空间自回归模型中系数变量及误差项的贝叶斯估计
2021-09-30吴茜茜
王 慧, 吴茜茜
(合肥工业大学 数学学院,安徽 合肥 230601)
0 引 言
空间自回归(spatial autoregression,SAR)模型是空间计量模型的一个特例,常被用于分析具有空间相关性的数据。由于其独特的博弈结构并且可以被解释为反应函数,被广泛地应用于空间计量经济学和社交网络建模中[1]。建立模型的过程离不开对模型中未知参数的估计,而针对SAR模型中参数的估计,文献[2]提出编码法;文献[3]利用最小二乘估计方法研究SAR模型;文献[4]概括了SAR模型的似然函数,并给出相应的极大似然估计,但SAR模型的极大似然估计量的收敛速度取决于空间权重矩阵的特征[5];文献[6]提出SAR模型的有限信息的极大似然估计量,但由于空间相关性,得到的是非一致估计。随着广义矩估计方法的提出,很多学者将其应用到空间计量模型中[7-8],但在异方差存在的情况下,该估计是非一致的[9]。
随着贝叶斯理论的发展,越来越多的学者开始重视贝叶斯统计推断这一有力工具。文献[10-12]研究了SAR模型和受限因变量SAR模型的贝叶斯方法,突破了SAR模型经典方法的限制;文献[13]的研究结果表明,当SAR模型中存在负的空间相关性时,通过马尔科夫链蒙特卡洛(Markov Chain Monte Carlo,MCMC)方法取得的贝叶斯估计量比稳健的广义矩估计量更有效。实际上,贝叶斯统计推断主要依靠后验分布,为此需要计算似然函数并给出合理的先验[14]。当模型参数空间维数增加或先验结构复杂时,似然函数越来越复杂而无法获取其解析表达式,无法计算后验密度,此时不能直接运用贝叶斯方法。近似贝叶斯计算(approximate Bayesian computation,ABC)最早由文献[15]提出并应用于种群基因的研究。与经典贝叶斯方法相比,ABC方法可以更合理地利用先验,作为一种“似然自由”的方法解决实际问题。目前ABC方法在生物及其他领域应用广泛,但在经济领域的应用偏少,本文将ABC方法引入SAR模型的推断分析。文献[16]将ABC方法应用于量子核磁共振模型推断;文献[17]将ABC方法应用于含噪声数据的随机伽马过程;文献[18]通过ABC方法和稳态信号模拟,从转录组和蛋白质组数据中的逆向工程指导基因调控网络。
本文首先介绍贝叶斯推断的思想、常见的马尔科夫链蒙特卡洛、近似贝叶斯计算方法、空间自回归模型;其次提出适应估计该模型参数的2种算法;最后基于长三角地区26个城市2007-2016年间的空间面板数据,建立相应的SAR模型,根据相应算法对该模型进行估计,并给出结果和讨论。
1 贝叶斯推断
1.1 贝叶斯定理
贝叶斯定理是贝叶斯推断的核心,最早由英国数学家Thomas Bayes提出[14]。模型分析中,通常利用已知数据(记为Y)与模型形式估计未知参数(记为θ)。
根据贝叶斯公式,有
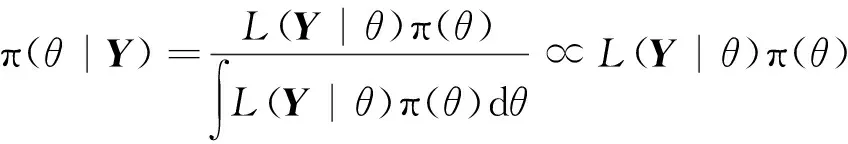
(1)
其中:π(θ)为参数θ的先验信息;L(Y|θ)为似然函数;π(θ|Y)为参数θ的后验分布。
1.2 马尔可夫链蒙特卡洛(MCMC)方法
MCMC方法是贝叶斯统计推断中一种重要的抽样方法。它通过构建一条马尔可夫链使其平稳分布为后验分布,由此产生的该链上的样本点{θ(1),θ(2),…,θ(n)}可以看作近似服从后验分布π(θ|Y)。该方法的关键是如何构造“合适”的马尔科夫链,常见的算法有M-H(Metropolis-Hastings)抽样和Gibbs抽样。
1.2.1M-H抽样
选取建议分布q(·),通常可以采用对称式(q(x|y)=q(y|x),q(x|y)=q(|x-y|)),独立式(q(x|y)=q(x))或随机游走的形式(y=x+η)。具体步骤如下:
(1) 令t=0,由π(θ)抽样θ(0)。
(2) 由q(·)抽样θ*。
(3) 计算接受概率α。计算公式为:
(4) 由U(0,1)抽样u,若u≤α,则θ(t+1)=θ*,否则θ(t+1)=θ(t)。
(5) 令t=t+1,重复上述步骤直到t=N。
1.2.2Gibbs抽样
上述M-H抽样针对低维问题较为有效。如果待估参数为向量θ=[θ1θ2…θn]T,其中T表示向量的转置,并且可以计算参数θi的后验条件密度π(θi|θ-i),其中θ-i=[θ1…θi-1θi+1…θn]T是由参数向量θ剔除了参数θi所构成的,那么可以采用Gibbs抽样,具体步骤如下:

(3) 令t=t+1,重复上述步骤直到t=N。特别地,当其中某个后验条件分布难以直接采样时,可以利用M-H抽样针对该分布进行抽样,由此构成Metropolis within Gibbs算法。
1.3 近似贝叶斯计算(ABC方法)
ABC方法避免了(1)式中似然函数L(Y|θ)的计算,其核心思想是从先验分布中直接抽样,通过距离函数等条件,筛选参数集来近似估计参数后验分布[15]。首先需要定义距离函数S(·)和容差阈值d0,ABC方法(通常又称为拒绝算法)的算法步骤如下:
(1) 由π(θ)抽样θ*。
(2) 基于模型和参数θ*计算模拟值Y′。
(3) 通过S(·)计算Y与Y′之间的距离d。
(4) 若d≤d0,则接受θ*;反之,则拒绝θ*。
对于比较小的d0,最终获得的模拟样本分布π(θ|S(Y,Y′)≤d0)可用于近似后验分布π(θ|Y)[15]。
1.4 SAR模型
SAR模型的一般形式为:
Y=ρWY+Xβ+ε,ε~MVN(0,σ2In)
(2)
其中:Y为(n×1)观测值;X为(n×k)解释变量矩阵;W为空间权重矩阵;β为(k×1)系数;ρ为空间自回归系数;In为n阶单位矩阵;ε=[ε1ε2…εn]T表示随机误差项,服从MVN(0,σ2In)。模型(2)的待估参数向量为θ=(β,σ2,ρ)T,且假设独立性存在,似然函数为:
(3)
其中:f(·)=exp(-(2σ2)-1(A(·)Y-Xβ)T·(A(·)Y-Xβ));A(ρ)=In-ρW。
2 算 法
2.1 Metropolis within Gibbs算法
假设参数β、σ2、ρ相互独立,先验分别为π(β)~N(μ、Σ)、π(σ2)~IG(α,γ)、π(ρ)~U(a,b)[12]。
由独立性及似然的表达可以得出后验的表达式,可利用M-H抽样进行采样,但由于待估参数维度高且参数类型不同,采用Gibbs抽样更加合适。根据Gibbs抽样,在后验条件分布抽样过程中,第t+1步迭代为:
β(t+1)~π(β|ρ(t),(σ2)(t),Y,W)
(4)
(σ2)(t+1)~π(σ2|ρ(t),β(t+1),Y,W)
(5)
ρ(t+1)~π(ρ|ρ(t),β(t+1),(σ2)(t+1),Y,W)
(6)
其中:β、σ2的条件后验分别为正态分布、逆伽玛分布,可以直接抽样。但是ρ的条件后验形式比较复杂,这里选择应用独立的M-H抽样对ρ的条件后验抽样,由此得到的Metropolis within Gibbs算法的步骤如下:
(1) 令t=0,由先验分布π(β)、π(σ2)、π(ρ)分别抽样θ(0)=[β(0)(σ2)(0)ρ(0)]T。
(2) 由(4)式、(5)式分别抽样β(t+1)、(σ2)(t+1)。
(3) 由建议分布ρ*=c·η(η~N(0,1))抽样ρ*。
(4) 计算接受概率。计算公式为:
由U(0,1)抽样u,若u≤α,则ρ(t+1)=ρ*;否则ρ(t+1)=ρ(t)。
(5) 令t=t+1,重复上述步骤直到t=N。
2.2 ABC方法
根据ABC方法,需要通过模型计算距离函数S(Y,Y′)。
模型(2)中存在误差项ε,且ε~MVN(0,σ2In),只要控制住了误差项ε(即εi,i=1,2,…,n),就可以近似计算出模拟数值Y′。
因为εi在(±3σ)中的概率为99.74%,所以有99.74%的把握将εi控制在一个区间内,只要计算出εi的区间端点处的值,然后代入计算即可。
在SAR模型中抽取参数θ*,模拟数值Y′计算公式为:
Y′=(In-ρ*W)-1(Xβ*+ε*)
(8)
其中:ε*=max(-3σ*In, 3σ*In)。具体的算法步骤如下:
(1) 令t=0,由先验分布π(β)、π(σ2)和π(ρ)分别抽样β*、(σ2)*和ρ*,记为θ*。
(2) 根据(8)式计算模拟数据Y′。
(3) 计算距离d(采用切比雪夫距离)。计算公式为:
若d≤d0,则θ(t+1)=θ*;否则返回步骤1。
(4) 令t=t+1,重复上述步骤,直到t=N。
3 模型建立及数值模拟
3.1 模型假设
本文使用长三角26个城市2006-2017年的面板数据进行实际论证。数据分别来自《中国城市统计年鉴》及江苏、浙江、安徽省统计年鉴,对于缺失1年的样本采用均值法补充,对于缺失2年及以上的数据采用线性插值法补充。假定社会投入和产出符合Cobb-Douglas生产函数,通过计算这26个城市的地区生产总值(per capita regional gross domestic product, PGDP)的Moran’s I指数及其统计量,结果表明,利用该数据建立SAR模型是可行的[18]。通过Pearson相关性检验研究变量之间的相关性,对于存在多重共线性的变量保留其中一个,保证估计值的唯一性。本文选择解释变量为服务业集聚度(agglomeration, AGG)、固定资本投入(fixed asset input, FI)、外商直接投资(foreign direct investment, FDI)以及劳动力资本投入(Human)。
为便于研究各要素投入对生产地区增长的贡献率,消除异方差和数据的剧烈波动,建立对数化SAR模型如下:
(9)
其中:i=1,2,3,4;j=1,2,…,26;Yjt为城市j在第t年的地区生产总值(PGDP);X1jt、X2jt、X3jt、X4jt分别为城市j在第t年的服务业集聚度(AGG)、固定资本投入(FI)、外商直接投资(FDI)、劳动力资本投入(Human);ρ为空间自回归系数;εjt~N(0,σ2In)为随机误差项向量;wjk为空间权重矩阵W中的元素,即

其中:sjk为城市j与城市k之间的距离;L为所选城市的数量。
该模型中未知参数向量为θ=[β1β2β3β4ρσ2]T。
3.2 参数估计结果
利用26个城市9年的数据,分别应用Metropolis within Gibbs算法和ABC算法对模型(9)进行参数估计,并利用估计结果对第10年的数据进行拟合分析。假设π(β)~N(μ,Σ),π(σ2)~IG(α,γ),π(ρ)~U(a,b),其中超参数的值分别取为:μ=(0.5,0.5,0,0)T,Σ=diag(0.05,0.05,0.1,0.1),α=100,γ=10,a=-1,b=1。在应用Metropolis within Gibbs算法的估计过程中,需要通过调整建议分布的方差(c-2)控制接受概率(确保接受概率在20%~30%)。通过对每M个样本取平均值降低抽样样本的自相关性,从而使每批次的均值近似独立,获得更有效的估计参数,最终需要的样本容量设定为N=600(其中前100个样本作为预烧期),M=50,c=0.1。
为方便对比,在ABC算法的计算中,样本容量设定为N=500;另外,需要通过降低d0来获得更为精确的估计,同时需要保证计算效率,因此取d0=1.7。
首先选取采用Metropolis within Gibbs算法估计的参数β1的结果作为展示,如图1所示。从图1a可以看出,截取前N=100个样本作为预烧期,剩余样本构成的马氏链已经收敛。根据图1b,随着阶数(Lag)值的增大,自相关函数(autocorrelation function,ACF)递减,这说明抽样容量是合理的,并且该ACF在2倍标准差范围内波动,说明其自相关系数截尾,该序列具有平稳性特征。其他5个参数的抽样序列图也都能快速达到收敛趋势,且相应的ACF也随Lag值增大而减小,由于篇幅有限,在此就不一一阐述。
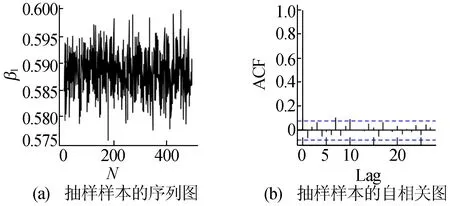
图1 参数β1的MCMC抽样结果
通过汇总2类算法的结果,各参数的后验均值、标准误差、拟合结果见表1所列。由表1可以看出,根据Metropolis within Gibbs算法和ABC算法估计参数得出的估计结果接近。其中β1和β2后验均值分别近似为0.6和0.5,这说明服务业集聚度和固定资产投资对长三角区域经济增长效果最显著。β3和β4均在0附近,说明外商直接投资和劳动力资本投入并不是影响区域经济的主要因素。空间自回归系数ρ的估计值约为0.15,说明该长三角地区存在空间自相关性,地区经济增长的强弱会受到相邻地区增长的影响。2类算法估计参数的后验标准误差均小于0.005,表明2种算法抽取的样本对总体来说具有代表性,具有较高的可靠度。在样本容量相同的情况下,Metropolis within Gibbs算法的四分位距(inter-quartile range,IQR)与标准误差均小于ABC算法,即利用前者估计参数比后者具有更高的精度,并且耗时更短。此外,通过这2种算法获得的估计拟合第10年数据的平均误差约为0.2。

表1 SAR模型估计结果
综合来看,Metropolis within Gibbs算法与ABC算法相比,可以提供更为有效和较高精度的估计,这是因为后者依赖于容差阈值和先验分布的选择,这两者对求解精度和效率起到关键作用;与此同时,Metropolis within Gibbs算法对于建议分布的选取、马氏链的收敛以及样本序列的自相关性都有较高的要求,一旦要求满足,后验概率的估计会相对高效。但Metropolis within Gibbs算法的实现需要似然函数的表达式,因此在实际应用中,当似然表达式未知时,是难以实现的。此时,在保证符合条件的样本量足够多的情况下,ABC算法能够避开似然的求解,提供另一种有效的方法。
4 结 论
本文基于长三角26个城市2006-2017年的面板数据建立SAR模型,并提出适应估计该模型参数的Metropolis within Gibbs算法和ABC算法进行贝叶斯推断和分析。结果表明:服务业集聚度及固定资产投资的参数估计对长三角地区生产总值具有显著的影响;外商直接投资和劳动力资本投入并不是影响区域经济的重要因素,说明这两者并不具备该地区生产总值的代表性,以上结论对地区发展经济具有参考价值。估计结果显示,Metropolis within Gibbs算法虽然能够有效估计参数,但是依赖于具体的似然函数的解析式,而ABC算法避免了求解似然函数,能够有效估计后验概率分布,2种算法在求解模型中各有优势。本文提出的SAR模型下参数估计的近似贝叶斯计算方法为空间计量模型的建立提供了一种新思路,可以将它运用于其他带有随机误差项的模型中。
