基于Huber指数平方损失函数的二维人体姿态估计网络
2021-10-01马金伯
马金伯
摘 要:人体姿态估计是计算机视觉领域的一个研究热点,已經应用于教育、体育等方面,在视频监控、人机交互、智能校园等领域有着广阔的应用前景。简单的姿态估计基线方法在沙漏残差模块中加入几层反卷积层,使用均方误差(MSE)损失函数,结构和算法复杂度较低且能够较为精确地预测出关节点热图。首先,采用分段函数H-ESL(huber-exponential squared loss)损失函数,克服了MSE损失函数对于异常值较为敏感的缺点。其次,提出的网络在基线方法的网络上加入了注意力机制,并将大的卷积核转换成小的卷积核,使得网络精度提升的同时减少参数量及计算量,从而提高网络的预测效率。拟建网络利用COCO2017数据集的地面真实值分别进行训练和验证,均实现了高精度,mAP提高了2.6%,证明该方法适用于各种人类关键热图的输入,并能取得良好的效果。
关键词:深度学习;人体姿态估计;损失函数;热图;COCO数据集
Abstract:As a hot topic in computer vision,human pose estimation has gradually penetrated into all aspects of education, sports and so on. It has a wide application prospect in the fields of video surveillance, human-computer interaction and intelligent campus.In the simple baseline method, several layers of deconvolution were added into the hourglass residual module, and the mean square error loss function is used.First, piecewise function H-ESL (Huber-Exponential Squared Loss) loss function is adopted to overcome the shortcoming that MSE loss function is sensitive to outliers.Secondly, the proposed network adds an attention mechanism to the network of the baseline method, and converts large convolution kernels into small convolution kernels, which improves the accuracy of the network and reduces the number of parameters and the amount of computation, thus improving the prediction efficiency of the network.The proposed network is trained and verified by ground truth value of COCO2017 dataset, and both of them achieve high precision. Map is increased by 2.6%, which proves that this method is suitable for heat mAP input of multiple human body key points and can achieve good results.
Key words:deep learning; human pose estimation; loss function;heat map; COCO datasets
人体姿态估计包括单人姿态估计和多人姿态估计两种估计模式,姿态估计的过程包括标注图片或者视频中人体关节点的位置后对关节点进行最优连接。由于通过深度学习进行二维人体姿态估计的方法与传统需要人工设定特征的方法相比较,更能充分地提取图像信息且获取更具有鲁棒性的特征,因此基于深度学习的姿态估计方法是目前二维人体姿态估计算法研究的主流方向。相对而言,多人姿态估计应用领域更加广泛,例如在自动驾驶时对路人的行为做出判断以提前避免车祸的发生、使用人体关键点定位识别出病人的肢体行为以对病人的病情进一步了解、根据姿态估计判别运动员的形体动作是否规范等等。
给定人数,通过对图像中给定的单人进行关节点的定位,从而确定人物位置的关节点定位的姿态估计过程就是单人姿态估计。单人姿态估计的算法模型在训练时通常采用有监督方法,由于地面真值(Ground Truth)有不同的类型,单人姿态估计方法也不相同,分为基于坐标回归和基于热图检测两种。多人姿态估计的难度比单人姿态估计更大,根据算法步骤的不同,多人姿态估计中使用的方法也不同,包括一步法(single-stage)和二步法(two-stage)两种。其中,一步法是一种较为新颖的方法,顾名思义一步法可以一步获取多人的姿态估计信息;而二步法的算法流程则较为复杂,首先需先进行人体框、关节点的检测,其次再进行关节点分组。
与此同时,姿态估计的网络结构也越来越复杂,这使得算法的比较与分析也比较困难。在MPII上较为显著的网络模型如文献[1]中的堆积沙漏网络、文献[2]中整合多内容信息注意力机制到CNN网络、文献[3]中结构感知卷积以及文献[4]中金字塔残差模块在许多细节上都有很大的差异,但在精度上差异不大,很难比较哪些细节起到了决定性作用。同样,在COCO数据集上效果较为显著的方法如文献[5]中single-stage结合end-to-end的关节点检测的方法,文献[6]中Faster r-cnn与Fully Convolutional Resnet相结合的方法,文献[7]中在Faster r-cnn的基础上增加了一个mask预测分支(Mask r-cnn)的方法,文献[8]中Cascaded Pyramid Network (CPN)网络模型,以及文献[9]中的PAF网络结构,这些方法、网络较为复杂,网络结构的差异也比较大。
热图(Heatmap)通过把变量放置于行和列中,再将表格内的不同单元格进行分析着色来产生一个色彩发展变化情况从而能够达到研究显示信息数据、交叉检查多变量的数据的目的。热图适用于很多场景,比如显示多个变量之间的差异,显示其中任意一个模块,显示是否有相似的变量,检测数据之间是否有相关性。热图网络(Heatmap Net)与基于二维坐标地面真实值(Ground Truth)回归的算法相比较来说,能够同时进行构建基于概率分布的地面真实值和添加一些人体部件之间的结构信息。热图网络按结构进行分类可以分为显式添加结构先验和隐式学习结构信息。显式添加结构在训练之前就掌握了人体结构的先验信息,在为各关节生成热图后,通过参照概率图模型和人体各关节点连通性,显式地搭建先验网络连接关系,因此,在训练过程中,该网络能够控制各个关节点信息在网络中的流向同时能够提升网络对这些特征信息流的敏感度。显式添加结构表达了各个部件检测器之间的依赖关系,因此虽然显示网络可以通过概率图模型学习到人体各关节的结构信息,但网络连接导致了网络结构过于复杂。目前,大多数姿态估计方法主要是基于大感受野(Receptive Field)机制来隐式地学习人体结构信息。感受野是由CNN网络的每一层输出特征图上的每个像素点在其原始图像上映射区域的大小,值越大则表示该网络模型能够通过学习到的原始数据图像进行特征研究范围越广,蕴含的信息管理更为全局化,语义层次也就越高,而值越小则该网络所包含的特征越局部和细节。因此,若想学习到远距离的关节点连接特征并且获得语义层次更高的关节点结构信息,则可以通过扩大热图的感受野的方法来完成。这种基于大感受野隐式学习结构信息的方法具有较高的泛化性和鲁棒性较高,许多方法也根据此方法进行了改进。热图的像素值表示该关节点在此位置的概率,而基于热图检测的方法是指先获取人体关节点热图,再获取关节点定位信息。Xiao等人在文献[10]中提出了简单的姿态估计基线方法(Simple Baselines),该方法是基于热图进行预测的,将低分辨率的特征图扩张为原图大小来预测关键点热图。基线方法所使用的网络结构是在沙漏残差模块中加入几层反卷积,从而大大降低了算法的复杂度且得到了较高的预测精度。改进后的姿态估计网络的主要贡献包括:
1)该网络是一个简单高效的姿态估计网络模型。在基线方法所使用的网络模型基础上加入了通道注意力机制并利用小卷积核代替了大卷积核,该网络模型能够在提高精度的同时减少参数,是一个简单、高效且精度较高的姿态估计网络模型。
2)使用H-ESL损失函数。该损失函数克服了MSE损失函数对异常值较为敏感的缺点。
1 姿态估计基线方法
1.1 网络结构
He等人[11]提出的Resnet网络是最常用的特征提取网络,文献[6]中的Faster r-cnn与Fully Convolutional Resnet相结合的方法和文献[8]中的CPN网络也使用了该网络模型进行野外人体姿态估计。基线方法的网络结构示意图如图1所示。
可以看出基线方法的网络结构就是在Resnet的基础上,取最后残差模块输出特征层,在Resnet最后一个卷积上添加了三个反卷积模块,每个模块为Deconv、Batchnorm和Relu,使用了He等人[7]提出的R-cnn模块、Ioe等人[12]提出的Batch归一化以及Krizhevsky等人[13]提出的Relu激活函数,每一层采用256个4×4的滤波器,步长为2,最后添加三层1×1的卷积层,从而最终生成预测的热图,可以说是最简单的根据深度低分辨率特征图生成热图的网络。
1.2 均值平方差损失函数
Tompson等人提出的MSE[14]是预测值与目标值之间的差值平方之和,它得出的结果越小,越能表明预测模型所描述的样本数据具有较好的准确性。在回归问题中,由于MSE具有无参数、计算成本低和物理意义明确等优点,该函数常被用作回归问题中,以评估模型的损失或算法的性能高低。在姿态估计的基线方法中也使用该函数作为损失函数,它的公式可表示为
1.3 算法评价指标
1)平均精度(AP):平均精度AP指检测出来的关键点个数占总个数的百分比,而APL和APM分别表示最大、最小的AP值。Object Keypoint Similarity(OKS)代表对模型的关节点进行相似度计算,计算方法是假设一张多人的2D图片上一共有M个人,通过算法预测出N个人,将预测出来的人数和图片原有人数相互对应计算OKS,便可得出一个M×N矩阵。给定一个阈值,如果OKS大于阈值则定义该关键点被检测出来。AP的计算公式是
2 改进的姿态估计基线方法
2.1 Huber指数平方损失函数
误差梯度用于在正确的方向和量上更新网络权重,神经网络训练过程中计算的误差梯度包括方向和数量。然而,在深度网络或循环神经网络的学习过程中,误差梯度在更新过程中逐渐积累,从而值变大,导致网络在训练过程中的权重大大增加,更导致了网络变得非常不稳定甚至溢出,比如进行训练时网络层之间值大于1的梯度重复相乘就会直接导致梯度的指数级增长,从而发展产生不同梯度信息爆炸。梯度爆炸带来很多坏结果,比如网络不稳定,网络无法从训练数据中学习,最坏的结果就是网络的权值无法更新,从而导致训练失败。二维的姿态估计网络模型大多使用的损失函数为MSE损失函数,该损失函数虽然是回归损失函数中较为常用的误差函数且各点都连续光滑,便于求导,得到的解也较为稳定,但是,由于当函数的输入值远离中心值时,使用梯度下降法解决时梯度非常大,可能导致梯度爆炸,因此损失的稳健性难以保证。
2.2 通道域注意力的使用
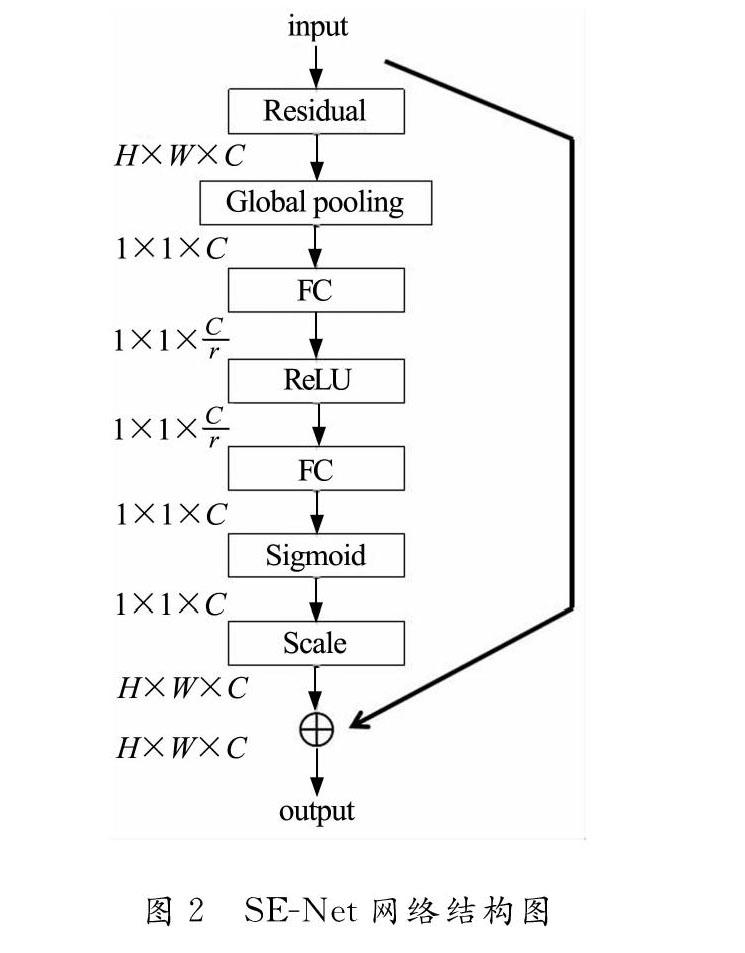
通道域注意力对不同的通道赋予不同的注意力权重值以对通道间的重要性进行筛选,从而对输入特征图的不同通道进行注意力权重赋值。采用的SENet结构示意图如图2所示,SENet网络能够通过在残差模块加入注意力机制来提高网络的分类精度,方法是通过损失函数来学习特征权重,赋予更高效用的特征图更高的注意力权重的同时降低低效用的特征图的权重,从而实现通道的注意力权重分配。SENet主要由两部分组成:Squeeze部分和Excitation部分。原始特征图(feature map)的尺寸为H×W×C,H和W分別代表了特征图的高度(Height)、宽度(width),而C则代表通道数(channel)。Squeeze部分的作用是把H×W压缩成一维,即把H×W×C压缩为1×1×C,在实验中通常使用global average pooling来实现压缩步骤。H把H×W×C压缩为1×1×C后,一维的参数获得了之前H×W全局的视野,这说明压缩后的感受区域更广。Excitation部分得到Squeeze的1×1×C的表示后,加入一个FC(Fully Connected)全连接层,这个层能够对每个通道的重要性进行预测,在得到不同通道数的权重值大小后再激励到之前的特征图的对应通道数上,再进行后续操作。
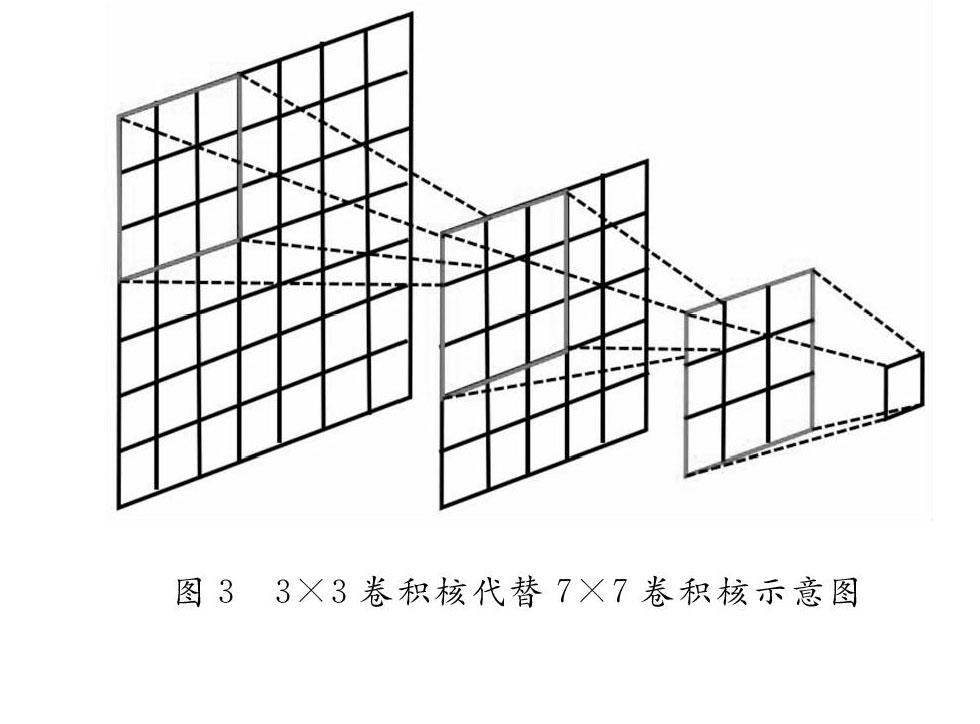
2.3 小卷积核的使用
卷积核通过对输入的某个局部块进行加权求和,从而能够实现对该输入的局部进行感知,其尺寸定义为W×D×C,其中,W表示单个感受野的长度,D表示单个感受野的宽度,C表示卷积核的深度,深度代表着卷积核在三维深度上的连接需要,也就是输入深度即输入矩阵的通道数。每一个卷积核均输出一个一维的特征图,多个卷积核就会输出对应个数的特征图,这些特征图堆叠在一起输出的就是一个有深度的特征图矩阵。一个大的卷积核可以带来更大的接受场,但也意味着会产生更多的参数,获得相同感受野的条件下,设置的卷积核尺寸越小,所需要的参数量就越小,同时计算量也就越小,例如5×5卷积核的参数有25个,3×3卷积核的参数有9个,可以看出前者的参数量是后者参数量的2.78倍。使用小卷积代替大卷积的具有很多优点,例如,集成了多个非线性激活层,集成的非线性激活层可以代替单个非线性激活层,从而提高了网络的非线性拟合能力,再例如改进后的网络减少了网络参数的同时减少了计算量、多个小卷积核的串联在网络结构搜索中能够给通道数设置增加更多的灵活性等等。改进后的网络以3个3×3的级联卷积代替1个7×7的卷积,原理示意图如图3所示。从图3中可以看出该方法减少22个、45%的参数,且原本需计算7×7×L次,使用小卷积核后只需计算3×3×3×L次,减少了22×L次计算即45%的计算量,因此,提出的网络模型是较轻量级,高效率的网络模型。
3 实验结果及分析
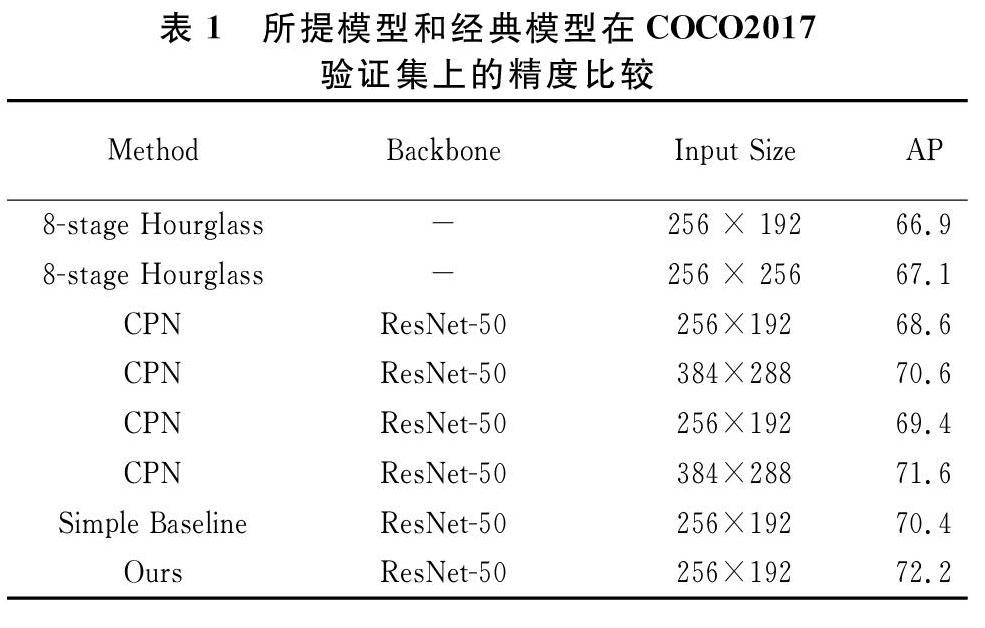
使用PyTorch[16]框架来搭建模型,以ResNet-50[17]网络为基础,加入了注意力机制、使用小卷积核代替大卷积核并使用H-ESL损失函数,将提出的模型与Hourglass、CPN和简单基线网络模型精度进行对比,结果如表1所列。
基线网络给出的PyTorch开源源代码mAP值为70.4,在我们的设备上得以复现。改进的网络在降低参数量的同时mAP值达到了72.2,相对精度提高2.6%,这说明提出的模型是一个高效且高精度模型。
4 结 论
针对2D图片多人姿态估计问题分别在网络与算法上提出了改进,设计了一个高效率、高精度的网络。该网络加入了通道注意力机制SE结构、使用小卷积核代替大卷积核并使用H-ESL损失函数。通过注意力机制合理分配特征权重使结构能够提取特征同时通过小卷积核代替大卷积核减少网络参数,在算法上使用H-ESL损失函数克服了MSE对异常值敏感结果不稳定额缺点,结果是精度有所提升。该模型在COCO2017数据集上进行验证,mAP达到了72.2。由于該模型精度高、参数量少,因此在一些实时人体定位场景中将有很好的应用价值。
参考文献
[1] NEWELL A, YANG K, JIA D. Stacked hourglass networks for human pose estimation[C]// European Conference on Computer Vision, 2016: 483-499.
[2] CHU X, YANG W, OUYANG W, et al.Multi-context attention for human pose estimation[C]// IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1831-1840.
[3] CHEN Y, SHEN C, WEI X, et al.Aware convolutional network for human pose estimation[C]// IEEE International Conference on Computer Vision, 2017: 1212-1221.
[4] YANG W, LI S, OUYANG W, et al. Learning feature pyramids for human pose estimation[C/OL]// IEEE International Conference on Computer Vision, 2017.
[5] NEWELL A, HUANG Z, DENG J. Associative embedding:End-to-end learning for joint detection and grouping[C]// Advances in Neural Information Processing Systems, 2017: 2274-2284.
[6] PAPANDREOU G, ZHU T, KANAZAWA N, et al.Towards accurate multi-person pose estimation in the wild[C]// Computer Vision and Pattern Recognition, 2017: 3711-3819.
[7] HE K, GKIOXARI G, DOLLAR P, et al.Mask R-CNN[C]// IEEE International Conference on R-Computer Vision, 2017: 2980-2988.
[8] CHEN Y, WANG Z,PENG Y, et al.Cascaded pyramid network for multi-person pose estimation[C/OL]//Computer Vision and Pattern Recognition, 2018.
[9] CAO Z, SIMON T, WEI S E, et al.Realtime multi-person 2D pose estimation using part affinity fields[C/OL]// Computer Vision and Pattern Recognition, 2017.
[10]XIAO Bin, WU Hai-ping, WEI Yi-chen. Simple baselines for human pose estimation and tracking[C]// European Conference on Computer Vision, 2018: 472-487.
[11]HE K, ZHANG X, REN S, et al.Deep residual learning for image recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
[12]IOE S, SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. International Conference on Machine Learning, 2015: 448-456.
[13]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]// Advances in Neural Information Processing Systems, 2012: 1097-1105.
[14]TOMPSION J, JAIN A, LECUN Y, et al.Joint training of a convolutional network and a graphical model for human pose estimation[J]. Advances in Neural Information Processing Systems, 2014:179-1807.
[15]MARONNA R A, MARTIN R D, YOHAI V J, et al.Robust statistics: Theory and methods (with R)[M].New York:Wiley,2006.
[16]PASZKE A, GROSS S, CHINTALA S, et al. Automatic differentiation in PyTorch[C/OL]// NIPS 2017 Workshop Autodiff Submission, 2017.
[17]HE K, ZHANG X, REN S, et al.Deep residual learning for image recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
