A Motion Planning Method Based on Reinforcement Learning for Automatic Parallel Parking in Small Slot
2021-09-29SunHongweiChenHuiSongShaoyu
Sun Hongwei,Chen Hui,Song Shaoyu
(Tongji University,Shanghai 201804)
【Abstract】In order to solve the problem of low efficiency for parallel parking in narrow space with traditional methods or methods based on reinforcement learning,this paper proposes a Monte Carlo Tree Search (MCTS) based method to plan simultaneously reversing and adjusting stages of parallel parking in tiny parking space.In the MCTS process,longitudinal action (velocity) and lateral action (steering wheel angle) are considered at the same time.Imitation Learning(IL) is introduced,which utilizes demonstration data from non-linear programming to get an initialized policy neural network and then uses RL to improve it,which reduces the training time from 20 h to 1 h.A sliding mode controller is adopted as lateral controller to track the planned path and the direction can be determined by the planned velocity profile bound on the planned path.The results of simulations and vehicle tests show that the proposed method can plan simultaneously 2 stages of parallel parking and complete the parking in tiny slot within 5 cm position error and 0.5°heading angle error.
Key words:Parallel parking,Motion planning,Imitation learning,Reinforcement learning,Sliding mode controller
1 Introduction
In the analysis of the causes of road accidents,approximately 23%of accidents are related to parking scenarios,and 75%of parking-related accidents are related to the process of reversing[1].The automatic parking system can improve safety and reduce the occurrence of traffic accidents,while saving time and energy.
Automatic parking system generally consists of 2 modules:slot detection and motion planning.Motion planning module,which guides vehicle into detected slot space,is a crucial module that determines how intelligent the system is[2].In this paper motion planning is focused.The methods of motion planning can be divided into 2 branches,namely,classical branch and artificial intelligence-based branch.
The classical branch generally is made up of geometric-based methods,heuristic search-based methods and optimization-based methods.Geometric-based methods are the most commonly used methods.Common curves used in geometric-based methods include Reeds-Sheep(RS)curve[3],clothoid curve[4]andβ-spline[5].The representative of the methods based on heuristic search is Hybrid-A*[6].Rapidly-exploring Random Trees(RRT)[7]is also a path planning method using heuristic information.Optimization-based methods[2,8-9]transform the planning problem into a numerical optimization problem through precise mathematical modelling considering objectives such as safety and comfort in the objective function to solve the parking problem.However,it needs a lot of computational source,which prevents its wide application on real vehicle.
Recently,the intelligent methods get more and more popular.Basic tool for this branch is Artificial Neural Network(ANN)[10-11].Since the AlphaGo[12]and AlphaGo Zeros[13],Reinforcement Learning(RL)is getting more and more attention of researchers in the field of autonomous driving[14],especially in the field of motion planning[15-16].The Deep Deterministic Policy Gradient(DDPG)[17],a model-free reinforcement learning method,has been applied to realize end-to-end automatic vertical parking.The learning process is tedious,even though vertical parking is much easier than parallel parking.In[18],Deep Q-Network(DQN)was researched and applied on automatic parking system.Although the training efficiency was improved by human demonstrations,the time for convergence was still so long.Monte Carlo Tree Search(MCTS)[19],a model-based reinforcement learning method,has been applied to realize automatic parallel parking combining with neural network[20].It can ensure multiobjective optimization,including safety,comfort,parking efficiency and final parking performance.However,the method in[20]only concerns lateral action(steering angle)while longitudinal action(velocity)is predefined within av-tcurve.
Based on the previous work[20],this paper aims to realize parallel parking in narrow slot in a unified manner.To realize forward and backward maneuver of vehicles,longitudinal action(velocity)is not predefined and is considered together with lateral action(steering angle).To speed up the training process of RL,Imitation Learning(IL)[21]is utilized in this work to initialize the Policy Neural Network(PNN),which is a component of agent.And then RL fine-tunes the PNN to improve its ability for parking until its convergence.The basic framework of RL is General Policy Improvement(GPI)[22].During GPI,onestep-MCTS is the operator for policy improvement.The trained PNN and one-step MCTS,components of agent,are packed into a planner.To eliminate the effect of model gap between kinematic vehicle model and real vehicle,a sliding mode controller is adopted to track the planned path by planner.
2 Problem Statement
2.1 Scenario Setting
Parallel parking is the most difficult scenario for automatic parking.So,in this paper parallel parking is chosen as the research scenario.The parallel parking scenario is shown in Figure 1 and there are 20 initial parking poses(represented by midpoint of rear axle).The coordination used in parking is bound to the left-rear point of front obstacle vehicle.According to ISO 16787[23],the initial clear side distance of vehicle should be 0.9~1.5 m.Adding the half width(1.551 m∕2≈0.775 m)of real vehicle platform used in experiments,the scope ofyis set to 1.25 m,1.50 m,1.75 m,2.00 m,2.25 m,which covers the scope recommended by ISO 16787.There is no recommendation for directionxin ISO 16787 and the scope ofxis empirically set to 2.0 m,2.5 m,3.0 m,3.5 m.Initial heading angles are all set to 0.Moreover,according to ISO 16787,the length of parking slot is set to 4.57 m which is 1 m longer than the length(3.57 m)of the real vehicle platform.Target parking depth in parking slot is set to 0.9 m and target heading angle is set to 0°.

Figure 1.Initial 20 Poses in parallel parking scenario
2.2 Problems of RL-Based Motion Planning Method for Parallel Parking in Narrow Slot
In previous works[20],the parallel parking process was divided into reversing stage and adjusting stage.The agent only takes responsibility for the reversing stage.During adjusting stage,the vehicle moves with max steering angle to adjust heading angle.The time of adjusting is unknown and the final parking pose is not determined.If the path can be generated without dividing into 2 stages,the final parking pose with respect to parking slot can be determined by the generated path,which is important for vehicle wireless charging system installed in parking slot in the future.Moreover,the adjusting times can be known in advance.So how to plan simultaneously reversing stage and adjusting stage of parallel parking in narrow slot is the first problem for reinforcement learning-based method.
The reward function shaping in reinforcement learning is a hard work,which guides the agent to explore better action during learning.If the reward function is not well designed,the training process will be long and even fail.So how to speed up the training process is the second problem.
The adopted reinforcement learning method MCTS is a model-based method,so a model of vehicle is needed.Kinematic vehicle model is ideal and different from real vehicle.The model error is inevitable.The trained agent outputs a series of nominal velocity and steering angle commands.If these commands are executed by Electronic Power System(EPS)and driving motor one by one,the task may fail.Therefore,eliminating the influence of model error is the third problem to be solved in this paper.
3 Proposed Method for Automatic Parking System
3.1 Unified Lateral and Longitudinal Action Representing
In previous works[20],the action considers lateral action,merely,i.e.,incremental steering angle in Δt.The longitudinal action,velocity,is predefined by av-tcurve.The velocity is always negative,so the direction of vehicle is always backward.To make the agent has the ability to move forward and backward in parking slot,the longitudinal action,velocity,should be considered together.Inspired by the incremental steering angle of lateral action,the longitudinal action is represented as change of velocity in Δt.Therefore,actionais represented as a vector as:

In which,Δφ,Δνrepresents change of steering angle,change of velocity separately.
Considering that the max steering angle rate of real vehicle is 400°∕s and the planning period Δtis 50 ms,Δφis set Δφ∈{-20°,-10°,0°,10°,20°}.The max acceleration is set to 0.3 m∕s2and Δφis set Δν∈{-0.015 m∕s,0 m∕s,0.015 m∕s}.Therefore Δφand Δνconstitute 15 actions of the action candidate set.The{s,a}pair means that the agent takes the actionaunder states.
3.2 Efficient Workflow of Training
Reinforcement learning is essentially a method by“trial and error”[24].The agent explores the environment through trying action randomly or according to a policy.The result of the trial is judged by a reward function after meeting terminal condition.The more reward,the more probability of the action is.Therefore,reward function plays a great role.However,the shaping of reward function is not so easy,even with well-designed reward function,the process of training lasts long time and even fails finally.Moreover,the reward is sparse and highly delayed because it can be acquired only after termination.
To speed up the training and reduce the design effort of the reward function,an efficient workflow of training for parallel parking will be introduced in this paper.Figure 2 shows the workflow of training by combining imitation learning and reinforcement learning.
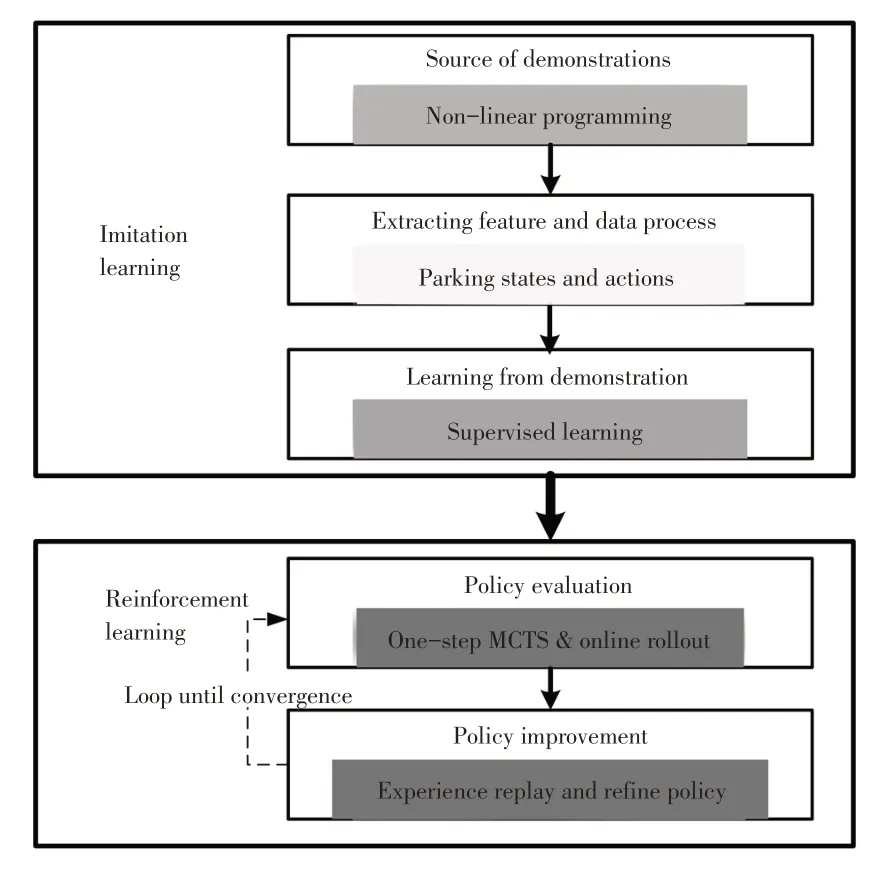
Figure 2.Training workflow combining imitation learning and reinforcement learning
In terms of imitation learning,demonstrations[25]come from a“teacher”.Intuitively an experienced human driver may be a good teacher.However,collecting lots of parking relevant data from an experienced human driver is time consuming and laborious.A human driver can hardly consider multi-objective optimization including safety,comfort,parking efficiency and final parking performance simultaneously.Therefore Non-Linear Programming(NLP)based automatic parking method[26]is considered to directly generate demonstrations.Although the NLP-based method needs large computation sources to be applied on real hardware,it can generate a lot of parking data offline on personal computers.The details of NLP-based automatic parking method can be found in[26].Thanks to the work of B.Li,a lot of demonstrations are acquired quickly.After acquiring demonstrations from“teacher”,demonstrations are organized in form of{s,a}pairs.Then supervised learning is utilized to map states to actions.A fully connected ANN is trained,which is actually a classifier that outputs the probability distribution of different actions under the input state.The trained ANN is called initial PNN and denotedπ0.Actually the demonstrations data guide the agent to imitate behaviors under different states without reward function feedback.The initial policyπ0is not enough to perform well in the given parallel parking task due to a number of issues such as demonstrations are insufficient to cover state space during parking.In this method,demonstrations are processed by linear interpolation according to time stamp.Therefore,errors of processed demonstrations are the main reasons for terrible enough performance ofπ0.
Reinforcement learning is then conducted based onπ0.Reinforcement learning repeats 2 steps iteratively:policy evaluation and policy improvement.In thei-th iteration,for policy evaluation,the agent performsπiand gets new experiences data online.These experience data are then filtered by reward function and filtered experience are utilized to refine policy.Refined policy isπi+1.The process of reinforcement learning will be stopped until the policy is converged.
3.3 Initializing Policy Neural Network by Imitation
Imitation learning is composed of 3 steps:acquiring demonstrations,data process and policy initialization.
3.3.1 Acquiring demonstrations and data process
The NLP-based parking method[26]generates demonstrations of parking data.The demonstration data are organized in{s,a}.Statesis a vector:

In which,(x,y,θ)represents the pose of vehicle;φrepresents the steering angle;vrepresents velocity.
3.3.2 Policy initialization
Generally,the function of a policyπ(a|s)is mapping a state to an action during parking.πis in the form of an ANN,called PNN,of which the input is the state vectorsand the output is the probability distribution of 15 actions in the candidate set.So the PNN is actually a classifier indicating the prioritization of actions under current state.
3.4 Refining Policy Neural Network by Reinforcement Learning
After initialization the PNNπ0(a|s),reinforcement learning is conducted to improve its ability of action exploration for parking.In this method,the PNN is used with MCTS together to achieve motion planning for automatic parking.
3.4.1 Policy evaluation by one-step MCTS and online rollout
MCTS is a family of algorithms for finding optimal actions by taking Monte-Carlo samples[19].It was used in AlphaGo[12]and Alpha Zero[13]to achieve a level above human chess players.From current statesta tree is built.Each node in tree represents a state and each edge connecting nodes is an action.Generally speaking,MCTS includes 2 steps:tree policy and default policy.Tree policy is used to choose node from tree until leaf node.Default policy is used to do imaginary online rollout until a terminal state and it will return a trajectory and a scalar reward representing the performance of the trajectory.
For general tree policy step of MCTS,the depth of traversing in tree is often more than 1.The nodes of 2nd layer must be visited at least one time.When the number of action candidates is large,it needs a lot of computation sources to build such a tree.In this setting,the number of action candidates is 15.Even for a tree with 3 layers,there are 15 nodes in the 2nd layer and 15×15(225)nodes in the 3rd layer.It is hard to traverse this huge tree.Alpha Zero solves this problem by adding information of prioritization provided by a PNN and traversing in tree selectively according to the statistic value of each node.In this paper,a shallow tree with only 2 layers is built,that is,the first layer with root node and the 2nd layer,of which the nodes represent next states transferring from root state by executing corresponding action.The transferring functionst+1=f(st,at)is kinematic model of vehicle as:

In which,Lrepresents the wheel base of vehicle;Δtrepresents the time interval;ψtrepresents the front wheel angle at the timet;vtrepresents the velocity at the timet.The nodes of the 2nd layer are all one step from root node,called one-step MCTS[27].Starting from one node of the 2nd layer is online rollout conducted.Online rollout is guided by the PNN.Roulette rule is utilized to choose action during rollout.Cumulative probabilityPcum(aj,t)of output of PNN under statest,i.e.,π(a|st)is shown as:
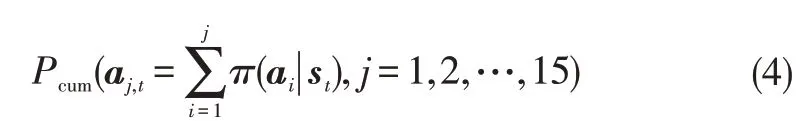
A random number,n∈[0,1]is created.The first index greater thanninPcum(aj,t)will be found and the associated action is selected.Roulette rule helps to explore actions with relative lower probability while keeps exploiting actions with large probability.
Rollout stops until terminal condition such as finish parking or collision.One rollout returns one trajectory and one reward.So there are 15 trajectories and 15 rewards in the setting after rollouts under statest.Inspired by the work of Hu[28],the trajectory with max reward (Tt-best) is chosen as the best one and is compared with the best one(Tbest)up tost-1at time(t-1).IfTt-bestis better thanTbest,updateTbest,which is,Tbest=Tt-best.IfTt-bestis worse thanTbest,statest+1followsTbest.
One-step MCTS is repeated with online rollout as shown in Figure 3 at each time stamptuntil meeting terminal state and a final parking trajectory named episode is stored,which includes many{s,a}pairs.Episode is evaluated by a reward function considering final poserpose,parking timertime,risk of collisionrcollisionand whether success or notrsuccess:
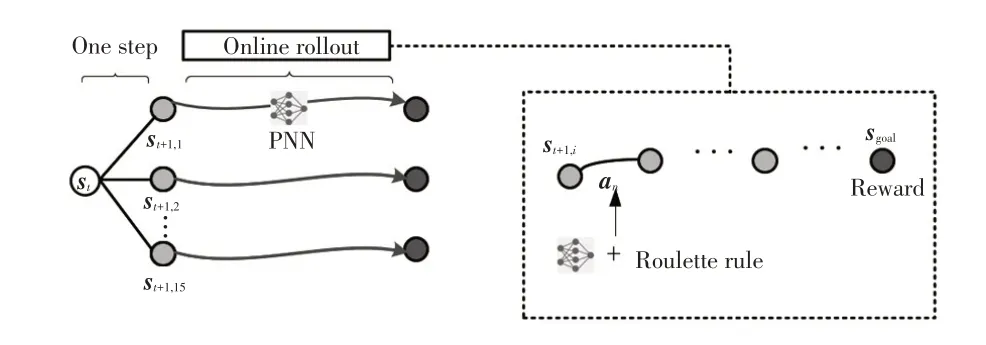
Figure 3.One-step MCTS and online rollout at the time t and state st

In which,yfinalrepresents the finaly-axis coordinate;ytargetrepresents the targety-axis coordinate mentioned in Sec-2;θfinalrepresents the final heading angle;θtargetrepresents the target heading angle 0°;tfinalrepresents the consumed time of parking.
A complete description of policy evaluation by onestep MCTS with online rollout at thei-th iteration:
Input:Initial posep0,initial steering angleφ0,initial velocityv0,PNN at(i-1)-th iteration
Output:Scalar rewardRi,actual trajectoryTi
Initialize:t=0,st=s0=(p0,φ0,v0)rmax=0,Tbest=Ø;Ti=Ø;


3.4.2 Policy improvement
After thei-th policy evaluation experiences,dataTiare stored in data pool for improving policy.As shown in Figure 4,there are a lot of episode data for 20 initial poses.Episode dataTi,nfor then-th initial pose and thei-th iteration are labelled with a scoreRi,n.Before improving policy,which is,retraining PNN,training data are sampled from the data pool.For each initial pose,the most recent episode data is not always with max score yet and the score of the most recent episode data may be so small that cannot improve the ability of PNN.Inspired by the work of[13]and[29],episode data with max score under each initial pose are collected for retraining PNN,i.e.π(a|s,w).The parameterwis adjusted by gradient descent on cross-entropy lossesH(π,q)as:
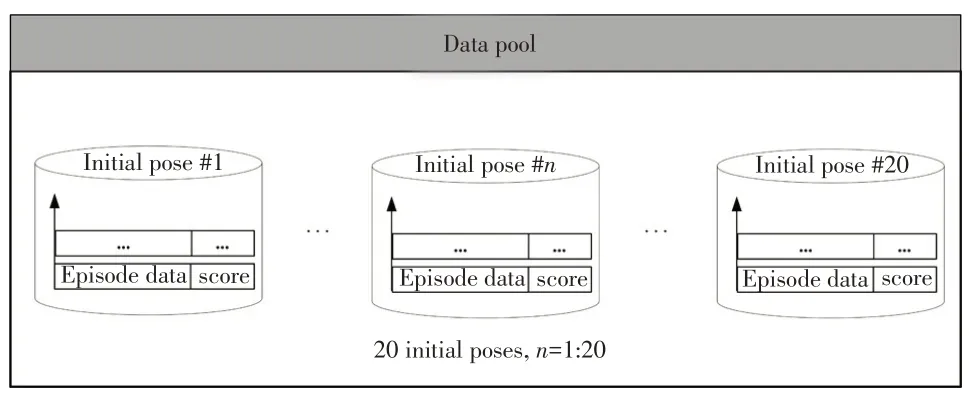
Figure 4.Episode data stored in data pool

In which,πrepresents the output of PNN;qrepresents the ground truth.
The new weighted PNN is then employed to conduct policy evaluation by one-step MCTS and online rollout again.Policy evaluation and policy improvement are performed iteratively until the PNN converges.
4 Sliding Mode Controller for Tracking
After training,the converged PNN is deployed to carry out parallel parking task.In this method,the PNN and MCTS are packaged in a trajectory planner.The output of planner is a whole parking trajectory in the form of{s,a}pairs including reversing stage and adjustment in parking slot.During training,the vehicle model is an ideal model as Eq(3),which assumes that actuators are with no delay and the state transition is deterministic.However real vehicle is equipped with actuators with stochastic delay.
The poses of output trajectories are connected by a series of open-loop nominal commands.These commands implicitly consider the constraints of max steering angle,max steering velocity and max velocity.The trajectory considers the obstacle avoidance requirement and is a kinematically feasible path associated with nominal openloop commands.
A simple Sliding Mode Controller(SMC)is adopted with non-time reference[30-31]to eliminate the influence of it.The SMC based on kinematic model is adopted to track the waypoints in the trajectory from planner.The velocity is determined by thexcoordination in the planned trajectoryT.The steering angle is output by SMC.The SMC is designed as follows.
During reversing,the erroryeand the errorθeare expected to be small at a certainx(t).The variable-x(t)is monotonically increasing and is chosen as reference variable.The errors are as:
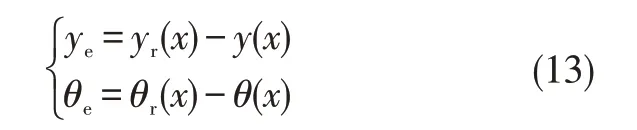
In which,yerepresents the difference between the reference coordinateyr(x)and the actual coordinate valuey(x)onY-axis at a certain coordinatexonX-axis;θerepresents the difference between reference heading angleθr(x)and the actual heading angleθ(x)at a certain coordinatex.
By taking the derivative with respect to-xfrom Eq(3),Eq(14)is derived:

In which,theLrepresents the wheelbase of vehicle;ψr(x)represents the reference front wheel angle at a certain coordinatex;ψ(x)represents the actual front wheel angle at a certain coordinatex.
Then,setting state variablex1andx2(xis omitted to simplified expression):

Then:
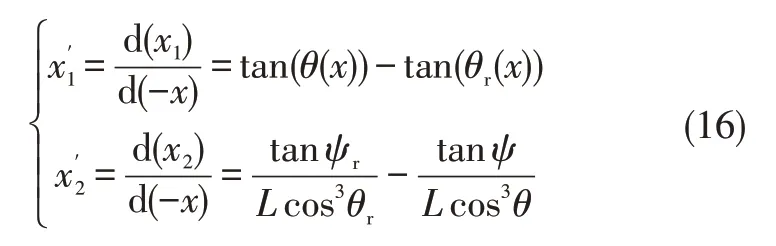
Where:

With:

The sliding mode face is set as:
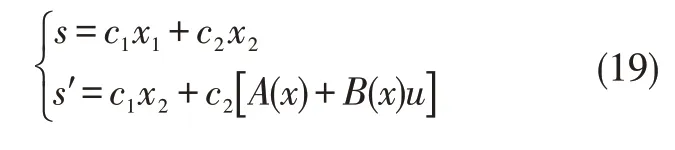
In which,c1andc2are predefined hyper parameters;srepresents sliding mode face;s′represents the derivative ofswith respect to-x.
To reduce chattering of output,thes′in Eq(19)is designed as:

In Eq(20),the predefined adjustable hyperparametersδ,εandkare greater than 0.
So,the output front wheel angle from the controller is:

When the vehicle moves forward,the reference variable is set tox(t)and the Eq(14)is transferred into Eq(22),the details are the same as moving backward:
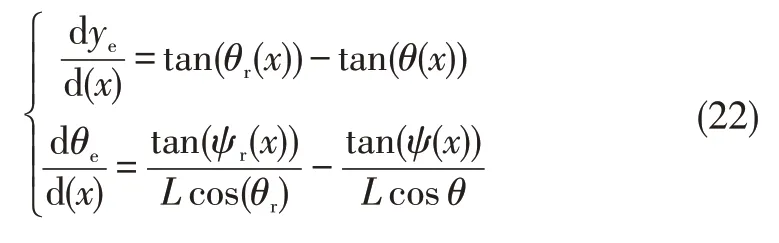
5 Simulation of Proposed Method
5.1 Effectiveness of Combining Imitation Learning and Reinforcement Learning
Based on the source code of[26],a lot of demonstrations data were acquired and were used to initialize the PNN.Based on the Machine Learning Toolbox of MATLAB,a full-connected neural network is trained with 2 hidden layers including 15 neurons respectively as shown in Figure 5.Then based on the initialized PNN and one-step MCTS,parallel parking is simulated in MATLAB.The results are shown in Figure 6a.It suggests that the PNN from Imitation learning alone is not enough for successful parking under 20 initial poses.

Figure 5.PNN in MATLAB
Then reinforcement learning was conducted to improve the ability of PNN.After 10 iterations,the average reward of 20 episodes converged.The results of parking based on the improved PNN and one-step MCTS are shown in Figure 6b.Figure 7 illustrates the effectiveness of combining imitation learning and reinforcement learning.
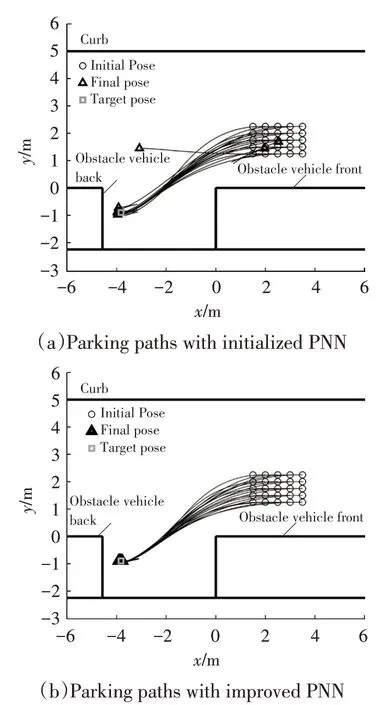
Figure 6.Comparison between different PNNs

Figure 7.Average reward during reinforcement learning
On the one hand,imitation learning speeds up reinforcement learning process.On another hand,reinforcement learning enhances imitation learning.Regarding the application of parallel parking,a near optimal PNN is derived in a short time(about 1 h)with 10 iterations.In previous works[20],the time of training is about 20 h with 800 iterations without imitation learning.
5.2 Simulation on Vehicle Simulator CarSim
Before deploying the proposed method on real vehicle platform,a simulation with vehicle simulator CarSim is conducted to validate the proposed method on high-fidelity vehicle model.The configuration of CarSim model is the same as the real vehicle in next section.Moreover,the outline of vehicle is represented by an octagon to make the best use of space.
The result path is as shown in Figure 8.The final pose is(-3.819 8 m,-0.906 7 m,-0.000 1°).The proposed method can finish automatic parallel parking in tiny parking slot without collision when deployed on CarSim model,although the planner is based on kinematic model.

Figure 8.Simulation of parallel parking on CarSim vehicle model
6 Validation of Proposed Method on Real Vehicle
6.1 Introduction of Real Vehicle
Experiments based on real vehicle were conducted to validate the proposed method.The vehicle is a Roewe E50 pure electric vehicle,as shown in Figure 9.The vehicle is equipped with an Around Vision Monitor(AVM)system around body,3 LiDARs on the top,8 radars around body,a monocular front-view camera,an RTK-GPS system and a dSpace MicroAutoBox-II(MAB-Ⅱ)with a 900 MHz processor.The whole algorithm was executed in the MAB.The actuators include an EPS and 2 longitudinal drive motors on the front wheels.Table 1 shows the basic configuration of the vehicle.
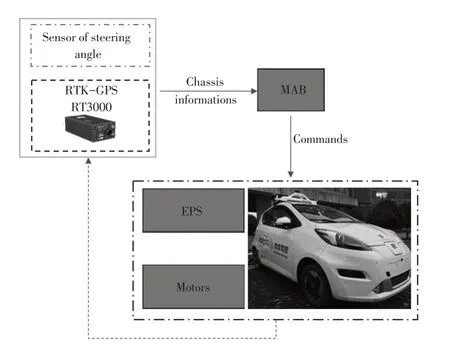
Figure 9.Experimental platform

Table 1.Configuration of vehicle
In the experiments,parking slot was assumed being already detected by AVM or LiDARs and the detection algorithm is beyond the scope of this paper.Location of vehicle during parking was acquired from RTK-GPS,of which the max error is within 2 cm.
6.2 Results
The experiments consisted of 2 groups:First,the initial positions were set as shown in Figure 1(20 tests),in order to verify the adaptability of the algorithm to real vehicle dynamics;Second,the initial orientation was changed from 0°to-4°and 4°,in order to test the generalization ability to unseen initial parking poses.
The results shown in Figure 10 and Table 2 suggested that the proposed method can finish automatic parking with high accuracy and high efficiency from 20 initial poses.After finishing parking,the max value of Δyis within 5 cm and the max value of Δθis 0.23°.Maximum parking time spent is 29.5 s and the minimum parking time is 18.88 s.It is highly more efficient than the result shown in[20].
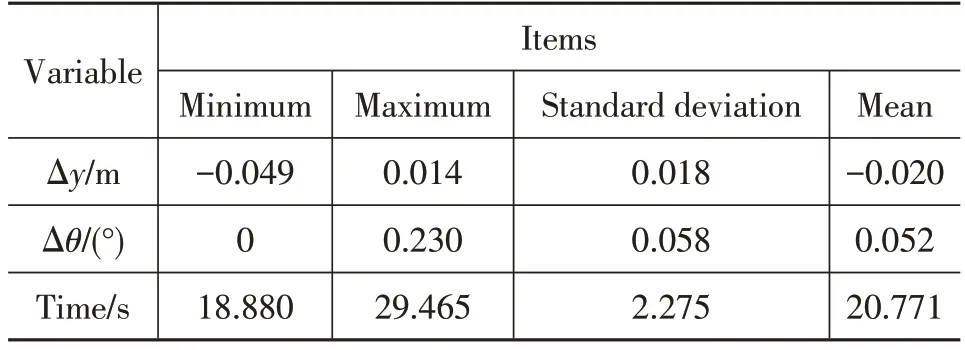
Table 2.Test results for the 20 parking trials
The results shown in Figure 11 and Figure 12 suggested that the proposed method has the generalzation ability to park from unseen initial parking poses.The final parking pose is within small error to targety=-0.9 m and targetθ=0°.

Figure 10.Parallel parking paths for 20 initial poses
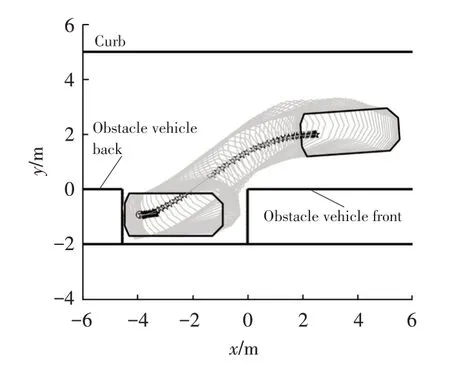
Figure 11.Path of parallel parking paths from(2.5 m,2 m,4°),end pose is(-3.93 m,-0.93 m,-0.01°)
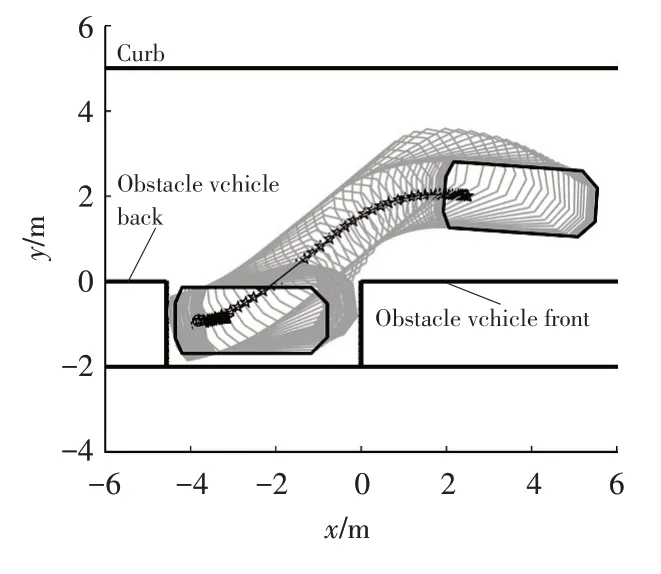
Figure 12.Path of parallel parking paths from(2.5 m,2 m,-4°),end pose is(-3.81 m,-0.93 m,0°)
7 Conclusions
In this paper,a unified motion planning method based on an efficient workflow combining imitation learning and reinforcement learning for automatic parallel parking system in narrow slot is proposed.Imitation learning speeds up the process of reinforcement learning greatly and reinforcement learning refines the policy from imitation learning.The number of training iteration can be reduced to 10 within only 1 h.The trained PNN and MCTS are packed into a planner to perform motion planning for parallel parking.Because the PNN can output the probability of incremental value of steering angle and velocity under each state,the planner can plan the whole parking trajectory including adjusting stage in parking slot uniformly,during which gear shift is needed.For deployment on real vehicle,a simple non-time referencebased SMC is used to track trajectory.
The above experimental results revealed that the proposed method is feasible for tiny parking slots and can finish parallel parking with high accuracy and efficiency.However,future research can still make some improvement:
a.Parking slot detection algorithm should be integrated together in the future and the uncertainty of detection should be considered.
b.It is assumed that there are no dynamic obstacles in the scenario.In reality dynamic obstacles may occur during parking.So cope with obstacles is a direction in the future work.
c.The selected network architecture only considers the mapping from network inputs to target outputs,while sequence property of network inputs is not included.
