基于深度学习的自动文本摘要生成
2021-10-30谢涵朱逸青
谢涵 朱逸青









摘要:以往人们都是手动写摘要,手动写摘要既不能省时省力,摘要的水平有时候会也受到写摘要的人写作水平的影响。随着自然语言处理在国内的兴起,相关的文本摘要数据集也可以被整理和获取。本文通过基于深度学习的技术自动生成文本摘要,使用海量样本训练生成相应领域的自动文本摘要器。在生活和生产中使用能够提取有用信息的自动文本摘要器,可以筛选出不必要且无关紧要的数据,实现摘要可以增强文档的可读性,减少研究信息所花费的时间。在本文中,我们构建seq2seq的框架并结合attention机制,比较基于RNN、LSTM和GRU的神经单元对社交媒体数据的中文文本摘要的处理情况。实验表明,引入分层注意力机制的Seq2Seq+ Hierarchical Attention+basedGRU模型可以从原文中生成较高质量的摘要。
关键词:自动摘要;深度学习;Seq2Seq;注意力机制
0 引言
随着网络媒体的飞速发展,微信、论坛、博客、微博等新媒体平台深深地影响着人们的阅读方式,相对于报纸、杂志,越来越多的人们选择从各新媒体平台上获取更方便、简洁的新闻资讯及其他信息。然而,人们在享受信息获取的便利性的同时面临着信息爆炸所带来的困扰。在各大媒体平台中,文本信息呈现出指数级别的增长,使得人们无法迅速从海量的信息中获取所需的资讯。文本摘要作为文本内容的缩影,概括了文章的主要内容和核心观点。因此,为了快速获得文章的主要信息,节省访问时间,提高阅读效率,自动摘要技术应运而生。
1958年,美国IBM公司(International Business Machines Corporation,國际商业机器公司)的Luhn提出了自动文摘的概念,并对此进行了研究,他提出利用文本中词频信息来统计文本中的高频词,然后以高频词作为特征进行加权,从而 提取出文章中的关键句作为摘要。尽管这种方法在当时已经非常超前,但也存在一定的缺陷,一些低频但重要的词信息经常会被忽略,从而使得摘要质量差强人意。
1969年,Edmundson利用标题词、线索词、句子位置以及关键词频等计算每个句子的权重[1],取得分最高的几个句子作为文章的摘要。
1995年,Kupiec提出了使用朴素贝叶斯分类模型来判定句子是否应该抽取为摘要[2],计算每个句子成为摘要的概率,取得分最高的几个句子作为文章的摘要。
1999年,Lin等人假设文章中用于摘要抽取的各种特征是相互关联的,并使用决策树对句子进行打分[3],取得分最高的几个句子作为文章的摘要。
2001年,Conroy与O'leary使用隐马尔可夫模型进行摘要抽取[4]。该方法也使用句子位置、句内词数以及句内词语与文章词语的相似度等一些文章的特征来确定句子的得分。
2004年,Mihalcea等人使用pageRan算法抽取关键句子生成文档摘要[5]。先把文章分解成若干个句子,每个句子对应一个图的顶点,句子间的关系作为边,最后通过pageRan算法得出各顶点的得分并生成文本摘要。
2014年,Kageback M等人首次引入深度学习方法完成摘要任务[6],利用语义表示的相似度,并采用次优化选择适合的句子作为摘要。
2016年,Cheng和Lapata等人提出了一种基于序列到序列(Seq2Seq)的通用自动摘要框架[7],采用层次文档编译器和注意力机制抽取文摘句。
2017年,Abigail See等在序列到序列(Seq2Seq)的通用自动摘要框架上结合copy机制建立指针网络结构[8],将生成式文本与抽取式文本有机结合起来。同年,Google的团队提出了Transformer模型,该模型仅仅采用了Attention(注意力)机制[9],并不像传统的Seq2Seq那样需要结合RNN (Recurrent Neural Network,反馈神经网络)或者CNN(Convolutional Neural Networks,卷积神经网络)才能使用,这个模型对谷歌翻
译的发展起到了巨大的推动作用,而且文本摘要生成与机器翻译有一些相似之处,在2018年Arman Cohan等基于Attention机制更进一步,提出根据文章语篇结构和句子结构,建立句子注意力机制,使得自动文本摘要取得当时最好的效果[10],这个注意力机制有可以被本研究借鉴的地方。
文本摘要技术可分为抽取式和生成式两种,通过提取或生成一段短文本,总结和表达原文的主要信息。抽取式文本摘要是从文档中抽取已有句子形成摘要,而生成式文本摘要则是在理解原文意思的基础上,通过转述、同义替换、句子缩写等技术,生成更简洁、更流畅的摘要。与抽取式摘要相比,生成式摘要更接近人工摘要的效果。随着深度神经网络的迅速发展以及基于注意力机制的端到端模型的提出,基于神经网络的生成式文本摘要的应用迅速发展,它在一些上百万的数据集中的表现已经超越了抽取式文本摘要,可以取得不错的效果。
相对于机器翻译、情感分析、知识图谱等领域,自动文本摘要在国内起步较晚。然而基于Attention的Seq2Seq模型的提出以及Hu等人提出了一个新的中文文本摘要数据集LCSTS[11],使得中文文本摘要得到了一定的发展。此外,中文相比于英文,在数据处理方面更加复杂。第一,中文不存在天然的分隔符,正确的根据语义对句子进行分词具有一定的挑战性。第二,中文具有一词多义的特点,很多词汇在不同的语境下具有不同的解释。第三,中文语法较英语而言更加灵活,时常导致歧义的出现。
Matthew等人于2018年提出了一种新型深度语境化词表征的EMLO (Embeddings from Language Models,语言模型嵌入)预训练模型[12],用于对多义词进行建模。接着,Open AI 团队提出了GPT模型[13],一种基于Transformer的可迁移到多种NLP(Natural Language Processing,自然语言处理)任务的神经语言模型;此外,Google团队提出的BERT(Bidirectional Encoder Representation from Transformers)模型[14],刷新了NLP11个方向的记录,于是2019年Yang Liu等专门基于BERT模型构建自动文本摘要模型,在数据集上实现当时最优效果[15]。
2020年,Jingqing Zhang等人提出了一种新的自监督预训练目标:GSG (Gap Sentences Generation),以适配Transformer-based的encoder-decoder模型在海量文本语料上预训练,用PEGASUS 模型进行全面测试,结果PEGASUS 刷新12个数据集的ROUGE得分记录,结果表明PEGASUS模型在多个数据集上达到与人工摘要相媲美的性能[16]。
目前国内研究文本摘要技术的中坚力量在高校,主要包括哈尔滨工业大学信息检索实验室、清华大学智能技术与系统国家重点实验室、北京大学计算科学技术研究所等。有国内学者通过融合TextRank算法,利用其实现简单、无监督学习、语言弱相关、既适用单文本也适用于多文本的特点,但发现它易受词频影响,在提取摘要的准确度上不尽人意;综合考虑文章的结构、标题、句子位置、句子长度等多种统计特征,提出了一种改进的iTextRank算法,通过改进中文文档中句子相似度的计算方法,得到的文本摘要比TextRank的质量更好。
尽管这种方法通过权重控制了识别文本的精确度,但没有考虑社交媒体的特征与语义的信息,仅依照词汇的共现特征规则无法将互动关联的文本当成一个整体,无法解释相关的文本是否表示共同的主题。直接将整个语料集的句子独立地进行排序,可能导致生成的摘要意思太模糊,无法衡量其覆盖了哪些话题或社交实体。因此,本研究在进行模型生成摘要前采用了多种分类方法将文本进行分类。
1数据预处理与数据标定
1.1数据来源
哈尔滨工业大学深圳研究院的教授,通过爬取新浪微博的短文本数据构建了LCSTS数据集。LCSTS是一个超过200万数据的中文短文本摘要数据集,由短文本及其对应的摘要组成。数据收集方法:首先收集来自多个领域的50个流行的官方组织用户作为种子,再从种子用户中抓取他们关注的用户,然后选取新浪微博粉丝大于100万的大V用户,最后抓取候选用户的微博内容进行清洗过滤,得到纯文本数据。
1.2数据预处理
首先,随机选取LSCTS数据集中的一个子集作为训练集,用于训练模型。
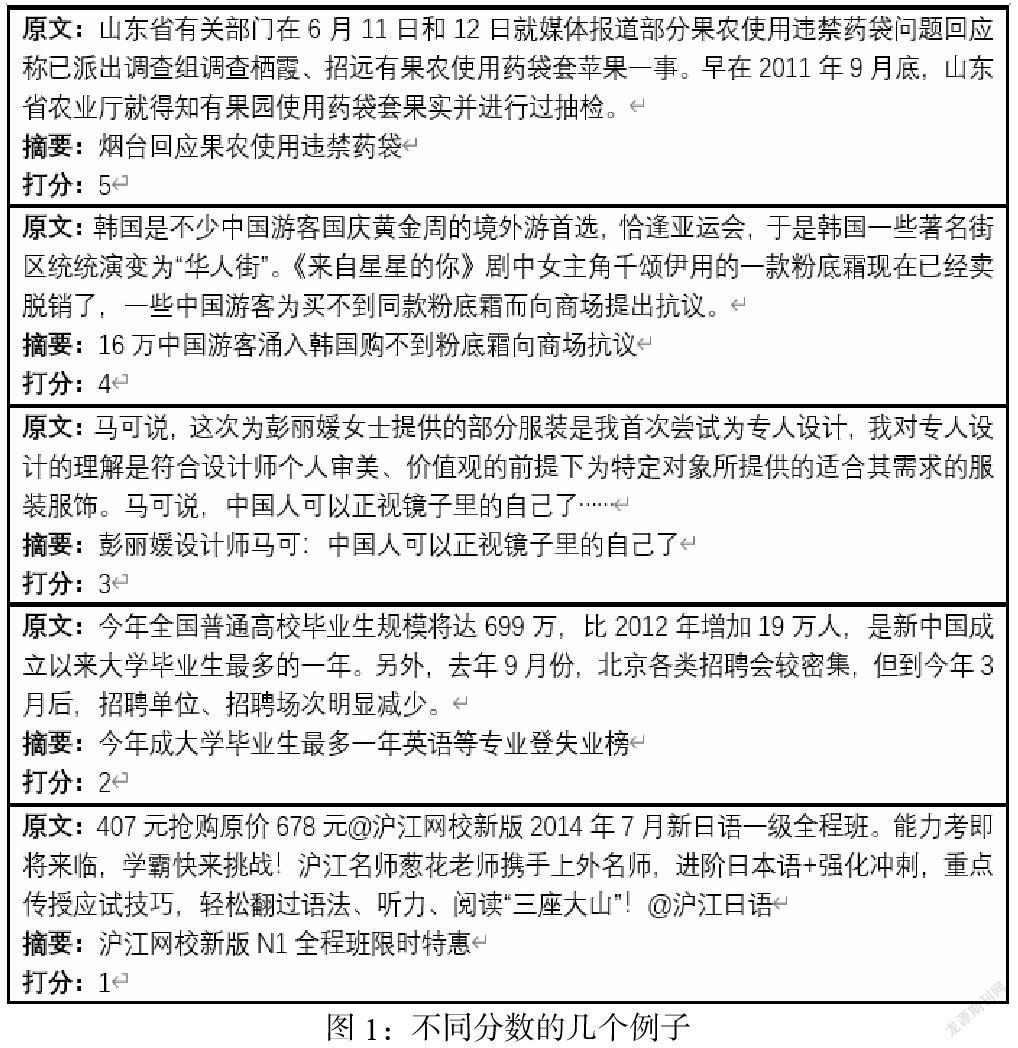
第二,数据标定。选取5名志愿者对数据集中的文本数据和对应摘要进行打分,分数为1、2、3、4、5,用来表示文本与相应摘要之间的相关性,其中“1”表示“最不相关”,“5”表示“最相关”。用于打分的数据是从训练集中随机抽取的,以此来描述训练集的分布。图1说明了不同分数的例子。从例子中我们可以看出,评分为3、4或5的文本与相应摘要非常相关,这些摘要内容准确且简洁;而评分为1或2的摘要高度抽象,相对较难从文本中总结出来,它们更有可能是标题或评论,而不是摘要。
第三,统计数据显示,1分和2分的百分比小于总数据的20%,可以通过使用经过训练的分类器进行筛除。最后将得到的分数为3、4、5且具有共同分数的文本作为测试集。
2 模型构建
2.1数据的清洗和整合
文本是非结构化数据,将其输入神经网路首先要给文本建立一个语料库,根据词频排序,使得每个词语或短语都可以用一个One-Hot(独热)向量表示。
为了提取到每个词语或短语的特征,也为了加速网络的收敛,引入了词嵌入向量。首先,对下载的数据集进行清洗和分词,通过Word2vec得到Word embedding(词嵌入)向量。
Word2vec解决了以往One-Hot Encoder中由于字词数量过大而造成维度灾难的问题,能够将One-Hot Encoder转化成低緯度的连续值,而且向量中意思相近的词也会被映射到向量空间中的相近位置。
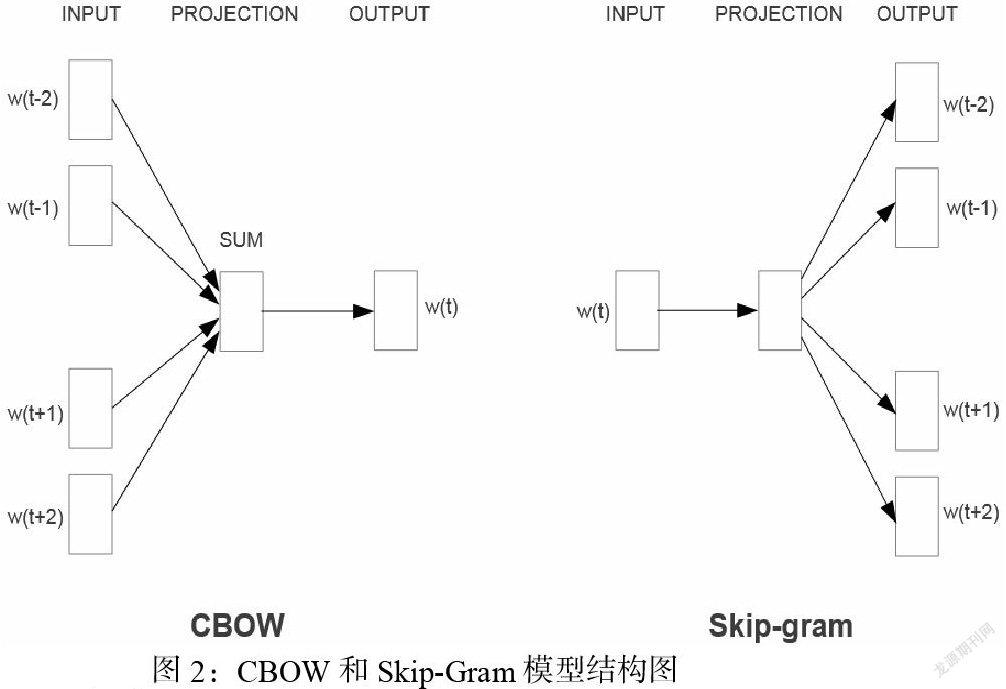
Word2vec由两种训练方式,分别是CBOW(Continuous Bag of Words,连续词袋)模型和Skip-Gram模型。CBOW模型又被称为连续词袋模型,其结构是一个单层神经网络。特点是输入已知的上下文,输入对当前单词的预测。Skip-Gram模型则与之相反,只是对CBOW模型的因果关系进行了逆转,即用当前的词语来预测上下文。
两种模型具体如下图:
2.2构建Seq2seq模型
Seq2seq模型有一个Encoder(编码器)和一个Decoder(解码器),将一个输入的句子编码成一个固定大小的state,然后作为Decoder的初始状态(当然也可以作为每一时刻的输入),但这个状态对于Decoder中的所有时刻都是一样的。
2.3构建加入Attention机制的Seq2seq模型
Attention即为注意力,人脑在对于不同部分的注意力是不同的。需要Attention的原因是非常直观的,如当我们看一张照片时,照片上有一个人,我们的注意力会集中在这个人身上,而它身边的花草蓝天,可能就不会得到太多的注意力。也就是说,普通的模型可以看成所有部分的Attention都是一样的,而这里的Attention-Based Model(基于注意力的模型)对于不同的部分,重要的程度则不同,Decoder中每一个时刻的状态是不同的。
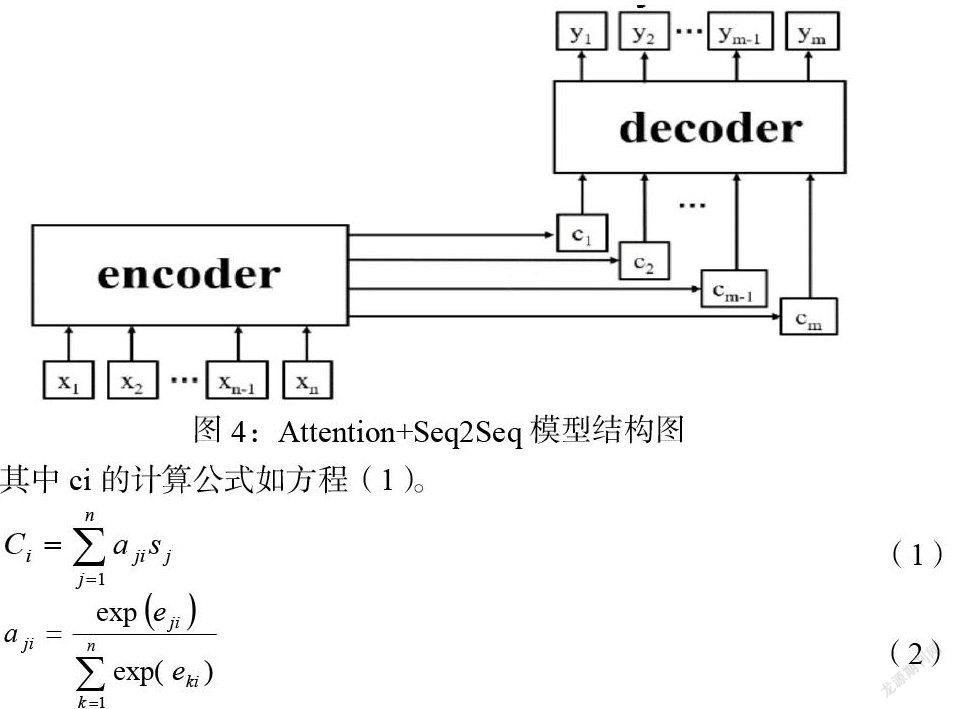
而没有Attention机制的Encoder-Decoder结构通常把Encoder的最后一个状态作为Decoder的输入(可能作为初始化,也可能作为每一时刻的输入),但是Encoder的state(状态)毕竟是有限的,存储不了太多的信息,对于Decoder过程,每一个步骤都和之前的输入都没有关系了,只与这个传入的state有关。Attention机制的引入之后,Decoder根据时刻的不同,让每一时刻的输入都有所不同。简而言之,使用Attention机制的Seq2Seq模型可以更好的把握文本的整体意向[8]。具有注意机制的Seq2seq模型如图4所示。
其中ci的计算公式如方程(1)。
在预测时刻输出时,Attention结构会将每个输入与当前时刻的输出匹配,然后自动计算每个注意概率的分布值。αij的计算公式如方程(2),sj表示输入部分中隐藏神经元的激活值。
2.3.1 RNN-based
RNN是比较早期的循环神经网络,结构相对简单,其结构如下图所示:
Encoder-Decoder结构中以RNN(Recurrent Neural Network,循环神经网络)神经单元作为基本单元。
2.3.2 LSTM-based
传统的循环神经网络 RNN 容易出现梯度消失与梯度爆炸的问题,因此目前比较常用的一般是 LSTM 及其变种。Encoder-Decoder结构中以LSTM(Long Short-Term Memory,长短期记忆网络)神经单元作为基本单元[18]。在使用基于LSTM的Seq2Seq文本摘要生成模型生成文本摘要时,具体过程如下:
(1)首先对文本进行矢量化,并将其输入到模型中;
(2)使用LSTM获得文章的分布式表示;
(3)使用注意机制获得更准确的表达式;
(4)将文章的分布式表达式输入LSTM单元以预测摘要的分布式表达式;
(5)将摘要的分布式表示转换为文本形式以获得摘要。
2.3.3 GRU-based
Encoder-Decoder结构中以GRU(Gate Recurrent Unit,门控循环单元)作为基本单元,GRU是LSTM的一种变种,结构比LSTM简单一点。GRU 只有两个门 (更新门update,重置门reset)。
2.4构建分层Attention机制的Seq2seq模型
字词作为文章的基本组成单元,通过普通的注意力机制能够较好的体现出文章中不同的字词对于文章的重要性,但是句子同样作为文章的组成部分,仍然值得关注。为了生成质量更高的摘要,在计算字词注意力基础上,引入句子级Attention机制,计算每个句子对于文章的重要性。其结构如图8。
具体来说,表示源文档的上下文向量的计算公式为:
其中,N表示句子个数,M表示句子中的字词数,表示编码部分第j句话中第k个字词的隐藏状态,表示第j句话中第k个字词的注意力权重。计算公式为:
2.5经典模型
(一)TF-IDF词频统计[19]
①关键词提取:
对每一篇短文进行分词,除去文章的停用词,例如“的”、“是”和“在”等毫无帮助却最常见的词和一些标点符号,进而构建一个词库。如果某个词很重要,那么它应该多次出现在这篇文章,因而要统计词频TF:
即为第i个单词出现在第j篇文章的次数。
然而,有的单词在所有的文档中出现的次数都多,这就不一定是必须的关键词;有的单词在所有文档中出现的次数少,但在这篇文章出现的次数较多,可能恰好反应了这篇文章的主题,正是这篇文章所需要的关键词。对此,引入了逆文档频率IDF:
其中分子为语料库的文档总数,分母为包含第i个单词的文档数加上偏置项1。
综合考虑词频和逆文档频率,TF-IDF统计量可定义为两者相乘,即:
TF-IDF=TF×IDF
②基于TF-IDF的文本摘要提取
首先将短文进行分词,然后去掉停用词,计算出每个词语的TF-IDF值并找出关键词,将短文中距离相近(一般为4或5)的关键词分为一类,找出包含分支最高的类的句子,然后将他们合在一起,即构成文本的摘要。
(二)Textrank算法[20]
Textrank算法的模型可以简单表示为一个有向权图G=(V,E),由点集合V个边集合E组成,Textrank算法的计算公式为:
①Textrank关键词提取
(1)把短文按照完整文本进行分割
(2)对于分割的句子进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词等。
(3)构建候选关键词图G=(V,E),其中V为节点集,由生成的候选关键词组成,然后采用共线关系构造任意两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
(4)根据得分公式,迭代传播各个节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
(6)由上述得到最重要的T个单词,在原短文中进行标记,若形成相邻词组,则组合成多次关键词。
②基于Textrank的自动文摘
基于Textrank的自动文摘属于自动文摘,通过选取短文中重要度较高的句子形成文摘。
(1)预处理:将短文内容分割成句子得
构建图G=(V,E),其中V为句子集,对句子进行分词、去除停用词得:
其中,是保留后得候选关键词。
(2)句子相似度计算:构建图G中得边集E,基于句子间得内容覆盖率,给定两个句子
利用如下公式计算:
若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将他们连接起来,即边的权值
(3)句子权重计算:根据公式,迭代传播权重计算各句子的得分;
(4)抽取文摘句:将(3)得到的句子得分进行倒序排序,抽取重要度最高的T个句子作为候選文摘句。
(5)形成文摘:根据字数或句子数要求,从候选文摘句中抽取句子组成文本摘要。
3 實验
首先,文本收集。获取LCSTS数据集用于模型训练。利用Python抓取环球网、南方都市报、中国新闻网等网站新闻的标题与内容数据作为测试数据。
第二步,文本处理。对爬取的数据进行预处理,文本清洗与分割,结构划分、分词、去除停用词、标点符号,获取词向量并作词频统计等。
第三步,文本分类。使用用主题相似或主题相同的预料进行训练,可以更好、更快地训练出适用的文摘网络,因而,本研究在训练网络前先对文本进行主题分类。尝试多种文本的分类算法,如传统的文本分类算法朴素贝叶斯,K最近邻,支持向量机,如机器学习TextCNN、FastText、RCNN等文本的分类算法,对它们的分类结果做比较,选取最适合的文本分类算法进行分类,分类完的原始数据用于下一步的研究。
第四步,摘要生成。用训练好的模型对文本数据做摘要生成处理。首先用基于深度学习的方法,在Seq2Seq框架下,加入句子级Attention机制,分别用RNN,LSTM,GRU神经网络模型对文本提取摘要;然后用传统的TF-IDF词频统计、Textrank算法对文本提取摘要。具体实验设置:首先使用两个双向RNN(LSTM,GRU),cell大小为256,embedding嵌入尺寸为128,embedding是从头开始训练的,不使用与训练的,embedding。我们使用批处理填充和动态展开在LSTM中处理可变的序列长度,每一个batch的大小为16。训练时使用Adagrad优化器,学习率设置为0.15。
第五步,模型比较。以下是随机选取的一则新闻利用训练好的模型进行摘要生成的结果,新闻内容如下:
山东省有关部门在6月11日和12日就媒体报道部分果农使用违禁药袋问题回应称已派出调查组调查栖霞、招远有果农使用药袋套苹果一事。早在2018年9月底,山东省农业厅就得知有果园使用药袋套果实并进行过抽检。
结果如下:
第六步,效果评价与模型优化。构建效果评价指标,对于评估,我们使用了(Lin和Hovy,2003)提出的Rouge评价指标[21]。与包含各种n-gram匹配的BLEU不同,有几种不同匹配长度的ROUGE度量方法:ROUGE-1、ROUGE-2和ROUGE-L。
在测试集中随机选取200个样本进行测试,并将三种基于深度学习模型的预测摘要与参考摘要进行对比。根据Rouge-L计算公式,得到评价值,得到的结果如下表所示:
根据评测结果对模型进行微调改进。把调试好的模型运用于新抓取文档自动摘要生成。对文本生成效果做出预判,并与传统的提取方法做比较。对算法做优化,对产生的摘要进行一定的数据平滑和修正,构建最优生成模型最后以一定的用户界面形式将提取的内容显示出来。
将Seq2Seq+Hierarchical Attention+basedGRU模型,设置了100次迭代,得到训练集与测试集的模型损失函数如图9所示,从图中看来这一个模型收敛效果较好。
4 结语
本文通过对生成式文本摘要的研究,针对中文中长文本的摘要生成问题,使用LSCTS数据集,并在该数据集上采用基于神经网络的方法,用Python抓取环球网、南方都市报、中国新闻网等网站新闻的标题与内容数据作为测试数据取得了良好的效果。在编码器和解码器中分别使用了RNN、LSTM、GRU,以充分利用上下文信息来理解语义特征,并且在LSCTS数据集上进行训练。并与传统的TF-IDF、Texrank模型进行比较和分析。我们最终得出结论:在中长文本摘要生成中,加入分层注意力机制的GRU+Seq2Seq模型具有更高的ROUGE指数值,表明这个方法可以保留核心信息,过滤辅助信息与真实摘要的相似度更高,预测摘要更准确、更真实。但这只是一个深入模型的开始,还有很大的改进空间。
参考文献
[1]Edmundson,H P.New Methods in Automatic Extracting[ j] . Journal of the ACM,1969,16(2):264
[2]Kupiec,J,Pedersen,J,Chen,F. A Trainable Document Summarizer[C]. ACM SIGIR New York USA,1995
[3]Lin CY. Training a Selection Function for Extraction[C].the Eighth ACM Conference on Information and Knowledge Management,Kansas City,Missouri,USA,1999
[4]Conroy J M,O'leary D P. Text Summarization Via Hidden Markov Models[C].ACM SIGIR New Orleans,Louisiana,USA,2001
[5]Rada Mihalcea.Graph-based Ranking Algorithms for Sentence extraction,Applied to Text summarization [C].the ACL 2004 on Interactive Poster and Demonstration Sessions.Barcelona,Spain,2004
[6]Lin,Junyang,et al. “Global Encoding for Abstractive Summariza- tion.” ACL 2018:56th Annual Meeting of the Association for Computational Linguistics,vol. 2,2018,pp. 163-169.
[7]Sutskever,Ilya,et al. “Sequence to Sequence Learning with Neural Networks.” Advances in Neural Information Processing Systems 27,2014,pp. 3104–3112.
[8]Abigail See,Christopher Manning,and Peter Liu. Get to the point:Summarization with pointer generator networks. In Association for Computational Linguistics. 2017. https://arxiv.org/abs/ 1704.04368.
[9]Bahdanau,Dzmitry,et al. “Neural Machine Translation by Jointly Learning to Align and Translate.” ICLR 2015:International Conference on Learning Representations 2015,2015.
[10]Arman Cohan Franck Dernoncourt,et al. A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents. 2017. https://arXiv:1804.05685v2
[11]Hu,Baotian,et al. “LCSTS:A Large Scale Chinese Short Text Summarization Dataset.” Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing,2015,pp. 1967–1972.
[12]Peters,Matthew E.,et al. “DEEP CONTEXTUALIZED WORD REPRESENTATIONS.” NAACL HLT 2018:16th Annual Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,vol. 1,2018,pp. 2227–2237.
[13]Radford,A. & Salimans,T. Improving Language Understanding by Generative Pre-Training. (2018)
[14]Yang Liu,Mirella Lapata.Text Summarization with Pretrained Encoders. 2019. https://arXiv:1908.08345v2
[15]Jingqing Zhang,Yao Zhao,et al. PEGASUS:Pre-training with Extracted Gap-sentences for Abstractive Summarization. LCML 2020.
[16]Radford,A. & Salimans,T. Improving Language Understanding by Generative Pre-Training. (2018)
[17]Vaswni,Ashish,et al. “Attention Is All You Need.” Proceedings of the 31st International Conference on Neural Information Processing Systems,2017,pp. 5998–6008.
[18]Hochreiter,Sepp,and Jürgen Schmidhuber. “Long Short-Term Memory.” Neural Computation,vol. 9,no. 8,1997,pp. 1735–1780.
[19]Jia,LV. “Improvement and Application of TFIDF Method Based on Text Classification.” Computer Engineering,2006.
[20]Mihalcea,Rada,and Paul Tarau. “TextRank:Bringing Order into Texts.” Proc. 2004 Conference on Empirical Methods in Natural Language Processing,Barcelona,Spain,July,2004,pp. 404–411.
[21]Chin-Yew Lin and Eduard H. Hovy. 2003. Automatic evaluation of summaries using n-gram cooccurrence statistics. In Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics,HLTNAACL 2003,Edmonton,Canada,May 27 - June 1,2003 評价指标
