基于改进K-SVD算法在牛脸识别上的应用*
2021-10-15赵建敏姜世奇
赵建敏,姜世奇,李 琦
(内蒙古科技大学 信息工程学院,内蒙古 包头 014000)
0 引 言
目前传统畜牧业正在不断寻找新的发展模式,不再仅以增产为主,转而更加注重产品的质量与品种,向智能化、精细化、规模化方向发展,提出了精准畜牧业的发展理念,这也是由我国目前的发展现状与时代特征所决定的,同时也对牲畜的个体身份识别提出了更高的要求。目前主流的牛个体识别都是采用基于射频识别(radio frequency identification,RFID)的识别方式[1~3],这种方法不仅识别距离有限,而且存在被替换、损坏和丢失导致无法准确识别的潜在风险。因此,国内外学者利用图像处理技术对牲畜的识别展开了广泛的研究。Xia M等人[4]提出了利用稀疏表示分类器(SRC)对牛脸图像进行识别,通过主成分分析(PCA)进行特征提取后利用SRC进行识别。陈娟娟等人[5]用改进的特征袋模型(BOF)对奶牛头部图像进行识别,在基于空间金字塔匹配原理(SPM)的BOF模型上,引入了HOG特征替换SIFT特征,针对奶牛图像降低特征复杂度,提升了识别性能。深度学习的兴起使得卷积神经网络(CNN)对图像识别表现优异,很多学者利用CNN进行牛的个体识别[6,7],取得了较好的识别效果,但基于CNN的网络模型需要大量人工标注的数据进行训练与测试,对于人力成本要求较高,在实际牧场应用中难以大范围开展。Kumar S等人[8,9]利用牛的鼻口点(muzzle point)信息来进行个体识别,这些信息与人类指纹类似具有较高的辨识度,但相比脸部图像获取,鼻口点数据的实际采集过程对人工成本要求较高,采集难度较大,实际应用困难。
对此,本文将字典学习理论结合牛脸图像识别应用到牛的个体身份识别,在经典K-SVD算法[10]基础上进行了改进,对于输入的牛脸图像,通过构造冗余字典原子的线性组合来对样本进行稀疏表示,在稀疏表示过程中加强了原子的优化策略,求解样本在不同字典下的重构误差,针对牛脸识别问题,有了明显改善。
1 材 料
数据来源于内蒙古自治区乌兰察布市察哈尔地区某牧场,为了更好地采集完整的牛脸图像,选取了牛在饮水期间进行图像采集,经过挑选后构造了一个牛脸图像数据集IMCFR20。该数据集中包含20头牛,每头牛挑选20张正面牛脸图片,共计400张。采集时间为2018年7月,采集设备为高清数码摄像机。
图1为IMCFR20数据集中部分牛只ID对应的牛脸图像,可以看出除ID17的花纹毛色呈现明显区别外,其余ID02,03,06,15所代表的牛只外形极为相似,只在牛角以及毛发的弯曲程度以及其他细节特征上有所区别。除此以外,相似的养殖环境进一步提升了识别难度,依赖人的主观判断很难对其进行准确识别。
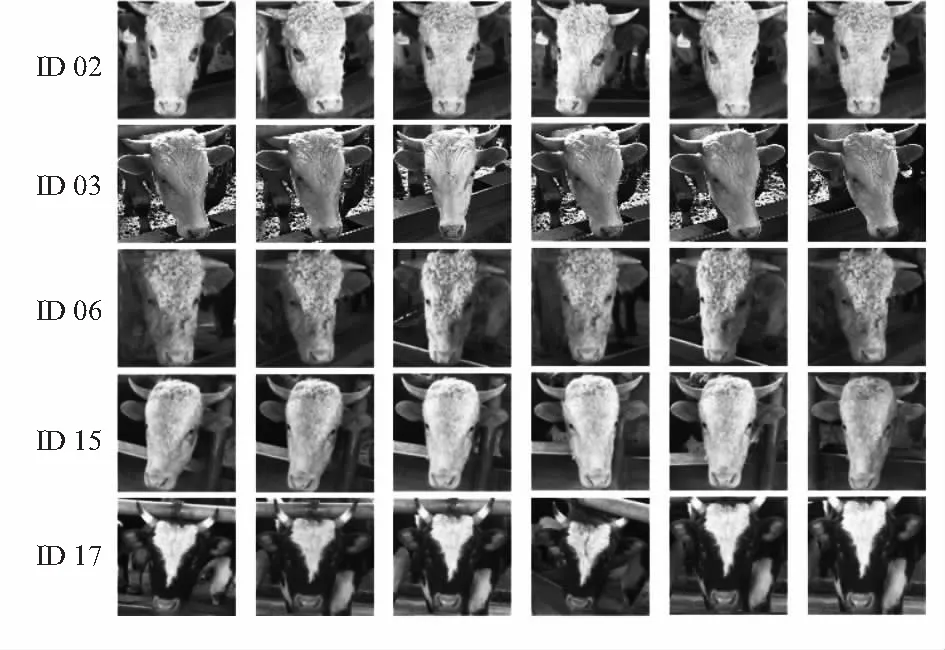
图1 IMCFR20部分牛脸图像
2 方 法
2.1 K-SVD算法
K-SVD算法的提出将K-Means与SVD进行了有机结合,通过得到一个对原始样本进行学习的冗余字典,利用其原子的线性组合来实现近似表示。对于样本集合Y=[y1,…,yN]∈Rn×N,可以近似描述为Y≈DX,D=[d1,…,dK]∈Rn×K表示过完备字典,X=[x1,…,xN]∈RK×N表示Y对应稀疏系数构成的矩阵。算法可表示为以下问题的优化
(1)

在求解过程中大致分为三个步骤:第一步是初始化D0,在Y中随机选取K个样本对字典进行初始化。第二步是稀疏编码过程,将式(1)的优化问题转换为求解Y对应稀疏矩阵X,这里采用OMP算法[11]进行求解,通过不断迭代计算样本向量与字典原子的内积,选择与信号残差最匹配的原子,直到满足稀疏度限制。第三步是字典更新过程,交替优化求解X和D。在更新时对X中非零列逐次更新,将式(1)转换为
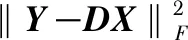
(2)


(3)
2.2 K-SVD算法的改进
K-SVD在稀疏编码阶段是通过求解一个稀疏矩阵来对算法进行优化,通常采用OMP算法。具体是通过反复迭代求解样本向量与字典原子的内积来寻找一个最佳的正交投影进行信号的稀疏逼近。在利用牛脸图像进行牛个体身份的识别问题上,希望通过输入的牛脸图像尽可能准确地对牛个体进行分类和识别,不需要对原始的牛脸图像进行精准的重构,而对于输入样本的稀疏表达形式提出了不同要求。因此针对分类与识别问题,使残差尽可能取最小并不是目的,而是需要使稀疏向量的系数尽可能非负。借鉴文献[12]的思想对OMP算法进行改进,为了使负值系数尽可能少出现,在迭代过程中不再选取使内积最大的字典原子作为最优解,而是保留使系数取最大值的原子,将其余原子去除,进而实现稀疏表示的优化。具体流程如下:
输入:字典D,样本Y,稀疏度L,迭代次数N
输出:稀疏矩阵X
初始化:残差r0=y,索引集Λ(0)=∅,J=1
过程:
1)计算rJ-1与D中原子dj内积,求取使系数最大的原子(Pdj表示在原子dj上的投影)
2)更新索引集和字典原子:Λ(J)J=λ,D(J)J=D(︰,Λ(J)J(1︰J));
3)x(J)=‖y-D(J)x‖2;
4)更新残差r(J)=D(J)x(J),J=J+1;
5)若J>N,则停止迭代,否则,循环步骤(1)~步骤(5)。
3 结果与分析
实验环境为CPU:Intel Core i7—7700K;内存:32 GB;显卡:GTX 1080Ti;OS:Ubuntu16.04;MATLAB 2016a。IMCFR20数据集中包含20头牛的400张牛脸图像,样本大小为128×128。
通过牛脸图像数据集IMCFR20对本文算法进行验证。首先进行数据的预处理,将IMCFR20数据集中的图像进行灰度变换,针对每个ID的样本数据随机选取70 %作为训练数据,剩余30 %作为测试数据。在训练阶段,对于每个输入的训练样本,将128×128维度下采样为256维,将所有训练样本映射为R256×280的矩阵,迭代次数设为60,稀疏度阈值为10,字典原子K初始设为300。由于改变了K-SVD的稀疏编码过程中字典原子的选取原则,分别测试改进后的算法与原始K-SVD算法在不同迭代次数下的重构误差,结果如图2所示。
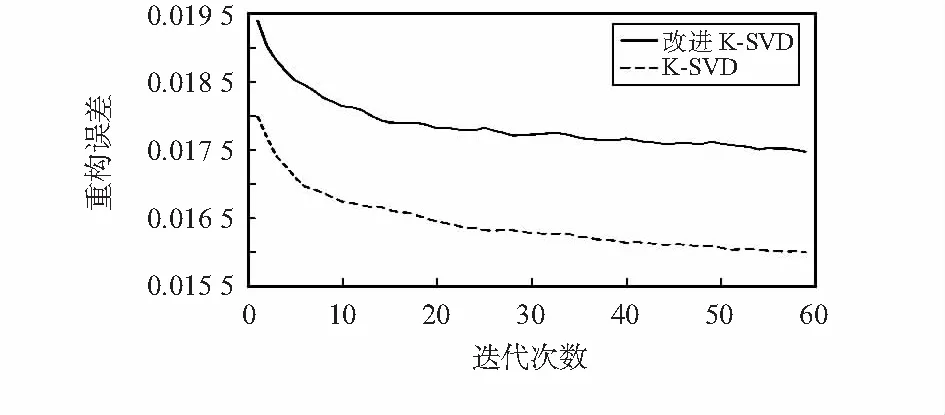
图2 重构误差与迭代次数的关系
通过表1可以看出将字典原子的选择方式变为保留使系数最大的原子后,相比原算法的重构性能会有一定下降。为了进一步分析验证改进后算法的识别效果,在IMCFR20数据集上分别对K-SVD与改进K-SVD算法进行测试,由于稀疏度大小与字典原子的不同取值都会对识别结果产生影响,针对以上两个参数分别进行实验。首先分析稀疏度取值的不同对识别效果的影响,分别选取L=2,L=4,L=6,L=8,L=10进行实验,测试结果如表1所示。实验表明,改进后算法的识别率增加3 %左右,提升效果较为明显。随着稀疏度的增加,重构误差会不断减小,但识别效果会呈现先上升后下降的趋势,稀疏度在L=6时识别率最佳。
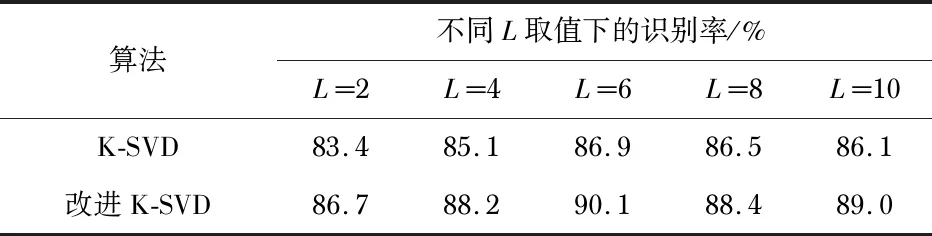
表1 不同稀疏度对识别率的影响
分析字典原子数量对识别效果的影响,随机选取每类牛脸图像中的16张用于训练,4张用于测试,共20类。稀疏度L=6,字典原子数K分别取300,400,500进行测试,结果如表2所示。

表2 不同数量的字典原子对识别率的影响
实验表明,在一定范围内增加字典原子个数可以提升识别效果,当K=500时,本文算法可以达到90.9 %,具有较好的识别性能。K在300~500的变化范围内,K-SVD算法的识别率波动了1.5 %,改进K-SVD算法的识别率波动了0.8 %,可见本文对字典原子数量的改变所造成的结果影响波动较小。
4 结 论
本文在K-SVD算法的基础上,对稀疏编码阶段的字典原子选择方式进行了改进,使得改进后的算法更适用于图像分类与识别问题。在构造的牛脸图像数据集IMCFR20上的实验结果表明:本文算法的牛脸图像识别准确率达到了90 %以上,识别效果较好,对通过图像方式进行牛个体身份识别问题提供了一种可行的方案。
