高性能流场并行粒子追踪数据管理系统
2021-10-20杨昌和李彦达张江王昉袁晓如
杨昌和,李彦达,张江,王昉,袁晓如,*
1.北京大学 信息科学技术学院 机器感知与智能教育部重点实验室,北京 100871
2.北京大学 大数据分析与应用技术国家工程实验室,北京 100871
3. 北京大学,北京 100871
4. 中国空气动力研究与发展中心 计算空气动力研究所,绵阳 621000
随着科学、工程、生物医学等领域的不断发展,研究者们往往需要面对大量基于模拟和观测的科学数据,尤其在空气动力学领域,需要从中发现有意义的规律。科学数据包括标量场数据和矢量场数据,通常具有时变、多变量等特性,且体量庞大,特征复杂多变,因而用户直接对于数据本身进行演算和观测十分困难,需要十分庞大的理解代价。在此背景下,科学可视化方法应运而生。科学可视化是可视化研究领域中十分重要的组成部分,该技术赋予了科学数据具体又可操作的直观形态,帮助科学家们在图形世界中直接对信息进行操作和处理,赋予科学家们一种仿真的实时交互能力。科学家们通过对数据进行有效的可视化并分析出其中存在的特征,从而解释现象或者验证假设。
流场可视化是科学可视化中的重要组成部分,能够有效地帮助人们理解现实世界流场数据的复杂现象和动态演变的复杂现象和动态演变,是近年来科学研究中的重点问题,被广泛应用于燃烧、气候、航空等科学模拟和分析。国家数值风洞(NNW)工程[1]针对该方面进行了深入的研究。流场数据可视化方法可以分为4类,即直接可视化方法、基于纹理的可视化方法[2]、基于几何的可视化方法[3]以及特征提取方法[4]。其中,直接可视化和基于纹理的可视化方法分别通过使用箭头等符号形式和条纹状纹理来表示流场,基于几何的可视化方法使用点线面等几何形式对流场进行可视化,特征提取方法则通过提取流场中的重要特征对流场进行探索。在这些方法中,通过粒子追踪生成场线又是一种最基本的技术,其在各种各样的流场可视化和分析任务,特别是基于几何和特征提取的可视化方法中,得到了广泛的应用。
随着科学家通过计算流体学(CFD)等数值模拟方法得到的流场数据愈加复杂多变,传统的流场可视化方法遇到了越来越多的挑战,先进的流场可视化系统的提出成为了十分迫切的需求。纵观流场可视化框架的发展方向,该工作总结出如下两个趋势。一方面,科学家通过数值模拟等方式得到的流场数据规模越来越大,其内部结构也越来越复杂,甚至以几何级数的速度增长,这给流场可视化的计算性能提出了新的考验。现实应用中单台处理机由于内存和计算能力等的限制,很难满足这种大规模粒子追踪的计算需求。而早前研究者所使用的核外(Out-of-core)技术[5-6],也因其I/O瓶颈在大规模流场数据中变得越来越不适用。研究者们考虑粒子追踪生成场线中任务的高度可并行性,采用并行计算模式提升性能,成为了一种十分行之有效的解决方案,基于并行粒子追踪的大规模场线可视化逐渐成为流场可视化的主流趋势。尤其是近年来随着高性能计算技术的发展,研究者可以更多地利用超级计算机或者并行计算集群等强大的计算资源来进行并行计算,有效地提升了计算结果产出的效率。另一方面,流场本身相关的分析任务也呈现出越来越复杂的趋势,这给流场可视化技术提出了新的设计要求。例如在一些诸如线积分卷积[7-8]、基于有限时间李雅普诺夫指数计算的拉格朗日拟序结构提取[9-10]以及流场曲面计算[11]、源汇查询[12]等基于场线的应用中,需要进行复杂的粒子追踪计算,也引发了更加复杂多变的数据分析任务。
然而,当下的流场可视化系统框架下仍然存在一些问题。首先,基于并行粒子追踪性能优化的大规模流场可视化引发了新的困难和问题讨论。具体地说,即传统并行计算框架下的任务优化和数据管理策略如何较好地迁移至流场可视化应用中。例如,在并行计算的过程中,负载均衡问题显得尤为重要,需要设计精细的任务分配和调度策略,每个计算节点都始终被分配有较为均衡的任务量,才能最大化地利用计算资源,达到效率的最优化。但是,粒子追踪的并行化本身存在着粒子的运行时间和轨迹难以预测的复杂问题,对粒子的初始划分很难保证进程的负载均衡,需要合理而精细的预估模型。其次,现有的流场可视化系统下,粒子追踪过程对于用户难以理解和干预,因而对于已有算法难以进行评估、校验和诊断优化,这也对新方法的试验、应用带来了一定困难。用户对于粒子追踪的过程难以显示地获得理解,难以获取过程中数据块、任务调度和进程负载变化等核心信息,这使得占据整个流场可视化应用中巨大时间、存储消耗的过程难以进行合理地优化。流场可视化系统同样需要对这一过程采用系统化的可视化技术动态展现,提升系统运行效率,以增加流场可视化系统的可用性。
针对这些问题,结合在流场可视化领域的研究、应用和实践,本文研究团队主导设计并开发了高性能流场并行粒子追踪数据管理系统,帮助领域用户使用最新发展的可视化方法和技术理解、分析和探索流场数据,同时促进可视化和领域研究的发展。和现有的可视化系统相比,本文研究的系统关注于采用先进科学的并行数据管理方法提升流场可视化应用中粒子追踪的效率,同时支持先进的流场数据可视化算法的诊断和分析,能够有效地应用于不同的流场数据,并广泛地支持流场中的分析任务。
1 相关工作概述
在科学可视化针对大规模流场的可视化任务中,基于粒子追踪的流场可视化需要从原始数据出发生成场线。流场可视化粒子追踪的计算过程十分复杂,涉及大量的数据读取访问、密集型积分计算。而通过采用并行计算的模式,将工作负载分布到成百上千上万甚至更多的计算节点单元,由这些节点单元协作计算大规模粒子的轨迹,粒子追踪的效率会大大提高。这也使得并行粒子追踪成为了目前基于场线的大规模流场可视化的主流趋势。其主要工作流程包括基于分析任务需要生成初始粒子的分布和基于初始粒子分布进行积分迹线生成。初始粒子的数目由流场规模、局部特征和性能的平衡综合决定。针对大规模流场数据可视化的并行粒子追踪方法主要分为两类,即任务并行和数据并行。最近也有一些将两者进行结合的并行方法,即混合并行方法。不同类别的并行计算方式如下:
1) 任务并行:初始粒子种子被静态划分为若干组并被分配给不同的进程,每个进程负责其所分配到的粒子的追踪计算。
2) 数据并行:流场数据被静态划分为若干数据块并分配给不同的进程,每个进程负责在其所分配到的数据块内进行粒子追踪计算。
基于不同类别的并行计算策略,多种先进的数据管理策略被应用以提升计算效率,包括数据预取策略、负载均衡化策略和数据约减策略等。已有工作中主要关注于如何使用有效的数据划分、分配和移动等数据管理策略,尽量使进程负载均衡并减小通信和I/O等方面的开销,优化数据访问性能,以下部分将简述已有工作中针对不同并行计算策略采取的数据管理优化策略。
1.1 任务并行的粒子追踪算法中的数据管理策略
任务并行的粒子追踪算法将每个粒子的追踪计算看成是一个任务,其在初始时将所有种子静态地分配给所有的进程,同时在粒子追踪过程中由进程按需载入数据。为了保证负载均衡性,任务并行算法需要在初始时给每个进程预估并分配较为均衡的负载,或者在多轮运行的过程中实现动态任务重分配。在已有方法中,动态任务重分配主要通过工作窃取(Work Stealing)、工作请求(Work Requesting)或者k-d树分解来完成。工作窃取是一种常见的动态平衡负载方法,其原理是当某一个工作进程(称为窃取进程)完成所负责的任务时,会从其他繁忙进程(称为被窃取进程)处“偷取”一部分任务给自己执行。窃取目标的选择可以基于随机选择[13],然后从被窃取进程的任务队列末端开始转移任务,该方法被证明具有良好的效率[14]。Pugmire等[15]提出一种基于主-辅(Master-slave)模式的混合调度方法,也是基于这个思想。Lu等[16]针对流面计算也使用了工作窃取来平衡动态过程中的任务负载。Müller等[17]提出了一种类似工作窃取的方法,称作工作请求,该方法会带来更多的通信,但是更易于实现,更适合于分布式内存系统。基于k-d树分解的负载均衡思想被成功地运用到了针对Delaunay曲面细分(Delaunay Tessellation)的负载平衡中[18]。Zhang等提出了一种新颖的基于带有约束的k-d树分解的方法[19],可以在可用内存限制下尽量对未完成粒子进行重分配。
任务并行的粒子追踪算法中通常采用按需载入的数据访问策略,I/O问题是制约并行粒子追踪计算性能的一个非常重要的瓶颈。数据预取的思想是在载入所需要的数据时,将之后粒子追踪可能访问到的数据也一并提前载入,这样可以降低I/O操作次数,减少进程因为数据不在内存中而必须等待的时间。早在2005年,Rhodes等[20]就将访问模式作为先验知识,使用缓存和预取机制来动态提高I/O性能。近年来,俄亥俄州立大学的可视化小组针对流场可视化中流线和迹线等的计算,提出了一系列基于数据访问依赖的数据预取方法[21-22]。在预处理阶段,他们将数据划分为小块形式,然后根据粒子追踪的数据访问关系生成数据块之间的访问依赖图。需要注意的是,数据预取应该适度进行,过度的预取不仅会降低预测的准确性,还会饱和系统的带宽[23],造成适得其反的效果。
1.2 数据并行的粒子追踪算法中的数据管理策略
数据并行的粒子追踪算法在初始时将整个数据划分为若干数据块,并将这些数据块分配给各个进程。在粒子追踪的过程中,当粒子离开对应进程负责的数据块时,会被发送给目标数据块对应的进程继续追踪计算。一般情况下,该方法假设数据可以被所有进程一次性载入到内存中,所以具有较小的I/O开销。但由于需要频繁地在进程之间交换粒子,密集的通信带来的耗费对性能也具有较大的影响。相关的数据管理策略主要包括两类:静态负载平衡方法(例如根据某些划分规则的数据静态分配策略)以及动态负载平衡方法。
一种最直接的静态数据划分方法为规则数据划分,其中最直接的划分方法是静态轮转(Round-robin)法[24]。对于n个进程和m个数据块,该方法中第i个进程被分配到编号为i,i+m/n,i+2m/n,…的这些数据块。轮转法可以确保每个进程被分到空间位置不连续的相等数量的数据块。该方法的一个典型应用是在Nouanesengsy等[25]提出的基于有限时间李雅普诺夫指数(Finite-Time Lyapunov Exponents,FTLE)计算方法中。为了更进一步地解决负载不平衡的瓶颈, Nouanesengsy等[26]提出了一种负载感知的方法,即静态评估每个数据块的负载,并据此对数据块进行分配。该方法允许同一数据块被重复分配给多个进程,每个进程只负责重复数据块中一部分的粒子追踪工作量,但总的负载比较均等。另一类数据划分方法即不规则的数据划分。Chen和Fujishiro[27]提出了一种根据流场方向的数据划分方法,考虑了种子的分布和诸如漩涡等流场的局部特征。另一种不规则的划分是利用层次聚类进行自适应网格区域划分[28]。数据首先被分解成单位网格,即最小的簇,然后具有类似模式的相邻网格会被两两合并,自下而上迭代地形成二叉树的层次结构。
在动态负载平衡优化算法中,Peterka等[24]提出了一种基于递归坐标二分(Recursive Coordinate Bisection, RCB)[29]动态数据重划分方法。在他们的方法中,每个数据块中追踪的积分步数被记录为其历史负载,这种历史负载信息被用做数据重划分的依据。该方法的理论假设是,相邻时间步相同空间位置上每个数据块的负载可以认为是相似的。因此在数据重划分后,进程可以被重新分配到负载近似相等的数据块,然后在下一阶段进行计算。这里数据重划分通过RCB算法[29]实现。除了RCB,类似的算法包括递归惯性二分(Recursive Inertial Bisection, RIB)[30]以及基于图拓扑的划分[31-32]。
2 系统特性和功能设计支持
高性能流场并行粒子追踪数据管理系统具有以下特性:
1) 对于数据的支持
系统支持定义在线性网格上的二维、三维定常和时变的矢量场数据形式,并支持多种不同的常见数据格式,例如NetCDF、HDF5以及系统定义的XML数据描述等。系统提供不同体量的撒种规模,支持远超内存量的流场数据。系统支持多种典型的流场数据分析,包括Geos5全球风场数据、Isabel飓风数据、Nek5000热力水工数据等。
2) 对于常用分析任务的支持
系统支持流场数据的通用分析任务,包括流场中源汇查询、线积分卷积、基于有限时间李雅普诺夫指数计算的拉格朗日拟序结构提取、流场曲面计算等典型分析任务,为流场数据分析提供有力的支持。
3) 对于高性能的支持
系统支持高性能的流场可视化应用,支持针对大规模数据和任务,能够在不同的计算平台上针对并行粒子追踪算法进行并行计算效率加速。
4) 对于高可扩展性的支持
该系统在小型并行集群及超算平台上均具有良好的适应性,能够支持高度可扩展的并行加速,最高对于1 K核规模的并行集群仍然表现出良好的可扩展性。
5) 对于可视分析进行性能诊断方法的支持
系统支持对于先进的粒子追踪算法性能数据的可视分析技术,能够针对算法在运行过程中的数据、任务交换的行为模式进行比较和分析,帮助用户深入理解该复杂的计算过程。同时支持定位并行粒子追踪算法在计算过程中的性能桎梏,尤其针对负载不平衡的原因的探究,实现对于算法性能的诊断,以帮助专家学者进一步优化和改良已有的算法。
3 系统软件架构与实现
3.1 系统概览
高性能流场并行粒子追踪数据管理系统的整体工作流水线如图1所示。该系统支持的计算和操作流程依据其部署的不同操作平台和计算任务目标可拆分为在超算平台与本地平台运行的两个相互分离的阶段,共同支持大规模流场数据可视化的构建和优化分析。
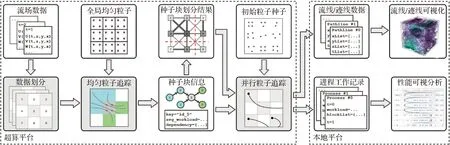
图1 高性能流场并行粒子追踪数据管理系统工作流水线 Fig.1 Workflow of high-performance flow parallel particle tracing data management system
部署在超算平台上的高性能流场并行粒子追踪数据管理系统主要支持高性能流场并行粒子追踪算法的实现和基于大规模科学数据管理的优化策略。该过程中,系统根据用户设定的分析任务目标和撒种初始化,使用一些诸如四阶龙格-库塔(Fourth-order Runge-Kutta, RK4)等数值积分算法计算追踪这些粒子在流场中的运行轨迹。为了进一步提升计算效率,系统关注于粒子积分算法中固有的天然可并行性,采用多进程并行优化计算的方式提升计算的效率,以适应粒子追踪本身的计算复杂性带来的挑战。引入并行计算机制在潜在提升计算效率的同时,使得算法具有更加复杂的流程,也使得负载均衡问题成为效率提升的关键所在。由于并行粒子追踪问题中,粒子的轨迹和粒子的运行时间难以预测,如何预估不同计算进程的负载情况,合理设计和实现负载均衡算法成为了十分重要的问题。而随着大规模流场数据对粒子追踪过程提出的更高要求,由于实际应用中有限的计算资源,并行粒子追踪过程中内存和I/O带宽的限制被进一步放大。如何有效地利用有限的计算资源并设计出合理的数据管理策略来改善内存和I/O带宽等资源的使用成为了另一个亟待解决的问题,这同样有助于提升计算的整体效率。
面对上述挑战和问题,高性能流场并行粒子追踪数据管理系统在优化策略上通过设计高效的数据管理策略,结合大规模流场可视化的特点,充分利用计算资源,从数据存储组织方式、数据访问以及在并行粒子追踪过程中对数据的划分和调度管理等方面进行考虑。在优化目标方面,高性能流场并行粒子追踪数据管理系统关注于并行粒子追踪流程中的两大性能桎梏,即负载均衡问题和大规模I/O问题。负载均衡问题和大规模I/O问题两者相互联系,相互制约。该系统通过先进的评估和划分算法,同时权衡优化两大目标,以达到实际性能的最大化。
支持本地平台运行的高性能流场并行粒子追踪数据管理系统能对并行粒子追踪过程产生迹线数据,系统支持灵活多变的本地端多种迹线可视化与可视分析方法,用于帮助用户理解与探索原始流场的特性。进一步地,高性能流场并行粒子追踪数据管理系统能对并行粒子追踪过程中产生的进程工作记录数据,系统支持用户对该过程中进程的负载与进程间数据块转移情况进行可视分析,在有效增强过程理解的同时,用户据此可对并行计算过程做出诊断。
3.2 流场并行粒子追踪数据管理模块构建
3.2.1 基于键值对存储的并行粒子追踪框架实现
在大规模流场可视化并行粒子追踪计算过程中,数据访问的效率是提升计算性能、可扩展性和存储空间效率的已知最大瓶颈。因而高效的数据存储管理、计算框架、底层架构实现成为十分重要的部分,是高效、高可扩展性计算性能的有力保证。究其原因,是因为大规模科学可视化构建所需要的可用计算资源十分有限,远远小于原始模拟的计算和数据规模,需要在有限地条件下平衡诸方面的因素,实现性能的提升。
高性能流场并行粒子追踪数据管理系统基于一种键值对(Key-value)存储的并行粒子追踪框架底层实现[33],旨在提升数据访问的效率。在流场可视化并行粒子追踪过程中,尽管流场可视化整体数据集十分庞大,但单次使用的工作集却非常小,因此从粗粒度分区到细粒度划分和调用是可行的。由于粒子追踪过程中粒子的轨迹难以预测性,基于按需载入的存储操作基本方法能够最有效地适应数据访问的实现模式。同时先进的粒子追踪方式越来越多地采用本地任务队列来管理局部粒子追踪任务的启动、停止和通信状态。基于先进的并行粒子追踪技术现状,该工作发现基于键值对存储的稀疏数据管理可以大大减少并行粒子追踪运行的内存占用,很好地适应按需数据访问需求,并且可以在不妨碍性能和扩展性的前提下进行高效管理。
在该方法的实现中,运行时的数据以初始划分的多个数据小块为基本的管理粒度,包含单个单元或更细粒度的单元块。该方法同时包含两个模块的组件:① 一个并行的键值对存储模块,支持统筹集中地进行数据块的I/O操作,以最大限度地将I/O延迟隐藏在并行粒子追踪积分计算的过程背后;② 一组完全独立的任务并行的追踪器。每个并行粒子追踪计算任务都被分配到一个追踪器,而每个追踪器拥有并管理着大量的追踪任务,通过任务队列的管理方式执行和管理待处理的任务集。追踪器通过访问和查询并行键值对存储的方式来请求计算过程中的数据,并将收到的数据块保存在本地基于最近最少使用(Least Recently Used, LRU)策略的缓存中,该缓存机制采用一个简单的随机存取存储器(Random Access Memory, RAM)键值存储实现。为了实现上述并行化模块组件,任务管理中包含两种不同的进程,即键值对存储进程和粒子追踪进程,分别处理不同的任务,数据主要从键值对存储流向粒子追踪进程。键值对存储进程负责数据请求的通信接收和载入处理,粒子追踪进程的任务则不涉及数据的访问,仅进行数值计算的过程。
在当前的实现中,由粒子追踪进程进行数据访问的过程与具有多层高速缓存的CPU上的数据访问非常相似。粒子追踪进程首先检查所需的数据是否缓存在本地,若本地缓存未命中,则粒子追踪进程向对应的并行键值对存储请求,若并行键值对存储仍然没有所需要的数据,则将花费更长的时间从文件系统中载入所需的数据并返回。并行键值对存储系统可以依据一定的数据预取策略,利用已有的信息积极地进行数据预取以避免缓存丢失,同时实现流控制以避免I/O系统的拥塞。基于三级缓存机制实现的数据访问过程和所需时间如图2所示。
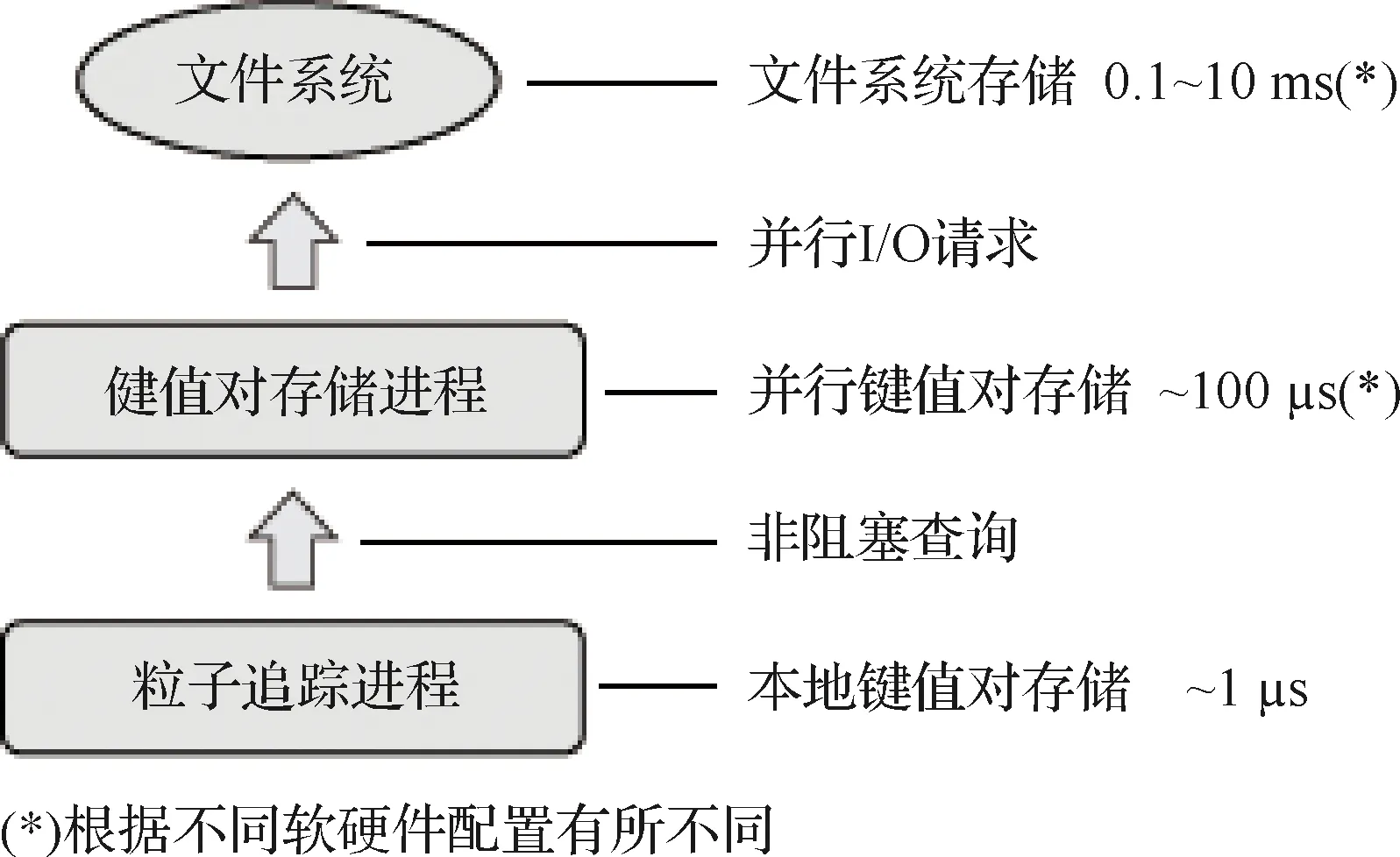
图2 流场并行粒子追踪数据管理模块软件逻辑架构Fig.2 Software logic architecture of flow field parallel particle tracing data management module
每个键值对存储进程负责一系列粒子追踪计算进程的数据访问请求。为了实现负载平衡,需要合理设计进程间任务负责的映射方法。该实现中通过散列的方法来划分整体的索引空间,并通过轮转法[24]来进行负责进程的分配。一个密钥k根据公式i=hash(k)modn,被分配给一个键值对存储进程,其中n为键值对存储进程数。粒子追踪进程发出的数据请求通过点对点通信,直接发送到相应的键值对进程实现交流。
该系统开发基于C++语言,混合了MPI/线程并行。所有的数据通信都是通过消息传递,同时粒子追踪进程和键值对存储进程被划分在同一个MPI通信组中。在该方法实现的框架中,有3种类型的进程间通信,即粒子追踪和键值对存储进程间通信,键值对存储和粒子追踪进程之间通信,键值对存储进程之间的通信,粒子追踪进程之间不支持建立通信。一般情况下,粒子追踪进程向相应的键值对存储进程发送请求,然后将数据条目发回给粒子追踪进程。数据预取是通过存储到存储的通信来完成的。实现中预定义了一系列运行时程序应用接口(Application Programming Interface, API),以及其他消息用于传递数据条目、处理状态和统计。所有的消息都会被入队,使用谷歌protobuf库序列化后发送至目的地进程。目的地进程在接收到消息后,将消息反序列化后进行后续处理。该系统利用异步通信来降低延迟。
3.2.2 基于访问依赖的大规模数据访问模式建模
流场可视化并行粒子追踪技术中数据I/O的代价十分庞大,减轻I/O负担的关键在于提高数据计算和利用中的局部性。其中主要的解决方案是将数据访问模式结合到粒子追踪中。但是,在流场可视化中,由于数据访问模式是由流场特性隐式决定的,对其进行建模十分具有挑战性。究其原因,粒子的轨迹难以预测。基于上述的特点,建立数据访问模式模型的一种方法是使用马尔可夫链。在随机模型中,访问下一个数据块的概率只建立在刚被访问过的那个数据块上。通过计算每对数据块的状态转移概率,一阶访问模式可以被记录下来。然后在场线追踪的过程中,根据粒子当前所在的数据块位置,可以提前评估下一个可能访问到的数据块。这种一阶的马尔可夫模型已经被有效地应用在了计算流体动力学和流场可视化的应用和分析之中[34],但仍然存在一定缺陷。由于状态(数据访问)从一个数据块可能会转移到多种不同的数据块,随着一阶马尔可夫链的增长,算法难以进行准确的预测。
高性能流场并行粒子追踪数据管理系统中集成了一种新颖的基于高阶马尔可夫链[35]的访问依赖模型[36]。这种高阶的访问依赖将历史访问信息也考虑进去,计算下一步的数据块访问是建立在当前的数据块和一系列过去已经被访问的数据块之上,可以更加准确地对数据访问进行预测性,从而相比于一阶访问模式的建模方法[21-34],进一步提高了数据局部性以提升流场可视化粒子追踪场线计算的效率。
高性能流场并行粒子追踪数据管理系统基于不同的用户任务设计和实际需求针对该数据访问依赖的建模形式设计了两种不同的实现方式,即一种基于预处理统计建模键值对存储查询的实现方式和基于机器学习进行访问序列建模预测的实现方式。
基于预处理统计建模键值对存储查询的实现方式通过进行一次预处理化得全局撒种并行粒子追踪过程,产生高度可重用的数据记录,为后续并行粒子追踪应用提供有效的辅助建模。整个数据全域被均匀划分为若干数据块,每个块都包含各个维度上相等大小的范围,并且使用均匀撒种的方式在不同位置上放置粒子。由于高阶访问对于依赖历史访问信息的需求,该方法从起始位置开始同时正向和反向进行追踪计算。对应生成的迹线分别叫做正向迹线和反向迹线,其区别在于在迹线追踪过程中前者每一步增加时间,而后者每一步减少时间。始于同一个位置的正向和反向迹线可以看成是一条完整的同时包含历史和下一步访问信息的迹线。在迹线追踪过程中,该方法使用一阶龙格-库塔(RK1)数值积分算法,并设置了较大的积分步长来优化预处理性能。为了生成指定m阶的访问依赖数据,该方法考虑历史访问数据块序列长度为m-1的所有合并迹线。该方法针对这些历史访问信息有所不同将迹线进行分组。算法进一步计算下一个访问包含每个数据块的所有迹线数量与访问所有可能数据块的迹线总数的比值,作为访问转移概率。其计算公式为
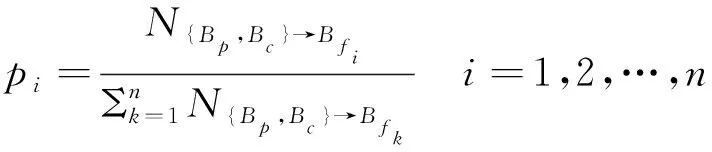
(1)
式中:Bp为访问历史数据块序列;Bc为当前访问数据块;Bfi为下一步可能访问的数据块;N为对应迹线支持的数量。
该算法的伪代码如算法1所示。通过该方法,只要一轮预处理计算,就可以得到不同阶数访问依赖结果。例如,如果阶数设为m,阶数为m,m-1,…,1的依赖都会被计算出来。为了高性能的数据访问模式和存储,高性能流场并行粒子追踪数据管理系统使用谷歌protobuf库所提供的数据结构。图3为高阶访问依赖计算过程的示意图。
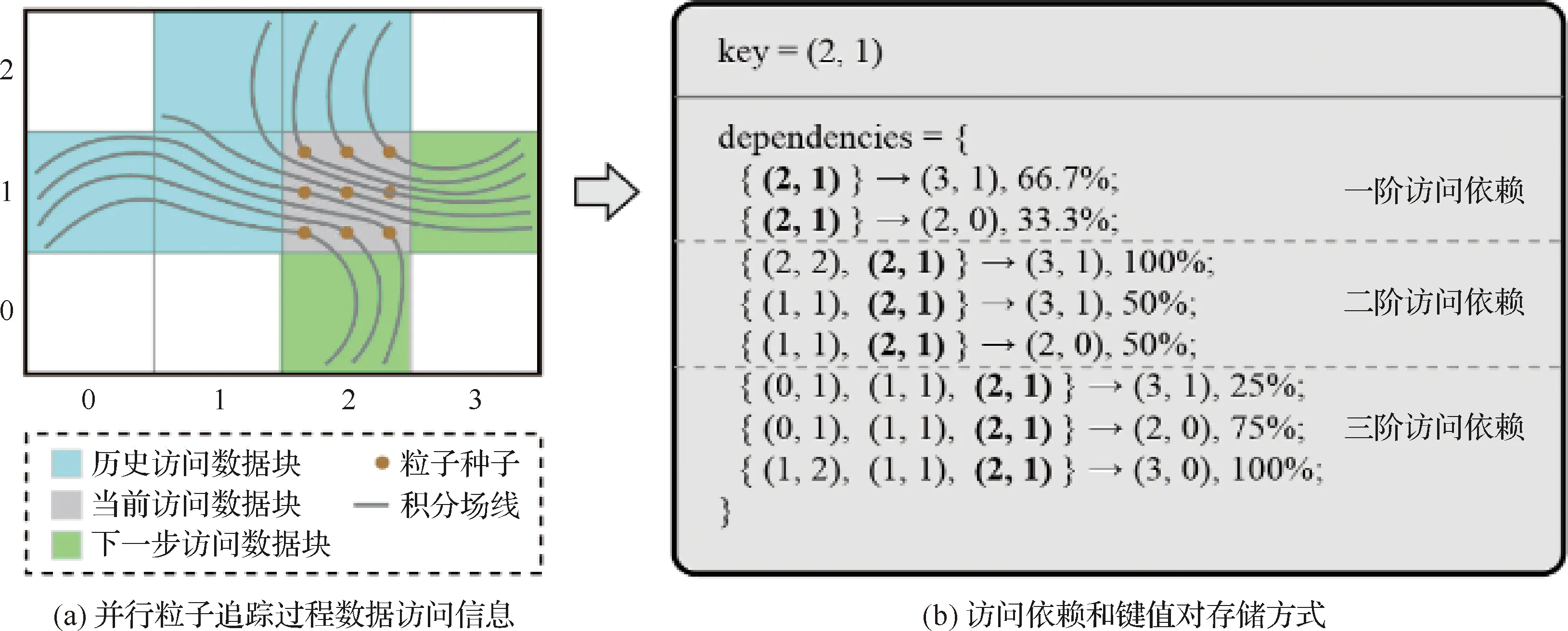
图3 高阶访问依赖计算过程示意图Fig.3 Computation process of high-order access dependency
随着机器学习技术的飞速发展,深度学习和可视化领域的结合日渐成为了研究热点。高性能流场并行粒子追踪数据管理系统关注于基于机器学习进行数据管理策略的研究领域下的潜力,提出了一种基于深度学习模型进行流场数据访问模式的分析、提取和建模预测的新方法[37],并据此采用先进的数据管理策略优化过程,支持灵活地嵌入流场可视化并行粒子追踪的框架中。该方法提出了一种新的使用泛化能力更强的长短时记忆模型[38]来对数据访问模式进行建模。通过在数据空间域中放置若干粒子,积分计算它们的轨迹,并将它们作为训练数据来训练模型,学习数据块之间的访问模式。首先将数据块索引序列转化为粒子移动方向的序列,图4为由粒子轨迹转化为数据块访问模式序列的过程示意图。高性能流场并行粒子追踪数据管理系统进一步集成了一个先进的机器学习模型,通过接受一个基于移动表示的序列,输出一个概率分布的序列,表示为考虑粒子所有之前移动和起始数据块后,预测得到下次移动的分布情况。

图4 粒子轨迹转化为数据块访问模式序列示意图Fig.4 Process of transferring pathline into sequence of data block access pattern

算法1 高阶访问依赖的提取算法MPI_Init()if RankID in tracer_list then local_db_initialize() ∥初始化本地记录 data_initialize()∥根据初始均匀划分载入数据 seed_placing() ∥根据初始均匀撒种获取任务 tracing_particle(); ∥正向粒子追踪 inverse_tracing_particle() ∥反向粒子追踪 if pathline in local_db then increase_record_num(pathline)∥增加对应记录的数量 else new_record(pathline) ∥添加新记录 end ifend ifglobal_db_initialize()gather_stastics(global_db, local_db)∥收集各个进程流线记录信息while order ≤ max_order do calculate_frequency(order, global_db)∥迭代计算各种流线模式频率end whileMPI_Finalize()
图5展示了该方法中进行数据访问模式建模采用的机器学习模型结构,其中D为粒子所有可能移动到的数据块运动方向。其输入是一个长度为n的移动序列s={s0,s1,…,sn-1},代表数据块访问的历史和当前信息。序列中每一项被嵌入层转化为一个实值向量。在嵌入层中,所有元素都被投影嵌入到另一个空间中。在嵌入层之后,高维向量的序列作为输入,进入到LSTM层。LSTM层输出一个由hidden_size维向量构成的序列。为了让LSTM层的输出能支持在待处理集合上的分类任务,网络结构中还添加了一个全连接层将输出序列的每一项转化为向量,并通过一个ReLU激活层将向量中的负数值整流为0。最后通过一个softmax层对这些权重进行重新调整,使得同一个向量里的值全部变换到(0, 1)之间并且和为1。对于每个输入项,其对应的输出向量可以看作一个所有元素的概率分布Pi,作为预测下一步数据访问数据块访问模式方向的概率分布。该模型使用负对数概率函数来作为损失函数支持训练,具体计算公式为
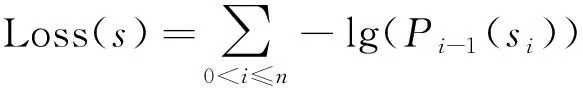
(2)

图5 数据访问模式建模采用的机器学习模型结构Fig.5 Machine learning model structure applied in data access pattern modeling
对于优化器的合理选择问题,该工作选择了小批量梯度下降算法,也就是每次更新模型只计算并考虑在一个小训练集上的损失函数之和。小批量梯度下降算法可以看作是随机梯度下降和全批量随机梯度的折中方案,具有更新次数更少,计算效率更高,模型更新频率更高,收敛过程也更加联邦鲁棒,更容易避免局部最小值的优势。RMSProp因为在已有工作中的优异性能,而被选择为模型参数的学习器。它能够自适应地调节学习率,使其在梯度的同一个量级上。该机器学习方法可以内嵌于并行粒子追踪的流程中,实现数据块预取技术,实现一种崭新的、具有潜力的CPU/GPU合作进行粒子追踪任务的形式,仅需要很少量的数据在主存和显存中传输。
高性能流场并行粒子追踪数据管理系统基于上述基于访问依赖的大规模数据访问模式建模实现,能够高效地支持并行粒子追踪流程中的数据局部性,结合大规模数据预取的有效数据管理策略,能够有效提升数据I/O过程中的性能指标,为实现高性能并行粒子追踪流程构建流场可视化提供有力的技术模块支持。
3.2.3 基于访问模式的负载动态负载评估策略
为了进一步提升计算效率,现有算法关注于粒子追踪算法中固有的天然可并行性,采用多进程并行优化计算的方式提升效率,以适应粒子追踪本身的计算复杂性带来的挑战。引入并行计算的机制在潜在提升计算效率的同时,使得算法具有更加复杂的流程,使得并行计算中负载均衡问题成为效率提升的关键所在。由于并行粒子追踪计算过程的复杂性中,粒子的轨迹和粒子的运行时间难以预测,如何预估不同计算进程的负载情况,从而合理设计和实现负载均衡算法成为了十分重要的问题。
高性能流场并行粒子追踪数据管理系统集成了一种基于访问模式的负载动态负载评估策略[39]。该策略使用粒子追踪的积分步数来衡量不同进程的工作负载。在每一轮粒子追踪计算过程中,数据块的负载被定义为所有粒子在该轮中在此数据块内被追踪的步数总和。由于不同进程基于划分的策略负责多个不同的数据块中包含的粒子计算任务,因此其负载也是这些数据块的负载之和。该方法同时将粒子数目和其历史负载进行考虑,用于预估数据块在一轮中的负载。
首先记录在每个数据块中追踪过的粒子数目和积分步数,并将其作为历史追踪信息附加在这个数据块中。当一轮粒子追踪结束时,算法可以计算每个数据块中粒子的平均负载。同时,根据未完成粒子的坐标,算法可以获知它们接下来在所有数据块中的分布数量。因此,每个数据块将来包含的负载可以用如下方法评估得到。假设在第j-1轮追踪结束之后,对于每一个数据块k,如果在第j轮有nk,j个粒子以它为起始块,那么第j轮预估负载可以使用如下公式进行计算:
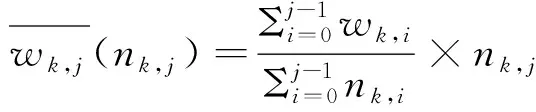
(3)
式中:wk,i是数据块k在前面的第i轮中的实际负载;nk,i是在前面的第i轮中经过数据块k的实际粒子数目(i 算法在运行时动态地建立了一个一阶访问依赖图的数据结构,来便捷地表达粒子在多个数据块之间的转移概率。每个数据块以多个键值对的形式保有访问依赖图的一部分,其中key是该数据块的邻接块索引,value是对应的访问转移概率,用来提升查询的效率。该方法根据从初始数据块的访问转移关系,可以预测在第2级追踪深度层次上要访问的数据块。基于访问转移概率,算法可以预测粒子在这些数据块中的粒子分布数量。之后,根据式(3)可以计算得到在每个数据块中的负载。从这些数据块出发,算法可以进一步预测在下一级追踪深度层次上要访问的数据块,直至追踪到第N级追踪深度层次。图6展示了追踪深度为3时的负载评估流程。 图6 基于访问模式的负载动态负载评估策略Fig.6 Dynamic data block load estimation strategy based on access pattern 高性能流场并行粒子追踪数据管理系统采用基于访问模式的负载动态负载评估策略实现对不同计算进程的准确负载预估,结合后续提出的负载均衡化调度算法实现数据和任务的合理分配,能够有效地改善并行粒子追踪流程中计算效率,减少空闲进程的占比,为实现高性能并行粒子追踪流程构建流场可视化提供有力的技术模块支持。 3.3.1 基于图划分算法整合实现的静态高性能 并行粒子追踪优化高性能并行粒子追踪器为了实现并行粒子追踪计算效率的最优化,复用了上述已有工作中多样化的流场并行粒子追踪数据管理模块化的技术,并加以合理应用、集成和精简,提出一种新颖的高性能并行粒子追踪优化算法框架。算法框架基于静态任务划分的并行优化方法。静态的任务划分方法仅在初始的轮次对于任务生成初始的划分,能够最小化地减少算法的额外计算和开销,使得并行粒子追踪过程更加简洁可控,也为进一步的算法优化提供了便利。该方法提出的框架仍在优化和迭代过程中。 算法构建了一个基于图的数据结构,用以描述并行粒子追踪任务的分配信息,并通过图划分的算法实现各个进程的数据和任务的分配。算法框架的主要流程包括两个部分:预处理阶段和运行时阶段。其中,运行阶段又由两个子阶段组成,分别是任务划分和随后的任务并行粒子追踪。 算法框架预处理阶段将流场转化为高阶访问依赖和负载信息的形式进行表达。首先将给定的流场数据在空间维度上均匀分块,在各个数据分块上均匀撒种,进行一轮的并行粒子追踪,并记录下追踪信息。该过程应用3.2.2节中基于访问依赖的大规模数据访问模式建模技术,与其预处理步骤较为一致,同时对每个种子点进行正向和反向追踪。只要一轮预处理计算,算法就可以得到不同阶数访问依赖结果。与上述基本技术模块的不同之处在于,该方法不仅收集粒子的历史访问信息以构建数据块访问依赖的建模关系,还记录了粒子在数据块内的负载信息(即积分步数)。框架又进一步结合3.2.3节中基于访问模式的负载动态负载评估策略,计算每个数据块内粒子的平均负载信息。其具体计算过程与上述算法一致。新增加的这一步平均粒子负载计算直接利用了粒子追踪的中间结果,并不会显著提高预处理开销。基于该预处理过程中生成的每个数据块信息,会在后续的任务划分和运行时并行粒子追踪过程中得到应用,基于上述方法生成的单个数据块数据信息以<数据索引,平均负载,访问依赖>的模型结构形式对其进行组织。 算法框架任务划分阶段旨在通过构建种子块图结构,实现兼具负载均衡性和高I/O效率的任务划分,以进行后续的并行粒子追踪过程。该阶段首先同样将流场数据在空间维度上均匀划分为数据块。给定基于任务定义的种子点分布,遵循流场分块结果,算法将其组织成多个种子块,每个种子块和一个数据块及其包含的种子点相对应,使得粒子追踪任务和数据更紧密地结合起来。对于每一个种子块,算法根据预处理的结果预测其中的种子在后续粒子追踪过程中会访问哪些数据块,同时预估其负载,并据此进行图构建算法。 对种子块的数据块访问进行预测是一个递归的过程。从某一个种子块出发,可以得到该对应数据块访问依赖中的一阶访问依赖,并找出所有可能在下一步访问的数据块。这个预测过程可以一直循环迭代,直至预先定义的粒子最多可以经过的数据块数量。上述算法可以得到种子块中的种子点可能经过的所有数据块序列。对于不同的种子块,算法可以计算任意两个种子块中的粒子迹线计算需要的数据块的相似性。同时根据预测到的数据块序列,该方法还可以评估初始粒子种子在这些数据块中进行追踪计算时产生的负载,并计算出对应种子块中粒子的总预估负载。 算法框架构建的图结构是一个无向图G=(V,E),节点和边分别映射了种子块的负载信息和种子块之间数据访问的关联。图结构中的每个节点表示一个种子块,其权重表示该种子块的负载。节点之间的边表示对应的两个种子块在数据访问路径的相似度。基于该表示下的流场和初始种子数据,需要通过图划分的方式,将不同的种子块节点分配给不同的进程,以实现负载均衡和I/O效率的优化。基于上述优化目标,该图划分的优化任务需要将种子块图划分成若干节点权重之和相近的子图。每个子图对应一部分的种子块并被分配给一个进程。图划分的另一个目标是确保划分后相同子图中的种子块具有尽量相似的数据访问,同时不同子图中种子块访问的数据块重复性最小。因此,需要在种子块图划分中,最小化需要的切割代价的大小。该方法使用ParMETIS库[40]所提供的图划分算法来解决上述种子块图的划分和分配问题,结果如图7所示。 图7 图划分算法结果示意图Fig.7 Result of graph partition-based algorithm 任务划分之后,每个进程可以被分配到若干个种子块中的粒子种子,并进行任务并行的粒子追踪。并行粒子追踪框架的数据管理基于3.2.1节中的键值对存储框架高效实现。在运行并行粒子追踪过程中,高性能流场并行粒子追踪数据管理系统实现了面向数据块的粒子追踪管理和高阶数据预取技术,以进一步提升计算的效率。该框架使用了数据预取来提高I/O效率。当从外存中载入所需要的数据项时,根据其访问依赖部分,预测下一步可能访问的数据块,并将其对应的数据项一同载入到内存中。 3.3.2 可视分析技术支持的并行粒子追踪过程 理解和优化并行粒子追踪过程及相应的算法十分复杂,其中涉及较大的并行计算规模和不断变化的数据行为。为了理解这一复杂的并行计算过程,从中整合并行计算进程间的行为模式、数据迁移、任务交换等信息十分必要,用户可以据此提出深刻的见解。可视分析技术能有效地帮助用户理解该过程,通过图形化的高效编码方式,降低用户的认知负担。高性能流场并行粒子追踪数据管理系统集成了一套交互式的可视分析工具[41],以帮助用户探索和诊断流场可视化并行粒子跟踪过程中动态负载平衡过程(数据和任务划分)。整个并行粒子追踪的流程被通用地建模为包含多个轮次的过程,在每个轮次中,每个粒子在流场中分别进行积分计算,直至达到最大步长或离开定义的流场边界。 交互式可视分析工具的系统界面如图8所示,共包括3个视图:整体视图、节点-链接图视图和空间视图。这3个视图通过交互手段链接在一起,供研究人员从整体到细节进行探索。在整体视图中,系统利用折线图来显示并行粒子追踪中各个进程负载平衡过程的概述。其中横轴表示执行时间,其上标记出运行的轮数。纵轴表示负载平衡指标,该指标按此轮中进程最大工作负载与平均进程工作负载之比计算得出。节点-链接图作为该可视分析工具的主要视图,可视化整个并行粒子追踪流程的数据行为,包含数据块的传输以及各个计算进程之间的任务交换。其中每个节点代表某一个轮次中的一个计算进程,节点的大小编码了在相应的轮次进程中分配的数据块的总数,同时应用颜色对每个进程的负载进行编码。节点之间的链接表示数据块的移动或任务从一轮中的一个进程到下一轮中的另一个进程的交换。系统还对分配给每个过程的数据块进行编码以显示详细信息。每个数据块都可视化为一个正方形。对于每个进程,其分配的数据块将在相应节点上方水平显示。节点-链接图视图设计采用了类似矩阵的总体布局。视图中从上到下显示多行节点,表示连续的并行粒子追踪轮次。每列中的节点表示在不同的轮次中的同一进程。空间视图用来绘制指定数据块中的粒子迹线,以帮助用户诊断异常。 图8 交互式可视分析工具的系统界面Fig.8 System interface of interactive visual analytics tool 流场数据全局分析任务目的是研究流场的综合性特征。流场可视化典型的全局分析应用包括有限时间李雅普诺夫指数(FTLE)的计算,用来衡量非定常流场的分离特性。FTLE计算使用了全局密集撒种策略,需要追踪大量的粒子,对流场并行粒子追踪的性能提出了较高的要求。本次测试分析任务采用的飓风Isabel数据自于美国国家大气研究中心对飓风的模拟结果,由若干时变的标量和矢量变量组成。数据时空分辨率为500×500×100×48。 测试分析利用国家超算广州中心的天河2号超级计算机平台。该测试最多使用了512个进程,每个进程的缓存被设置为512 MB。采用的数据块划分粒度为16×16×16×1,追踪总数为54 000个的粒子。实验的性能基准为强可扩展性测试,同时分析负载均衡性以及I/O效率。强可扩展性是测量在固定数量粒子下总执行时间如何随进程数的变化而变化。其通过对所有进程上分配一个总规模大小固定的问题来测试方法的效率。该实验中采用的基线方法为不施加优化的并行粒子追踪算法,与高性能流场并行粒子追踪数据管理系统采用的并行粒子追踪算法形成对比。实验结果如图9所示,验证了高性能流场可视化粒子追踪器在性能、负载平衡、I/O效率上的优势,达到了预期的目标。 图9 基于Isabel数据集进行的强可扩展性测试结果Fig.9 Strong scalability test results based on Isabel dataset 已有的流场可视化并行粒子追踪中负载均衡化算法进行了多样化优化设计,从不同的角度提升负载均衡指标。案例分析采用高性能流场并行粒子追踪数据管理系统中集成的交互式可视分析工具针对不同的负载均衡算法进行详细的探索,帮助理解和比较不同算法设计和对并行粒子追踪过程的干预方式,以待研究人员进行针对性的诊断和进一步地改进。测试中主要关注的是通过数据块和任务的转移来进行动态负载平衡算法。通过在这个动态过程中嵌入中间数据提取代码,转储相关性能信息,进行可视化和可视分析。在每一轮并行粒子追踪过程中,系统都会获得两种类型的性能数据。第1种是数据块和任务在不同进程和运行轮次的分布情况。第2种涉及与源/目的进程有关的流入/流出的数据块和任务数据。 测试中采用的热工水力学数据是Nek5000求解器的输出结果,来自于美国阿贡国家实验室开发的大涡Navier-Stokes模拟。本次测试使用单个时间步的数据,分辨率为512×512×512,数据规模为1.5 GB。测试分析利用国家超算广州中心的天河2号超级计算机平台,使用32个进程进行并行粒子追踪。共对比分析运行了3种不同的算法,如图10所示。基于负载窃取的优化算法的基本思想是在每轮追踪之后将任务从繁忙的进程发送到空闲的进程。基于动态数据重划分的优化算法则定期执行数据重划分,然后在每轮粒子追踪后根据划分结果重新分配数据块。图10展示了使用Nek5000数据和多种优化算法实现的并行粒子追踪过程中进程间数据行为比较可视化。 图10 使用Nek5000数据和多种优化算法实现的并行粒子追踪过程中进程间数据行为可视化比较Fig.10 Comparison visualization of data behavior among processes in parallel particle tracing implemented by multiple optimization methods based on Nek5000 dataset 在基线算法中,每个进程都保持最初分配的数据块,并且在运行时数据不在进程之间移动,进程0和进程3始终具有很高的负载,未实现负载均衡化。基于动态数据重划分的优化算法流程中则出现了频繁的数据迁移和调度,尽管有一些进程被分配了较多的数据块,系统却实现了较为良好的负载均衡,这得益于良好的负载预估和动态数据块重分配算法。基于负载窃取的优化算法同样具有较多的数据迁移行为,但数据迁移大多发生在并行粒子多轮追踪的后期,且集中于多个固定的进程。由于并行计算任务在初始几轮大多难以触发结束跳出条件,同时数据初始按空间划分分配的相对均匀性,大多数进程未出现空闲的时间,因而不符合负载窃取的触发条件。相比于基于动态数据重划分的优化算法,其负载均衡指标略逊一筹。案例证明了基于该可视分析工具可以有效帮助用户发现不同并行粒子追踪算法的特征。 1) 高性能流场并行粒子追踪数据管理系统包括超算服务器平台上部署的基于先进数据管理策略优化的并行粒子追踪器,能帮助用户高效地生成流场中的迹线。 2) 高性能流场并行粒子追踪数据管理系统包括在本地端的可视分析理解诊断工具,能帮助用户理解、分析、诊断并行粒子追踪负载均衡算法。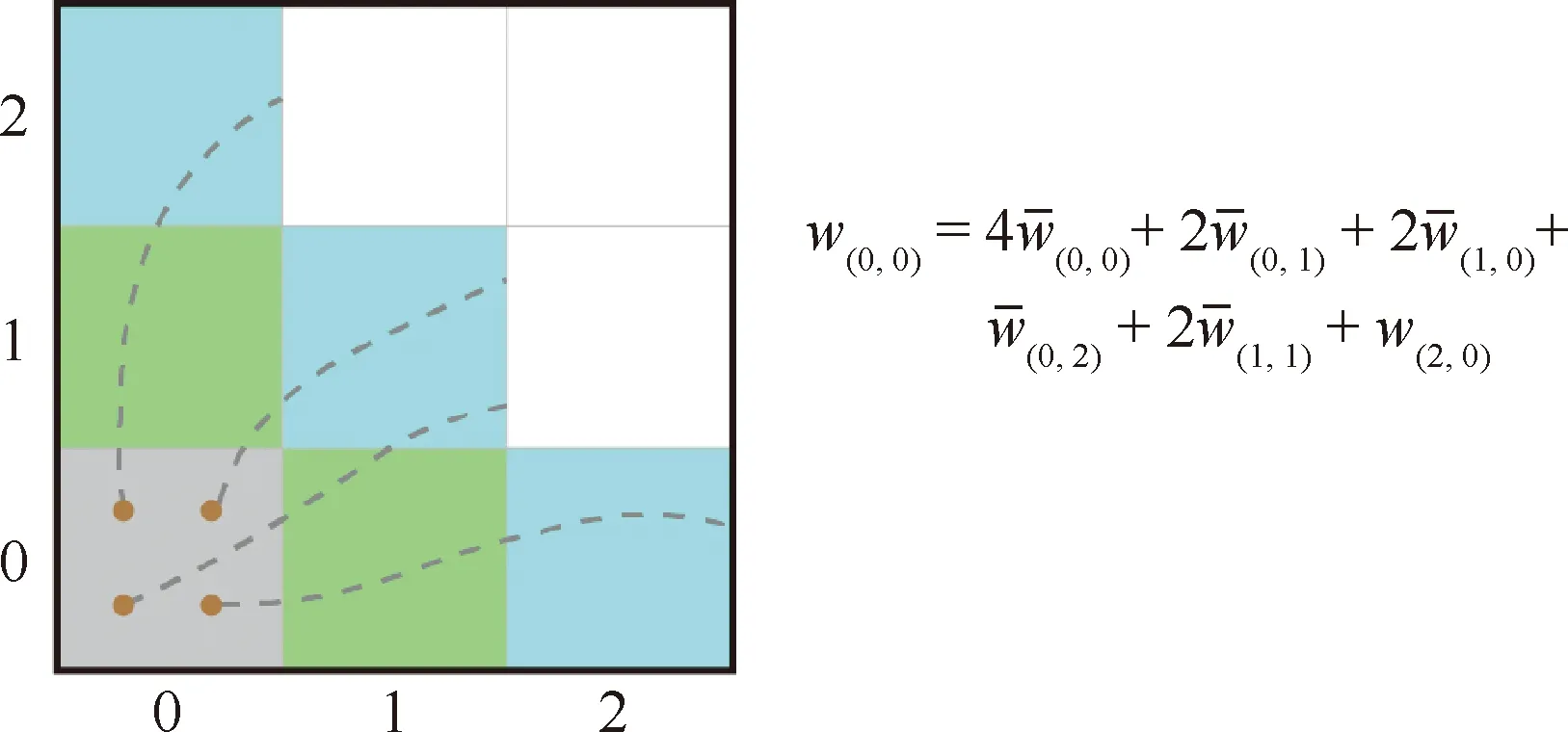
3.3 高性能并行粒子追踪全流程


4 应用实例
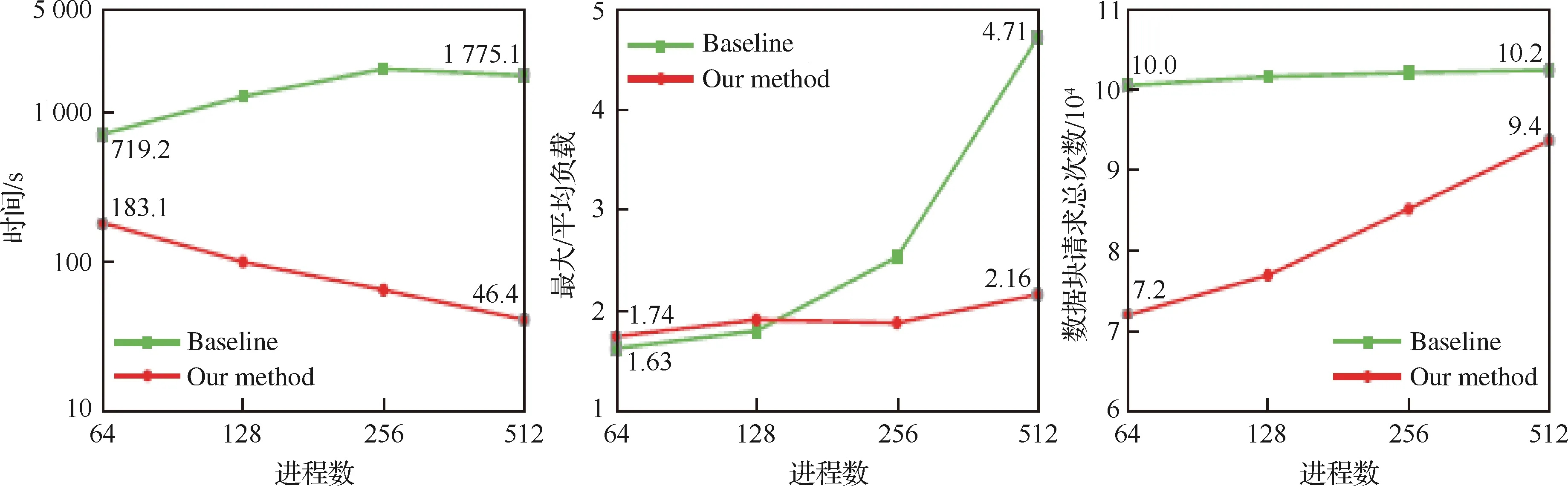
4.1 基于飓风Isabel模拟数据的流场全局分析并行粒子追踪性能测试
4.2 可视分析技术支持的基于Nek5000热工水力学模拟数据多种动态负载平衡算法比较

5 结 论
