基于GF-1和Sentinel-2时序数据的茶园识别
2021-10-12张赫林金志凤
柏 佳,孙 睿※,张赫林,王 岩,金志凤
(1.北京师范大学地理科学学部,遥感科学国家重点实验室,北京 100875;2.北京师范大学地理科学学部,北京市陆表遥感数据产品工程技术研究中心,北京 100875;3.中国科学院空天信息创新研究院/数字地球科学重点实验室,北京 100094;4.中国科学院大学,北京 100049;5.浙江省气候中心,杭州 310002)
0 引 言
茶树是中国重要的经济树种,近年来茶园面积大幅增长[1-2]。茶树的扩张种植能够促进区域的经济发展,但是单一的树种会降低生态系统的生物多样性,加速水土流失、土壤酸化等生态环境问题[1,3-4],及时掌握茶园的空间分布信息对茶园的生态管理、环境保护以及茶叶灾害的监测预警具有重要意义。中国茶园大多分布在地形复杂的山区,地块破碎,分布零散,形状差异大、植被混杂且茶园所处环境长期受到云雨的影响,增加了茶园遥感提取的难度与不确定性,因此有必要研究遥感提取茶园的方法,来获得较好的茶园识别精度。
近年来,遥感影像成为茶园提取的常用的数据来源[5],例如,马超等[6]利用30 m空间分辨率的Landsat8和250 m空间分辨率的MODIS数据对福建省安溪县茶园进行了提取,总体分类精度达到 85.71%;Zhu等[7]基于多时相 Sentinel-2的 10 m多光谱数据,基于随机森林提取茶园,生产者精度和用户精度分别达到96.57%和96.02%。但由于中国茶园大多分布在地形复杂的山区,地块破碎,分布零散,形状差异大,10~30 m空间分辨率的遥感数据不足以分辨小面积的茶树种植区[8-10]。随着遥感技术的发展,地物细节突出的更高空间分辨率遥感影像为茶园识别提供了新途径[10-11],其包含的纹理信息是解决茶园与其他植被光谱混淆的有效方法[12]。一些研究结合高空间分辨率遥感数据的纹理特征和光谱特征成功提取了茶园并取得较好的分类精度[13-15]。但是,在高分辨率遥感图像上,农作物与茶园的光谱特征和纹理特征十分接近,难以区分。归一化差值植被指数(Normalized Difference Vegetation Index,NDVI)的时序信息可以反映茶园与农作物的季节变化及物候期,通过比较茶园与农作物 NDVI季节变化的相似性,可将部分农作物与茶园区分开来。因此,有必要结合茶园与农作物 NDVI的时序相似性提高二者的可分性[16-20]。基于动态时间序列归整算法(Dynamic Time Warping,DTW)计算的DTW距离能够有效地度量两个时序数据的相似性,目前已被证明是基于时序特征研究地表覆盖分类的有效信息[21]。然而,高空间分辨率的卫星重访周期长,且茶树种植区多云雾、多阴雨的特点造成时序数据的大量缺失[22-23]。目前,基于时空融合算法,将高空间分辨率数据的空间信息与中低空间分辨率的时间信息融合是解决时序数据难以获取的有效手段[24]。
综上所述,中低空间分辨率的遥感影像难以识别小面积的茶园,单一时相的高空间分辨率遥感影像的光谱信息和纹理信息无法很好地区分部分农作物与茶园。表征NDVI时序相似性信息的DTW距离是提高农作物与茶园可分性的重要特征,但受云雾的影响,完整的 NDVI时序数据难以获取。针对以上问题,本文基于时空融合算法构建时序NDVI,并结合高空间分辨率遥感影像的光谱特征和纹理特征研究茶园提取的方法,旨在及时掌握茶园分布,以期为茶园的管理及政策制定提供参考。
1 研究区与数据
1.1 研究区概况
研究区王宅镇隶属浙江省金华市武义县,位于武义县中心,面积达101.7 km2,为武义县第二大镇。王宅镇境内四周丘陵起伏,西北地势高峻,多峡谷丘陵,中部平坡盆地,土壤肥沃。气候为亚热带季风气候,气候温和,光照充足,雨量充沛,年平均温度 16.7 ℃,年平均降水量1 450 mm。茶树和农作物为当地主要的经济作物,茶树属于常绿灌木,大多种植在丘陵地带,农作物类型主要包括水稻、玉米、马铃薯、油菜等,主要分布在平原地区。研究区如图1所示。
1.2 遥感数据和预处理
所用数据包括 GF-1数据、Sentinel-2地表反射率数据和MODIS地表反射率产品(MCD43A4)。
为了降低其他植被对茶树识别的影响,同时考虑到遥感数据的质量,本文选取2017年冬季(2017年12月28日)覆盖研究区的GF-1 2 m全色和8 m多光谱数据为主要数据源。基于地面调研得到的地面控制点(Ground Control Point,GCP)结合更高空间分辨率的影像(Google Earth)对GF-1影像进行几何精校正,辅以ASTER DEM数据对GF-1数据进行正射校正,然后利用Gram-Schmidt融合方法将2m分辨率全色波段和8 m分辨率多光谱数据融合,得到2 m分辨率多光谱影像。
由于研究区农作物类型众多,物候复杂,仅基于几期 NDVI数据来区分农作物与茶园难以实现,因此需要更加完整的 NDVI时序数据来提高农作物与茶园的可分性。然而,由于研究区全年多云多雨,完整的Sentinal-2时序NDVI难以获取,因此,本文利用时间分辨率为1 d的MODIS反射率产品MCD43A4对Sentine-2 数据进行时空融合得到完整的时序NDVI。
2017年研究区仅有9期Sentinel-2数据可用,可用数据日期分别为2017年2月28日、2017年4月29日、2017年7月18日、2017年9月16日、2017年10月1日、2017年10月31日、2017年12月10日、2017年12月20日和2017年12月2日。本文基于Google Earth Engine(GEE,https://earthengine.google.com/)平台对Sentinel-2和MCD43A4数据进行质量控制后分别计算并提取了研究区2017年可用的9期Sentinel-2和2017年全年MODIS NDVI时序数据;利用 IDL平台对 MODIS NDVI时序数据进行插值和Savitzky-Golay(SG)滤波;最后基于贝叶斯最大熵(Bayesian Maximum Entropy,BME)时空统计的多源遥感数据融合方法[25-26],融合MODIS和Sentinel-2的NDVI得到时空完整、时间分辨率5 d的10 m空间分辨率NDVI时序,为了避免空间统计估计中的空间平滑效应,本研究只采用了时间协方差进行融合,并对融合结果进行SG滤波[27]。
2 研究方法
利用基于时空融合算法重建的Sentinel-2 NDVI时序数据,采用DTW算法计算茶园样本与待分像元的DTW距离,用来表征茶园与待分像元的时相差异;结合GF-1的光谱特征和基于灰度共生矩阵(Gray Level Co-occurrence Matrix,GLCM)计算的纹理特征,选择两种数据组合方案(包括和不包括DTW距离),利用随机森林算法提取茶园并进行精度检验,技术路线如图2所示。
2.1 分类特征提取
2.1.1 光谱特征和纹理特征
光谱特征包括GF-1多光谱数据的光谱信息(包括近红外、红光、绿光和蓝光波段)和基于光谱信息计算的单期NDVI。纹理特征由GF-1全色波段数据,以15为纹理提取窗口,基于GLCM计算包括均值(mean)、方差(variance)、同质性(homogeneity)、对比度(contrast)、非相似性(dissimilarity)、熵(entropy)、角二阶矩(angular second moment)和相关性(correlation)8个纹理特征[28-29]。
2.1.2 NDVI时序相似性
研究区平原地区存在大面积的冬种农作物,其纹理和光谱特征与茶园非常相似,易造成二者的混分。为有效区分茶园与农作物,提高茶园的分类精度,本文采用DTW算法[21,30],计算待分像元与茶园样本NDVI时序的相似性,该算法以两个时列之间的距离来度量时序的相似性,两个时序的相似性越高,则二者时序变化越相似,属于同一地物类型的可能性越大。DTW算法的特点是可以自动寻找目标曲线和参考曲线的最佳对齐方式,该方式对应两条曲线距离最短,最短距离即为DTW距离,也就是两个时序的相似度,距离越短,相似度越大[31-32]。
2.2 分类方法及精度评价
为了评估加入 NDVI时序特征对茶园提取的影响,选择两种特征组合方案进行分类。方案 1:仅基于 GF-1的光谱特征和纹理特征;方案2:GF-1数据的光谱特征、纹理特征结合DTW距离特征。分类方法采用随机森林分类方法。随机森林是广泛使用的基于集合的分类器,由若干个分类决策树组成,每个决策树为像素提供一个类别标签,最终获得投票数最多的类别标签即为该像素的类别[33-34]。随机森林在处理高维数据时具有灵活性和速度优势,并且可以解决过度拟合的问题[35-36]。
结合实地调研及更高分辨率的Google Earth图像选取茶园(49 128个像元)与非茶园(552 311个像元)训练样本进行分类,样本分布如图1,分类工作基于Python平台实现。
为了验证分类精度,结合Google Earth对研究区的茶园进行目视判读,并利用目视判读结果随机生成1 008个茶园和1 095个非茶园验证图斑,验证图斑分布如图1所示。基于混淆矩阵,采用准确率、错误率、精确率、召回率和F1分数进行茶园识别精度评价[37]。
3 结果与分析
3.1 Sentinel-2 NDVI的时空融合结果与NDVI时序相似性分析
研究区平原地区存在大面积的冬种农作物,其纹理和光谱特征与茶园非常相似,容易造成二者的混分。为了有效区分茶园与农作物,提高茶园的分类精度,本文基于时空融合获得完整的NDVI时序数据并利用DTW算法计算茶园样本与待分像元的DTW距离表征NDVI时序的相似性。图3a显示了2月8日NDVI的融合结果,该日研究区被云层完全覆盖,无可用的 Sentinel-2数据。图3b为2月28日实际Sentinel-2的NDVI图像,时空融合后的NDVI图像完整,较高值分布在北部和南部山区,较低值分布在中部城区,分布较为合理,地物细节突出,与2月28日实际Sentinel-2的NDVI相比,二者空间分布较为接近,说明基于MODIS和Sentinel-2 NDVI时序数据的时空融合结果可以用于茶园的提取。
基于DTW算法计算茶园样本与待分像元NDVI时序的DTW距离如图4所示。茶园样本与茶园的DTW距离基本小于4,并主要分布在山区;由于常绿林的NDVI时序与茶园相似,研究区西北部的林地与茶园样本的DTW距离基本小于4,南部地区的林地与茶园样本的DTW距离在4~8之间;农作物与茶园的NDVI时序差异较大,二者NDVI曲线的相似性较低,平原区农作物与茶园样本的DTW距离基本大于4;水体、建筑物和裸地等非植被的NDVI时序与茶园具有显著差异,其DTW距离基本大于16。DTW距离的计算结果细节突出,有助于区分农作物与茶园。
3.2 分类结果与精度验证
3.2.1 茶园提取的空间分布结果
基于两种特征组合茶园的分类结果如图5所示。总体而言,两种特征组合提取的茶园空间分布较为一致。可以看出,研究区的大片茶园主要分布在西北和中部山区,中部平原地区分布较零散,面积较小。对于山区大片的茶园,二者的分类结果相似,均能较好地提取出茶园;在平原地区,添加DTW距离的茶园分类面积明显小于未添加DTW距离的分类面积,这主要是由于将光谱和纹理特征与茶园相似的部分农田与茶园区分开来,说明添加DTW距离能够有效降低茶园与农作物的混分,提高茶园的分类精度。
3.2.2 精度评价
基于混淆矩阵的精度评价如表1所示。添加DTW距离的准确率为 96.91%,错误率为3.09%,茶园提取的精确率为89.00%,召回率为83.09%,F1分数为0.86;未添加DTW距离的分类结果的准确率94.72%,错误率为5.28%,茶园提取的精确率为73.09%,召回率为84.61%,F1分数为0.78。添加DTW距离的准确率较未添加DTW距离提高2.19个百分点,错误率降低2.19个百分点,精确率提高15.91个百分点,召回率略微下降(1.52个百分点),但是两种方案的召回率相差不大,F1分数提高0.06,说明添加DTW距离的分类性能较好,茶园提取的精确率较高。
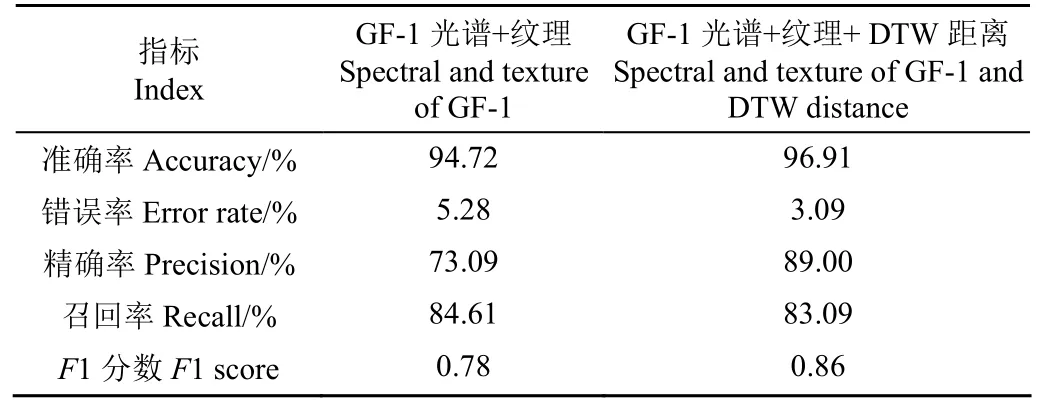
表1 不同特征组合的茶园分类结果精度评价Table 1 Accuracy assessment for extraction of tea plantations based on different feature combinations
加入DTW距离茶园的提取结果召回率略微下降,造成召回率略微降低的原因可能有:1)为了降低茶园种植造成的水土流失等问题,茶园内部和周围会种植一些较高树木,GF-1的空间分辨率较高,导致其内部和周围存在这些树木的阴影。阴影的NDVI时序的DTW距离与茶园存在差异,添加DTW距离后,会减少部分原本是茶园的识别;2)DTW 距离是基于融合后的 NDVI计算的,其空间分辨率是10 m,与GF-1的2 m分辨率相比,较粗空间分辨率的DTW距离的边界锯齿状现象更加明显,因此添加DTW距离特征时,茶园提取的部分边界不及未添加DTW距离时完整和平滑,因此会造成茶园的召回率略微下降。
添加DTW距离的茶园分类的精确率显著提高(提高15.91个百分点),说明未加入DTW距离的茶园分类面积明显偏大,将非茶园的地类(如农作物)错分为茶园,茶园的多分现象导致精确率比较低;而加入 DTW 距离后,由于茶园的NDVI时序与农作物NDVI时序存在明显差异,会显著降低农作物与茶园的混分,减小了茶园的多分现象,分类结果更加可靠。
4 讨 论
本研究主要探讨利用高空间分辨率遥感影像结合时序信息提取茶园的方法。马超等[6]使用中空间分辨率的Landsat影像提取山区茶园,分类总体精度为85.71%。杨艳魁等[38]使用GF-2影像提取茶园,加入纹理信息后总体精度达到89.8%。徐伟燕等[13]使用资源三号卫星数据,加入纹理信息作为分类特征,山区与平原地区的茶园提取精度分别达到92.97%和95%。本研究仅基于GF-1光谱与纹理信息茶园提取的准确率达到94.72%。先前茶园提取的研究中,首先确定茶园与其他植被有差异的时间窗口,并以该时间窗口的影像作为时序特征。例如,马超等[6]使用时序MODIS植被指数确定基于Landsat影像的茶园提取的最适窗口为10月份,选择该月份Landsat影像进行茶园分类,造成了茶园与林地、果园及其他植被类型的混分。赵晓晴等[39]仅使用三期Sentinel-2A数据作为时序特征,使用不同植被在 3期的差异构建决策树。本研究加入时序特征主要区分茶园与农作物,而不同的农作物生长季不同,仅使用某一个时间窗口的数据或较少的时序数据可能并不适用于区域内所有的农作物。因此,本研究基于Sentinel-2反射率数据与MCD43A4反射率产品进行时空融合获得完整的 NDVI时序数据,加入NDVI时序信息茶园提取的准确率达到 96.91%,较未添加NDVI时序信息提高了2.19个百分点,由于茶园占比较小,因此总体精度提高不多。但是添加 NDVI时序信息茶园提取的精确率较未添加NDVI时序信息提高15.91个百分点,说明添加时序信息能够有效提高茶园提取的精度。
但是本研究仍存在一些不确定性。首先,茶树种植区多云雾、多阴雨,难以获取高质量的时序数据,为了弥补时序数据难以获取的不足,本研究利用中低分辨率的MODIS时序数据对Sentinel-2的数据进行了时序重建。在云量较大的时期,MODIS数据本身存在误差且MODIS与Sentinel-2数据的空间分辨率差距较大,尽管MODIS高时间分辨率的特点基本能够捕捉植被物候的差异,但是融合效果还是存在一些不确定性。在未来的研究中,需考虑影像质量对融合精度的影响,尝试利用空间分辨率较高的数据来融合时间分辨率较低的GF-1数据,进一步提高茶园提取精度。其次,本研究仅使用GF-1数据为主要数据源,目前已有增加了能够有效反映作物特有光谱特性的“红边”波段的GF-6数据。在未来的研究中,可以尝试结合GF-1和GF-6来弥补GF-1时间分辨率较低的不足,及结合GF-6的“红边”波段,来提高茶园的提取精度。
5 结 论
本文通过对MODIS地表反射率产品和Sentinel-2反射率数据的时空融合,在获得10 m空间分辨率的NDVI时序数据的基础上,结合GF-1的光谱信息和纹理信息,利用随机森林方法进行了茶园分类,结果表明:
1)高时间、低空间分辨率的MODIS数据和高空间、时序不完整的Sentinel-2数据的融合,进而得到完整的时序归一化差值植被指数(Normalized Difference Vegetation Index,NDVI),及在此基础上计算的动态时间序列归整距离(Dynamic Time Warping distance,DTW distance)能够捕捉不同地物NDVI时序的差异,可用于茶园提取。
2)基于GF-1光谱、纹理信息结合DTW距离茶园分类结果的准确率、错误率、精确率、召回率和F1分数分别为 96.91%、3.09%、89.00%、83.09%和 0.86,仅基于GF-1光谱和纹理信息茶园分类的准确率、错误率、精确率、召回率和F1分数分别为94.72%、5.28%、73.09%、84.61%和 0.78。相对于仅基于光谱和纹理特征的分类结果,添加DTW距离的茶园分类精度有较大幅度提高,精确率和F1分数分别提高了15.91个百分点和0.06,主要是由于时序信息的添加降低了茶园与平原地区农作物的混分,表明高分辨率结合时序信息是提高茶园分类精度的有效手段。
