基于MD-CGAN的情感语音去噪算法
2021-09-29李怡菲
李怡菲,应 娜,杨 鹏
(杭州电子科技大学通信工程学院,浙江 杭州 310018)
0 引 言
语音情感识别系统是一种有效、准确的人类情感鉴别系统。语音采集过程中,除了目标人物的音频信息,还会采集到干扰作用的冗余音频信息,此类信息定义为噪声[1]。在特殊应用场景下,采集过程中的环境因素(马路上车辆行驶带来的噪声、餐厅中餐具碰撞的噪声等)、系统因素(音频传输时的高斯噪声、泊松噪声等),均会使采集到的音频信息携带噪声,降低了包含情感信息的音频质量,影响了情感特征的提取,最终导致识别性能下降[2]。所以,语音情感去噪研究具有重要的研究意义。
传统的语音去噪算法有谱减法、自适应噪声抵消法、小波变换法等。张亚峰等[3]运用自适应滤波器经典算法之一的最小均方算法实现了语音信号的去噪处理。靳立燕等[4]提出一种基于奇异谱分析和维纳滤波的语音去噪算法,解决了去噪处理后出现信号失真、信噪比不高的问题,更有效地去除了背景噪声。针对传统方法去除噪声时情感特征恢复不明显的问题,本文提出一种基于矩阵条件生成对抗网络(Matrix Distance-Conditional Generative Adversarial Networks,MD-CGAN)的情感语音去噪算法,有效提升了语音情感识别率。
1 基于MD-CGAN的情感语音去噪算法
基于MD-CGAN的情感语音去噪算法在去除噪声的同时还能有效保护情感特征。模型为了避免反卷积带来的棋盘化效应和情感信息损失,生成器网络采用维度保持结构;为了减少异常语音数据的影响,在生成器网络中加入残差结构;在损失函数中加入矩阵距离损失,并针对矩阵距离损失的权重设定进行探究,设定适用于情感特征恢复的最佳权重。
1.1 条件生成对抗网络
原始生成对抗网络(Generative Adversarial Nets,GAN)是由生成器(Generator, G)和判决器(Discriminator, D)组成的训练生成式模型,将随机噪声和真实图像输入到GAN中,通过生成器和判决器之间不断对抗学习,生成近似真实数据的图像[5]。在对抗训练中,生成器通过不断迭代学习生成图像,企图“欺骗”判决器;判决器通过不断学习,尽可能“不受欺骗”,判决器和生成器通过不断的对抗训练,寻求最优解。
由于GAN过于自由,较大的图片出现超高维,影响生成器的训练结果。为了解决这个问题,Mirza等[6]提出了条件生成对抗网络(Conditional Generative Adversarial Networks,CGAN),在生成器和判决器的模型中都引入了约束条件Iy,通过约束条件指导生成器生成正确的数据。因此,CGAN将无监督的模型转换为有监督的模型。
基于CGAN的语音去噪模型如图1所示,Iz表示有噪声的语谱图,Ix表示干净语谱图,Ig表示去噪后的语谱图,Iy表示语音情感类别标签。生成器网络G的输入是Iz和标签Iy,输出是Ig,判决器网络D的输入是Ix和Ig,输出为1或0。D需要将Ix判定为真,将Ig判定为假,从而使得G为了通过D的判定,将改变它的参数让Ig更加接近Ix,而D通过反向传播,在判定Ig和Ix方面变得更加优秀。Iy作为整个网络的约束来指导语谱图去噪过程。最后,训练出适合去除语谱图噪声的生成器模型。
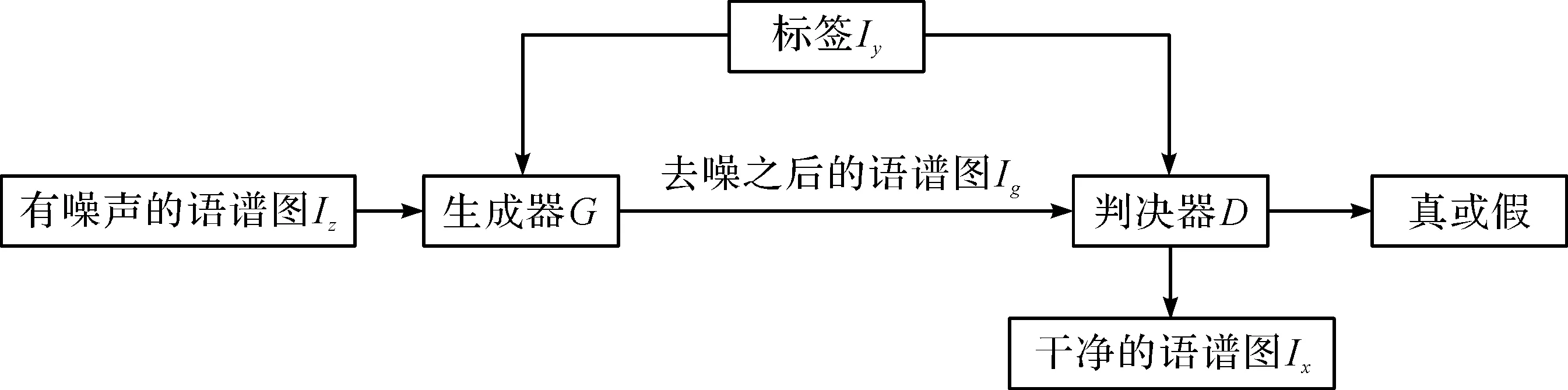
图1 基于CGAN的语音去噪模型
1.2 生成器网络结构
携带噪声情感谱图去噪的目的是将含噪图像投影到干净的图像空间中,尽可能保留情感表征。本文的生成器网络结构采用特征维度保持的结构,保证了情感表征的成功恢复。同时,加入残差结构,将输入Iz添加到最后1个卷积层的输出,并连接到反卷积层[7]。卷积中感受野的范围与学习结果有关,为了进一步提高情感表征的恢复效果,卷积核的大小随通道数的变化而变化,从而学习不同感受野下的细节信息[8]。本文提出的生成器网络的结构如图2所示。

图2 本文生成器网络结构
1.3 判决器网络结构
判决器网络实际是二分类网络,对去噪的结果进行评价,0代表去噪失败,1代表去噪成功,判决器网络评价的准确性影响模型的去噪性能。判决器网络结构需要结合生成器网络模型进行设计[9],判决器过强会导致生成器竞争失败,无法进行正常去噪;判决器过弱会导致判决器的评价指标失去参考意义,最终得到的去噪模型去噪能力过弱。根据1.2小节中的生成器网络来设计判决器网络,网络结构由5层卷积层组成,采用sigmoid函数将数值映射到0~1之间的概率,具体结构如图3所示。

图3 本文判决器网络结构
1.4 训练过程和损失函数
对于有噪声语谱图的CGAN的训练目标如下:
minGmaxDV(D,G)=Ex~Pdata(x)[log2D(x|y)]+Ez~Pz(z)[log2(1-D(G(z|y)))]
(1)
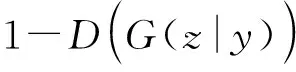
(1)给定生成器模型,优化判决器,判决器的损失函数如下:
L(D)=Ex~Pdata(x)[log2D(x|y)]+Ez~Pz(z)[log2(1-D(G(z|y)))]=
(2)
式中,Pdata(x)表示干净的语谱图概率分布,PG(x)表示通过生成器去噪之后的语谱图概率分布。当输入干净的语谱图时,D(x|y)输出的概率值较大;当输入去噪之后的语谱图G(z|y)时,D(G(z|y))输出的概率值较小,则1-D(G(z|y))的值较大;即判决器的训练目标是使损失函数L(D)取得最大值[10]。当生成器G中的参数已给定时,Pdata(x)与PG(x)都可以看作是常数,通过对式(2)求导可得:
(3)
此时,判决器取得最优值。
(2)在判决器取得优的情况下,训练生成器。生成器的训练目标是输出的去噪语谱图能混淆判定器,使得判定器将去噪之后的语谱图判定为1,即干净的语谱图。生成的损失函数如下:
L(G)=Ex~Pdata(x)[log2D(x|y)]+Ez~Pz(z)[log2(1-D(G(z|y)))]=
(4)
式中:
(5)
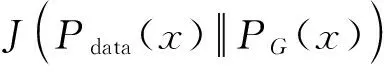
综上所述,去噪之后的语谱图当且仅当等于干净的语谱图时,生成器的损失函数取得最优值。
由于噪声环境下提取的语谱图与对应干净语谱图的矩阵距离差异过大,通过原始生成器的损失函数很难完全学习到2幅图像间的映射关系。为此,本文提出矩阵条件生成对抗网络(Matrix Distance-Conditional Generative Adversarial Networks,MD-CGAN),通过在生成器的损失函数L(G)中加入谱图的矩阵距离参数来对谱图的生成过程进行约束。该矩阵距离参数通过计算2个谱图整体的欧氏距离得到,将谱图损失和对抗损失结合起来共同作为损失方程。根据式(5)结合谱图损失,得到改进后的损失方程如下:
(6)
式中,λ表示矩阵距离参数,权重Ig表示生成器的输出,即去噪之后的语谱图,Ix表示干净的语谱图,w,h,c分别表示语谱图的宽度、高度和通道数。式(6)根据矩阵距离防止过拟合现象的发生,防止语谱图去噪之后情感特征质量下降,使得去噪之后的语谱图质量得到提升。
(3)返回步骤1,直到训练达到最优值,即判决器的损失函数取得最大值,生成器的损失函数取得最小值。
当环境噪声为白噪声,信噪比为0 dB时,不同阶段的语谱图如图4所示。

图4 采用本文算法去噪前后语谱图
图4中,颜色的深浅表示能量的大小,颜色越浅表示能量越大,颜色越深表示能量越小。一条条横向的条纹称为“声纹”,代表元音的基频以及各次谐波,其中曲折、升降变化表示音高的变化[11]。对比3张图可以看出,噪声对语谱图的“声纹”和语音能量信息影响较大,而通过MD-CGAN去噪模型得到的语谱图能够较好的回复“条纹”和能量信息,与干净的语谱图较为相似。
1.5 矩阵距离权重选择
生成器的损失函数中,矩阵距离权重λ影响去噪模型的整体性能。为了探究矩阵距离权重λ对本文算法去噪性能的影响,随机选取100张携带噪声的语音(包含马路噪声、餐厅噪声、高斯噪声等),设定不同矩阵距离权重λ,采用本文算法去噪后进行情感分类,分类结果如图5所示。

图5 不同矩阵距离权重下的识别性能比较
从图5的结果可以看出,矩阵距离权重λ为0.76时,本文算法的去噪性能最优。
2 实验结果与分析
在不同噪声环境下,通过实验来验证本文提出的基于MD-CGAN的语音情感去噪算法的语音情感特征恢复效果。分别采用无去噪的情感识别算法、基于最小均方误差(Least Mean Square,LMS)的经典语音去噪方法[12]和本文算法进行实验,比较分析3种算法的情感识别率。
实验采用语音情感CASIA数据库和噪声Noise-92数据库。CASIA数据集是由中科院自动化研究所录制的汉语语音情感数据库,由4位专业人员(2位男生,2位女生),在没有噪声污染的录音环境下录制,包括6种情感:生气(angry)、害怕(fear)、高兴(happy)、中性(neutral)、伤心(sad)、惊奇(surprise)。整个语料库的样本语音采用16 kHz采样,16 bit量化,选取相同文本50句的6种情感语音共1 200条构成实验语音库,每种情感有200个音频[13]。Noise-92数据库由荷兰语音研究所测量的噪声数据库,包含100种不同的噪声,样本采样率为19.98 kHz,16 bit量化,本文选取其中4种常见的噪声,即白噪声、餐厅噪声、工厂噪声和马路上的噪声。
针对信噪比的选择问题,实验选取较为典型的0 dB情况作为主要研究对象。实验将2个语音按信噪比为0 dB进行混合,组成有噪声的语音情感和干净的语音情感。
实验服务器GPU为NVIDIA TITAN RTX,训练使用的深度学习框架为Pytorch,在MD-CGAN网络中批次大小为32,迭代次数为100 000次,全局学习率为0.004,通过适应性矩估计(Adaptive moment estimation,Adam)优化器进行优化。经过MD-CGAN去噪后的语谱图通过ResNet网络进行情感分类,学习率为0.001,迭代次数为500次。实验结果以识别率的形式呈现。
在4种噪音环境下,采用不去噪算法、LMS去噪算法和MD-CGAN去噪算法,经过ResNet识别网络,得到的识别率如表1所示。

表1 不同噪声环境下,不同去噪算法的情感语音识别率 单位:%
从表1可以看出,在4种噪声环境下的情感语音识别效果较差,平均识别率为28.13%;经过传统的LMS去噪算法去噪之后,平均情感语音识别率达到74.27%,去噪效果较好;经过本文提出的MD-CGAN去噪算法去噪后,平均情感语音识别率达到80.96%,去噪效果更加明显,相较于不去噪识别率提升了52.83%,相较于传统的LMS去噪算法,识别率提升了6.69%。所以,本文提出的语音去噪算法对情感语音有更好地去噪效果,有效提升情感语音识别率。
3 结束语
情感语音识别系统中常常面临噪声干扰,本文对此展开相关研究,分析噪声给情感语音识别系统带来的识别率下降等问题的原因,提出一种基于MD-CGAN去噪算法,有效提高了语音情感在噪声环境下的识别率。但是,本文实验所采用的数据库是在实验室环境下录制的,缺少自然语音数据库的实验结果。在以后的研究中,会更加注重实际生活中的语音情感信息,加快语音情感识别系统在生活中的应用。
