基于光伏系统发现未知工况和物理含义的聚类算法*
2021-10-15李小坤刘光宇俞玮捷俞武嘉
李小坤,刘光宇,俞玮捷,俞武嘉
(杭州电子科技大学 自动化学院,浙江 杭州 310000)
0 引 言
近几年,光伏发电受到中国和欧洲国家欢迎[1]。光伏系统,尤其是直流侧“光伏阵列”,必须在恶劣的室外条件下运行,导致功率不稳定,降低效率和盈利能力[2,3]。然而,对于一个现场太阳能发电厂来说,很难辨别正在进行的是哪种运行模式,因此,需要对光伏系统在不同工况下的性能进行观察和分析。
光伏系统故障诊断方法主要分为两类:传统的阈值方法和基于机器学习的方法[2]。传统的阈值方法通过分析电流和电压[4]等电气指标来实现[5],但是成本很高。近几年,人工智能中的一些方法被广泛应用于故障诊断领域,如神经网络用于估计变工况下的功率输出[6]和识别故障类型,属于监督学习方法,需要在测量变量和实际工作条件的映射上精确标注。事实上,监督学习对太阳能行业来说并不是很有用,不仅因为标记不同工作条件的成本很高,而且太阳能系统太复杂无法正确标记。
本文假设太阳能系统的时间序列电流和电压可以通过时间序列聚类方法得到一些统计聚类,这些聚类具有一定的物理意义。为了支持这一假设,首先使用DTW[7]算法对太阳能电站产生的时间序列数据进行处理,然后使用DBSCAN算法对处理后数据的相似性进行聚类[8~10]。最后,通过数据分析发现集群的物理含义。研究结果有助于在光伏发电系统在工作条件不明确的情况下采用智能技术进行监测、预测和故障诊断。
1 问题陈述
定义时间序列为X(t)∈m,并且X(t)={x1(t),x2(t),…,xm(t)}是关于独立变量t的有序实数值数据序列。时间序列聚类是为所有变量在相同的时间间隔内提供一定的相似性度量,将时间序列X(t)划分为一组聚类C={C1,C2,…,Ck}。在这里并且i≠j。
在光伏领域,光强以外的高维时间序列数据如何聚类,时间序列聚类是否具有明确的物理意义,目前还没有研究。假设当使用适当的聚类方法时,太阳能发电系统在未知工作条件下会产生不同的电流和电压的时间序列序集。在接下来的研究中,研究了太阳能系统的时间序列聚类,然后发现了时间序列数据的任何实质性的物理含义。
2 基于DTW的密度聚类方法
2.1 密度聚类DBSCAN算法
DBSCAN是基于密度的聚类算法的先驱,是科学文献中最重要、最流行的聚类算法之一。该算法能够发现非凸形状的类簇。DBSCAN只有两个参数:ε(Eps)和MinPts,其中ε是扫描半径,MinPts是一个点的邻域内所包含的最少点的个数。
DBSCAN算法中概念的定义:1)点p的ε邻域:Nε(p)表示样本集中与p的距离不大于ε的样本,即Nε(p)={q|q∈D,dp,q≤ε},其中,dp,q是点p与点q之间的欧几里得距离。2)核心点:如果|Nε(p)|≥MinPts,则p为核心点。3)密度直达:如果q∈Nε(p),p是一个核心点,则称q由p密度直达。4)边界点:如果q是由核心点p密度直达,并且|Nε(q)| DBSCAN算法的核心思想是以核心对象为中心的小稠密区域构成一个大稠密区域。首先,数据集D中的所有对象都被标记“unvisted”。DBSCAN随机选取一个未访问的点p,标记p为“visted”,如果点p的ε邻域中至少有MinPts个对象,则创建一个p作为核心对象的新簇C。然后,DBSCAN反复地寻找这个核心对象密度可达的对象添加到新簇C中。当没有新的点可以被添加到新簇C中时,这一过程结束。重复以上过程直到不存在“unvisted”对象,则DBSCAN产生的簇集合为C={C1,C2,…,Cn}。DBSCAN算法的伪代码如下: 输入:样本集D和邻域参数(ε,MinPts) 输出:基于密度的簇的集合C={C1,C2,…,Cn} 方法: 1)标记所有对象为unvisited; 2)do; 3)随机选择一个unvisited对象p; 4)标记p为visited; 5)ifp的ε邻域至少有MinPts个对象; 6)创建一个新簇C,并把p添加到C; 7)令N为p的ε邻域中对象的集合; 8)forN中每一个点q; 9)ifq是unvisited 10)标记q为visited; 11)ifq的ε邻域至少有MinPts个点,将这些点添加到N; 12)ifq还不是任何簇的成员,将q添加到C; 13)end for; 14)输出C; 15)else 标记p为噪声; 16)until没有标记为unvisited的对象。 提出了一种时序DBSCAN方法,作为DTW和DBSCAN的结合处理时间序列X(t)的聚类方法。首先,使用动态时间扭曲作为相似性度量方法提取X(t)的特征。然后,将DBSCAN方法应用与这些特征生成X(t)的时间序列簇。换句话说,由于DTW算法,DBSCAN方法将用于新的时间序列XDTW(t)划分为K个簇,每个簇由时间序列X(t)的特定分区组成。 本文设计并搭建了一个小型光伏电站,表1列出了光伏电站4种工作条件。两个光伏组件之间的电线连接断开,模拟开路故障。光伏阵列由一块布遮挡,模拟树木或建筑物的遮阳效果。类似地,部分遮阳被用于模拟光伏组件的树叶或沉积物堵塞。 表1 实验中的条件 从光伏电站中选择8个属性从早上8点到下午1点采集实验数据,8个属性分别为光伏阵列的总输出电压Vpv,光伏阵列的总输出电流Ipv,逆变器电压Vinv,逆变器电Iinv,负载电压Vload,负载电流Iload,环境温度T和辐照度G。 时间序列变量X(t)∈1 791×8从室外实验中获得,图1展示了未知工况下的原始数据。 图1 未知工作条件下太阳能系统的原始数据 分别采用DBSCAN算法和时序DBSCAN方法对原始数据进行聚类,后者具有一个辅助步骤,以动态时间翘曲的方式处理时间序列,而普通DBSCAN算法不考虑独立的时间变量。 在实验中,聚类任务不知道原始数据中隐含了多少工作条件,因此,必须确定最佳聚类个数K。如果存在一个特定的K,使得DB最小,则K是最佳聚类个数。DBSCAN有两个参数,调整参数可以得到不同的聚类结果。设定算法的阈值MinPts=9,时序DBSCAN的Eps范围为0~0.2,DBSCAN的Eps范围为0~4。聚类结果如图2所示。 图2 K值的确定 观察图2可以发现,时序DBSCAN算法在K=3时DB最小,K=3是最佳聚类个数。而DBSCAN算法在K=4时DB最小,K=4是最佳聚类个数。 此时再用外部指标来确定最优聚类个数。从表2和表3中可以发现K=3时相对较优,而且时序DBSCAN算法比DBSCAN算法在辨别噪声方面明显更好。 表2 时序DBSCAN聚类结果 表3 DBSCAN聚类结果 不可否认,实验中未知的工作条件是为了测试所提出的聚类思想而故意设计的。但是,在聚类过程中没有使用任何与原始数据相关联的标签,所以这些簇完全是由数学公式推导出来的。在后续中,撤销这些“未知”条件的先验知识,发现实际物理现象和簇之间的一些自然联系。 表4和表5是聚类算法簇与人工标记簇之间的比较结果。无论K为多少,开路故障C2与整体遮阳C3和局部遮阳C4都几乎完全分离,因此,可以通过选择不同的K准确地识别出电气故障。然而,无论K为多少,整体遮挡和局部遮挡都不能够清晰地分辨出,且往往会把整体遮阳和局部遮阳分为同一类。而随着K的增加,会把正常条件C1分裂为多个簇,可能是环境变化的属性欺骗了聚类算法。 表4 以百分比表示的基于时序DBSCAN方法聚类的物理含义 表5 以百分比表示的DBSCAN方法聚类的物理含义 综上所述,开路故障更容易与其他条件分离,正常条件是最容易混淆的条件,而局部遮阳和整体遮阳分为一类,可能是因为基本的物理原理是开路故障是一种电气故障,而其他条件都会受到太阳辐射变化的影响。 建成的太阳能电站能够在正常工作、局部遮阳、整体遮阳、开路故障等不同的运行条件下工作,采集室外实验中的时间序列电流和电压数据进行聚类。实验结果表明:未知的工作条件与电压和电流的聚类有物理联系,而太阳能发电系统的未知工作条件是否与电流和电压的时间序列簇相关,从而使每个簇具有明确的物理含义,这是一个有待解决的问题。2.2 时序DBSCAN方法
3 实 验

4 实验结果与分析
4.1 原始数据
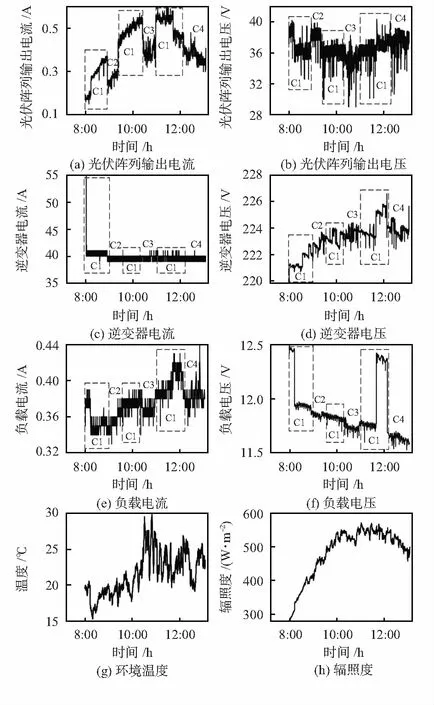
4.2 聚类结果

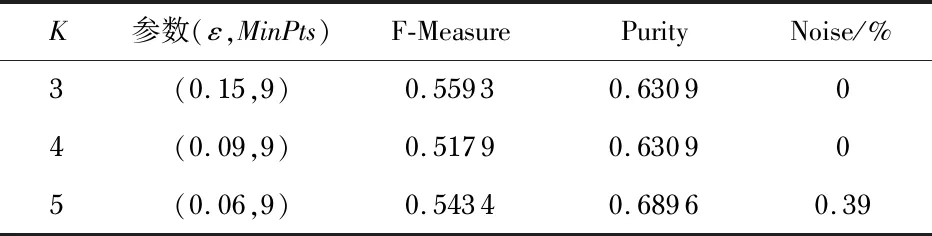
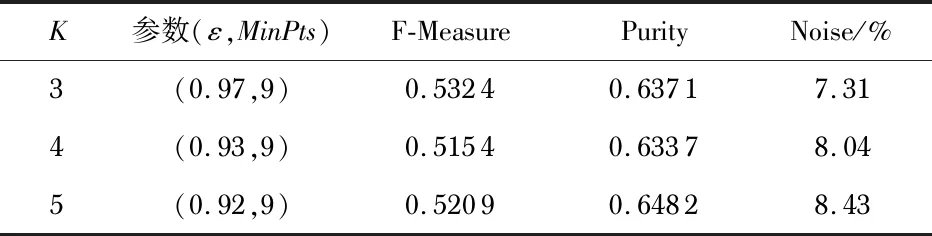
4.3 聚类的物理含义


5 结 论
