法对列控车载设备的故障进行分类;钟志旺等[4]提出了基于主题模型和支持向量机的道岔设备故障特征提取与诊断方法。基于上述研究,铁路事故文本分类存在两个挑战亟待解决:①由于事故类型、描述人员的差异,使得文本的长度、叙述有较大的差异性;②铁路事故文本中含有大量专业词语,如轨道电路红光带、受电弓等,直接影响分词效率和分类准确率。
采用智能方法解决文本分类问题是目前的研究热点。Bengio等[5]创建了三层神经网络的机器学习模型,并率先应用到自然语言处理的任务中。循环型神经网络(Recurrent Neural Network,RNN)[6-7]越来越多地应用到文本分类中。其中,因为在缓解梯度爆炸问题上表现出色,长短时记忆(Long Short Term Memory,LSTM)网络在文本分类问题中得到了较为广泛的应用[8]。
针对文本问题的特征提取,目前最常见的方法是将词语转化为向量。Tai等[9]将LSTM模型应用于树状语句拓扑结构,提高了分类精度。杜修明等[10]分析了电网故障案例文本,使用双向LSTM(Bidirectional LSTM,BiLSTM)网络取得了良好的分类结果。研究表明,在词向量特征提取方法中采用多通道的形式,是提升文本特征提取效率的有效手段之一。康雁等[11]采用双通道词向量训练方式,实验结果表明双通道策略优于单通道策略。Du等[12]采用多通道KNN文本分类,保证了文本较高的准确性。
文本以词向量形式输入网络时的长度是固定的,而由于文本本身长短不一的特性,使得在处理长文本时,一部分词向量将被舍去;在处理短文本时,则需要扩充零向量,相当于添加了无用信息和网络负担。因此,对于长度差异性大的铁路行车事故文本,扩充和舍去词向量都会影响文本分类的准确性。句子同样可以作为一个整体进行特征提取,构成句向量。王亚珅等[13]提出概念化句嵌入模型,Guo等[14]基于词向量信息生成句向量,均在文本分类中取得了良好结果。李心蕾等[15]研究表明,针对新浪微博这一类短文本分类问题,句向量的特征提取效果要劣于词向量。而针对长文本问题,李云红等[16]使用单一句向量提取特征,取得良好结果。铁路事故文本具有叙述长短不一的特点,上述研究为本文结合词向量和句向量两种方法进行特征提取,提供了研究依据。
铁路事故文本分类中关键词对于等级的划分有重要影响,引入注意力机制,将有效提升文本识别效率。注意力机制是受到人类在观察和思考过程中目光随着感兴趣区域发生移动的思想启发,目前在三维动作识别[17]、家庭活动识别[18]、社区问答文本识别[19]、视频-脑电交互协同情感识别[20]、机器翻译[21]等领域得到广泛应用。相对于传统机器学习模型,注意力机制可改善计算量以及精度,因此在自然语言处理领域应用广泛。
综上,双向长短时记忆网络因其结构优势,可以兼顾前后两个方向的特征,适合于文本的上下文关系提取;词向量和句向量双通道可以有效解决文本长短不一、差异性大的问题,提高样本的利用程度和分类准确率。所以本文设计了双通道双向长短时记忆网络进行铁路行车事故文本分类。首先,针对铁路事故文本专有词汇,基于铁路专用设备产品数据库,构建“铁路行车事故词库”,提高分词和特征的提取效率。然后,针对铁路事故文本长短不一、文本长度差异性大的特点,设计同时使用词向量和句向量的双通道双向LSTM网络模型。
1 铁路行车事故词库的构建
1.1 铁路行车一般事故分类
从成都、广州等7个铁路局提供的文本信息,获取了铁路行车事故情况。从中可知,因违反规章制度、劳动纪律,技术设备不良及其他原因,在铁路行车中造成人员伤亡、设备损害、经济损失、影响正常行车或危及行车安全的,均构成铁路行车事故。本文针对日常发生较多的铁路行车一般事故类别展开研究。根据《铁路行车事故处理规则》[22],铁路行车中一般事故分类依据见表1。

表1 铁路行车中一般事故分类依据
1.2 铁路行车事故词库
在常规词库下,专有词“轨道电路红光带”会被分为“轨道电路红光带”,不仅造成专有词汇拆分,也增加了词向量维度;“×时×分销记”会被误分为“×时×分销记”,错误分词“分销记”与正确分词“分销记”所表达的意思完全不同。因此,要有效提升铁路专业词汇的分词准确性,有必要构建铁路行车事故词库。本文结合GB/T 8568—2013《铁路行车组织词汇》[23]和项目研究中收集到的文本,构建了“铁路行车事故词库”。
首先,考虑到文本中客运线名称和铁路工作机构均为固定名词,且存在广泛,设计了铁路客运线名词库和铁路用语词库,丰富常用词典。这两部分内容在词库中占有很大比例。其次,电气化铁路词库由供电段负责的电气化铁路牵引供电、铁路运输信号供电、电力设备等方面词语构成;铁路信号词库由电务段或工务段负责的信号设备、转辙机及道岔等词语构成。最后,建立铁路词汇词库,结合铁路行车事故文本发现的稀有专用词语,实现整体词库的补充。
“铁路行车事故词库”见表2,由电气化铁路词库、铁路信号词库、铁路客运线名词库、铁路用语词库、铁路词汇词库等二级词库组成,有效提高了铁路事故文本在中文分词阶段的准确性。

表2 铁路行车事故词库
两段典型事故词语标注见图1。

图1 两段典型事故词语标注
2 铁路事故文本分类模型
铁路行车事故文本分类总体模型见图2。
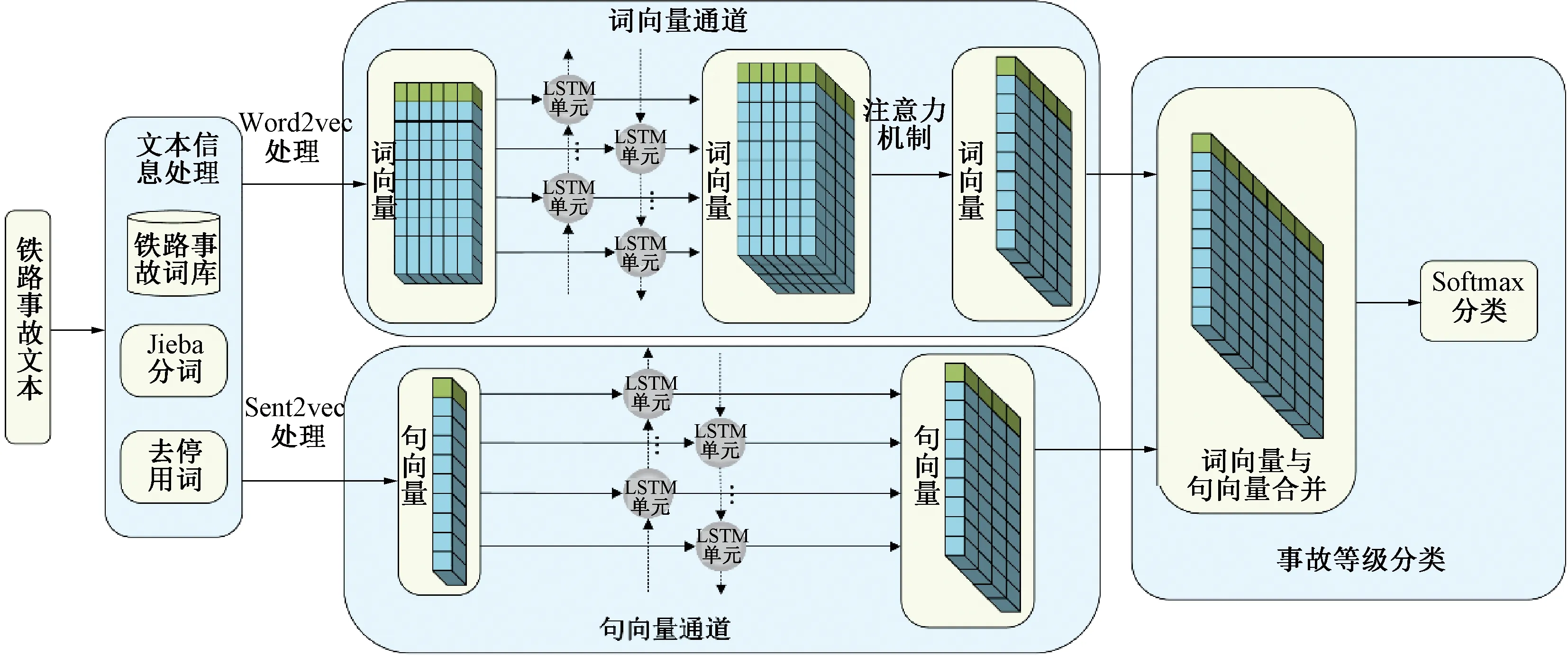
图2 铁路行车事故文本分类总体模型
2.1 文本预处理
由于中文文本没有间断,所以需要对文本进行分词处理。本文使用Jieba分词的精确模式,将句子依靠词典精确地切开,使用构建的“铁路行车事故词库”提高分词准确率;再使用停用词处理来降低维度和去噪;之后使用Google开源代码词语转向量(Word to Vector,Word2vec)和句子转向量(Sentence to Vector,Sent2vec)来获得文本的词向量表达和句向量表达。
2.2 文本词向量表示

2.3 文本句向量表示
句向量的两种训练方式是PV-DM (Distributed Memory model of Paragraph Vectors)和PV-DBOW (Distributed Bag of words of Paragraph Vector)。Sent2vec在句向量输入时增添了Paragraph vector,在文本滑动训练中Paragraph vector是共享的,因此,Paragraph vector所表达的句子思想会更加精确。
句向量模型不需要规定句子长度,能够解决词向量面临的长度选择问题。可是,单独使用句向量,其表示的信息会少于词向量,导致分类精度降低。因此,针对铁路事故文本长短差异性大的问题,本文将采用词向量和句向量相结合的方法。
2.4 双向长短时记忆网络
LSTM是一种特殊的RNN结构,包括门控单元和细胞储存单元,用来控制数据传播。其中门控单元由输入门it、遗忘门ft、输出门ot和细胞候选gt组成,其方程表达式为
it=σ(WiXt+Riht-1+bi)
(1)
ft=σ(WfXt+Rfht-1+bf)
(2)
ot=σ(WoXt+Roht-1+bo)
(3)
gt=tanh(WgXt+Rght-1+bg)
(4)
式中:Wi、Wf、Wo、Wg为输入权重矩阵;Ri、Rf、Ro、Rg为循环权重矩阵;bi、bf、bo、bg为偏置权重;Xt为当前词向量输入;ht-1为LSTM在t-1时的输出;σ(·)为sigmoid激活函数;tanh(·)为tanh激活函数。LSTM单细胞结构见图3。

图3 LSTM单细胞结构
LSTM第t时刻的细胞状态cellt和输出ht为
cellt=ft⊗cellt-1+it⊗gt
(5)
ht=ot⊗tanh(cellt)
(6)
式中:⊗为逐点乘积。

图4 LSTM细胞连接和BiLSTM神经网络结构
2.5 静态注意力机制
BiLSTM有效地融合了上下文信息,但却无法凸显文中的关键信息。注意力机制利用权重反映特征序列的相关性,可以让模型更专注于查找出与当前分类更有相关性的输入信息。本文采用静态注意力模型,通过计算一次加权α和输入向量得到整个句子的向量表示。静态注意力模型见图5。

图5 结合静态注意力机制的LSTM模型
静态注意力机制(自注意力机制)对LSTM输出的隐层向量表达进行加权求和计算,其中权重的大小表示每个词或句子的重要程度,其表达式为
(7)
(8)
(9)

2.6 归一化输出层
在模型中,词向量通道的输出为序列模式,句向量通道的输出为最后时刻的输出。词向量经过静态注意力机制的特征提取后,将与句向量具有相同维度,进而作为Softmax函数的归一化输入,最终计算得到一个n维向量(n为标签数目),每个维度对应一个标签的概率,其计算公式为
yi=Softmax(Wcct+bc)
(10)
式中:Wc为归一化权重向量;bc为归一化偏置;yi为标签概率。
2.7 损失函数及模型优化策略
在铁路行车事故文本分类中,采用交叉熵损失函数会在准确性和收敛性上优于最小二乘损失函数。交叉熵函数计算公式为
(11)
式中:E为交叉熵损失值;Ti为真实样本类别;Yi为预测样本类别。
本文使用L2正则化梯度防止过拟合和梯度阈值策略防止梯度爆炸。在遇到较大斜率的悬崖结构时,梯度阈值也可以防止梯度改变较大参数值。L2正则化公式为
J=J0+λ‖ω‖22
(12)
式中:λ为正则化系数;J为正则化梯度;J0为正则化初始梯度;ω为原始梯度。
本文使用Adam算法对BiLSTM网络的输入权重矩阵、循环权重矩阵和偏置权重矩阵,以及静态注意力机制的权值和偏置进行梯度更新。Adam算法是RMSProp和矩技术结合的增强,其算法公式为
(13)
(14)
(15)

3 实验
3.1 数据集
实验数据来自2019年1—10月间我国各铁路局的铁路行车事故文本。去除不能训练和样本数目极少的事故文本,剩余共计432条文本。这些数据分别隶属于10个等级,其事故描述和相应文本数目见表3。

表3 铁路事故文本类型及描述
从表3中可以看出:D21是事故中最轻的一级,发生次数也最多;C13和D3类别发生次数较少;铁路设备的不规范操作会对人员造成伤害,因此,B1和B2类别发生次数也较多。不同事故类别的文本词向量长度分布见图6,数据分析见表4。

图6 不同事故类别文本词向量长度分布
从图6和表4中可以看出,不同类型的事故,其文本词向量长度和波动情况存在明显的差异。
3.2 实验环境及参数设置
实验平台基于Matlab 2019a,中文分词和词向量生成使用Pycharm软件实现。实验环境设置见表5。
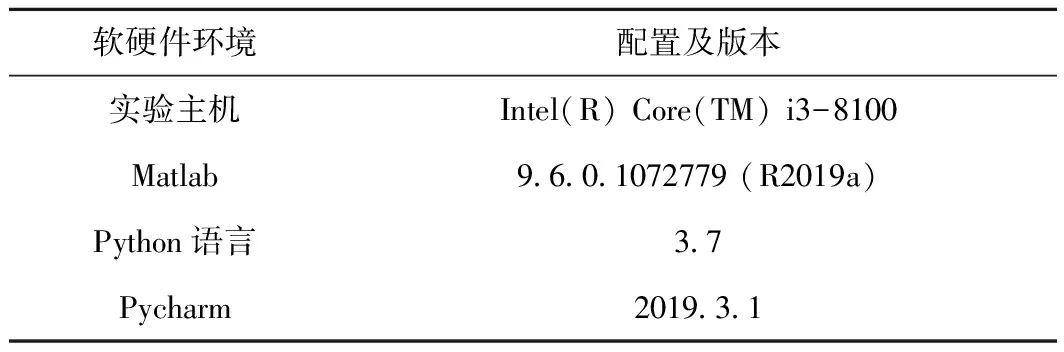
表5 实验环境
网络结构和训练的参数设置见表6。模型的参数是在训练过程中结合实验结果进行反复调试得到的。经过预实验,当词向量长度选择为100个时,网络能够在各类长度的文本分类中取得综合最优的结果。

表6 参数设置
为了减少数据量少和样本数量不平衡两个问题的影响,一方面在各次实验中随机划分训练样本和测试样本;另一方面,由于样本维度较大,不适宜采用基于欧氏距离计算的过采样方法,因此,选择带有放回的随机抽样过采样方法进行样本扩充。为了防止过度采样导致的过拟合问题,同时保留大类类别的属性,少数类样本数量均被扩充至50个左右。
3.3 评价指标
评价指标选择查准率Precision、查全率Recall和综合衡量指标F1分数。其中,查准率是指分类器正确分类的样本数与总样本数之比,查全率是指被正确判定的正例占总正例的比重,二者相互制约。F1平衡了查准率和查全率之间的关系,为了更直观地展示分类情况,本文引入MacroF1进行评估。MacroF1分数计算出每一类查准率和查全率的F1,最后将F1平均。各评价指标计算为
(16)
(17)
(18)
(19)
式中:TP为真实标签为真,且预测标签也为真的数目;FP为真实标签为假,且预测标签中为真的数目;FN为真实标签为真,且预测标签为假的数目。
3.4 实验设计和实验结果分析
本文设计的对比实验包括3种传统方法和5种模型结构。3种传统方法为:朴素贝叶斯、支持向量机SVM、未使用“铁路行车事故词库”的SVM。5种模型结构为:词向量BiLSTM网络(W-BiLSTM)、结合注意力机制的词向量BiLSTM网络(WA-BiLSTM)、句向量BiLSTM网络(S-BiLSTM)、结合注意力机制的词向量和句向量双通道BiLSTM网络(WA-S-BiLSTM)、未使用“铁路行车事故词库”的WA-S-BiLSTM)。各方法实验结果对比见表7。表7中所有数据均为运行10次的平均值,保留两位小数表示。
从表7可以看出,结合了词向量和句向量双通道的WA-S-BiLSTM神经网络在识别精度上取得了明显的提升,说明本文所提出方法在铁路行车事故分类中的有效性。根据实验结果,进一步的在以下方面进行分析。

表7 铁路行车事故分类结果
(1)文本数据特征对传统识别方法的影响
传统方法(朴素贝叶斯、SVM)在进行文本分类时,只有D2类取得了优秀的识别精度。结合表3和表4可以看出,D2类事故文本向量平均长度较短(74.41),文本间波动较小(25.54)。特别是,因D2类针对“调车脱轨”这一确定性事件,降低了训练的难度。
数据的样本数量对传统方法的识别精度存在影响。一方面,D21样本量最大,效果较好;另一方面,C13、D3等事故,因为样本数量小,传统方法识别精度波动很大。而对比样本数量相接近的类别,词向量平均长度越短,传统方法识别精度会相应提高。
相对而言,WA-S-BiLSTM从结果上能够降低数据量少和样本数量不平衡带来的影响,在不同数据量的样本中均取得了满意的识别精度。
(2)静态注意力机制的有效性
对比W-BiLSTM和WA-BiLSTM,结合静态注意力机制后,文本识别精度得到了提升,说明静态注意力机制有效提升了关键词向量的特征提取效率。值得注意的是,引入静态注意力机制后,提升最大的是D2和D3两类的分类结果。结合样本数据特点,D2、D3的文本平均长度较短,文本长度波动最小,更有利于静态注意力机制发挥作用。
(3)词向量与句向量的特征提取效果
因为铁路行车事故文本的长度总体波动较大,因此在识别精度上,句向量的特征提取效果整体要优于词向量。而对于如B1、C13、D2、D3这几类词向量长度较短、波动也较小的类别,词向量的特征提取效果相对更优。而词向量长度波动较大的类别,会对词向量的特征提取造成很大的影响。
在结合了词向量、句向量双通道的特点之后,WA-S-BiLSTM有效地提升了各类别的识别精度。
(4)同类型文本叙述多样性问题
在所有类别中,D10是WA-S-BiLSTM方法的识别结果中F1指数最小的。从样本数据特点分析,D10的样本总数为29,词向量平均长度76.14,词向量波动28.25。究其原因,与违反劳动纪律的形式多样导致D10文本叙述多样性强有关。在本文分析的10种类型的铁路行车事故样本中,D10类型样本的叙述多样性是最强的。
例1:“***客专***站始发的***次列车开车时联系不到机车乘务员,***,影响本列。”
例2:“***线***次列车运行至***处因车务人员挡道停车,***,影响货车1列。”
上述两例说明了D10文本叙述中违反劳动纪律形式的多样性,这给提取训练样本的特征造成了较大的困难,导致了识别精度的降低。
(5)“铁路行车事故词库”的有效性
如前文所述,“铁路行车事故词库”可以实现铁路专用词汇的准确分词。从表7中可以看出,使用“铁路行车事故词库”之后,无论是传统SVM方法还是本文提出的WA-S-BiLSTM方法,事故类别的分类精度均有明显提升。
3.5 实验结论
综上,可以得出以下结论:
(1)针对铁路行车事故文本存在明显的文本长度不一,文本长度波动大的特点,结合词向量在短文本、波动小文本中的提取效果和句向量在长文本、波动大文本中的提取效果,本文提出了WA-S-BiLSTM方法,有效地提升了整体识别精度。
(2)在词向量通道引入静态注意力机制,能够有效提升特征提取效率。特别是针对文本长度较短、文本波动较小的事故文本类别,效果更加明显。
(3)样本数据的数量和不平衡会对传统方法识别精度造成很大影响。这些影响可以通过合理设计实验来降低。从实验结果来看,本文提出的WA-S-BiLSTM方法也有助于降低样本数量对于识别精度的影响。
(4)铁路行车事故文本中,存在叙述非常多样化的类型,如何进一步提升这一类文本的识别精度,是未来研究应关注的一个方向。
4 结束语
针对铁路行车事故文本的分类问题,本文提出了基于LSTM网络的事故文本分类模型。由于铁路文本的专业性,在中文分词阶段就会造成大量的分词误差,为此本文构建了“铁路行车事故词库”;针对铁路事故文本长短不一的问题,设计了词向量和句子向量双通道的分类模型结构;针对铁路行车事故文本的词向量特征提取效果,在词向量通道中引入了静态注意力机制,有效提升了铁路事故文本重点词语的特征提取效率。实验结果证明了本文所提出方法的有效性。同时,在实验中发现,样本叙述的多样性,以及文本向量长、波动大的小数量样本均会对识别精度产生负面影响,这也是未来研究中应进一步解决的问题。
