相机源识别算法鲁棒性研究
2021-09-28张凯,张珣
张 凯,张 珣
(杭州电子科技大学电子信息学院,浙江杭州 310018)
0 引言
通过数码相机、手机、打印机等设备可获取数字图像,且随着Photoshop 等图像处理软件的优化与普及,人们可以轻松改动原图,制作出任何想要的新图像[1]。在知识产权、法庭取证和学术研究等领域,随意篡改图像可能会引发一系列恶劣的社会问题。因此,鉴别图像内容的真实性尤为重要,在这一背景下,数字图像取证技术应运而生。
数字图像取证技术是通过各种手段分析数字图像统计信息,包括真实性、完整性、原创性息,进而判断图像是否经过篡改或伪造的一种技术[2-4],可分为主动取证[5-6]和被动取证[7]两种。主动取证包括数字水印和数字签名,被动取证包括图像源辨识[8]、图像篡改检测[9]、图像真实性鉴定。主动取证技术是在图像中预先加入水印或签名信息,若图像经过篡改,预先嵌入的信息就会被破坏。被动取证技术只需要检测数字图像的内在统计特性,应用范围广泛。
图像源辨识是数字图像被动取证的重要研究方向,其可根据待测图像确定成像设备来源。在数字成像过程中,光信号在经过镜头、成像传感器时会引入噪声,在后期数字信号处理阶段也会引入一系列噪声,可根据这些噪声性质判断设备来源。针对相机源识别,相关学者已经进行了大量研究。Roy 等[10]采用离散余弦变换方法提取特征,基于随机森林的AdaBoost 集成分类器进行相机源识别;Jaro⁃slaw 等[11]基于镜头渐晕现象会使图像边缘光强较弱的依据,提出采用照片边缘光强值进行相机识别的方法;Li等[12]提出利用镜头畸变现象计算图像畸变系数以识别相机,但该方法受环境影响较大,失真参数会随着物体距离、焦距和视角的变化而变化。
近年来,深度学习在图像识别领域广泛应用[13-14]。深度学习能自动学习图像特征,其提取的特征比人工设计的特征有更强的表达能力和稳定性,因此深度学习可获得更为本质的图像深层特征。深度学习领域具有代表性的卷积神经网络(Convolutional Neural Network,CNN)通过卷积核提取图像特征,而卷积核的本质是特征提取的滤波器,可根据提取特征性质选择不同卷积核。本文以相机噪声频率域特征为研究对象,结合CNN 进行特征提取与分类,通过对图像进行加噪、裁剪成不同图像块处理,对该算法的可靠性和鲁棒性进行研究。
1 源相机识别噪声分析
1.1 数码相机成像原理
数码相机成像原理[15]如图1 所示。当数码相机拍摄照片时,自然场景的反射光信号通过镜头,通过彩色滤波阵列分解成不同颜色的光,然后通过成像传感器将光信号转换为电信号,电信号经过颜色插值、白平衡[16]、伽马矫正[17]、对比度增强、图像压缩等处理后被转化为数字图像,最终保存在存储器中。

Fig.1 Camera imaging process图1 相机成像过程
1.2 相机噪声分析
相机噪声分为很多种,如经过光电转换的数字图像会引入噪声;自然场景的光经过镜头时会因镜头灰尘、镜头畸变现象引入噪声;由于生产工艺限制,成像传感器会引入暗电流噪声和PRNU 噪声[18-19];在后期图像处理阶段会引入热噪声、散粒噪声等随机噪声。
传感器噪声在数码相机生产过程中便已产生,不同生产商的传感器噪声不同,即使是同一生产商的同一型号相机,其传感器噪声也不同,因此传感器噪声可被视为相机的“固有指纹”。光响应非均匀性(PRNU)噪声是较为普遍的传感器噪声,由于成像传感器各部分对光线敏感度不同,使得光子在传感器表面分布不均,表现在数字图像上即为像素值不同。这种噪声与传感器材料、制造工艺等物理特性相关,几乎是无法消除的。
Lukas 等[20]最早提出了基于PRNU 的图像源辨识算法,其首先对成像传感器输出建模,通过最大似然估计法从多张参考图像中估计PRNU 特征,之后又通过平均多幅参考图像的噪声残差,得到该相机的参考模式噪声,具体公式如下。
由原图减去滤波器处理后的图像得到噪声残差:

噪声残差求平均值得到PRNU 信号:
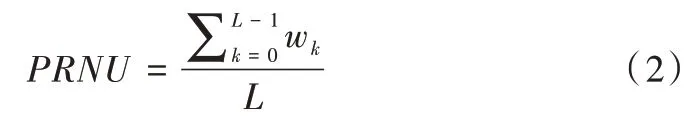
式中,Wk为图像k的噪声残差,Ik为原始图像k,F(Ik)为对图像k做滤波处理。
使用噪声残留测试图像(n)与相机参考PRNU 图像(P)之间的归一化相关系数确定特定图像是否由相机(C)拍摄。该归一化相关统计检验可用于确定源相机识别中基于滤波的PRNU 噪声残差与相机参考PRNU 图像之间的相关度,计算公式为:
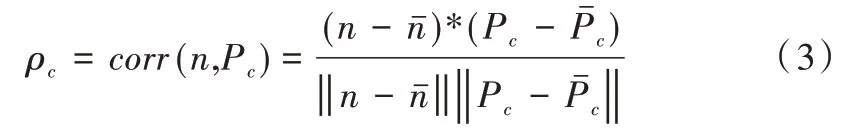
1.3 噪声信号性质
PRNU 噪声中通常还有一种非唯一伪像噪声(NUA),主要由传感器、彩色滤波阵列和镜头等器件引起。由于图像信号的内容信息主要分布在低频区域,噪声信息分布在高频区域,因此可以使用以下高通滤波器提取图片高频分量。

提取出的噪声信号包含PRNU 噪声和NUA 噪声,对PRNU 噪声图像作自相关处理,能够体现信号周期性。
以Huawei-P9 为例,图2 展示了其噪声图、自相关图像与傅里叶幅值图像。噪声图像的自相关图像有周期性网格特征,在经过傅里叶变换后具有周期性亮点,高亮度表示该频率的特征更加明显。

Fig.2 Processing image of noise signal图2 噪声信号处理图像
2 CNN 概述
2.1 CNN 基本结构
CNN 结构模型[21-22]如图3 所示,包含输入层、卷积层、池化层、全连接层和Softmax 回归分类层。卷积层和池化层可用于提取图像特征,以下主要介绍卷积层、池化层和Softmax 回归分类层。

Fig.3 Basic structure of convolutional neural network图3 CNN 基本结构
2.2 卷积层
卷积层又称为特征提取层,用于学习输入数据的局部特征,通常使用多层卷积得到更深层次的特征图。卷积运算可提取图像边缘、线条等特性,但不会改变图像大小。
2.3 池化层
池化层又称为特征映射层,通常位于卷积层后,为对输入图像进行下采样得到的层。池化层的主要作用为降维数据、去除冗余信息、压缩特征、简化网络复杂度、减少计算量、减小内存消耗,同时实现平移不变性、旋转不变性和尺度不变性。
池化方法包括一般池化、重叠池化和空金字塔池化。一般池化通常包括平均池化和最大池化,其中平均池化是计算图像区域的平均值作为该区域池化后的值,最大池化是选择图像区域的最大值作为该区域池化后的值。重叠池化即相邻池化窗口间有重叠区域。空间金字塔池化是将一个池化变成多个尺度的池化,用不同大小池化窗口作用于上层卷积特征。
2.4 Softmax 分类层
CNN 分类层如图4 所示。全连接层将权重矩阵与输入向量相乘再加上偏置,将n 个(-∞,+∞)的实数映射为K 个(-∞,+∞)的实数。Softmax 将K 个(-∞,+∞)的实数映射为K 个(0,1)的概率,同时保证它们之和为1。具体可表示为:
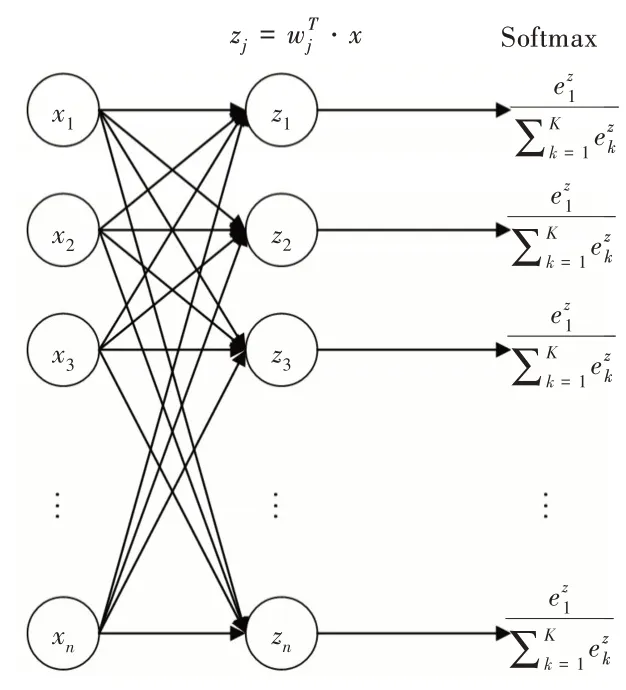
Fig.4 Softmax classification layer图4 Softmax 分类层
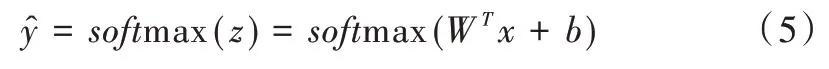
式中,x 为全连接层的输入,Wn×K为权重,b 为偏置项,为Softmax 输出的概率。Softmax 计算方式为:
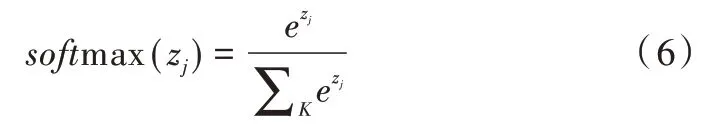
拆成每个类别的概率如下:
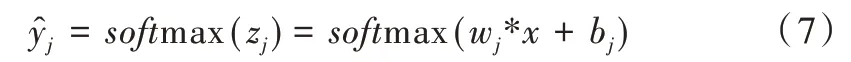
式中,wj为图4 中的权重系数,最终分类结果取其最大值。
3 实验设计
3.1 实验环境
深度学习需要大量数据运算,对硬件有一定要求,本实验使用的计算机软硬件配置如表1 所示。系统为Win⁃dows10,实现训练的代码均在PyTorch 框架下使用Python 语言编程。

Table 1 Experimental equipment表1 实验设备
3.2 数据集分析
使用Dresden 数据集,其是基于相机数字取证技术开发与基准测试而构建的数据集。在环境可控的条件下,使用25 种不同型号的73 台相机共拍摄了14 000 张室内和室外场景图像,有助于严格分析制造商、模型、设备相关特性及其与其他影响因素的关系。以下实验共使用5 种型号的相机进行实验。
3.3 实验流程
实验设计方案如图5 所示,主要包括图像预处理、提取噪声信号、CNN 实现图像分类3 个部分。

Fig.5 Experimental flow图5 实验流程
在图像预处理过程中,在原始图像中加上高斯噪声、椒盐噪声进行模糊处理,并与不加噪声的图像进行比较,验证噪声对算法鲁棒性的影响。将原始图像裁剪成不同图像块,以破坏其周期性信息,验证尺寸对算法鲁棒性的影响。
3.4 网络模型
PyTorch 框架中torchvision 模块下有torchvision.datas⁃ets、torchvision.models、torchvision.transforms 3 个子包。torchvision.models 中包含常用的Alexnet、Densenet、Incep⁃tion、Resnet、Squeezenet、VGG 等网络结构,并且提供了预训练模型,本实验使用该模块下的VGG16 网络结构模型。
3.5 实验衡量标准
实验衡量标准与以下4 个指标相关:①True Positive(真正,TP):将正类预测为正类数;②True Negative(真负,TN):将负类预测为负类数;③False Positive(假正,FP):将负类预测为正类数误报;④False Negative(假负,FN):将正类预测为负类数。
仅用精确度或召回率无法全面评估模型优劣,因此可将精确度与召回率结合起来,得到F1 评分作为模型评价准则。在多分类问题中,F1 为精确度与召回率的调和平均,表示为:
另一个流行的度量标准为马修斯相关系数(MCC),即决策图与基本事实之间的互相关系数,其计算方式对不平衡类具有鲁棒性,公式如下:
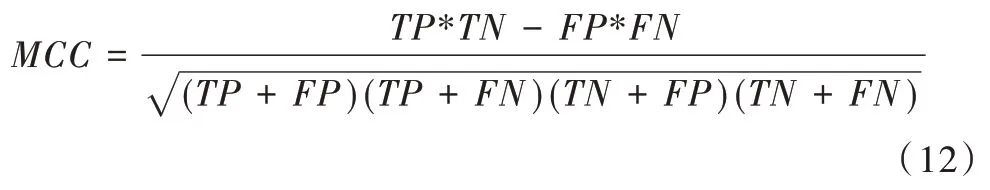
4 实验结果分析
4.1 实验一
选取5 类相机的原始图像,分别裁剪成56×56、128×128、256×256 大小的图像块进行实验,分析不同尺寸图像块对NUA 信号周期性的影响。
如表2 所示,基于噪声频域的处理算法有较好的分类准确率,可达95%以上,并且同一型号相机不同尺寸图像的分类准确率相差较小。FinePixJ50 型相机受尺寸影响最小,在128×128 尺寸下分类准确率最高,为98.9%,在56×56尺寸下分类准确率最低,为97.6%,相差1.3%。DSC-H50型相机受尺寸影响最大,在128×128 尺寸下分类准确率最高,为98.7%,在56×56 尺寸下分类准确率最低,为95.9%,相差2.8%。由此可见,图像尺寸大小对算法影响并不大,最多相差2.8%。
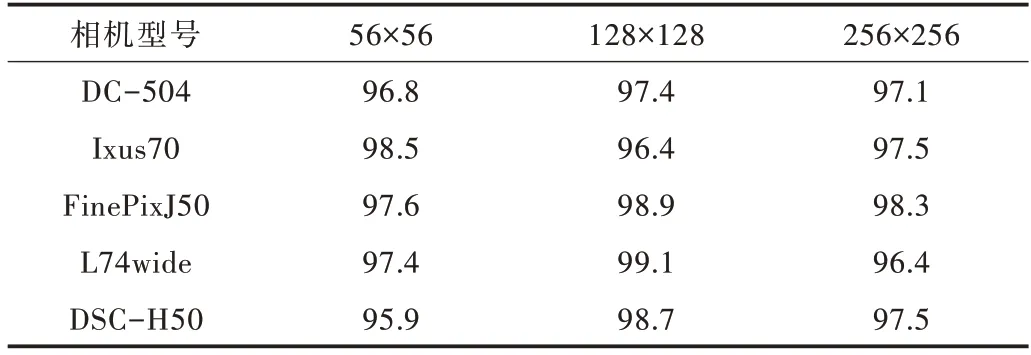
Table 2 Classification accuracy of image blocks in different sizes表2 不同尺寸图像块分类准确率 (%)
表3 为256×256 尺寸下的图像分类混淆矩阵,表4 为256×256 尺寸下的图像分类报告。

Table 3 Confusion matrix of 256×256 size表3 256×256 尺寸下的混淆矩阵 (%)
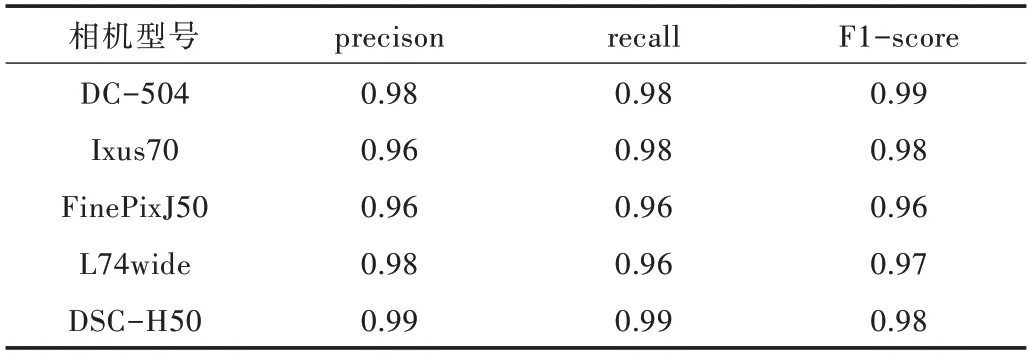
Table 4 Classification report of 256×256 size表4 256×256 尺寸下的分类报告
4.2 实验二
图像块尺寸统一采用256×256,分别在不加噪声、加上高斯噪声、加上椒盐噪声3 种情况下进行实验,分析噪声对算法的影响,其中初始高斯噪声均值为0,方差为0.01,椒盐噪声密度为0.05。由表5 可知,在给图像加上高斯或椒盐噪声后,相机识别准确率会有一定下降,但均在90%以上。
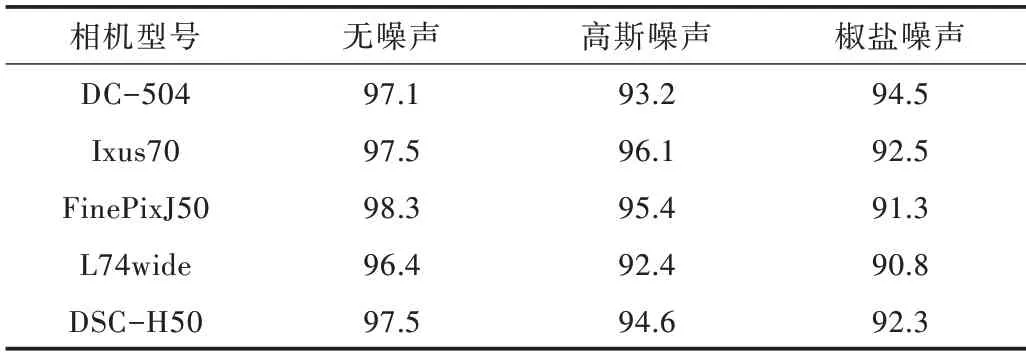
Table 5 Classification accuracy after noise processing表5 加噪处理下的分类准确率 (%)
为进一步研究噪声对识别准确率的影响,以下实验分别增加高斯噪声和椒盐噪声的密度。由图6 可知,随着噪声密度不断增大,图像内容信息以及“指纹信息”会被噪声信号掩盖,准确率降低。但在噪声密度达到一定值后,识别准确率受噪声影响的敏感度降低,由此可见本文算法具有一定抗噪声干扰能力,鲁棒性较好。
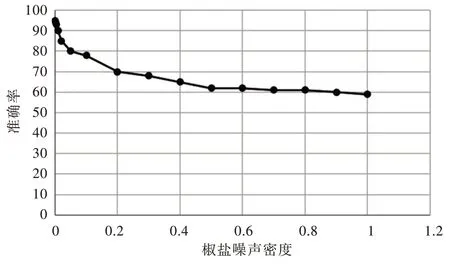
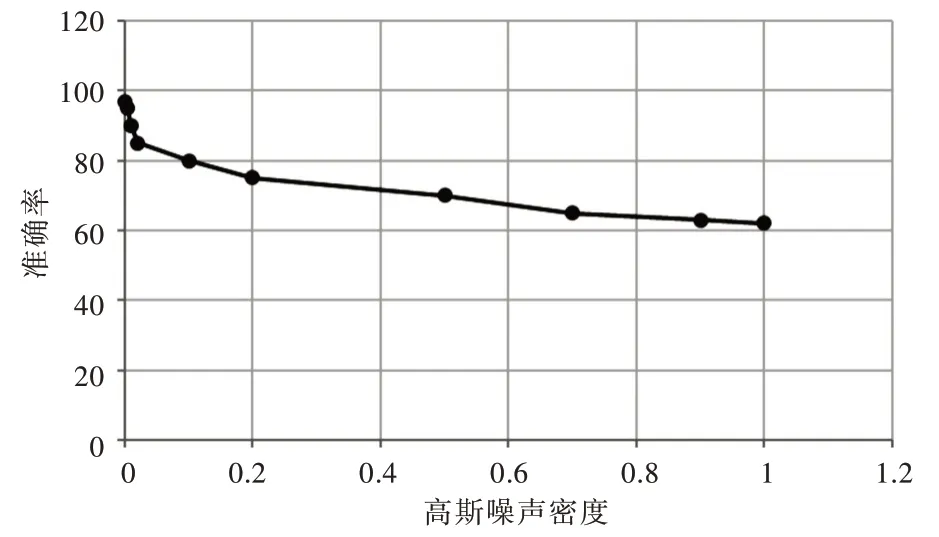
Fig.6 Classification accuracy under different noise densities图6 不同噪声密度下的分类准确率
5 结语
本文针对相机源识别算法的鲁棒性进行了研究,以相机噪声频域信号为研究对象,通过对图像进行切割、加噪处理,证明了该算法的鲁棒性。后续工作可以考虑使用不同神经网络或分类器进行实验,探究分类器对算法的影响。同时可通过切割图像块的方式对图像进行篡改检测,即检测篡改区域位于哪个图像块,并精确定位到原图中。
