基于电子舌和EEMD-WOA-LSSVM模型的红酒贮藏年限区分
2021-10-29王首程李庆盛高继勇于雪莹王志强山东理工大学计算机科学与技术学院山东淄博255049
缪 楠,张 鑫,王首程,李庆盛,高继勇,于雪莹,王志强(山东理工大学计算机科学与技术学院,山东淄博 255049)
红酒是一种以新鲜葡萄或葡萄汁为原料酿制的酒精饮品,其内部富含多糖、多酚、有机酸和多种氨基酸,具有抑瘤抗癌、延缓衰老等功效[1]。红酒品味和质量会随着贮藏年限的变化而有所区别。红酒的贮藏年限快速鉴别是目前生产厂家和消费者非常关注的技术难题[2]。目前,红酒贮藏年限分析方法主要有感官分析法和仪器分析法等[3]。感官分析法主要依靠品鉴师的视觉、味觉、嗅觉等感官进行判断,但该方法受人的主观因素和环境因素影响较大。常用的仪器分析法包括液相色谱-串联质谱法、等离子体发射光谱法和原子吸收光谱法等[4−6],但此类分析仪器价格昂贵、体积大、操作过程繁琐,无法满足检测分析的需求[7]。电子舌是一种利用传感器阵列结合模式识别技术对液体样本的“指纹图谱”进行分析的仪器,具有操作简单、成本低廉、客观高效等特点[8],近年来已被广泛应用于食品质量分析、产品溯源、掺假辨别等多个领域[9−11]。模式识别是影响电子舌检测性能的关键技术,其过程主要包括特征提取和分类识别两个阶段。目前,常用的电子舌信号特征提取方法主要有极值点法(FPE)[12]、主成分分析(PCA)[13]、快速傅里叶变换(FFT)[14]、小波变换(WT)[15]等。但此类方法在对原始信号进行处理时,仅能挖掘和利用“指纹图谱”的局部信息,容易造成特征信息的丢失[16]。集合经验模态分解(EEMD)是根据经验模态分解(Empirical mode decomposition,EMD)进行改良的新型信号处理方法。EEMD 通过向原始信号添加白噪声,可以显著地减少EMD 方法中存在的模态混叠现象,从而实现对非线性、非平稳信号的自适应时频域分析,且具有较高的信噪比和时频聚焦特性[17],但目前尚未有报道将EEMD 应用到电子舌信号分析领域。
基于提取的特征,选用合适的分类识别算法是电子舌模式识别研究的另一个重点。史庆瑞等[15]利用BP 神经网络(BPNN)对中成药的品种进行辨识。国婷婷等[18]利用极限学习机(ELM)对5 种年限的小麦进行了识别和分类。Shi 等[19]利用随机森林(RF)建立了一种对不同年限陈皮区分的判别模型。但这些方法通常需要人工调整工作参数,很难达到最优性能[20]。最小二乘支持向量机(LSSVM)是在支持向量机(SVM)基础上遵循结构风险最小化原则的机器学习算法,其模型具有训练效率高、泛化能力强、辨别精度准确等特点[21]。LSSVM的惩罚系数和核函数宽度是影响模型性能的关键[21],传统方法主要采用人工比对法确定,很难达到全局最优。近年来,研究人员为确定LSSVM 模型的参数分别尝试采用粒子群优化算法[22]、人工鱼群优化算法[18]、遗传算法[20]等优化算法,取得了较为理想的效果。鲸鱼算法是一种受自然集群运动启发的启发式算法,通过模仿鲸鱼的捕猎行为来解决优化问题。与传统群集智能算法相比,鲸鱼算法需要调整的参数较少且更容易跳出局部最优,具有收敛速度快、局部搜索能力强、优化性能好等特点,目前已成功应用于多参数优化问题[23−24]。
本文以4 种不同陈酿年限的红酒为研究对象,利用实验室自主研制的伏安电子舌系统对红酒样本进行辨别分析。针对红酒样本“指纹图谱”信号复杂、数据量大、识别困难的问题,提出基于集合经验模态分解、鲸鱼算法及最小二乘支持向量机的模式识别模型。然后通过实验验证了系统检测结果的准确性和可靠性,该研究可为基于人工智能感官技术的红酒贮藏年限区分提供理论依据和技术支持。
1 材料与方法
1.1 材料与仪器
样品红酒 取自4 种不同陈酿年限市售红酒,如表1 所示,同一年限红酒分别来自不同批次,以确保样本的多样性;纤维滤膜 规格0.45 μm,上海市新亚净化器件厂。

表1 红酒样本Table 1 Red wine samples
电子舌系统 采用自行研制的基于虚拟仪器技术的伏安电子舌系统。
1.2 实验方法
1.2.1 电子舌系统 伏安电子舌系统结构如图1 所示。该系统由传感器阵列模块、信号调理模块、数据采集卡和基于LabView的上位机软件组成。传感器阵列由8 个贵金属工作电极(铂、金、钛、钯、银、钨、镍、玻碳),1 个Ag/AgCl 参比电极和1 个铂辅助电极组成。信号调理模块主要由恒电位电路模块、工作电极多通道切换模块、信号放大电路模块及RC 滤波电路组成。电子舌检测溶液时,利用数据采集卡可产生大幅脉冲伏安信号(Large amplitude pulse voltammetry,LAPV)。该信号通过数据采集卡进行D/A 转换,随后利用恒电位电路传递至传感器阵列。在LAPV 信号的激励下,浸没于被测溶液的工作电极在表面产生微弱的响应电流信号并发生电化学反应,该信号经信号调理电路模块进行数据转换、放大、滤波后,利用数据采集卡对其进行A/D 转换,然后送上位机对其进行模式识别分析。相较于传统的理化分析仪器,伏安型电子舌主要通过施加特定电信号来使溶液中产生离子的移动,通过测量电信号的变化来感知不同样本的指纹信息。

图1 电子舌系统结构图Fig.1 Diagram of electronic tongue system structure
1.2.2 样本数据采集 实验时准确量取10 mL 待测红酒样品,经0.45 μm的纤维滤膜过滤后置于50 mL烧杯中。在室温条件(25 ℃)下,利用电子舌检测并采集数据,每个样本检测4 次,去掉前3 次不稳定数据。每次更换检测样本前,为了避免电极表面残留物影响下次检测,采用Al2O3打磨粉和抛光布对电极进行抛光打磨,并用去离子水对电极进行超声清洗。最终得到400 个实验样本数据,并划分比例为7:2:1的训练集、测试集和验证集。
1.3 数据处理方法
1.3.1 EEMD 分解 集合经验模态分解(EEMD)是Wu 等[17]针对EMD 方法存在的模态混叠现象提出的一种新型信号分析方法。其核心过程是根据白噪声信号在整个时频空间均匀分布的统计特性,将高斯白噪声加入到数据信号中,随后通过不同尺度的分解可得到一组本征模态函数(Intrinsic mode function,IMF)。实验中针对电子舌信号复杂、数据量大的特点,利用EEMD 对电子舌信号进行自适应的时频局部分析,使得到的时间序列具有更强的规律性,从而提取电子舌信号时频域中的有效特征。假设一个时序信号为x (t),EEMD 分解的主要步骤如下:
a.在原始信号 x(t) 中 加入服从 (0,(αε)2)正态分布的白噪声n (t),获得加噪声后信号X (t),即:

b.利用EEMD 对加噪后的信号进行分解,得到多个IMF 分量ci(t)和 一个残余分量RN(t):

c.将均方根相等的不同白噪声序列 ni(t),i=1,2,···,j 附加在每次待分解的信号 x(t)上,对b,c 重复j次,可得到对应的IMF 分量cij(t):

d.为消除因多次添加白噪声信号对实际IMF 产生的干扰,平均计算各IMF 分量cij(t)的数值,最终可得本征模态函数:

1.3.2 奇异谱熵和边际谱 奇异谱熵分析是一种时域信号分析方法,可根据原始信号的时间序列在相空间进行构造展开,随后通过分解、重构得到原始信号中对应的时域特征[16]。希尔伯特边际谱可体现原始信号在每一个瞬时频率点上的幅值分布情况,并能够反映信号中的频域特征,目前已成功用于光电容积脉搏波信号频域[25]。故本文分别提取本征模态函数的奇异谱熵和边际谱作为电子舌信号的特征信息,奇异谱熵的计算步骤如下:
a.将K 个IMF 分量组成一个模态矩阵:

b.将所得矩阵A 进行奇异值分解,可获得对应的矩阵奇异谱λ1,λ2,···,λk。奇异值描述信号各频段的特征,在此基础上,引入信息熵理论,构造信号的奇异谱熵:

希尔伯特边际谱计算过程如下:
d.对所有EEMD 分解获得的有效IMF 分量cj(t)进行希尔伯特变换得H [Cj(t)],之后构造解析信号:

e.计算所得解析信号的瞬时幅值和瞬时频率:

f.组合上述公式(9)(10)得到希尔伯特谱 H [f,t],对时间积分可得希尔伯特边际谱:

1.3.3 最小支持二乘向量机(LSSVM) 最小二乘支持向量机(LSSVM)是一种遵循结构风险最小化原则的核函数机器学习算法。LSSVM 通过引入平方项的方法,使其目标函数的约束从不等式变为等式,将二次规划问题转化为线性方程组进行求解[21]。实验中使用LSSVM 模型对电子舌特征数据进行识别分类。LSSVM 模型建立过程如下:
a.采用函数 f(x)将原始信号映射到高维特征空间,开始构造最优的线性函数:

式中 ω为高维特征空间的权向量,b为偏差变量。
b.遵循结构风险最小化原则,将LSSVM的优化目标表示为:
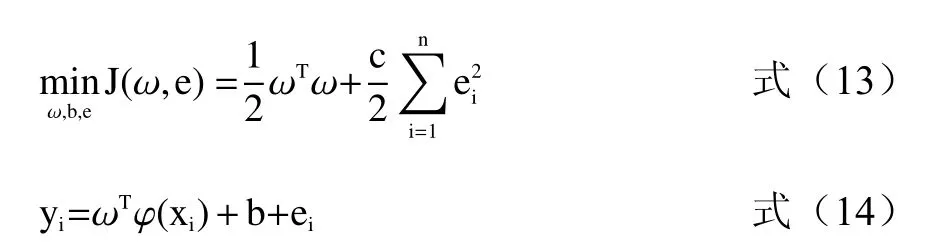
式中,ei为误差变量。
c.为解决优化目标问题,构建Lagrange 函数:

式中,i为Lagrange 乘法算子。
d.然后根据KKT 条件求解得到b,并最终得到优化函数为:

e.实验设置K (xi,xj)为径向基核函数:

根据式(13)和式(17)可知,惩罚系数c 和核函数宽度 σ为LSSVM 模型的2 个待优化参数。故上述参数组合可对LSSVM 模型的准确度和鲁棒性产生影响。
1.3.4 鲸鱼算法(WOA) 鲸鱼算法(WOA)是一种基于模仿鲸鱼的捕食行为来构建模型的集群优化算法。在鲸鱼算法中,将鲸鱼的整体狩猎行为分成三个阶段:包围猎物、狩猎猎物和搜寻猎物,其行为如图2所示。实验中,利用鲸鱼算法对LSSVM 模型的惩罚系数c 和 核函数宽度σ 进行参数优化。将上述参数组合作为优化目标,根据鲸鱼狩猎行为,迭代寻找最优鲸鱼位置,从而得到最佳参数组合。

图2 座头鲸狩猎行为Fig.2 Feeding behavior of humpback whale
a.包围猎物:
假设当前气味所反映的猎物位置是最佳位置,并定义一定种群数量的座头鲸,让每个座头鲸包围猎物,更新每个座头鲸的位置向量,之后对各个更新位置进行收缩环绕,最终达到局部最优位置,利用数学公式对上述行为进行描述:


式中,t 表示当前迭代次数,X∗(t)表示目前最优的位置向量,X (t)表 示当前鲸鱼位置向量,A和 C表示两个控制系数向量,D 为位置衡量系数。
b.狩猎猎物:
鲸鱼主要是通过螺旋向上的运动方式对猎物进行捕食,可通过数学方程对其进行描述:

其中,Dp表示鲸鱼当前位置和猎物位置之间的距离,X∗(t)表 示目前最优的鲸鱼位置,b 为定义对数螺旋形状的一个常数,l是(−1,1)中任意数。
在狩猎过程中,鲸鱼同时采用收缩环绕和螺旋方式进行位置更新。因此,设置阈值Pi决定不同的方式来更新下一代位置,其数学模型如下:

c.搜索猎物:
在搜索猎物过程中,通过不断更新局部最优位置,最终达到全局最优,其数学模型表示为:

其中,Xrand是随机选择的鲸鱼位置向量,通过控制向量系数A的绝对值来设定算法的位置更新方式。
1.3.5 WOA-LSSVM 模型构建 利用WOA 算法对LSSVM 参数组合进行优化,具体流程步骤如图3 所示:

图3 鲸鱼算法优化最小二乘支持向量机流程图Fig.3 Flow chart of optimization least square support vector machine by improved whale optimization algorithm
a.设置初始化参数,优化迭代次数Tmax和鲸鱼种群大小SN。
b.选取SN个鲸鱼作为初始种群,并计算出所有鲸鱼的适应度值大小。
c.根据步骤b 计算出每个鲸鱼的适应度值,选取适应度值最小的鲸鱼位置作为当前个体最优位置。
d.鲸鱼群中的其他鲸鱼,根据整体狩猎行为,全局搜索最优鲸鱼的位置。当A ≥1时,采用式(23)通过搜索行为来更新鲸鱼位置,若A <1,则采用公式(21)根据收缩环绕方式更新下一代鲸鱼的位置。
e.迭代终止条件判断。检查目前的迭代次数是否达到Tmax,若已达到,则停止迭代,输出当前最优位置,通过参数解码可得最佳的LSSVM 参数组合。若未达到,则转至步骤d,继续寻找最优位置。
2 结果与分析
2.1 电子舌响应信号
图4 为铂、金、钛、钯、银、钨、镍、玻碳工作电极得到的红酒样本响应信号。可以看出,不同的工作电极对不同贮藏年限的红酒响应信号有着明显差异。经实验验证分析,使用上述电极可以较为全面反映红酒样品的“指纹图谱”。经检测,每个样本采样可得8000 个原始数据点,则4 种年限的红酒样本最后得400×8000的数据矩阵。

图4 电子舌对红酒样品的响应信号Fig.4 Electronic tongue response signal of red wine
2.2 数据预处理
2.2.1 EEMD 信号分解 针对电子舌响应信号,实验采用EEMD 算法进行分解。初始化参数,设置白噪声幅值为0.2,执行次数为100,分解结果如图5 所示。经EEMD 分解的样本原始信号可得到多个IMF分量和一个RES 残余分量。从图5 可以看出,IMF1~IMF5 突变性强,频率较高且波形复杂,呈现出明显的多尺度特征。从IMF6~IMF9 分量开始,整体信号趋缓,变化幅度较小,分量的规律性比IMF1~IMF5更强,但是波动的周期并不稳定,表明上述分量主要体现信号的大体趋势。

图5 原始信号EEMD 分解结果Fig.5 EEMD decomposition results for original signal
2.2.2 IMF 奇异谱熵与边际谱 对原始信号经EEMD分解的1~9 阶IMF 分量,利用奇异谱熵法进行特征选择。依据实验经验,设定分段长度L =3000,奇异谱熵值分布情况如图6 所示。由奇异谱熵分布可知,奇异谱熵峰值随着分解次数的增加而逐渐减小,说明其包含的特征信息也逐渐减少。由于IMF9 分量的熵值变化微小,故选择1~8 阶IMF 分量的奇异谱熵值作为电子舌信号的特征向量[26]。

图6 不同红酒的IMF 奇异谱熵分布Fig.6 IMF singular spectral entropy distribution of different red wine
对1~8 阶IMF 分量进行希尔伯特变换,可得如图7 所示的希尔伯特边际谱。由图7 可知,4 种红酒的希尔伯特边际谱总体变化趋势大致相似,即在10 Hz 左右均有较为明显的凸起变化,且在30 Hz 左右有凸起变化。其中2 年样本在0~10 Hz 内有2 次凸起,但4 种红酒样本的最大幅值存在明显区别。而幅值的大小可体现出信号时频分布的能量特征,由于边际谱的幅值变化主要集中在0~50 Hz的区间范围内,故根据希尔伯特边际谱理论,选取边际谱中的前50 个值作为特征向量[27]。最终单个红酒样本可得到58 个特征向量。

图7 红酒信号的希尔伯特边际谱Fig.7 Hilbert marginal spectrum of red wine signals
2.3 基于EEMD-WOA-LSSVM的红酒贮藏年限定性分析
采用EEMD-WOA-LSSVM 模型,对4 个不同年限的红酒进行分类。训练集、测试集和验证集比例设置为7:2:1,将EEMD 分解后得到的奇异谱熵和边际谱作为特征数据输入WOA-LSSVM 模型中进行判别分析。采用鲸鱼算法优化LSSVM 模型参数,设定鲸鱼群种群规模 N=150,迭代次数最大值Tmax=100,根据收敛速度和迭代效果对算法进行评估。图8 为以均方根误差作为评价标准的优化迭代收敛曲线。由图8 可知,鲸鱼优化算法在迭代前期,模型均方误差随着迭代次数的增加迅速下降,并在25 次左右逐渐趋于恒定值。此时可得LSSVM 最佳参数组合惩罚系数 c=71.1582,核函数宽度σ=239.2288,且均方根误差仅为0.0905。为了对比分析,同时采用粒子群算法[22](Particle Swarm Optimization,PSO)和遗传算法[19](Genetic Algorithm,GA)对LSSVM 惩罚系数和核函数宽度参数组合进行优化,从图8 可以看出,GA 和PSO 算法在收敛速度和最终收敛效果上,均劣于WOA 算法。

图8 三种集群算法优化LSSVM 参数的对比曲线Fig.8 Three clustering algorithms optimization LSSVM parameter optimization iteration
实验采用测试集对EEMD-WOA-LSSVM 模型评价分析,可得混淆矩阵如图9 所示。图中混淆矩阵的横坐标为样本预测类别,纵坐标为样本实际类别。由图9 可知,在测试集样本中1 年和6 年贮藏红酒样本均无混淆现象,有1 个2 年贮藏红酒样本被错分为1 年样本。在4 年贮藏红酒样本中,有2 个样本被错误分类。模型测试集样本的平均分类准确率达到96.25%,表明EEMD-WOA-LSSVM 模型可对不同贮藏年限的红酒进行良好的辨别区分。

图9 EEMD-WOA-LSSVM 模型测试集样本混淆矩阵Fig.9 Confusion matrix of EEMD-WOA-LSSVM model on test set
2.4 模型验证
为进一步验证本文提出算法的优越性,以验证集中预处理后的特征数据为输入数据,分别选择SVM、LSSVM 和相同初始参数值下的PSO-LSSVM、GA-LSSVM 模型进行对比分析。分别采用精确率(Precision)、召回率(Recall)、F1-Score 和Kappa 系数评估各个模型的鲁棒性和辨别能力,其评判标准指标定义如下:

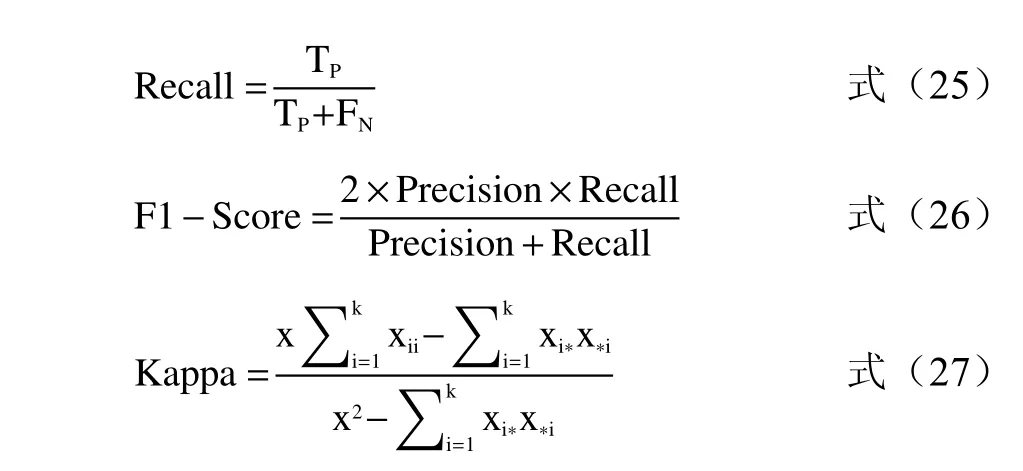
上述公式中,TP为 真实的正样本数量;FP为真实的负样本数量;FN为 虚假的负样本数量。x为验证样本的总数;xi∗和 x∗i分 别为结果中第i类样本的总样本数和测试集样本中第i 类样本的总样本数;xii为矩阵中第i 行 i 列 中的样本数,代表第i类样本中正确分类的样本数;k 为分类的类别数。
表2 为各模型对4 种不同贮藏年限红酒的分类性能统计。精确率代表被所有预测为正的样本中实际为正样本的概率。召回率代表在实际为正的样本中被预测为正样本的概率。而F1-Score 和Kappa系数是衡量模型准确度的两个参数标准。结果表明,LSSVM 分类性能优于SVM,其准确率、精确率、召回率、F1-Score、Kappa 系数分别提高了5%、5.5%、5%、0.05、0.06。这是由于LSSVM 使用了平方差损失函数,将等式约束代替不等式约束,从而提升了模型的分类精度。与未优化的LSSVM 相比,经过GA、PSO、WOA 集群算法优化的LSSVM 效果更好,其准确率提高了2.5%~10%。在三种优化算法中,WOA 表现出比GA 和PSO 更好的优化性能,这是由于鲸鱼优化算法具有良好的寻优能力,使得收敛速度和收敛精度得到了较大幅度的提升,避免了传统集群优化算法的早熟现象、易陷入局部最优等现象。

表2 各模型分类结果Table 2 Model classification results
3 结论
研究采用伏安电子舌对不同贮藏年限的红酒进行辨别分析,针对电子舌信号数据量大、复杂的特点,提出一种基于EEMD-WOA-LSSVM的组合模式识别模型。采用EEMD 对红酒电子舌信号进行多尺度分解,得到多个IMF 函数并选取对应的奇异谱熵和希尔伯特边际谱作为特征向量。同时为解决LSSVM 模型参数选择的盲目性问题,提出了利用WOA 对LSSVM 模型参数进行寻优,有效的提高了模型的辨别准确度。实验结果表明,利用电子舌结合EEMD-WOA-LSSVM 模型各项精度评价指标比其他模型更高,其准确率、精确率、召回率、F1-Score、Kappa 系数分别为97.5%、97.75%、97.5%、0.98 和0.97,能够很好地区分4 种不同贮藏年限的红酒。该研究将为红酒贮藏年限区分提供一种新的研究思路和技术手段。
