基础研究领域知识图谱研究前沿的可视化分析
2021-10-15陈雅丹杜元朱爽赵欣然孙娜李心怡胡烨胤李新龙
陈雅丹,杜元,朱爽,赵欣然,孙娜,李心怡,胡烨胤,李新龙
1.北京中医药大学,北京 100029;
2.北京中医药大学东方医院,北京 100078;
3.北京中医药大学东直门医院,北京 100700
知识图谱(Knowledge Graph)一词在1972 年即已经被提出[1],随着2012年谷歌知识图谱的发布,特定领域的知识图谱构建成为研究热点问题,并逐渐渗透到金融、工业和医学领域[2]。知识图谱的本质是连接实体间关系的图,即揭示实体之间关系的语义网络[3],在实现知识可视化的同时,也可以挖掘知识单元或知识群之间隐含的复杂关系[4]。知识图谱技术作为新一代人工智能的关键通用技术[5],在推动人工智能从感知智能向认知智能的跨越中扮演着重要角色。国家自然科学基金(national natural science foundation of China,NSFC)作为我国资助基础研究的主体之一,其所资助的项目在一定程度上代表了国内基础研究领域的热点和方向。本文通过对NSFC在知识图谱研究资助项目的分布情况、研究热点及前沿的计量分析,系统梳理了基础研究领域知识图谱技术的研究进展。
1 资料与方法
1.1 数据来源在NSFC 官网[6]立项项目中,以“知识图谱”、“知识地图”为关键词检索相关研究,检索时间1997至2019年。
1.2 数据预处理(1)数据库建立:将检索结果分批导入到Excel 软件,提取立项项目标题、所属学部、项目类型、项目编号、项目金额、负责人、单位、批准年份等信息。(2)项目初筛及预处理:首先根据项目标题剔除与知识图谱无关的项目。对项目单位信息进行预处理,将同一大学或科研院所附属研究所统一合并为该大学或科研院所,如“中国科学院北京基因组研究所、中国科学院沈阳自动化研究所、中国科学院大连化学物理研究所”统一为“中国科学院”。(3)主题词提取及预处理:对纳入项目的标题进行分词处理,在分词处理时遵循以下原则:①拆分,最小完整意义拆分,保留具有实际意义的最小完整词汇,如“异质信息网络的多粒度表示与知识获取方法研究”拆分为“异质信息网络、多粒度、知识表示、知识获取”;②剔除,剔除标题中部分通用表述或无特定含义的词汇,如知识图谱、机制、研究、关系、作用;③统一,对同一含义的主题词统一为多数研究采用的表述,英文缩略词统一为相应的中文表述,如“DEA”统一为“数据包络分析”;④合并,将同一研究领域内的具体分子物质、通用技术等合并为其上级概念,如“知识抽取”、“知识发现”等相同概念统一为“知识获取”。
1.3 主题词共现分析及可视化(1)数据格式转换:将完成预处理的项目信息表(.xlsx) 整理为“CNKI-EndNote 格式”,另存为“制表符分隔的文本(.txt)”文件后将制表符替换为空格,将每条题录最后增加两空行,将项目信息表转换成可视化软件VOSViewer (Version 1.6.15)[7]可读取的文章题录信息形式:%0 Journal Article;%A 辜丽川;%+安徽农业大学;%T 基于知识图谱的农业大数据碎片化知识发现方法研究;%D 2017;%K 农业;大数据;碎片化知识;知识发现;%W CNKI。(2)主题可视化网络构建及聚类:将“.txt”题录文件导入VOSViewer 软件,构建主题词可视化网络,采用软件网络聚类算法进行聚类分析。VOSViewer网络聚类算法类似于Modularity方法(公式1),能够实现聚类内部各元素间较高的相似性,不同簇间存在较高的相异性。

公式中,Wij=2m/cicj,ci为元素i 所属的聚类,δ (ci,cj)表示的方程值为1 (若ci=cj)或0;γ为聚类的分辨率,γ越大则得到的聚类越多,分类就越细。(3)主题词时间叠加网络:在上述主题词网络的基础上,以主题词出现的平均年度为依据,构建主题词时间叠加网络。将主题词可视化网络及时间叠加网络导出为“.png”格式。
2 结果
2.1 一般情况描述自1997—2019 年,共检索到立项项目2 069项,剔除无关项目后共纳入141个项目,总资助金额8 916.5 万元,共涉及9 种项目类型(表1),其中面上项目、联合基金项目、青年科学基金项目是主要立项类型,共计123项(88%),资助总额6 860万元(76.93%),见图1和图2。

图1 各年度项目立项项目数分布

图2 各年度项目立项总金额分布
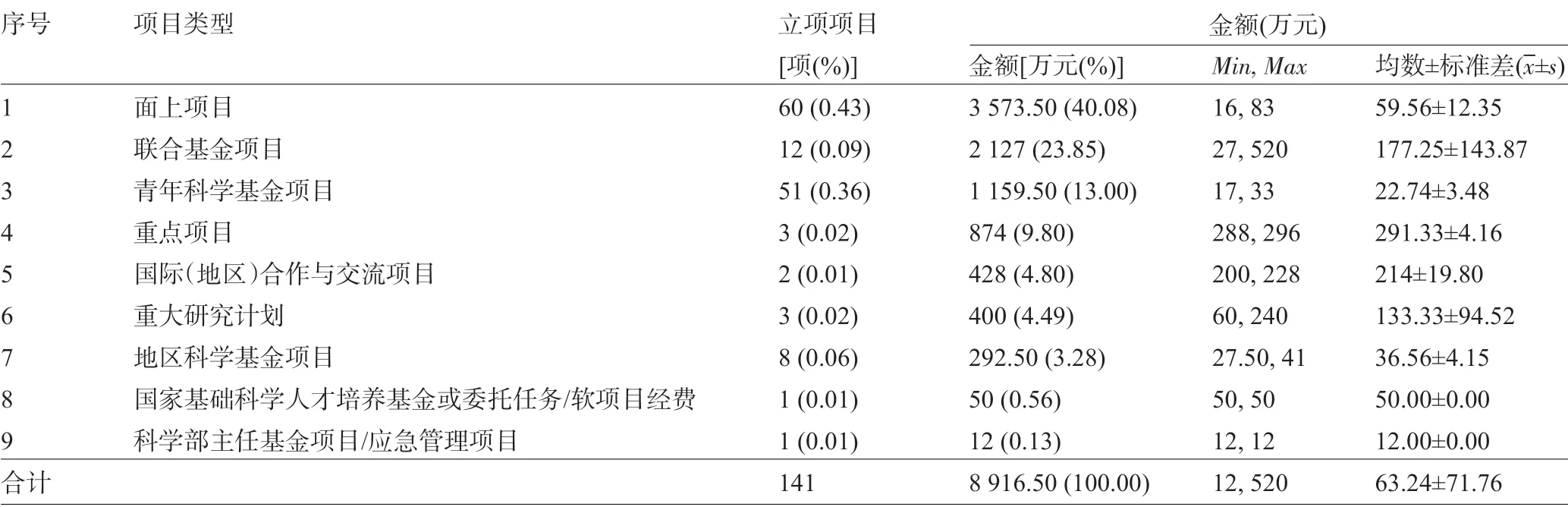
表1 立项项目类型及金额分布
纳入项目主要分布在7 个学部,立项项目数目及资助金额前3 位的学部为信息科学部、地球科学部和管理科学部(表2),其中信息科学部立项项目94 项(66.67%),资助金额6 698万元(75.12%)。17个知识图谱研究涉及生命医学内容,在学科领域分布上,中医学领域7 项,藏医学1 项,现代医学6 个,生命科学3项;分布在医学科学部8 项、生命科学部4 项、信息科学部4项,管理科学部1项。

表2 各学部立项项目及金额分布
纳入项目分布在81家单位,资助金额前3位的单位为中国科学院,浙江大学和中国人民大学(表3),三家单位共立项项目16 项(11.40%),资助金额2 065 万元(23.16%)。

表3 各单位立项项目及金额分布(前10位)
2.2 主题词分析纳入项目共包含274 个主题词,共出现频次486 次,出现频次前10 位的主题词包括:图谱构建(36,7.4%)、大规模(12,2.5%)、模型(11,2.3%)、大数据(11,2.3%)、关系推理(10,2.1%)、图谱查询(8,1.6%)、文本(8,1.6%)、中医学(7,1.4%)、语义网络(7,1.4%)、个性化(7,1.4%)。构建主题词的可视化网络(图3),对其进行聚类分析并构建时间叠加网络(图4)。主题词可视化网络(图3)中,节点代表主题词,主题词频次越高,节点直径越大;节点间的连线表示两主题词在同一项目标题中出现,共同出现频次越高,连线越粗(下同)。节点的颜色用于表示不同聚类,颜色相同的节点属于同一聚类,纳入主题词共分为5个亚类,聚类一(红色)围绕知识图谱技术模型,主要涉及“模型、大规模、关系推理、图谱查询、图谱分析、图谱补全、分布式”等主题词;聚类二(绿色)以围绕医学领域知识图谱应用,主要涉及“中医学、医学、可视化、深度学习、知识发现”等主题词;聚类三(蓝色)围绕图谱构建,主要涉及“文本、语义网络、动态、时空”等主题词;聚类四(黄色)围绕人工智能,主要涉及“个性化、推荐、自动化、智能化、机器人、在线”等主题词;聚类五(紫色)围绕数据应用,主要涉及“大数据、社交媒体、社交优化”等主题词。主题词时间叠加网络(图4)中,节点颜色表示该主题词出现的时间,每个主题词的出现时间为其所在项目立项年度的平均值(下同),从图中可以看出,“模型、主题模型、知识发现、图谱分析、时空、人工知识”等主题词为早期研究热点,“云制造、深度学习、强化学习、神经网络、体制、嵌入式、多源数据、多目标协同”等主题词为目前研究前沿热点。对纳入研究的17 个生命医学相关项目主题词进行亚组分析,构建主题词可视化网络(图5),共计62 个主题词,出现87 次,其中“中医学(7,8%)、医学(6,6.9%)、图谱构建(4,4.6%)、古籍(3,3.4%)、知识发现(3,3.4%)”为出现频次前5 位的主题词。上述主题词可分为5个亚类,其中聚类一(红色)围绕现代医学,主要涉及“生物、知识库”等主题词;聚类二(绿色)围绕中医学,主要涉及“古籍、知识发现、可视化、本体”等主题词;聚类三(蓝色)围绕图谱技术,主要涉及“图谱构建、非完整数据、个性化”等主题词;聚类四(黄色)围绕体质研究,涉及“体质、动态”等主题词;聚类五(紫色)围绕针灸研究,涉及“针灸知识、古代、框架”等主题词。

图3 纳入项目主题词可视化网络

图4 纳入项目主题词时间叠加网络
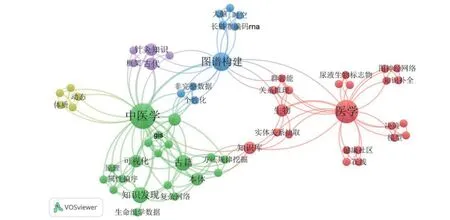
图5 生命医学领域项目主题词可视化网络
主题词时间叠加网络(图6)提示“医学、决策模型、群智能、关系推理、图神经网络、知识补全、健康社区、体质、动态”等主题词为目前研究前沿热点。

图6 生命医学领域项目主题词时间叠加网络
3 讨论
从NSFC 在知识图谱研究资助课资助力度来看,自2003 年起不同类型项目的立项数量及总资助金额呈现波动中增长的趋势,其中青年科学基金项目在立项数量方面总体增长态势较为明显,但资助金额整体水平并不高,平均资助金额有限;面上项目在项目数量及资助总额呈现稳步增长趋势,是NSFC 在知识图谱资助的主要类型。根据NSFC“十三五”发展规划[8],将科学基金资助格局调整为探索、人才、工具、融合四大系列,在知识图谱领域立项项目主要分布在探索系列和人才系列,近几年主要资助融合系列及探索系列项目,工具系列的研究一直偏少。从立项项目学部分布情况来看,信息科学部为知识图谱的热点学部,相交于其他学部NSFC 立项项目和金额数占据绝对优势。在生命科学和医学科学部,也可看到知识图谱相关研究立项,但目前资助力度还处于较低水平,个别生命医学领域知识图谱研究立项在其他学部。从立项项目单位分布情况来看,知识图谱领域NSFC 的26.95%支持在前10位的单位,其中中国科学院的立项项目数目及基金总量均位于首位,其次为浙江大学与中国人民大学,一定程度上反映出NSFC 项目对研究基础的要求相对较高。
在研究关键词分析方面,限于项目公示信息的限制,本研究根据立项项目标题进行了主题词的拆分和预处理,虽然一定程度上引入了新的偏倚风险,但考虑研究标题对一个NSFC 项目的重要性,以其作为研究主题分析数据源,还是能够最大程度上保留研究的原意。从研究主题词分布来看,“知识获取、创新、企业”等主题词频率远远高于其他主题词,这也反映出NSFC资助基础研究的战略定位。对知识图谱领域高频主题词的聚类分析提示,目前NSFC 在知识图谱领域资助的项目主要围绕图谱技术模型、医学应用、图谱构建、人工智能、数据应用等形成了五大热点研究领域,根据主题词的时间叠加网络图(图4),可以清晰的看出,主题词平均出现时间主要集中在2014—2019年,这与本时段NSFC 立项项目数量整体较高有关,“云制造、深度学习、强化学习、神经网络、体制、嵌入式、多源数据、多目标协同”等成为我国基础研究领域知识图谱研究前沿。在生命医学领域内,围绕现代医学、中医学、针灸、体质、图谱技术形成五个研究热点领域,其中“医学、决策模型、群智能、关系推理、图神经网络、知识补全、健康社区、体质、动态”为当前研究前沿。
从目前NSFC在知识图谱研究资助项目分布情况来看,资助项目数量波动式上升,资助金额总量变化较大,研究主题丰富度逐渐增加,主要分布在探索系列和人才系列研究,融合系列有明显提升,工具系列研究依旧薄弱,学科交叉型及成果转化型研究有待进一步提高。知识图谱研究已经渗透到金融、工业和医学领域,对知识图谱的定量和定性特征的科学理解已经成为大数据、智能化时代科学研究中一个基础性研究方向。在医学特别是中医学领域有着广阔的应用前景,目前已在中医百科系统、中医智能问答、临床辅助决策、数据挖掘分析领域进行了很多有益的尝试[2],但目前我国基础研究领域知识图谱研究仍偏于技术应用层面,知识图谱关键基础技术研究有待进一步加强深化。
