基于卷积神经网络的车辆位姿估计算法
2021-09-29周苏郑淼郑守建金杰
周苏 郑淼 郑守建 金杰
(同济大学,上海 201804)
主题词:卷积神经网络 位姿估计 单目视觉 自动驾驶
1 前言
目标的位姿估计方法大致可分为基于激光雷达和基于视觉的2 类方法,其中,基于视觉的方法又分为单目视觉方法和双目视觉方法。以激光雷达作为传感器的位姿估计方法[1]利用三维点云数据结合深度学习对车辆目标的位姿信息进行估计,检测精度高,鲁棒性好,但往往面临成本、体积和满足车规级要求等问题。基于双目视觉的方法[2-4]利用左、右图像的视差对不同距离的目标提取相应的特征,且基线越长,测量距离越远,精度虽高,却很难满足实时性要求。相比之下,单目视觉以其成本低、速度快等优点在自动驾驶场景中有着广泛的应用。
在目标的位姿估计中,目标的距离、语义信息和姿态信息是不可或缺的。在距离检测方面,单目视觉方法一般采取标定的方式进行距离估计[5-6],即利用先验信息,以目标的检测框底边来估计目标的距离。对于目标姿态和尺度信息,单目视觉更多采用估计的方式,其中,对目标的语义特征进行建模用于估计目标姿态,目标的参考基准可用于估计尺度信息[7]。例如,Roddick[8]基于ResNet50网络,对输入图片进行特征提取,并对特征进行正交变换处理,解决了透视效果影响的视角问题。但一方面该深度学习方法训练消耗较大,另一方面,其所搭建的神经网络提取特征困难,导致目标尺度估计的准确率低;而在传统的基于单目摄像头的解决方案,如单目同时定位与地图构建(Simutaneous Location and Mapping,SLAM)[9]算法中,除了单目相机的图像信号,还会利用惯性传感器,通过积分预算提供尺度信号和速度信号。传统方案往往需要利用更多的传感器来解决单目视觉从二维信号恢复到三维信号的尺度问题,计算量倍增。
针对现有单目视觉方案存在的问题,本文提出一种纯单目视觉算法,通过设计卷积神经网络对车辆目标的尺寸、姿态角以及3D 中心点进行估计。基于一阶段检测算法对车辆目标进行定位,训练一个二级位姿估计网络用于车辆目标的位姿估计,将检测算法和位姿算法相结合以解决交通场景中车辆目标位姿估计的问题。
2 位姿估计算法模型基础
2.1 单目相机模型
采用如图1 所示的针孔相机模型。其中,Ow-Xw-Yw-Zw为世界坐标系。分别以相机光心Oc、图像平面中心O1和图像平面右上点O2为坐标原点构成相机坐标系Oc-Xc-Yc-Zc、图像坐标系O1-x-y和像素平面坐标系O2-u-v,f为相机焦距,(Xcp,Ycp,Zcp)为点P在相机坐标系下的坐标,(xp,yp)为点P在图像坐标系下的坐标。小孔成像原理描述了物相间的关系。
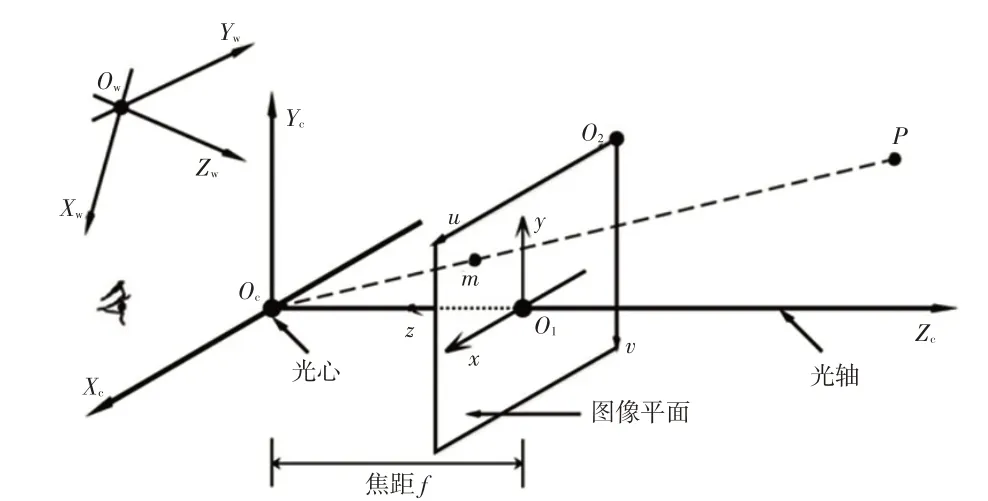
图1 针孔相机模型
如图1所示,u轴向右与x轴平行,v轴向下与y轴平行。因此,像素坐标(up,vp)和图像坐标(xp,yp)满足:

式中,α、β为缩放因子;cx、cy为平移因子。
令αf=fx、βf=fy,齐次坐标的矩阵形式为:
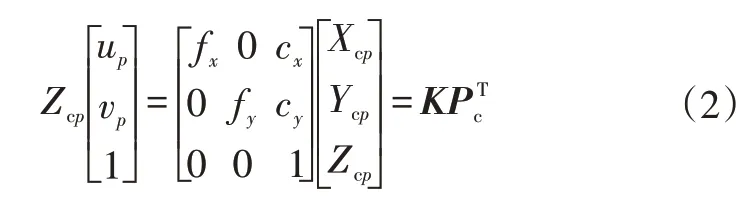
式中,Pc=(Xcp,Ycp,Zcp)为点P的相机坐标向量;K为相机内参矩阵,可利用张正友标定法[10]标定。
由于相机在运动,所以P的相机坐标应该由它的世界坐标向量Pw,根据相机当前的位姿变换得到:
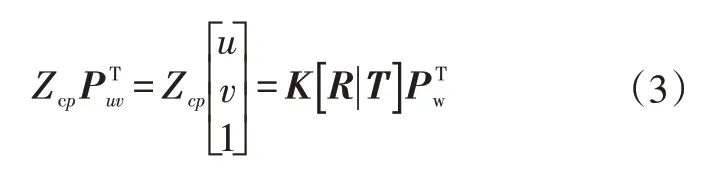
式中,R为旋转向量;T为平移向量。
2.2 车辆尺度建模
在进行车辆位姿估计前,需要通过检测网络得到目标的类别和检测框大小。不同类别目标的3D尺度相差较大,对于不同类别分别取均值。针对每个类别目标的尺度差值,以检测网络为估计模型,以类别作为先验信息,降低网络的学习难度。在KITTI数据集上对不同类别目标的3D尺度进行统计,结果如表1所示。
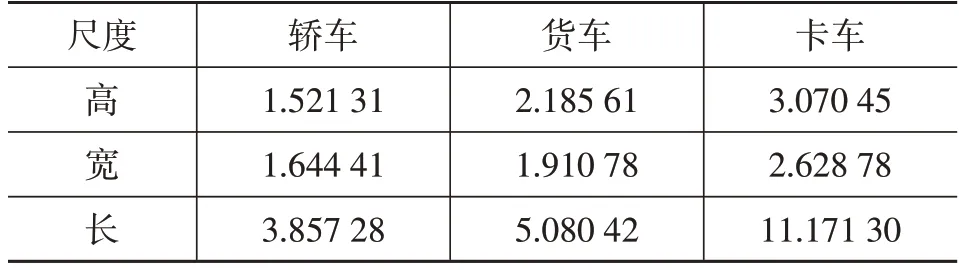
表1 不同车辆类别尺寸均值 m
尺度的损失值取平方差,则损失函数为:
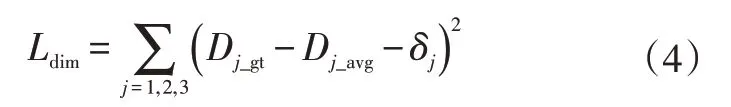
式中,Dj_gt、Dj_avg分别为对应目标类别的3个尺度的真值、均值;δj为网络对应的3个尺度的输出;j=1,2,3分别表示长、宽、高3个尺度。
网络训练完成后,目标相应类别的预测值Dj_pre(j=1,2,3)为:

2.3 车辆姿态角建模
目标的姿态角模型如图2所示,目标的姿态由观察角θray、当地位置角θ以及相机与目标中心连线方向与目标行驶方向之间的夹角θl描述。其中θray由目标在图像中的位置直接计算得到。θ相同但距离不同的目标经过裁剪后的输入是不同的。因此,对位姿角建模时不能对θ直接建模,应以如图2 所示的θl进行输出建模。θl、θray和θ应满足:

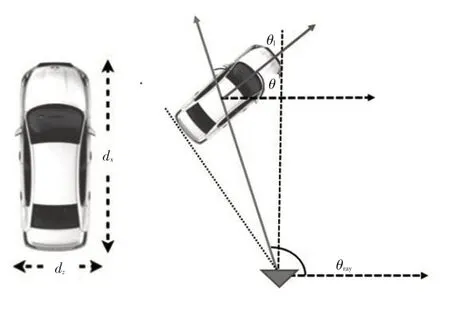
图2 目标姿态角模型
θl的取值范围为[0,2π),对其直接估计相对困难。因此,先对目标的θl进行分类,再对目标采用小角度回归方式估计姿态角。设θl的类别数量为n,则每个类别的角度范围的大小为2π∕n,第i个类别的角度范围为[i·2π∕n,(i+1)·2π∕n),i∈{0,1,…,n-1}。θl的类别置信度的损失函数为:

θl的实际角度偏移为:

设偏移损失函数为:
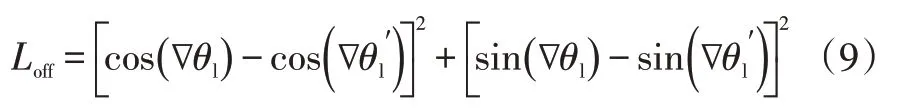
化简并去除比例系数后的损失函数为:

采用上述形式的损失函数,其导函数较为平滑,有利于网络优化。当θl偏移的绝对值较大时,梯度较大,能有效抑制离群点。
2.4 车辆3D Box建模
车辆三维边框(3D Bounding Box)可用{a,b,c,w,h,d,Y}表述,其中,(a,b,c)为3D Box的中心坐标,{w,h,d}和Y分别为车辆的长、高、宽和航向角,其值由网络模型输出。航向角Y和姿态角θ满足Y=π∕2-θ。车辆3D Box建模采用如下假设:车辆的翻滚角和俯仰角均为0;车辆中心与3D Box中心完全重合。
采用检测网络能够获得精确的车辆2D检测框(2D Box)。因此,构建2D Box和3D Box之间的投影关系,是车辆3D Box建模的关键。如图3所示,A、B、C、D4个点为目标在图像中的2D Box角点,编号为0~7的8个点为目标在图像上的3D Box 角点,交叉线所在面表示目标的朝向。假设候选3D Box的尺度为{w,h,d},其在同原点的世界坐标系中的坐标分别为:
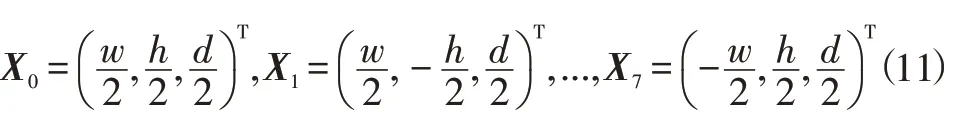
3D Box 的每个角至少能投射到2D Box 的1 条边上。如图3 的中点0,其投影到2D Box 的左边之上,由式(3)可知,两点坐标满足:
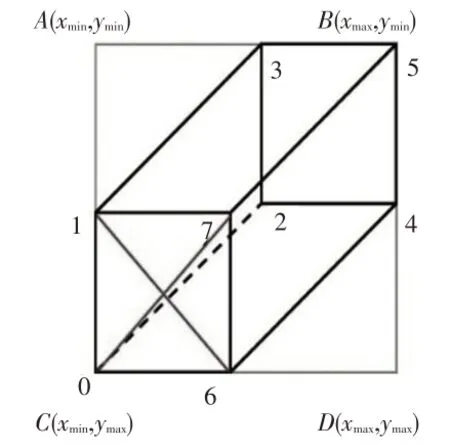
图3 3D Box与2D Box之间投影关系

对于其他点也能得到类似方程,即4 个2D Box 与3D Box 之间的约束关系。4 个方程均为类似Ax=0 的线性方程,可以通过奇异值分解(Singular Value Decomposition,SVD)[11]求得相应的平移向量T。一组4 个点到4条边的约束关系得到一组平移向量,再将平移向量T与物体的3D 尺度代入式(3),就可以得到预测的2D Box和检测网络计算的2D Box的误差。
3D Box 的点和2D Box 的边之间的关系无法直接获取,因此,实际计算过程中,取多组点对的计算结果中误差值对应最小的平移向量作为最后的计算结果,图4 所示为平移向量T的计算流程。其中,2D Box 用{xmin,ymin,xmax,ymax}表示,目标尺度用{w,h,d}表示,S表示以目标车辆3D Box 中心点为坐标系所对应顶点的坐标,初始投影误差E设置为一个浮点数范围内的极大值。

图4 平移向量T的计算流程
3 位姿估计网络构建、训练及检测
3.1 位姿估计网络构建
位姿网络的输入为一张包含较大信息量且无关噪声较少的三通道彩色图片,设计一种层数及通道数较少的卷积神经网络结构,提取特征的同时使位姿网络的前传消耗不至于过大。网络总体结构如图5 所示。
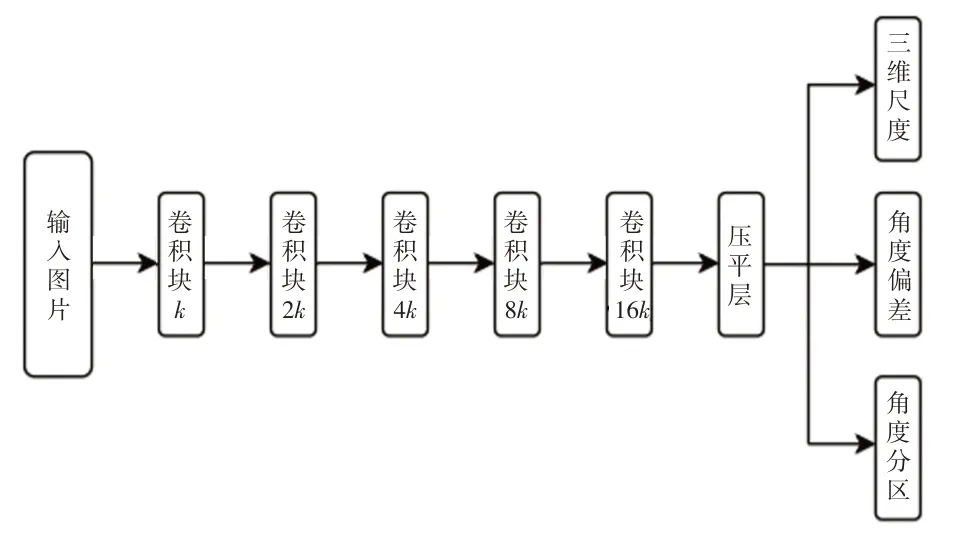
图5 位姿网络结构示意
将检测到的目标区域缩放到固定大小(224,224,3)并作为位姿网络的输入。设卷积块内的通道数量k=8个。卷积块由多个卷积集组成,每经过一个卷积块会利用步长为2 的卷积操作降低特征图的尺度,同时增加通道数量提升特征图的感受野,作为对特征图尺度降低的弥补。最后的压平层模块将多维输入转化为一维,作为卷积层到全连接层的过渡。位姿网络中的尺度模块预测目标3D 尺度,分区模块推测姿态角所在的角度分块区域,方向模块推测实际角度与区块中的实际角度之间的偏差,3 个模块共享骨干网络的输出特征。
3.2 位姿估计网络训练
构建网络结构后,通过上述目标函数构建网络总体的损失函数,对神经网络进行训练。网络训练过程的总损失如图6所示,包括尺度、分区和方向3个模块,属于多任务训练。任务之间根据重要程度设置不同的权重比,本文设置损失函数为:
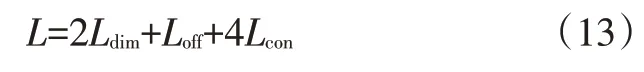
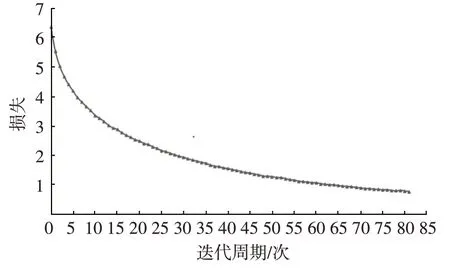
图6 位姿估计网络训练损失
在网络训练过程中,损失逐渐下降且速度变慢,直至网络收敛。训练过程中设置批大小为32 张,学习率为0.001,在迭代周期至80 次左右时,网络趋于收敛。
位姿网络的可视化特征图如图7、图8 所示。由图7、图8可以看出,浅层特征图保留了车辆形状和纹理信息,深层特征图则具有更加抽象的、富含语义的关键点信息,如车灯、后视镜及A 柱等有效特征。从网络损失角度而言,网络总体趋势是收敛的,神经网络能够有效提取用于降低损失的特征;从可视化的结果也可以看出,对于车辆输入目标,神经网络能够有效提取相应的特征。
传统的纹理贴图技术确有助益,但是当近距离观察采用纹理贴图技术进行绘制的物体时,其效果就大打折扣了。利用传统的纹理贴图技术可以呈现出物体表面的一些凹痕和细小的裂纹,但是这些细节仅仅通过颜色变化而被表现出来,它们更像是被直接涂染到物体表面上而并非客观存在的,整体的真实感太低。而现实中的物体表面大多并非光滑平坦,而是表现出无数凹凸不平的细节。

图7 可视化特征图

图8 深层特征图与输入对比
3.3 位姿估计网络算法集成与检测
3.3.1 位姿估计网络算法集成
以检测网络的输出作为位姿估计网络的输入,算法主要分为以下几个步骤:
a.通过目标在图像中的位置{xmin,ymin,xmax,ymax}和相机的内参计算得到目标的2D框中心c和观察角θray:

b.将目标图像裁剪缩放后进行网络前传,获得分类类别置信度最高的区域m、总类别数n和偏移角o,姿态角为:

c.根据3D Box建模方式计算目标的平移向量T;
d.由T和目标的3D 尺寸得到3D Box 中8 个点在相机坐标系中的坐标,根据式(3)计算每个点的像素坐标,由此绘制3D Box,流程如图9所示。

图9 位姿估计流程示意
3.3.2 位姿估计网络检测结果可视化
试验所使用硬件平台包括一台单显卡的台式机和一台带4 块TITAN X(PASCAL)显卡的深度学习工作站。2 个硬件平台的参数配置如表2 所示,硬件平台1 主要用于模型训练后的系统结构搭建和测试,硬件平台2 主要用于需要大量并行运算的卷积神经网络的模型训练。本文关于模型运算速度的测试均在硬件平台1 上完成,视频采集设备如图10所示。
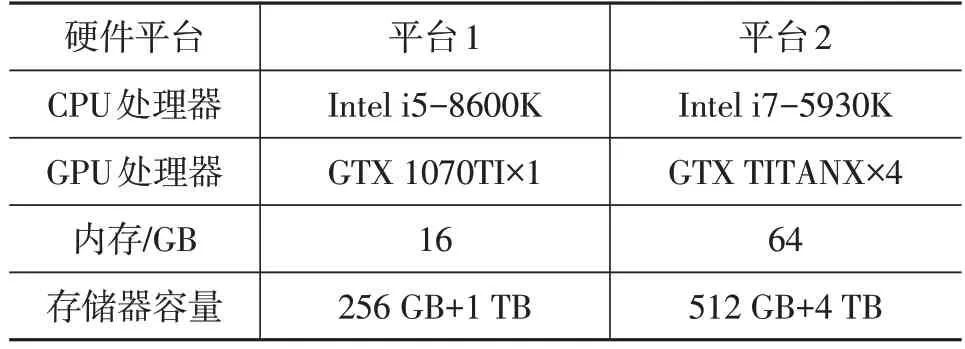
表2 试验硬件平台

图10 视频采集设备
对KITTI 数据集中的车辆目标进行可视化,结果如图11 所示。可视化绘制过程中,目标朝向的面添加2 条交叉的对角线。对于目标部分被遮挡和被图像边缘截断的情况,通过目标2D Box 和图像边界的距离设置阈值进行过滤。普通目标送入位姿估计网络,被过滤目标只进行2D Box 检测。实际的视频采集过程中,被过滤目标大多在本车的相邻车道或摄像头视野临界位置。

图11 3D Box可视化结果
3.3.3 位姿估计网络精度对比
精度测试的内容包括目标的尺度(长、宽、高)误差,基于KITTI测试集对每个目标根据所属类别在不同距离下进行计算,每个值计算预测值与真实值之间差值的绝对值,最后在每个距离内进行平均,尺度和角度误差如图12所示。
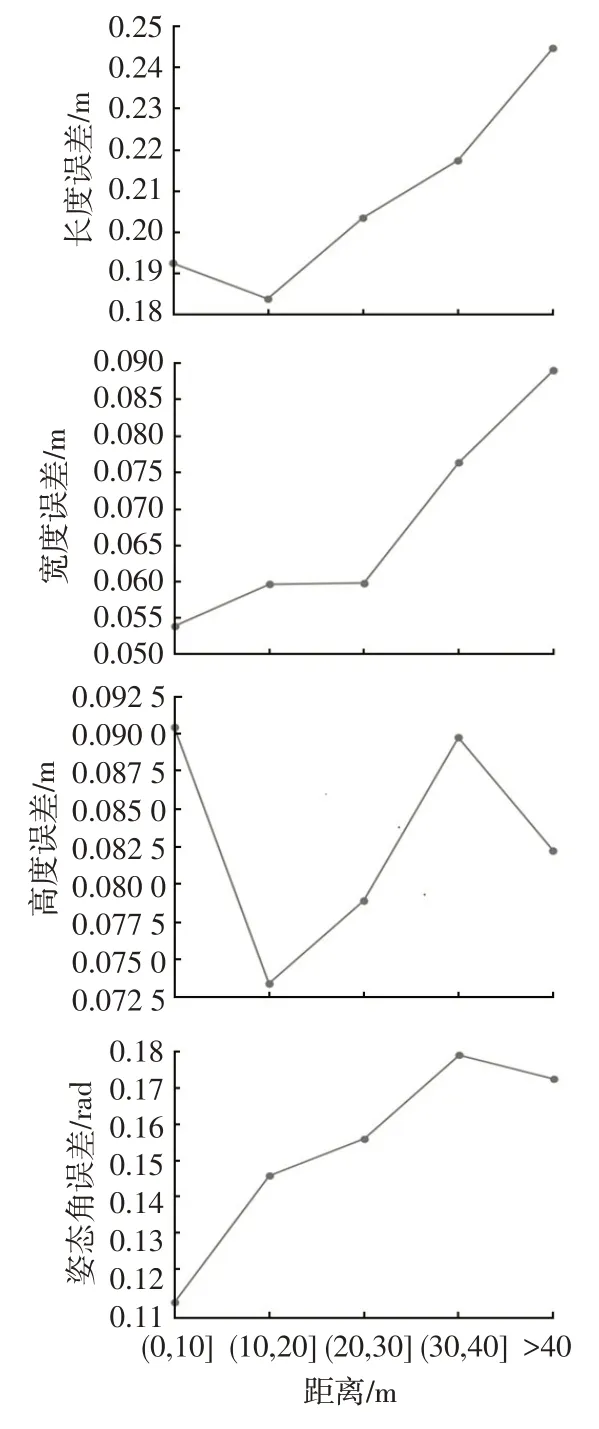
图12 不同距离下的尺度和角度误差
在尺度误差中,宽度和高度的误差基本不超过0.09 m,长度误差稍高,但最大值不超过0.24 m。这部分误差相对较低,原因在于车辆的长、宽、高的取值范围本身并不大,同时在估计的过程中,最终预测值是网络输出的估计偏差与先验的长、宽、高的统计平均值之和,这样也保证了最终的结果不会有很大的偏差。在角度误差中,随着距离的上升,误差增大,最大值约为0.18 rad。
同时将本文算法和当前精度最高的单目位姿估计算法子类别感知卷积神经网络(Subcategory-aware Convolutional Neural Networks,Sub-CNN)[12]进行精度对比。采用相机坐标系中心到3D目标中心点的距离作为距离评价指标,误差如图13 所示。本文算法相对于Sub-CNN而言,在不同距离下均有更高的精度,平均误差比Sub-CNN小0.371 2 m。
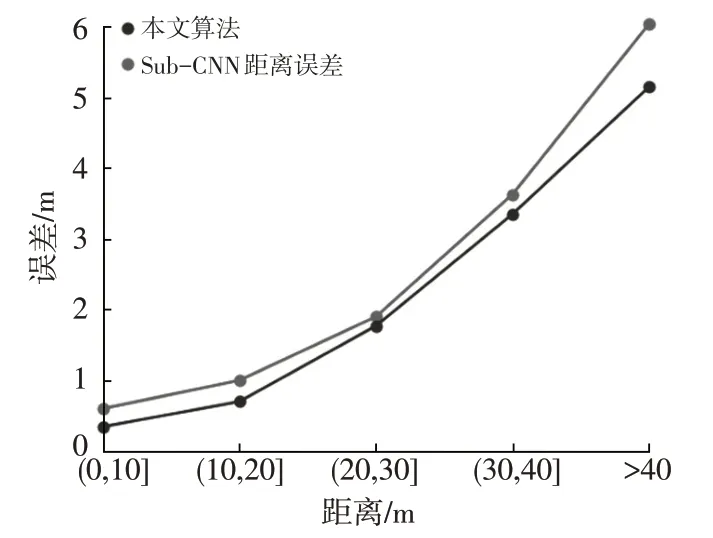
图13 本文算法和Sub-CNN距离误差
2 种方法采用平均方向相似性(Average Orientation Similarity,AOS)作为角度评价指标[13]。以Sub-CNN 和本文算法估计的姿态角作为评价对象,Sub-CNN 算法平均方向相似性为85.99%,本文算法为86.14%,比Sub-CNN高约0.15百分点。
3.3.4 位姿估计网络速度测试
位姿估计网络前传时间的统计结果如图14 所示,总体分布趋近于正态分布,均值为0.019 71 s,方差为5×10-7s2,前传时间稳定。
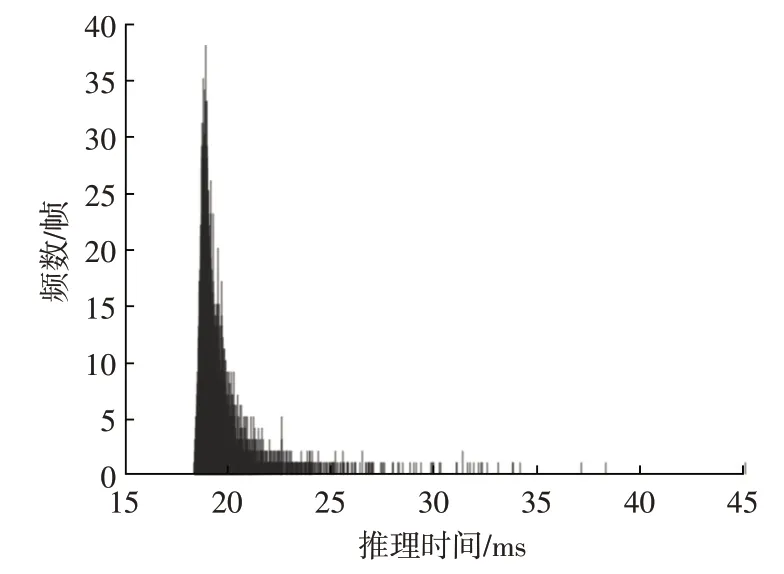
图14 前传时间
4 结束语
针对目标位姿估计问题,本文基于单目视觉原理,提出了一种基于卷积神经网络的位姿估计算法。首先利用KITTI数据集的车辆长、宽、高均值进行计算,对长、宽、高和均值的偏差进行尺度估计;对角度采用分类代替回归的方式,先对角度进行分块的方式进行分类,再对分类的偏差值进行小角度的回归以估计目标的姿态角;最后根据估计出的目标长、宽、高和姿态角,利用3D Box 和2D Box 投影关系对目标中心点距离进行建模估计。对整个位姿估计网络训练并测试,结果表明,本文所提出的车辆位姿估计网络实时性较好,且在不同目标距离下与当前最优的算法Sub-CNN相比,均有更高的估计精度。
