基于改进LSTM-SVM的多传感器船舶旋转机械快速故障诊断方法
2021-10-11宫文峰WANGDanwei
宫文峰,陈 辉,WANG Dan-wei
(1.武汉理工大学航海与能源动力工程学院;高性能舰船技术教育部重点实验室,武汉 430063;2.新加坡南洋理工大学电子与电气工程学院,新加坡 639798)
0 引 言
近十年来,我国在国产航空母舰、新型战略核潜艇和新一代电力推进器等海洋工程装备研制方面取得了飞跃式突破性进展,中国已成为世界第一造船大国和世界航运第一大国[1-2]。高技术舰船是保障国家海洋主权和实现“海洋强国梦”的重要载体,目前正朝着智能化、自动化和无人化方向发展[3]。旋转机械是船舶装备中最重要的类型之一,水面舰艇包含有大量的旋转机械,诸如推进电机、齿轮箱以及各类支撑轴承等。在复杂的海况环境下,此类旋转机械长期运行于高温、高压和变载荷的工况中,且受湿热和盐碱等环境影响而易于发生各种故障[4-7]。然而,船舶作为“独立”航行于海上的复杂系统,一旦关键部件发生故障,若不及时处理将影响船舶的正常运行,甚至导致重大损失及灾难性后果[8]。因此,研究智能、高效和快速的故障诊断技术对保障船舶的安全运行至关重要。
目前,传统的基于模型、知识和浅层机器学习算法的故障诊断方法已难以适应当前“数据爆炸”环境下的应用要求[6]。随着产品复杂度的提升,期望通过建立高精度的数学模型对故障演化机理进行描述愈加困难,并且随着新产品、新工况和新故障的不断更新,期望建立完备的故障诊断知识库以涵盖所有故障类型更加不切实际[9-10]。目前主流的基于支持向量机(SVM)、K近邻(KNN)、极限学习机(ELM)和人工神经网络(ANN)等浅层机器学习算法的智能诊断方法常因浅层网络结构简单而导致特征提取能力不足,无法取得更加优越的诊断效果[11]。为弥补这一不足,业内学者分别尝试采用小波变换(WT)、经验模态分解(SA)和快速傅立叶变换(FFT)等多种先进信号处理技术与浅层机器学习模型相结合的方法提高诊断性能[12-13],此类方法虽然取得了一定的效果,但是这些方法需要依赖专家经验采用多种复杂的信号处理手段用于特征提取,该操作费时、费力,且存在较大的主观盲目性[6];另外,人工提取的故障特征往往不全面,对于反映微小故障的隐蔽特征易被噪音掩盖和误删[9],并且前期设计好的特征只能解决特定的故障问题,其泛化通用性能差,尤其在处理多传感器、多通道的高维度大数据方面效果更加不理想。
近5年来,随着新一代人工智能和“工业4.0”时代的问世,基于深度学习技术的故障诊断方法得到了业内学者的广泛关注[9-10]。雷亚国等[10]提出了一种基于深度自编码网络(DAE)的旋转机械故障诊断方法;宫文峰等[6]提出了一种基于卷积神经网络(CNN)的电机轴承故障诊断方法;李巍华等[14]研究了基于深度信念网络(DBN)的轴承故障分类识别方法;Wang等[15]提出了一种基于FFT与CNN相结合的电机故障诊断方法。然而,以上研究主要集中于解决针对单一传感器的单通道时间序列数据的故障诊断问题,针对多传感器的诊断问题,Gong[9]和Xia等[16]分别提出了基于多通道CNN的故障诊断方法,然而此类方法需要采用数据重构的方法将多通道一维时间序列数据转变为二维特征图,再按照图像识别的方法用CNN进行分类诊断,该方法忽略了故障样本之间所具有的时间关联性,无法捕获故障随时间渐变的微弱演变特征,并且CNN的数据处理机制较复杂,训练和测试速度较慢。
通过分析故障演化机理可知,任何故障的演化均是一个随时间积累渐变的过程,后一时刻的故障状态均与前一时刻的故障特征有着密切关联[9]。长短期记忆循环神经网络(Long-Short-Term Memory Networks,LSTM)是一种具有长时间记忆功能的深度学习算法,具备辨识随时间渐变微小特征的潜力[17]。李冬辉等[18]和Yu等[19]分别研究了基于LSTM的故障诊断方法用于解决时间序列关联问题,然而这些方法主要解决单传感器诊断问题,没有给出多传感器诊断方案,并且使用的是针对语音识别的传统LSTM框架结构,仍然采用传统的Softmax作为分类器,无法对诊断准确率进一步提升。
针对以上问题,本文提出了一种基于改进的LSTM-SVM新算法用于多传感器监测环境下的船舶旋转机械故障快速诊断。首先,构建多层堆叠的LSTM作为深度特征提取器,对多传感器一维时间序列原始数据进行时空维度的特征挖掘,通过LSTM记忆单元和遗忘机制,捕获故障状态随时间演变过程中的微小差异性特征;其次,采用非线性SVM代替传统LSTM中的Softmax函数作为最终分类器,进一步提升故障诊断的准确率。提出的方法无需对多传感器原始数据做任何的人工特征提取操作,端到端的构架结构具有良好的通用性和可操作性。实验表明,相比现行的SVM、KNN、DNN、CNN和标准LSTM算法,提出的方法具有更高的诊断准确率和更快的诊断速度。
1 长短期记忆循环神经网络
LSTM网络是由Hochreiter等最早提出的一种具有记忆功能且专门用于处理时间序列数据的循环神经网络(RNN)[20]。LSTM不仅解决了传统BP网络和CNN算法中只凭当前输入数据判定输出状态的“信息丢失”问题,而且还解决了传统RNN在处理长时间序列数据时因长期依赖机制而容易陷入“梯度消失”和“梯度爆炸”的不足[17]。LSTM的内部结构如图1所示[18],LSTM的每个神经元都包含两条信息通道:一条为记忆通道Ct,用于存放记忆信息;另一条为当前输入数据xt与上一时刻输出ht-1的线性组合输入通道。由图1可见,LSTM不是简单地将上一时刻的状态与当前的输入一起输出,而是将状态更新和状态是否参与输入都由网络经过训练来确定[17]。LSTM引入了“门控”机制,由输入门It、遗忘门Ft和输出门Ot三个逻辑门组成[20]。
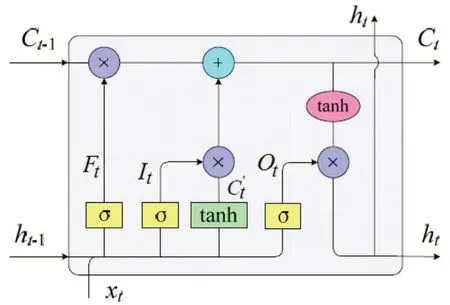
图1 LSTM神经网络的内部结构组成Fig.1 Internal structure of the LSTM neural network
1.1 输入门
输入门It用于控制当前的输入数据xt与上一时刻输出ht-1以多大程度加到记忆上,其数学表达式[18]为
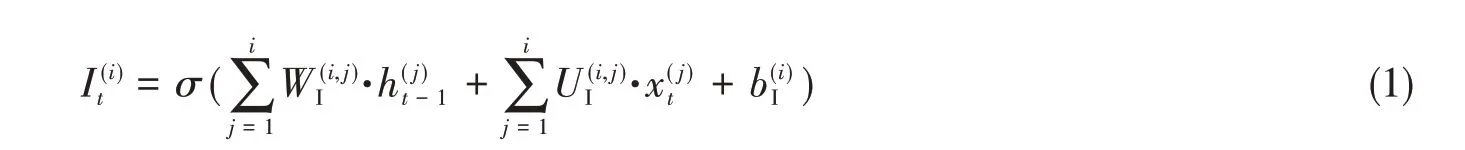
1.2 遗忘门

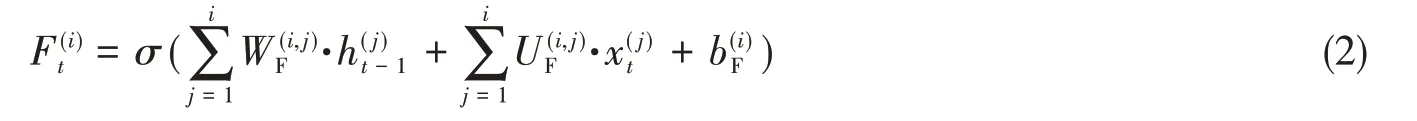
1.3 输出门
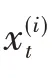

1.4 临时记忆增量
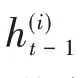

1.5 新记忆更新
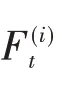

1.6 最终输出
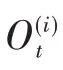

将待训练的一维时间序列数据输入到LSTM模型后,通过上述各模块的前向计算,即可得到当前时刻隐含层输出ht。在传统的LSTM中,ht再经过一个简单的Softmax函数执行符合概率分布的归一化操作,即可得到故障诊断的分类结果,然后通过对比预测值与实际标签即可计算误差值,其交叉熵损失函数表达式[19]为


2 改进的LSTM-SVM故障诊断算法
针对现行的LSTM网络和传统浅层机器学习算法的不足,本文提出了一种基于改进的LSTM-SVM新算法用于旋转机械在多传感器监测环境下的故障快速诊断,其诊断框架如图2所示。该诊断框架包含3个部分:最上层为原始数据输入层;中间层为LSTM特征提取层;最下层为SVM输出层。提出的算法通过构建多层堆叠的LSTM作为深度特征提取器,对多传感器一维时间序列原始数据进行时空维度的特征深度挖掘,通过LSTM记忆单元和遗忘机制,捕获故障状态随时间演变过程中的微小变化特征。其次,采用非线性SVM代替传统LSTM中的Softmax函数作为最终分类判别器,进一步提升故障诊断的准确率,诊断结果由SVM分类器直接输出。
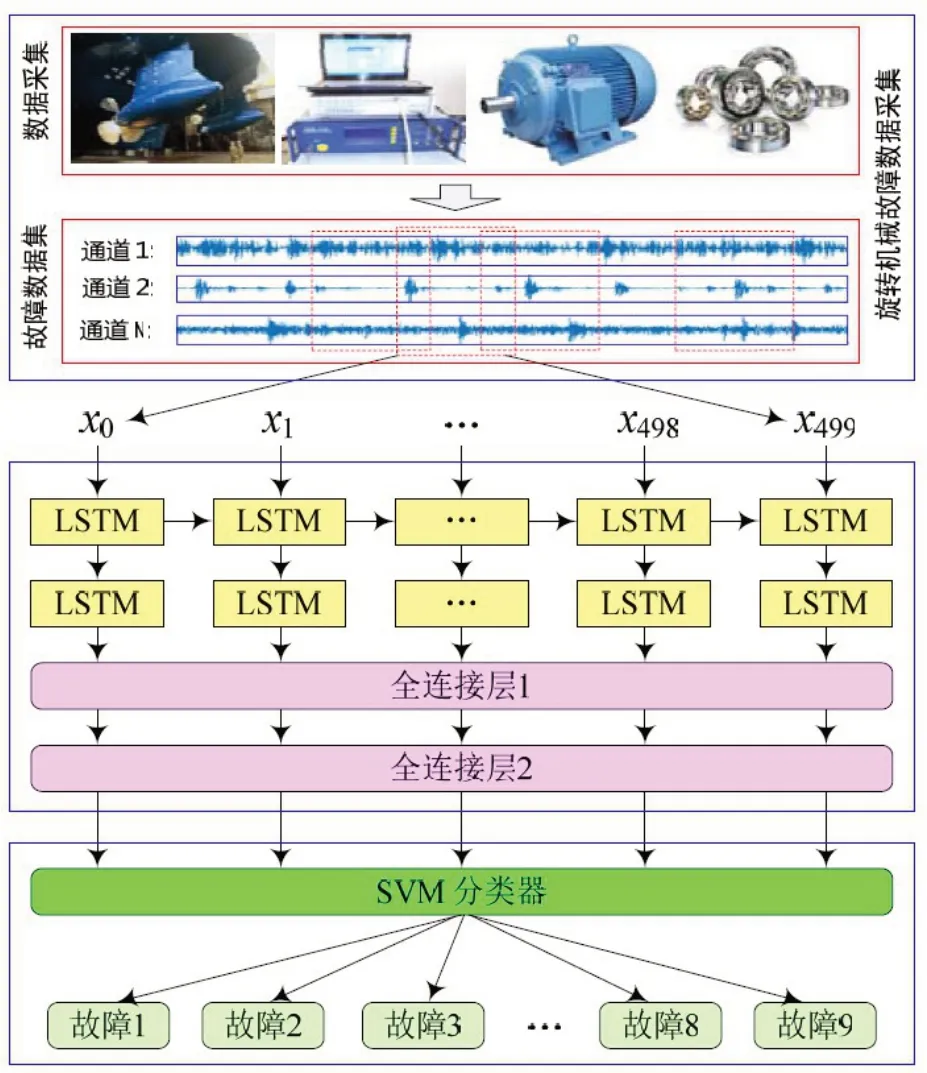
图2 改进的LSTM-SVM故障诊断模型Fig.2 Improved LSTM-SVM fault diagnosis model
提出的LSTM-SVM诊断算法的基本逻辑流程如图3所示,包含训练过程和测试过程两个阶段。在训练过程,先将LSTM与Softmax函数组合执行误差反向传播,最小化损失函数J(q),完成LSTM模型参数的训练;在模型的测试阶段,将LSTM与SVM分类器组合,由SVM完成最终的故障分类。原始的多通道一维时间序列数据直接输入提出的诊断模型,先由LSTM进行深度特征提取和数据挖掘,然后提取的低维代表特征数据再输入SVM。提出的方法无需对原始数据做任何的手工特征操作,端到端的算法结构具有良好的通用性和可操作性。

图3 提出的诊断算法流程Fig.3 Process of the proposed diagnosis algorithm
2.1 输入层
输入层用于接收多传感器原始故障数据,并对这些数据进行数据融合、数据截断、样本扩充和标准化处理等操作,将原始数据处理成LSTM-SVM模型可训练的样本格式。
(1)多通道数据融合。在实际的故障监测系统中,为了获得更多的、更全面的反映旋转机械运行状态的监测数据,通常每个监测对象和故障类型都由多种或多个传感器同时进行数据采集[9]。因此,首先要对这些数据进行融合,假设有n种故障类型,每种故障有m个监测传感器,每个传感器采集l个数据点,从而可以构建一个[n,m,l]的多维张量矩阵原始故障数据集,如图4所示。
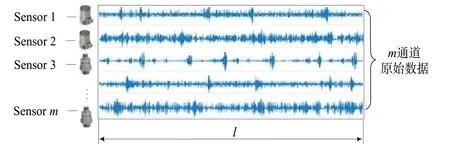
图4 多通道原始故障数据集Fig.4 Multi-channel raw fault dataset
(2)数据截断和数据扩充。
在LSTM训练过程中,若将原始的长时间序列数据一次性输入到模型,将导致计算机内存溢出而无法计算[6]。为了保留数据点之间的关联性特征、获得更多的训练样本,本文提出了一种基于滑动窗口法重叠采样的样本生成方法,如图5所示。每个样本的截取长度可根据故障频率、采集周期等确定[9]。式(8)给出了重叠采样后的样本数量计算经验公式。在图5中,假设每个通道包含2 000个数据点,通过重叠采样数据截断法,可获得6个训练样本(滑窗长度为400,步长为300,即重叠率为25%),每个故障样本的尺寸为[m,400]。由图5可见,最右侧的样本是不完整的,因此不能构成一个有效样本。
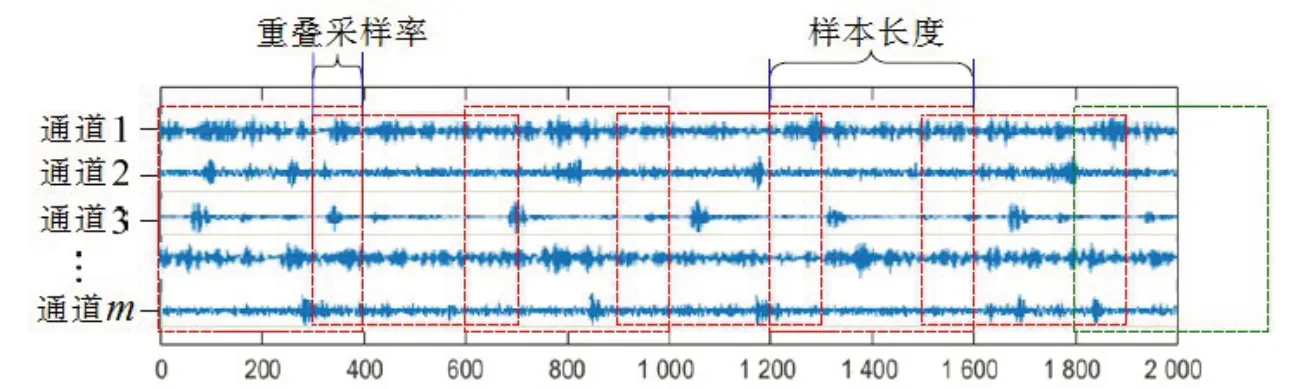
图5 滑动窗口重叠采样的数据截断方法Fig.5 Data segmentation method of sliding window overlapping sampling

式中,Inum代表输入样本的数据点个数,Wnum代表滑动窗口的长度,Snum代表滑窗步长,Tnum代表新故障样本的数量(特别注意:本公式的计算结果应当向上取整)。
2.2 特征提取层
特征提取层是改进LSTM-SVM算法的核心,由多层堆叠的LSTM层和2~3层的全连接层组成,主要用于提取隐藏于时间序列数据中的故障特征。图1所示的标准LSTM结构虽然能有效解决梯度消失问题,但是该模型仍存在一个问题,即前一时刻的记忆信息Ct-1并没有对当前时刻的输入门和遗忘门产生调节作用,造成了整个记忆单元丢失了上一个时间序列的部分信息[18]。因此,本文采用了一种改进的LSTM[18]作为特征提取器,相关表达式[18]如下:
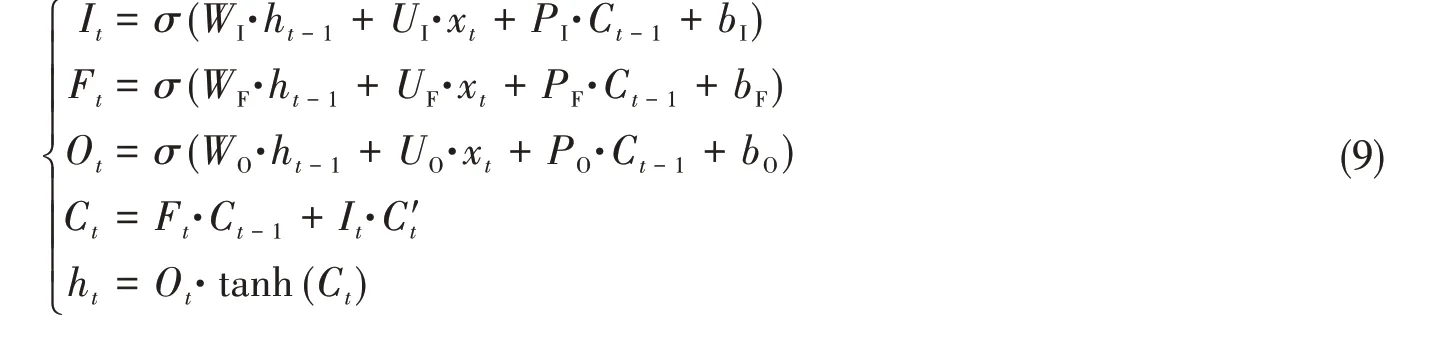
2.3 SVM分类输出层
在传统LSTM算法中,末端分类器采用的仍是Softmax函数,Softmax实质上是一个逻辑回归函数,仅对最终分类结果进行一次归一化操作[9],在多分类性能上尚不如SVM的功能强大。SVM是由Vapnik等最早提出的具有严谨数学推理的经典二分类模型[21],在解决小样本和多分类等任务中表现出了优异的性能[6]。在提出的算法中,使用了SVM代替Softmax函数作为最终分类器。非线性SVM将LSTM层输出的稀疏特征数据作为输入,通过使用核技巧[9]和软间隔最大化,在高维特征空间里构建最大软间隔分离超平面,完成最终的分类诊断,SVM的数学模型[21]为

式中,w和b为待优化参数。通过调整w和b,使得目标函数最小化,从而得到最大软间隔分离超平面[6]。本文使用高斯径向基核函数,构建的分类决策函数[9]为

3 实验验证
3.1 实验数据集
本实验使用了美国凯斯西储大学(CWRU)的滚动轴承故障实验台的实验数据[22],图6为轴承故障实验台,该实验台共布置了3个振动加速度传感器,分别安装在电动机的驱动端和风扇端的机罩外壳上以及基底上[9]。故障轴承用于支撑电机主轴,轴承型号为6205-2RS JEM球轴承[22]。该实验分别对0马力(1 797 r/min)、1马力(1 772 r/min)、2马力(1 750 r/min)和3马力(1 730 r/min)四种负载状态下的轴承振动数据进行了采集,所有数据的采样频率均为12 kHz,采样时间为10 s[23]。

图6 滚动轴承数据采集实验台Fig.6 Data acquisition experiment platform of rolling bearing
本实验选用了滚动轴承在1马力负载工况下的9种故障数据作为训练数据,9种故障分别为轴承的滚珠、内圈和外圈上植入的3个故障等级的点蚀凹坑,凹坑直径分别为0.007、0.014和0.021 in(1 in=25.4 mm)[22]。为了便于分析和计算,本实验截取所有监测数据的前10万个数据点用于构建原始故障数据集[9,3,100 000](9代表故障类别数,3代表传感器数),并由输入层对其进行必要的数据处理,主要包括:
(1)数据标准化。首先对每个故障类型的[3×100 000]的3通道数据进行均值标准化处理[23]。
(2)数据截断和重叠采样。对标准化后的数据进行数据截取,生成用于LSTM-SVM模型训练的故障样本。在本实验中,4种负载下的转速范围为1 730~1 797 r/min,12 kHz的采样频率下每秒采集12 000个点[23]。转轴每转一圈传感器采集的点数范围为400~416个点(12 000×60/1 730≈416),为保证故障数据的可信度,数据截断后每个样本的长度设置为500个数据点[6]。根据式(8)的方法,每类故障的[3×100 000]的长时间序列数据被划分为996个[3×500]的短样本(滑窗长度为500,步长为100,重叠率为20%)。为了便于分析计算,取前900个样本用于构建轴承故障总数据集,每种故障状态均包含900个样本,每个样本包含3个通道,每个通道包含500个数据点,如表1所示。
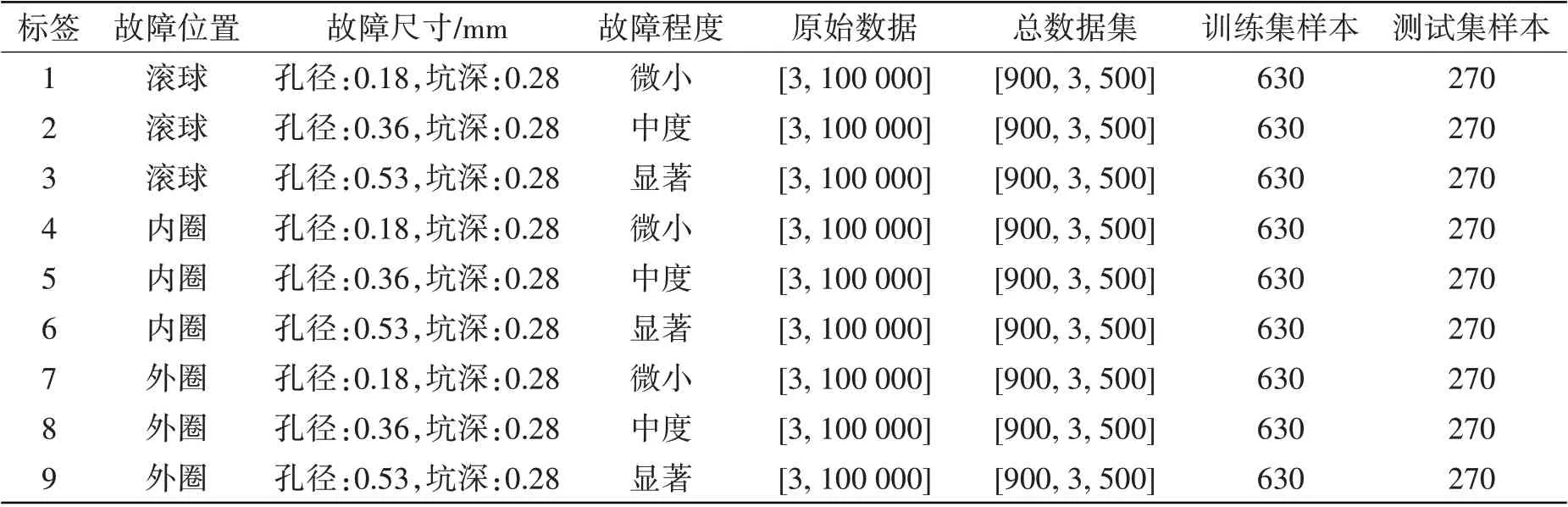
表1 滚动轴承故障数据集Tab.1 Fault dataset of rolling bearing
(3)划分数据集。将每类故障的900个样本随机地划分为训练集(70%)和测试集(30%),在训练集中再随机地取20%作为验证数据集进行交叉验证[23]。
3.2 网络超参数选择与训练过程
经过多次反复实验调参,本文采用了2层堆叠的LSTM和2层的全连接层构成特征提取层,LSTM层节点数为64、32,全连接层节点数为128、9,输入数据维度为[3×500],SVM输出维度为9。本实验采用了mini-batch小批训练法,每批次训练样本数为64,迭代轮数为100次,采用Adam自适应可变学习率优化器[23]。训练过程发现,训练集和验证集存在过拟合现象,于是在LSTM细胞结构中加入了Dropout训练技巧[23]改善过拟合问题。图7和图8分别是网络训练过程中未加入Dropout技术防止过拟合和加入Dropout防止过拟合的准确率及损失误差对比曲线图。可以看出,未加入Dropout技巧时,随着迭代次数的增加,训练集的准确率不断增加、误差不断减小,而验证集的准确率和误差到达一定值时不再改变;加入了Dropout后,上述情况明显得到解决。最终建立的诊断模型超参数如表2所示。

图7 未加入Dropout防止过拟合的网络训练过程Fig.7 Network training process without adding Dropout to prevent over-fitting
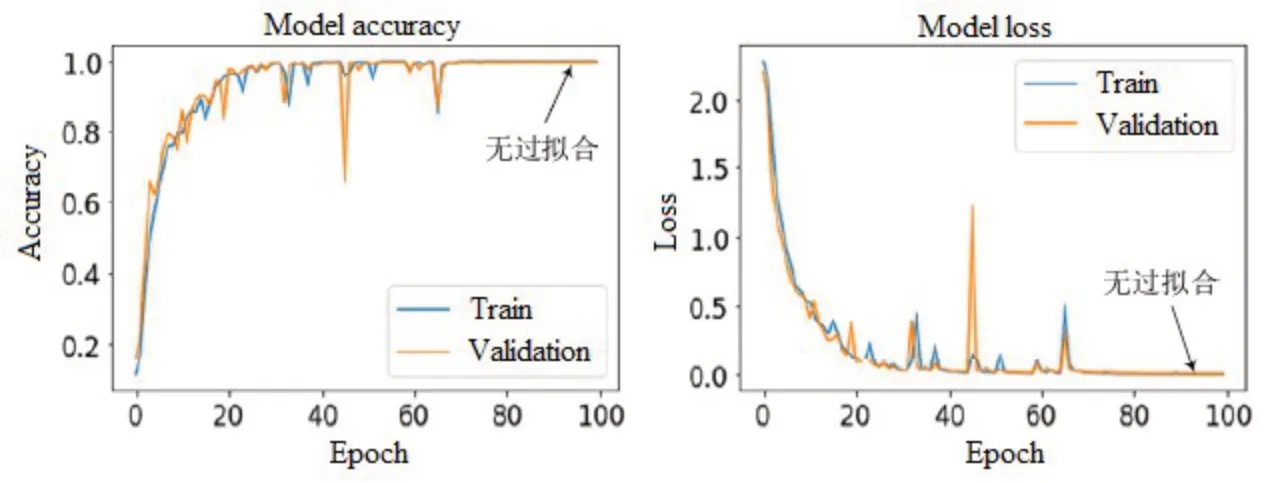
图8 加入Dropout防止过拟合的网络训练过程Fig.8 Network training process with adding Dropout to prevent over-fitting

表2 建立的LSTM-SVM诊断模型超参数Tab.2 Hyperparameters of the established LSTM-SVM diagnostic model
3.3 故障诊断结果及分析
将训练好的模型保存后,即可用测试集数据对诊断模型的性能进行测试,诊断结果见表3。为进一步量化诊断结果,本实验采用了F1-measure值[23]和多分类混淆矩阵[6]两种量化评估方法。F1值被广泛用于深度学习诊断模型的性能测评中,包含精确率和灵敏度(召回率)两个指标[9]。

表3 故障诊断结果的评估数据Tab.3 Evaluation data of fault diagnosis results
从表3中可以看出,改进的LSTM-SVM诊断模型的F1均值高达99.92%,而使用了Softmax作为分类器的传统LSTM模型的诊断准确率仅为98.77%。由此可见,提出的算法获得了较大的诊断准确率提升。在诊断时间方面,改进的LSTM-SVM的训练用时为186.72 s,虽然比传统LSTM略高出2.2 s(SVM训练时间),但是LSTM-SVM的测试时间更短,仅为0.517 s。分析原因在于训练后的SVM为一个具有固定支持向量的分离超平面,并且输入SVM的分类数据并非原始500维的高维数据,而是经过训练后的LSTM提取的维度为9的低维特征数据,因此测试速度得到了提升。图9为对应表3的两种模型的诊断结果混淆矩阵,由图9(a)可知,在2 430个测试样本中,提出的算法仅有2个样本被错误分类,2个故障6样本被误判为故障7。而图9(b)中存在30个样本被误判,误判较多的是故障6与故障7之间的混淆,分别为11故障6样本被误判为故障7,12个故障7样本被误判为故障6,分析这种误分类的主要原因是传统的LSTM对微小故障的识别能力不足。实验表明,改进的LSTM-SVM算法的诊断性能明显优于传统的LSTM算法。
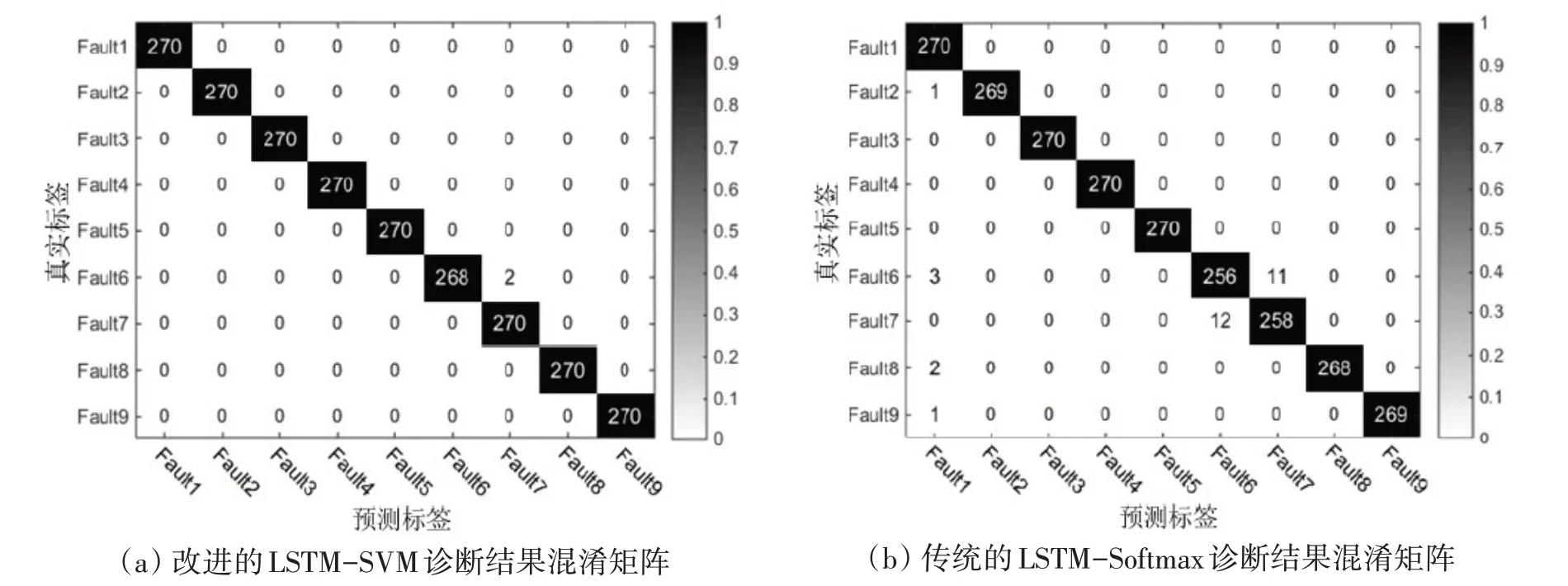
图9 故障诊断结果的多分类混淆矩阵Fig.9 Multi-class confusion matrix of fault diagnosis results
3.4 与其他智能算法的对比验证
近三年,卷积神经网络(CNN)由于具有良好的特征提取能力已被证明在旋转机械的故障诊断应用中取得了优异的效果[15-16,23-24]。为进一步验证提出的LSTM-SVM诊断算法相对于主流的智能诊断算法的优越性,本实验将表1所示的故障数据集分别用于支持向量机(SVM)、K近邻(KNN)、深层BP网络(DNN)和CNN算法进行测试。为辅助SVM和KNN进行诊断,文献[16]先对原始样本提取14个统计特征(10个时域特征、4个频域特征),然后再将每个样本的14个特征值输入到SVM和KNN进行诊断。
本实验同样采用文献[16]所提供的方法先提取波峰、峭度和裕度指数等14个统计特征,再输入到SVM和KNN进行分类诊断。DNN和CNN直接使用原始数据,实验结果如表4所示。

表4 五种算法诊断结果数据表Tab.4 Data of five algorithm diagnosis results
对比表4中的5种算法可以看出,诊断准确率从高到低排序为:LSTM-SVM、CNN、DNN、SVM和KNN。由此可见:深度学习算法明显比浅层机器学习算法拥有无可比拟的优势;虽然CNN的准确率与LSTM-SVM较为接近,但是CNN的训练时间和测试时间都远高于LSTM算法,LSTM在处理多传感器、多通道数据方面具有更显著的诊断实时性优势;在诊断时间方面,5种算法从快至慢依次为:DNN、LSTM-SVM、SVM、CNN和KNN;虽然DNN测试时间最快,但是其诊断准确率仅为96.03%,诊断性能明显低于提出的算法;另外,在微小故障辨识方面,LSTM-SVM和CNN两种深度学习算法显著优于SVM和KNN两种浅层机器学习算法。实验结果分析表明,提出的LSTM-SVM具有更高的诊断准确率和更快的诊断时间,更适用于故障的快速诊断。
3.5 不同负载工况的迁移实验
为了进一步评估提出的LSTM-SVM算法在应对不同工况负载时的诊断性能,本文进一步对滚动轴承在2马力和3马力负载下采集的3通道故障数据进行实验。迁移实验使用了与1马力负载相同的模型参数和数据处理方法,诊断结果如表5所示。
对比表5可以看出,改进的LSTM-SVM算法对2马力和3马力两种负载工况下的诊断准确率分别高达99.67%和99.51%。结果表明,提出的LSTM-SVM算法在不同负载工况下同样取得了较高的诊断准确率,具有优越的迁移泛化性能,这在实际的工程应用中具有重要的参考意义和借鉴价值。
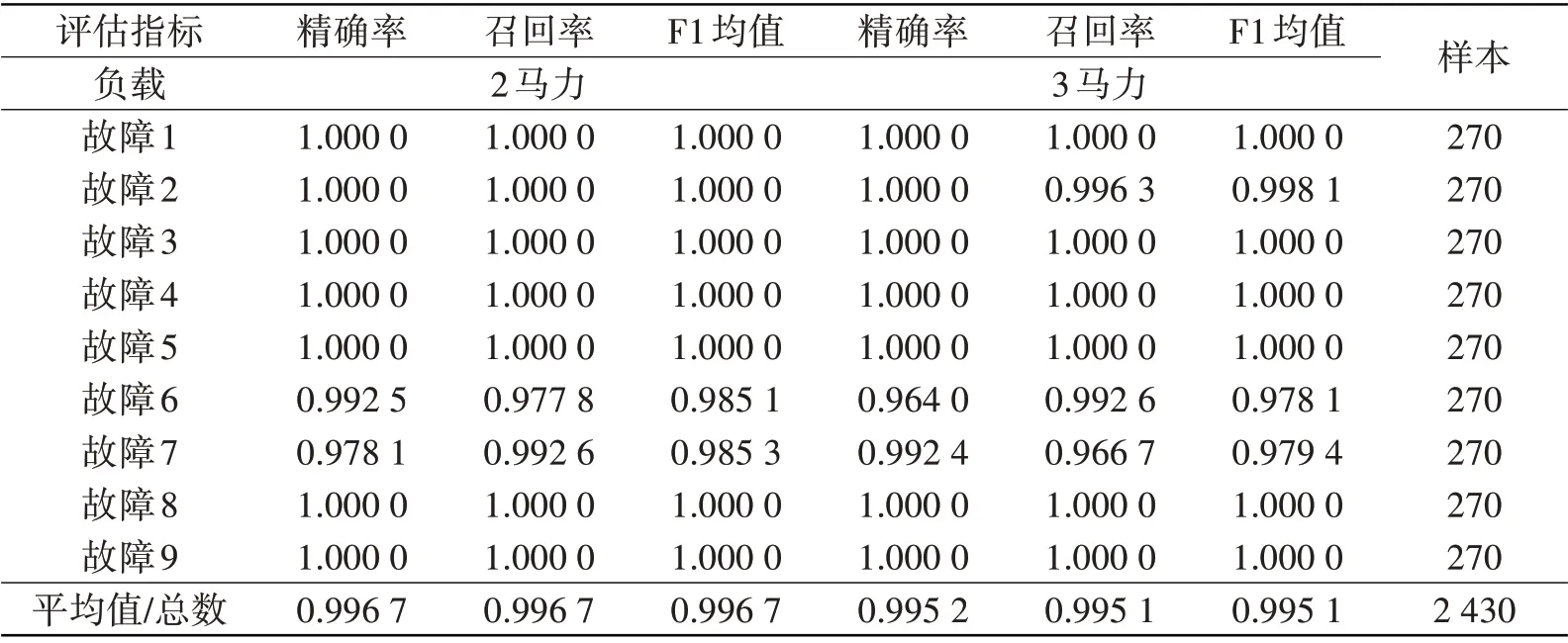
表5 迁移实验的故障诊断结果Tab.5 Fault diagnosis results of the migration experiment
4 结 论
本文提出了一种基于改进的LSTM-SVM的深度学习新方法用于解决船舶旋转机械在多传感器监测环境下的快速故障诊断问题。提出的方法改进了传统LSTM的算法结构,采用多层堆叠的LSTM网络作为特征提取器,在算法的末端引入SVM代替Softmax函数作为分类判别器,进一步提升诊断准确率。通过使用滚动轴承在不同负载工况下采集的3通道加速度传感器故障数据进行实验验证,并将诊断结果与SVM、KNN、DNN、CNN和标准LSTM五种方法进行了比较,得出了以下结论:
(1)提出的LSTM-SVM算法具有更高的诊断准确率,用于对比的五种算法诊断准确率分别为94.75%、91.85%、96.03%、99.10%和98.77%,而提出的方法准确率高达99.92%。
(2)提出的LSTM-SVM算法在保障诊断精度的前提下具有更快的诊断速度,相比CNN,提出的方法具有更高效的诊断实时性,其训练时间减少了近80%的耗时,测试时间相比CNN缩短近70%。
(3)提出的LSTM-SVM算法在用于诊断滚动轴承的2马力和3马力两种负载工况下的故障问题上,分别获得高达99.67%和99.51%的诊断准确率,验证了该算法具有良好的迁移通用性能。整个诊断过程无需任何手工特征提取干预,“端到端”的算法结构具有良好的通用性和可操作性。
综上所述,本文提出的LSTM-SVM方法取得了较理想的诊断效果,尤其是在诊断时间方面明显优于CNN算法,说明LSTM更适合于处理多传感器时间序列数据诊断问题,研究结果可为后续船舶旋转机械的实际在线诊断应用提供新思路,具有重要的参考意义和借鉴价值。
