基于遗传算法的快递物流配送中心选址
2021-11-01刘善球樊兵鹏
刘善球,樊兵鹏
0 引言
配送中心是物流系统网络中的关键节点和重要的基础设施,在整个物流系统网络规划中起着枢纽性的作用[1]。快递物流配送中心选址是指在具有若干个发件网点或者若干个收件网点的物流配送区域内,综合考虑物流运输成本、配送中心建设成本等成本因素,采用定性与定量分析方法,选取最符合经济社会情况的单个或者多个位置设置配送中心的物流系统网络规划过程。在整个快递物流供应链环节中,快递配送中心,对上承接来自发件网点包裹的集运任务,对下承接收件网点的配送运输任务,其选址结果将会对配送路径的规划、运营成本、配送效率等产生直接的影响。
1 研究综述
基于配送中心对国家流通经济发展的重要作用,国内学者们针对各种类型的配送中心的选址问题,分别采用不同的算法模型,对其进行了深入研究:如李茂林[2]认为物流配送中心选址难以优化以至于会影响整个物流系统的配送效率,针对这一问题他提出一系列的猴群优化算法求解策略,对模型进行求解,通过对线性函数表达式中多个影响因子的非线性调节,改进了猴群算法的爬行过程,提高了算法模型的求解精度和求解能力,最终更加精确地求解出物流配送中心优化选址位置;张于贤等[3]通过构建带有物流收益(输出)和物流成本(输入)之差的数据包络评估模型(data envelopment evaluation analysis,DEA),对现有配送中心的各项指标进行评估,根据评估的结果得到配送中心的再选址方案,但其基于DEA 选址方法所构建的线性函数选址评价模型与通常利用CCR 模型、BCC 模型等具有矩阵性质的评价模型方法不同,该选址评价研究方法的可行性有待进一步实证;崔杨等[4]针对第三方物流配送过程中产生的如延误、爆仓等配送异常问题,综合运用层次分析法中的定性分析方法和定量分析方法,对第三方物流配送中心选址问题进行了评价研究,通过构造层次分析模型、判断矩阵,求解出最优位置作为第三方物流配送中心的选址位置;于蕾[5]综合采用定性与定量分析法对安徽省农产品的供给与需求状况进行了分析,构建了基于重心法的农产品配送中心选址模型,并采用R 语言编程对具有迭代性质的选址模型进行求解,但存在绝对假设条件限制、去市场化、需求量计算过于简单等局限性;生力军[6]指出,经典粒子群选址模型在求解过程中存在局部最优和过早收敛等问题,为了克服此缺点,将量子进化算法与粒子群算法相结合,构建了基于量子粒子群算法的物流配送中心选址模型,并通过粒子编码和量子交换、变异等操作,有效避免了模型在选址求解中存在局部最优和过早收敛等问题。
基于遗传算法选址国内学者们针对不同类型的选址问题进行了大量创新性的研究:如赵斌等[7]指出,传统单一的遗传算法难以快速有效求解出系统复杂的医疗器械物流园区选址问题的最优化问题,通过将遗传算法和免疫算法相结合,建立了免疫遗传算法的选址模型,针对医疗器械物流园区选址的特点,构建了包含多种成本要素的医疗器械物流园区选址问题的目标函数模型,并且对选址模型的求解方法进行了设计,从而求解出最优的物流园区选址方案;郭静文等[8]为了优化消防站网络规划布局结构、降低消防站选址的系统选址成本,以及提升消防站空间资源利用率,对传统的遗传算法进行了改进,使其具有自适应性质,可自行求解出优化后的消防站规划建设个数和选址位置,有效克服了在已有选址规划方案中选择消防站建设个数和选址位置等的缺陷,但在实证研究中,并未给出具体的求解方法或求解过程;周思育等[9]为了解决湖北省内烟草资源物流配送不均衡和配送成本高昂等的问题,构建了综合考虑多种选址成本要素的遗传算法选址模型,并且通过Matlab 数据分析软件,对配送中心选址模型进行求解,选取最佳的位置设置配送中心,提高了烟草资源物流配送的效率,并降低了配送中心系统选址的成本;张钰川等[10]为兼顾物流园的配送运输、货物集散、仓储分拨、管理服务等的作用和功能,基于物流成本的基础上,构建了带有双层规划的遗传算法物流园选址模型:上层模型由影响物流园选址要素的各种成本函数所构成,下层模型由影响决策者和客户利益诉求的成本函数所构成,并通过遗传算法对双层规划模型进行求解,最后通过实例验证了遗传算法模型对物流园选址成本问题具有一定的优化作用。
本文选择利用遗传算法模型对快递物流配送中心的选址问题进行研究,针对配送中心选址的特点,构建了包含固定成本、分拣成本等多个成本要素的线性目标函数,建立了基于遗传算法的选址模型。遗传算法选址问题属于NP 难题,利用传统的算法求解方法容易产生局部最优等问题,为了克服遗传算法模型在选址问题求解过程中所产生的局部收敛和早熟收敛等局限性,本文提出了一系列经过改进后的遗传算法求解策略,具体包括编码方法、自适应交叉概率函数、自适应变异概率函数等求解方法,这在很大层度上提高了遗传算法模型在选址问题中的求解精度和求解效率。
2 遗传算法的配送中心选址模型
2.1 模型假设
为了便于构建快递物流配送中心遗传算法选址模型,简化算法模型计算复杂性和使其具有很好的适用性,现对模型做如下假设:
1)在一定备选范围内进行配送中心的选取;
2)发件网点或收件网点数目多于配送中心数目;
3)一个网点仅由一个配送中心提供配送服务,但一个配送中心可覆盖多个网点;
4)配送中心容量可满足各配送网点的总需求量;
5)各网点配送需求一次性运输完成,且假设匀速行驶;
6)物流系统中包含两个层次的运输,即从发件网点到配送中心的运输和从配送中心到收件网点的运输,且均采用公路运输;
7)系统总费用不考虑包裹在分拣中心的装卸搬运成本和暂存成本,只考虑配送中心建设成本、运输费用和变动成本。
2.2 变量设置
假设发件网点数量有m个,配送中心数量有n个,收件网点数量有l个。其他参数符号及变量设置如表1 所示。

表1 变量设置Table 1 Variable setting
2.3 模型构建
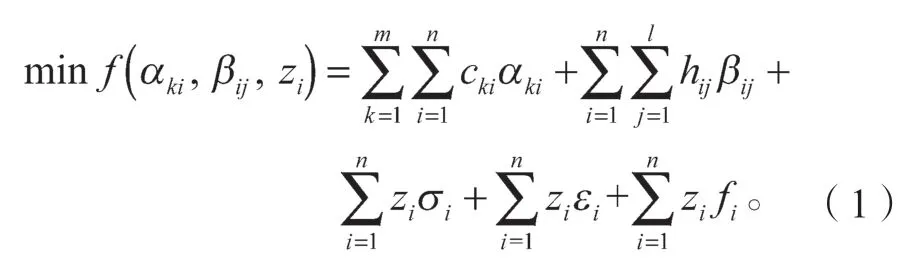
s.t.
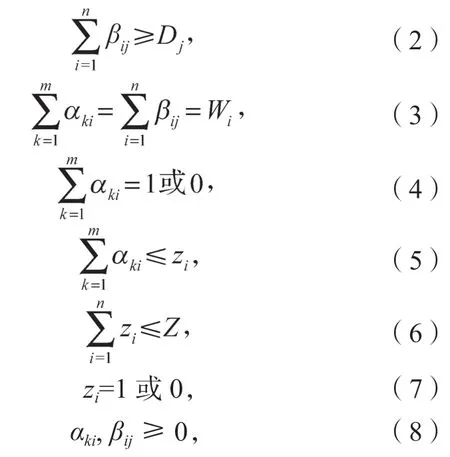
式中:i=1, 2,…,n;
k=1, 2,…,m;
j=1, 2,…,l。
在上述各式中,式(1)表示目标函数,等号右边第1 项为从发件网点到配送中心的运输成本,第2项为从配送中心到收件网点的运输费用,第3 项为建设配送中心的固定投资成本,第4 项和第5 项为配送中心的变动成本(分别为管理成本和分拣成本);式(2)表示配送中心可以满足所有收件网点的配送需求;式(3)表示从收件网点到配送中心的集运量恒等于从配送中心到收件网点的配送量;式(4)表示所有发件网点被配送中心所覆盖;式(5)表示从发件网点到配送中心的运输量小于等于配送中心的最大容量限制即流量限制[11];式(6)表示配送中心的建设数量不大于其最大建设数量;式(7)(8)为决策变量的约束。
3 基于遗传算法模型的求解
遗传算法(gentic algorithm,GA)这一术语于20 世纪50年代由美国学者J.Holland 所提出,是基于模拟自然选择和遗传机制的典型启发式算法模型,具有操作简单、鲁棒性强等优点。
在使用遗传算法对快递物流配送中心选址问题的求解过程中,容易产生过早收敛和局部最优等问题。为了提高算法模型的全局搜索能力以及保证种群的多样性,防止遗传算法在求解的过程中出现过早收敛和局部最优问题,需要对传统的遗传算法求解进行改进。因此本文提出了一系列的遗传算法选址模型的改进求解策略,从对染色体的编码策略的选择到自适应变异概率的计算,这些求解策略有效解决了传统遗传算法出现的过早收敛和局部最优问题,使GA 空间搜索能力明显增强,提高了算法模型的求解能力和求解效率。
3.1 遗传算法模型求解策略
1)染色体编码
将所需要解决的问题采用编码的方式是遗传算法的重要操作,即将求解的问题映射为编码问题,遗传算法中常见的编码方法有二进制编码、格雷编码、排列编码和浮点数编码等。对编码的性质进行评价的指标主要有完备性、健全性和非冗余性。
对于决策变量zi,课题组采用二进制编码[12]方法,利用{0, 1}自然数,将配送中心zi通过二进制编码成为由{0, 1}所构成的染色体或个体,编码串即染色体的长度L和数量K是由所要求解的精确度来确定的。二进制编码方式具有操作方便、计算简单等优点,但也存在求解精度低、易造成算法搜索空间过大等缺点,且不适应于连续函数问题的编码。
单一的编码方式无法将所有优化问题的决策变量约束表示出来,对于决策变量αki、βij,由于其对应的变量个数比较多,且编码串的长度由决策变量中的变量个数所决定,所以对其采用浮点编码的方法,使得编码后染色体的长度L不至于太长,增强了算法模型的空间搜索能力,有利于算法解码。浮点编码适用于对于求解要求精度较高、具有较大的搜索空间、需要处理复杂的决策变量及约束等特点的编码方法,它降低了遗传算法编码后计算的复杂性,提高了遗传算法的求解效率。
2)适应度函数
为了保证染色体中具有优良性质的个体基因遗传到下一代,通过模拟遗传进化过程中适者生存原理,建立唯一具有评价群体生存选择机会大小的适应度函数,适应度函数值越大,则种群中优良基因作为父代基因遗传到下一代的可能性越大;否则可能性越小。根据这种优化原理,建立如下与目标函数之间存在映射关系的适应度函数:
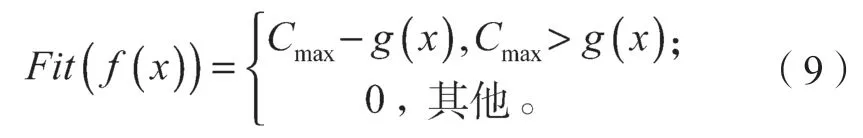
式中:Fit(f(x))为适应度函数;
Cmax表示截止当前进化进度(代数)所产生的g(x)的最大值,此时Cmax会随着进化进度(代数)的变化而变化;
g(x)为目标函数的期望值。
3)选择算子
选择算子操作,通过所构建的适应度函数,可以对群体中染色体遗传性质的优劣进行判断和评价,选择或复制那些群体中适应度值高的个体作为父代基因遗传到下一代,而适应度值低的个体则被淘汰,这种操作有效提高了算法的收敛性和计算效果。本文采用轮盘赌的方法进行选择算子操作[13],建立如下与适应度函数之间存在映射关系的选择概率:

式中:Pi表示个体i被选择的概率;
f(xi)表示各染色体个体的适应度函数值;
xi表示种群中的个体。
4)自适应交叉算子操作
交叉算子模仿自然进化过程中的遗传规律,将具有优良基因的两个父代染色中的部分基因通过交叉算子操作的方式进行基因重组,从而产生新的更适应于适应度函数值的子代个体,交叉算子操作是遗传算法中的核心操作步骤。交叉操作具有随机性和多样性等特点,其类型主要包括单点交叉、多点交叉、部分匹配交叉、顺序交叉等。
交叉算子操作中的交叉概率是影响遗传算法性能的关键所在,对算法的收敛性产生直接的影响。交叉概率越大,染色体产生交叉的速度越快,则其产生新的个体的速度也越快。当交叉概率过大时,在迭代初期会增强算法的搜索能力使其快速收敛,但在迭代后期对具有较高适应度函数值的个体基因的结构破坏性会增大,不利于算法最优解的产生;交叉概率过小时,算法的搜索能力即交叉操作能力过于缓慢,同样不利于寻求算法的最优解。基于这种优化问题,本文引入了自适应交叉概率[14],计算过程中交叉概率会随着适应度函数值的不同而自动调整,具体的计算公式如下:
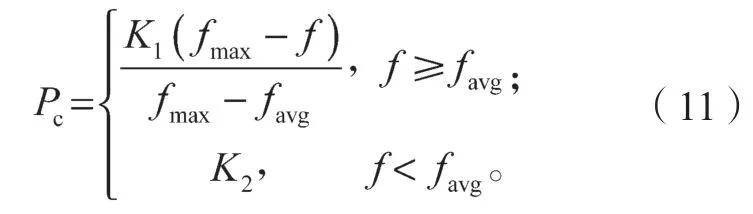
式中:Pc为自适应交叉概率;
fmax为群体中个体为最大的适应度函数值;
favg为每代群体的平均适应度函数值;
f为产生交叉的两个个体其中一个个体为较大的适应度函数值;
K1、K2为区间为(0, 1)的常数。
5)自适应变异算子操作
变异算子操作是模仿自然基因在遗传过程中发生基因突变现象,即某条染色体中的一个或者多个基因发生变异的现象,但一般发生变异的概率比较小(通常在为0.01~0.10)。当变异概率太小时,不利于染色体新个体结构的产生;当变异概率太大时,染色体结构遭到破坏的可能性会增大,遗传算法搜索的有效性随之降低。针对变异算子操作中的寻优问题,本文采用自适应变异概率[14]:
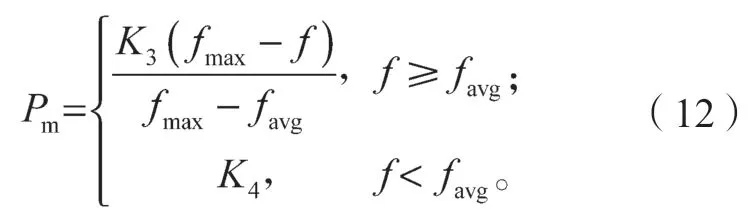
式中:Pm为自适应变异概率;
K3、K4为区间(0, 1)的常数。
3.2 遗传算法求解步骤
STEP 1 染色体编码。随机产生K条染色体,并通过二进制的方法进行编码,每条染色体即代表一种可行解。
STEP 2 群体初始化。建立适当规模的由染色体或个体所构成的初始化群体。
STEP 3 适应度函数。适应度函数值是判断个体生存机率大小的唯一标准,对群体进化进度和形势具有直接的影响,可利用式(9)计算出适应度函数值f(xi)。
STEP 4 选择算子。对于种群中适应度高的个体进行操作选择,可直接作为父代染色体进行繁殖,其他的染色体则采用轮盘赌的方式操作选择。
STEP 5 交叉算子。对于被选中的染色体,通过交叉算子操作,将具有优良性质的两个染色体中的部分基因通过交叉位移的方式产生新的个体,并利用式(11)计算出不同个体的自适应交叉概率Pc。
STEP 6 变异算子。对不同的个体采取自适应调整策略,利用式(12)计算出自适应变异概率Pm。
STEP 7 判断适应度函数值。完成STEP 6 后跳转至STEP 3,重新计算适应度函数值并作出判断,然后继续进行循环求解。
STEP 8 终止条件:根据预先设定的最大迭代次数Tmax,当达到所规定的迭代规模后则终止算法运行。
4 实例分析
1)假设及问题描述
为了验证遗传算法模型在配送中心选址中的有效性,本文结合算法模型设计了具体的算例,通过对算例的求解来验证遗传算法模型在配送中心选址问题研究中的有效性和实用性。长沙市某城际快递物流服务公司计划开展城际快递物流配送业务,假设该公司的配送业务统一采用公路运输,且具有固定的发件网点、收件网点、配送中心来具体开展该公司的城际快递物流配送业务。设发件网点有4 处,分别为芙蓉区(A1)、天心区(A2)、开福区(A3)、雨花区(A4);收件网点有5 处,分别为宁乡县(B1)、望城区(B2)、岳麓区(B3)、长沙县(B4)、浏阳市(B5);可供选择的城际快递物流配送中心有5 处,分别为芙蓉区(P1)、天心区(P2)、岳麓区(P3)、长沙县(P4)、浏阳市(P5),现需要从这5 处可选方案中选择3 处最符合经济社会情况的建立该公司的城际快递物流配送中心,其固定投资成本和容量限制如表2 所示。

表2 备选配送中心的固定投资成本和容量限制Table 2 Fixed investment costs and capacity constraints for alternative distribution centers
备选配送中心的变动成本(包括管理成本和分拣成本)如表3 所示;各发件网点到备选配送中心的单位运费和集运量如表4;备选配送中心到各收件网点的单位运费如表5 所示。
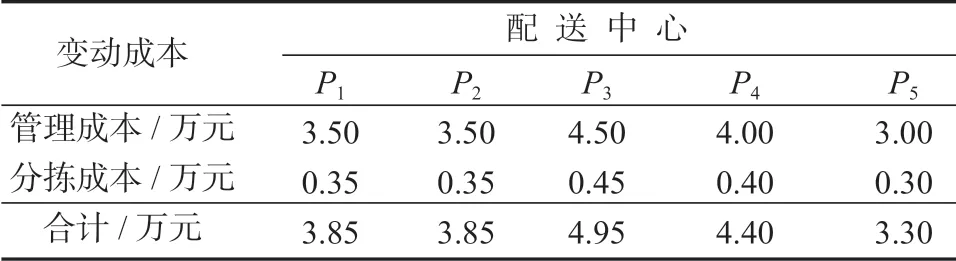
表3 备选配送中心的变动成本Table 3 Variable costs of alternative distribution centers
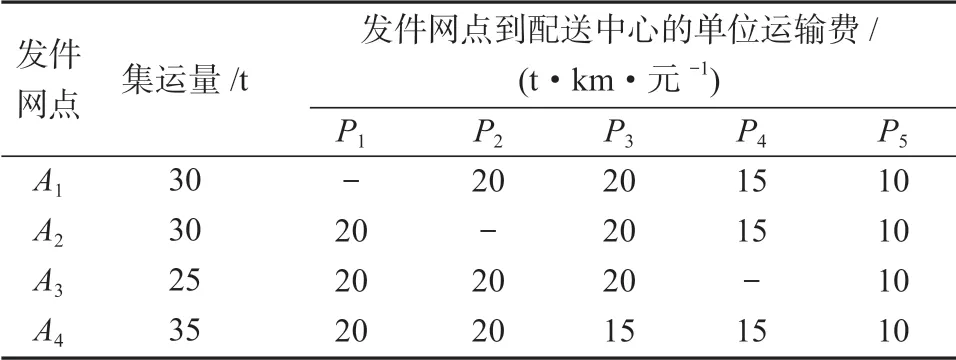
表4 各发件网点到备选配送中心的单位运费和集运量Table 4 Unit freight and volume of each outlet to the alternative distribution center
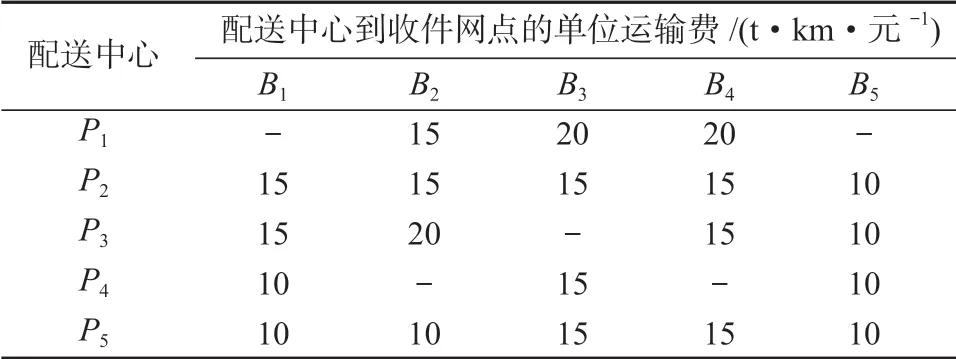
表5 备选配送中心到各收件网点的单位运费Table 5 Unit freight from alternative distribution centers to pick-up outlets
2)算例的求解
运用Matlab2017a 仿真软件中的遗传算法工具箱对算例进行仿真模拟求解计算,其中相关参数变量设置如下:最大迭代次数设置为Tmax=100;初始化种群规模N=100;自适应交叉概率Pc=[0.4, 1.0];自适应变异概率Pm=[0.01, 0.10]。通过编程软件计算求解,芙蓉区(P1),岳麓区(P3),长沙县(P4)被选中作为该公司的城际快递物流配送中心,由发件网点到配送中心的集运方案见表6,由配送中心到收件网点的配送方案见表7。
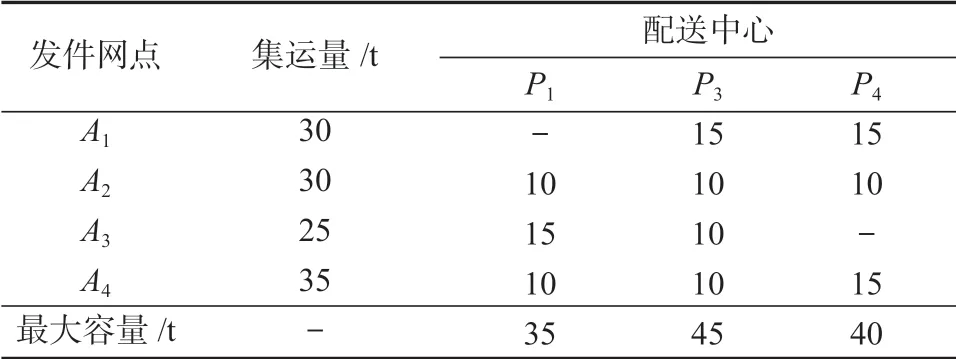
表6 由发件网点到配送中心的集运方案Table 6 Centralized transportation scheme from the outlet to the distribution center
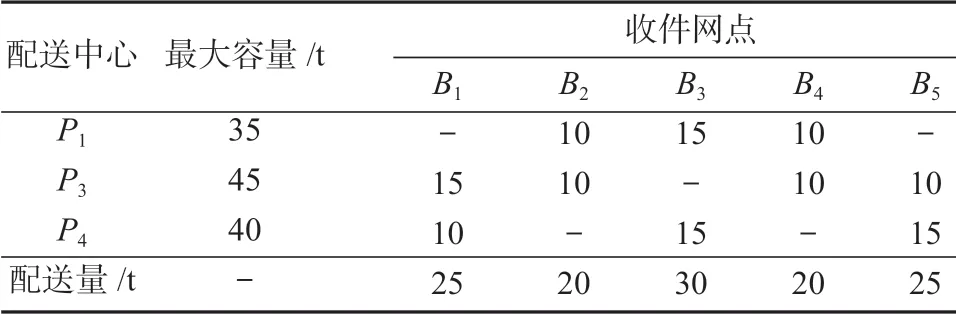
表7 配送中心到收件网点的配送方案Table 7 Distribution scheme for the transfer from distribution center to receiving outlets
通过利用Matlab2017a 系统仿真软件对算例进行计算,所得结果显示,所选3 个配送中心的选址系统总费用f=253.595 万元,其中配送中心固定投资成本成(即配送中心投资建设成本)占选址系统总费用的94.64%,是该选址系统最主要的投资成本。由表6~7 可以得知:发件网点到配送中心的集货量恒等于配送中心到收件网点的配送量;各发件网点到配送中心的集运量均在配送中心P1、P3、P4配置的最大容量限制范围以内,并且所有收件网点的配送需求也均得到了满足,几乎没有发生货物滞留、积压的现象,供配需求基本实现平衡,即在芙蓉区(P1)、岳麓区(P3)、长沙县(P4)共3 个区域内建立配送中心,能够最大限度地满足该公司在长沙市开展城际快递物流配送业务的需求。
5 结语
本文研究分析了快递物流配送中心的选址问题,因为利用传统简单遗传算法,难以求解出含有多种变量因素的选址问题的最优解,故选择和利用启发式算法中的遗传算法模型,对配送中心的选址问题进行了研究。
针对快递物流配送中心选址的特点提出了一系列的假设前提条件,并建立了含有固定投资成本、变动成本等多种选址成本要素的目标函数,构建了配送中心选址系统成本函数;针对遗传算法在求解过程中容易陷入局部最优和过早收敛等问题,提出了包括自适应交叉概率、自适应变异概率等一系列的求解策略,增强了算法的全局搜索能力和求解能力;针对配送中心实际选址问题,选择了长沙市某城际快递物流公司的配送业务进行实例研究,运用Matlab2017a 系统仿真软件对其进行求解,验证了遗传算法在配送中心选址问题研究中的有效性。
由于配送中心选址是一个相对多样且复杂的研究问题,而本文基于遗传算法的快递物流配送中心选址问题的研究,在理论和实例研究部分还有诸多不足,有待进一步深入研究。例如仅考虑了确定性因素下配送中心的选址问题,而没有考虑不确定因素下配送中心的选址问题;本文主要研究分析了在一定的物流区域范围内选择和建立新的物流配送中心,而未在现有配送中心的基础上对配送中心再选址问题进行研究;当现有配送中心的集货量、配送量超出其最大容量限制后,是应该对现有配送中心进行扩建还是重新建立新的配送中心等方面的研究还未涉及。因此,本文基于遗传算法配送中心选址问题的研究还具有很大的研究空间,有待进一步深化和拓展研究。
