母亲妊娠高血压对子代儿童期血压影响的队列研究
2021-10-22王倩倩梁小华
王倩倩 彭 鈊 张 敏 唐 娴 梁小华

1 方法
1.1 研究设计 回顾性队列研究。利用本课题组2014至2016年在重庆市建立的儿童队列(简称队列)研究人群[5],在队列人群中进行问卷调查,根据问卷调查结果,将母亲孕期有妊娠高血压的儿童定义为暴露组,匹配母亲孕期无妊娠高血压的儿童为非暴露组,比较两组儿童的血压水平和高血压患病率,分析妊娠期高血压对子代儿童期血压的影响。
1.2 伦理学和知情同意 队列研究获得重庆医科大学附属儿童医院(我院)伦理评审委员会的审批(审批号:066/2012)。队列中的儿童及其监护人均签署了书面知情同意书。
1.3 调查问卷 在基线调查时,对队列人群先后做了3份调查问卷,①健康信息调查表(家长和参与研究的工作人员共同完成),②儿童体格检查信息登记表(体检由护士完成),③儿童膳食睡眠与运动及行为健康评价量表(家长和医生共同完成)。本文截取数据来源于上述3个调查表,包括儿童年龄、性别、出生体重,父亲受教育程度,父母职业,家庭收入,城乡地区,是否母乳喂养,母亲是否曾患有妊娠高血压,父母身高、体重,儿童身高、体重、腰围、心率和血压测量结果。
1.4 母亲妊娠高血压判断 首先基于儿童膳食睡眠与运动及行为健康评价量表中怀孕期间母亲是否患有高血压“是”的选项,再与母亲电话确认,不能确认者在当地妇幼保健院的孕产妇健康管理系统的电子病历系统中查询确定。
1.5 暴露组儿童纳入和排除标准 ①母亲怀孕期间患有高血压的6~12岁儿童;②现居住地居住时间>6个月;③未服降压药 ;④排除患有严重肾脏疾病、糖尿病、先天性心脏病、内分泌疾病或继发性高血压。
1.6 非暴露组匹配原则 在统计软件中设定匹配的条件(性别比例相差±2.5%、年龄±0.5岁、BMI±0.5 kg·m-2)按照1∶4比例于非暴露儿童中随机抽取。
1.7 样本量计算 采用以下公式进行计算: N=2×[(Zα+Zβ)σ/δ]2,其中Ⅰ类错误的概率α=0.05,检验效能1-β=0.8, 容许误差δ= 1.5 mmHg, 标准差σ=10 mmHg。计算暴露组需样本量302例,非暴露组为1 208例。
1.8 体格检查 由我院经过统一培训的的护士完成,检查时间为上午9:00~11:00,采用统一标准测量,即受试者空腹、脱鞋、脱帽,穿贴身衣物。①身高和体重:采用超声波(型号:WS-H300D)身高体重测量仪连续测量2次(测量值数据精确至1位小数),如果身高的2次测量结果相差>0.1 cm ,检查测量误差原因,行校正后再测量1次,并取最相近2次的均值。以同一次测得的身高和体重数据计算BMI,取2次BMI的均值。②测量腰围时儿童直立,双脚并拢,放松腹部,皮尺置于腋中线最低肋骨下缘与髂棘连线中点的水平面,于呼气末、未吸气状态时测量[6],同种方法测量3次(测量值数据精确至1位小数),取其平均值。
1.9 血压和心率测量 血压测量均由测量人员穿便装在学校完成。测量工具为欧姆龙(HEM7051)上臂式电子血压计,该款血压计可同时测量并显示脉率,操作遵循中国高血压防治指南(2010)的要求。血压同日重复测量3次,取平均值,如3次血压波动>5 mmHg,行第4或5次测量(去除变异最大的1次或2次测量值),保留3次测量波动<5 mmHg的值,取平均值;若血压超出正常范围,在2~4周后重新进行测量,测量方法同前所述。非同日2次血压值均符合高血压诊断标准,判断为高血压[7~8]。脉率取3次均值。
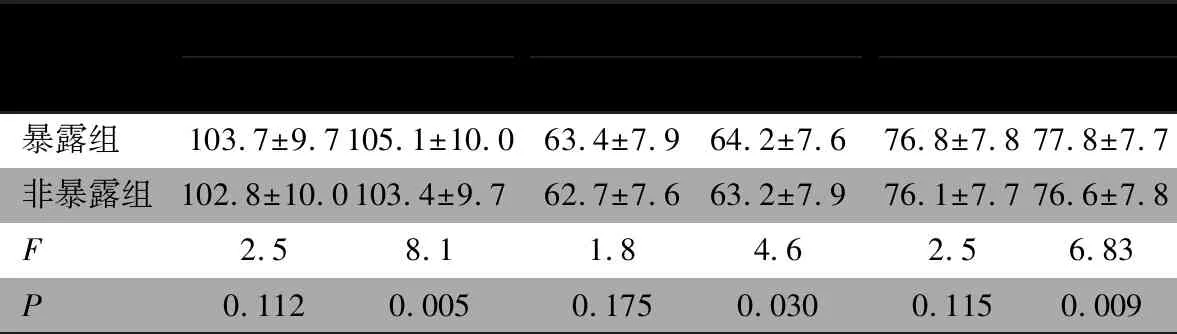
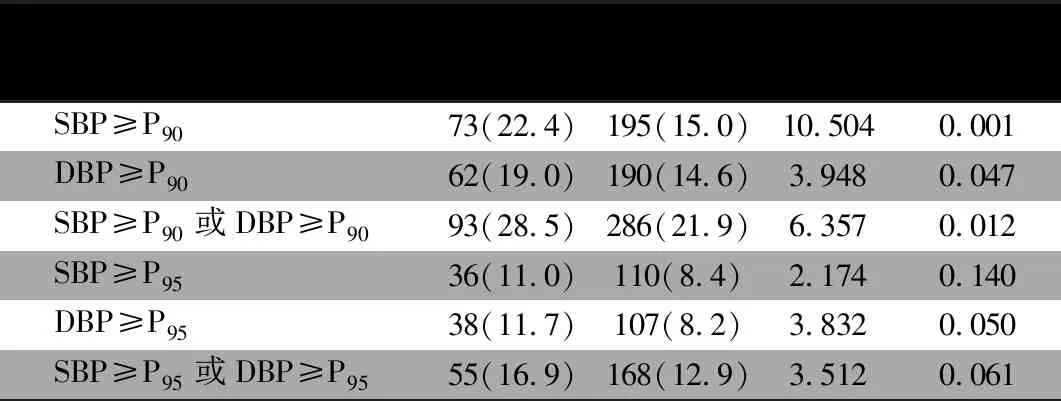
1.10 儿童高血压的诊断标准 根据文献[9]的血压诊断标准,分年龄别、性别别与身高别的收缩压与舒张压分别取P90~ 1.11 统计学方法 数据录入采取双人双机录入模式,采用Microsoft Access数据库进行录入,并对录入的数据进行一致性核对。数据统计分析使用SAS 9.4软件。采用Z评分法计算年龄别BMI-Z值[10]。正态分布的定量资料以mean±SD进行统计描述,组间比较采用t检验。偏态分布的定量资料以(M,IQR)描述,组间比较采用秩和检验。计数资料以n(%)表示,组间比较采用χ2检验或Fisher精确检验。采用协方差分析比较两组间血压指标的差异。采用Logistic回归模型分析妊娠高血压是否增加儿童期高血压的患病风险。以P<0.05为差异有统计学意义。 2.1 一般情况 队列人群18 054例,进入本研究暴露组儿童326例,匹配非暴露组1 304例;男童820例,女童810例,年龄6.0~12.8(9.1±1.7)岁。表1显示,暴露组母亲肥胖、家庭收入、母乳喂养、儿童年龄、儿童身高与非暴露组差异有统计学意义。 2.2 妊娠高血压对子代血压水平的影响 表2显示,校正了年龄、性别、家庭收入、母亲肥胖、母乳喂养、出生体重、现体重、心率和肥胖因素,暴露组儿童的收缩压[(105.1±10.0)vs(103.4±9.7)mmHg]、舒张压[(64.2±7.6)vs(63.2±7.9) mmHg]、平均动脉压[(77.8±7.7)vs(76.6±7.8) mmHg]均高于非暴露组,差异均有统计学意义。 表3显示,暴露组高血压前期和高血压患病率高于非暴露组,差异有统计学意义(收缩期:22.4%vs15.0%,P=0.001;舒张期:19.0%vs14.6%,P=0.04;收缩期或舒张期:28.5%vs21.9%,P=0.012)。暴露组高血压患病率均高于非暴露组,但差异无统计学意义(收缩期:11.0%vs8.4%,P=0.140;舒张期:11.7%vs8.2%,P=0.050;收缩期或舒张期:16.9%vs12.9%,P=0.061)。 将基线变量(包括儿童年龄、性别、家庭收入、母亲肥胖、母乳喂养、出生体重、现体重、心率和是否肥胖)纳入Logistic回归模型校正后,模型1纳入年龄和性别;模型2在模型1基础上增加了单因素分析,显示与儿童高血压有显著相关的变量,包括母亲肥胖、家庭收入和母乳喂养;模型3在模型2基础上增加了研究对象本身健康和体检相关变量(排除了共线性变量后,包括出生体重、现体重、心率和肥胖)。表4显示,收缩期高血压前期和高血压在模型3中OR=2.0、收缩期高血压和和舒张期高血压前期在模型3中OR分别1.66和1.56、收缩期或舒张期高血压前期和高血压OR=1.68、收缩期或舒张期高血压仅在模型3中OR=1.66,差异均有统计学意义。暴露组收缩期高血压风险和收缩期或舒张期高血压风险,均是非暴露组的1.66倍(95%CI:1.06~2.62,P=0.028;95%CI:1.13~2.43,P=0.009)。 表1 暴露组与非暴露组儿童人口统计学、父母信息以及体格检查情况 表2 暴露组和非暴露组儿童校正前后的血压情况(mean±SD,mmHg) 表3 暴露组与非暴露组子代高血压的发生情况比较(n,%) 表4 妊娠高血压对子代高血压风险的Logistic回归分析 本研究发现,暴露组与非暴露组儿童家庭收入差异有统计学意义。也有研究发现,家庭收入低与儿童高血压风险增加有关[13]。家庭收入是社会经济地位和生活质量的体现,高收入家庭可能受到更良好的教育或有更健康的生活方式。经过Logistic回归分析校正家庭收入后,妊娠高血压仍然是子代高血压的独立危险因素。有研究表明,肥胖的家族相关性可能在一定程度上解释了妊娠高血压与子代高血压的关系[2]。然而,在本研究中调整子代是否肥胖后,阳性关联仍然存在。因此,妊娠高血压为儿童期血压水平升高的独立危险因素。 本研究数据资料来自6~12岁儿童队列研究的随访过程,体格及血压资料均来自现场测量,测量值为经过培训合格后的护士,数据真实可靠。 本研究局限性:①样本抽样均来自重庆市社区,结论不一定适用于其他地区人群;②回顾性队列设计,母亲妊娠高血压是在儿童队列研究调查时通过问卷获得,调查时距离妊娠期时间较长,调查对象对妊娠高血压可能有回忆偏倚;③受调查问卷设计的限制,本研究母亲妊娠高血压与子代血压的影响因素不够全面;④本研究中儿童血压为非同日2个时点确定,很可能会有一些假阳性病例。2 结果


3 讨论
