改进LDA 模型的短文本聚类方法
2021-09-28俞卫国
孙 红,俞卫国
(1.上海理工大学光电信息与计算机工程学院;2.上海现代光学系统重点实验室,上海 200093)
0 引言
聚类是一种无监督的机器学习方法,文本聚类是依靠文档特征将文本聚集为文档簇。随着互联网及信息技术的飞速发展,社区平台Twitter、新浪微博等普及,短文本呈爆炸式增长,对短文本聚类预处理具有重要价值。不同于传统媒体平台的文本信息,短文本具有以下特点:更新快速,存在大量不规范用语,吸收新词汇多,数据具有稀疏性,这给短文本聚类增加了难度。
常用的文本聚类算法通过计算文本的相似度信息,如VSM(Vector Space Model)模型,通过计算空间向量之间的余弦值来衡量文本的相似度。目前文本聚类主要应用有文本分类、文本可视化、搜索引擎聚类、信息推荐等。
20 世纪中后期,Gerard 等[1]提出VSM 空间向量模型并成功应用,但这种模型在计算空间相似度时计算量比较大,而且没有考虑词与词之间的内部联系。主题模型(Top⁃ic Model)考虑了词语与主题之间的内部联系,刘金亮[2]提出了一种改进的LDA(Latent Dirichletalloc Allocation)主题模型,使得LDA 模型的主题分布向高频词倾斜,导致能够代表主题的多数词被少量的高频词淹没,使主题表达能力降低;汪进祥[3]提出一种基于主题模型的微博话题挖掘,结合词性标注进行话题提取;张志飞等[4]基于潜在狄利克雷分配的新方法,提出基于LDA 主题模型的短文本分类方法,生成的主题不仅可以区分常用词的上下文并降低其权重,还可以通过连接区分词并增加其权重来减少稀疏性;张芸[5]结合在短文本建模方面具有优势的BTM 主题模型对短文本进行特征扩展,将扩展后的特征矩阵进行相似度计算。
本文首先介绍了VSM(Vector Space Model)模型聚类、LTM(Lifelong Topic Modeling)模型聚类、LSA[6](Latent Se⁃mantic Analysis)模型聚类、PLSA[7](Probabilisticlatent Se⁃mantic Analysis)模型聚类,然后引出经典模型LDA(Latent Dirichlet Allocation),介绍了LDA 模型的优劣,最后针对经典的LDA 模型没有考虑到文本与主题之间的联系问题,提出一种具有判别学习能力的LDA-λ模型。将二项分布引入到LDA-λ基础模型中,增加词项的判别能力。最后经过对比聚类算法实验,证明基于判别学习能力的LDA-λ模型聚类性能比VSM 和LDA 模型显著提高。
1 基本模型与方法
1.1 VSM
VSM 是一种空间向量模型,出现在20 世纪中后期,由Gerard 等[8]提出,并成功应用于著名的SMART 文本检索系统。VSM 模型简单,易于理解。它的核心思想是把需要处理的文本内容转化到空间向量中,并以向量运算的方式计算语义的相似度。当文本表示为空间向量时,文本的相似性就可以通过计算文本空间向量的度量值表示。通常将余弦距离作为度量值来比较相似性。
假如一篇文本D1 中有a、b、c、d、e 五个特征项,权值分别为30、20、20、10、10,文本D2 中有a、c、d、e、f 五个特征向量,权值分别为30、30、20、10、10,则对应文档D(D1,D2)的总体特征为(a,b,c,d,e,f),D1 的向量表示为D1(30,20,20,10,10),D2 的向量表示为D2(30,30,20,10,10),根据夹角余弦公式:
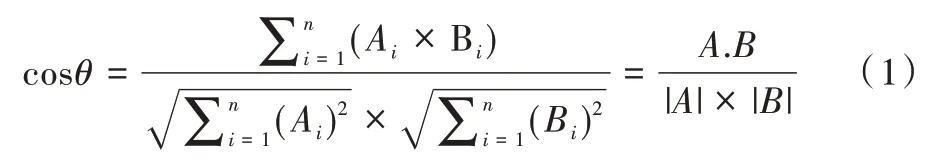
计算文本D1 与D2 的相似度是0.92。
从上述描述与计算可知VSM 模型用于聚类时的缺点:①在计算相似度时,相似度计算量较大,每次有新的文档加入时必须重新计算词的权值;②没有考虑到词与词之间的联系,语义相同但是使用不同词语的特征词没有关联起来。
1.2 LTM 模型
主题模型[9](Topic Model)是用在大量文档中发现一种潜在主题的统计模型。与上述VSM 模型相反,主题模型考虑被处理文档的语义信息以及与各个主题之间联系,并将文本到词项的分布转化为文档与主题之间的分布,有效降低了特征维度,利于短文本处理,但在提高性能的同时牺牲了时间。在主题模型中,假如一篇文章有一个中心思想,那么关于中心思想的词语就会频繁出现。在现实中一个文档通常包含多个主题,并且每个主题所占的比例各不相同,那么这些主题相关关键字出现的频率就与这些主题所占比例有关。
主题模型的特点是能够自动分析文档,统计文档中的单词时不需要考虑他们出现的顺序,根据统计出的信息判断文档中的主题以及各个主题所占的比例。
传统主题模型基本都是一种完全无监督模型,会产生许多不符合逻辑的Topic,针对该问题学者提出了许多关于先验知识的主题模型。本文的LTM 主题模型不需要任何用户输入就能从大量主题中自动地和动态地挖掘先验知识,这就是Lifelong 思想。
Lifelong 思想假设:问题:如何找到先验知识并利用它完成新的主题建模任务?
数据:情绪分析背景下的产品评论。
算法如下:
(1)先验topic 的生成,或者称为proir-topic。给定来自n 个领域的一个文档集合D={D1,…,Dn},使用Algorithm 1 PriorTopicsGenenration(D)对每个领域的文档Di(Di∈D)运行算法,生成所有topic 的集合S,称这个S 为proir-topic 集合。这些proir-topic 后续会用在LTM 模型上作为先验知识。S 中的proir-topic 可以通过迭代来改善。上一轮迭代中的S 可以通过下一轮的LTM 过程从D 中生成更好的top⁃ic。LTM 从第二轮开始使用。
(2)测试文档topic 的生成,或者称为test-topic。给定一个测试文档集合D(t)和第(1)步生成的proir-topics 集合S,利用Algorithm2(LTM)生成topics。区别第(1)步的topic称为test-topics。注意测试文档D(t)可以来自于D 或者新领域的一个文档集合。LTM 算法伪代码如下:


以上过程很自然地用上了Lifelong learning 思想。S 是系统生成的一个知识库(proir-topic),而LTM 是学习算法。给定一个新的学习任务G(如主题建模)和它的数据(如Da⁃ta),lifelong learning 可以分为两个阶段:①Learning with pri⁃or knowledge。这对第(2)步至关重要,它需要解决两个子问题(第(1)步是初始化)。②知识的保留和合并。如果G是一个新任务就简单地把G 的topic 加进S 中。如果G 是一个旧任务就在S 中替换其topics。
LTM 模型主要包括潜在语义分析LSA(Latent Semantic Analysis)、概率潜在语义分析PLSA(Probability Latent Se⁃mantic Analysis)和潜在迪里克雷分布LDA(Latent Dirichlet Allocation),3 个模型分别描述如下。
1.2.1 LSA
在某些情况下,LSA 又称作潜在语义索引(LSI),是一种非常有效的文本建模方法。正如其名称,该方法意在分析文本语料所包含的潜在语义,然后将单词和文档映射到该语义空间。LSA 以矩阵奇异值分解(SVD)为基础,在了解LSA 之前,需要先对奇异值分解[10]进行简单介绍。
一个矩阵代表一个线性变换(旋转,拉伸),可将一个线性变换过程分解多个子过程,矩阵奇异值分解就是将矩阵分解成若干个秩与矩阵的和。
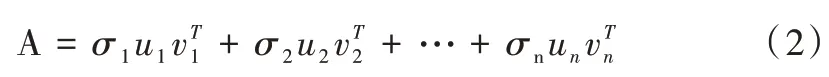
其中,σi是奇异值,是秩为的矩阵,表示一个线性变换子过程。奇异值σi反映了该子过程在该线性变换A 中的重要程度。对式(2)进行整理,将奇异值分解过程表示如下:

其中,U 是左奇异向量构成的矩阵,两两相互正交,S 是奇异值构成的对角矩阵,VT是右奇异向量构成的矩阵,两两相互正交。
奇异值分解具有如下数学性质:①一个m*n 的矩阵至多有p=min(m,n)个不同的奇异值;②矩阵的信息往往集中在较大的几个奇异值中。
LSA 正是利用了奇异值分解的这两个性质将原始的单词—文档矩阵映射到语义空间。在LSA 中不再将矩阵理解成变换,而是看作文本数据的集合。文本语料中所有单词构成矩阵的行,每一列表示一篇文档(词袋模型表示)。假设A 是一个m*n 的文本数据矩阵(n< 依据奇异值分解性质①,矩阵A 可以分解出n 个特征值,然后依据性质②选取其中较大的r 个并排序,这样USVT就可以近似表示为矩阵AA。对于矩阵U,每一列代表一个潜语义,这个潜语义的意义由m 个单词按不同权重组合而成。因为U 中每一列相互独立,所以r 个潜语义构成了一个语义空间。SS 中每一个奇异值表示该潜语义的重要度。VT中每一列仍然是一篇文档,但此时文档被映射了语义空间。VT的大小远小于A。有了VT就相当于有了矩阵A 的另外一种表示,之后就可使用VT代替A 进行之后的工作。 Fig.1 Singular value decomposition图1 奇异值分解 LSA 通过SVD 和低秩逼近,把原始向量空间映射到潜在语义空间,在潜在语义空间计算文档相似性能够解决部分一义多词的问题,从该层面可知LSA 优点很明显。但是低秩逼近后的矩阵中元素缺乏直观解释,甚至矩阵中会出现很多元素为负数的情况,特征向量的方向没有对应的物理解释,k 的选取会对结果产生很大影响,且k 不是计算出来的而是一个经验值,所以很难选出合理的k 值,无法对应现实中的概念。 1.2.2 PLSA 尽管上述的LSA 模型取得了一定的成功,但是由于缺乏严谨的数学统计基础,而且SVD 分解非常耗时,因此Hofmann 在SIGIR1999 上提出了基于概率统计的PLSA 模型,并且采用EM 算法学习模型参数。PLSA 模型是最接近LDA 的模型,所以理解PLSA 模型有助于理解LDA。PLSA模型如图2 所示。 Fig.2 PLSA model图2 PLSA 模型 PLSA 模型数学符号如表1 所示。 Table 1 Mathematical symbols of PLSA model表1 PLSA 模型数学符号 先从文档集合中选择一篇文档di,选定后从主题分布中按照概率P(zk|di)选择一个隐含的主题类别zk;选定主题zk后从词分布中按照概率P(wj|zk)选择一个词wj。 根据大量已知的文档—词项信息P(wj|di)训练出文档—主题P(zk|di)和主题—词项P(wj|zk),见式(5): 得到文档中每个词的生成概率为: 上述是完整的生成过程。事实上由于P(di)可事先计算求出,而P(wj|zk)、P(zk|di)未知,所以θ=(P(wj|zk),P(zk|di))就是要估计的参数值。一般要最大化这个θ,由参考文献[6]求解出这两个参数。 1.2.3 LDA 模型聚类 LDA 模型是一种文档—主题生成模型,在2003 年由Blei 等[11]提出。LDA 模型是PLSA 模型的扩展,它能够在一系列文档中分析出文档的主题概率分布,归属于统计模型。事实上,理解了PLSA 模型也就理解了LDA 模型,因为LDA就是在PLSA 的基础上加上贝叶斯框架,即LDA 就是PLSA的贝叶斯版本(正因为LDA 被贝叶斯化了,所以才需要考虑历史先验知识加上两个先验参数),LDA 模型如图3所示。 Fig.3 LDA model图3 LDA 模型 在LDA 模型中,一篇文档生成方式如下:①从迪利克雷分布α中取样生成文档i的主题分布θi;②从主题的多项式分布θi中取样生成文档i第j个词的主题zij;③从迪利克雷分布β中取样生成主题zij对应的词语分布φzij;④从词语的多项分布φzij中采样最终生成词语Wij。 和PLSA 模型一样,文档到主题服从多项式分布,主题到词服从多项式分布,是一种完全的概率生成模型。生成文档中每个词出现的概率为: 联合概率分布公式为: 词wi在主题z 上的分布如下: 文档d 在主题z 上的分布如下: 经过一系列的训练推导过程求出吉布斯采样公式如下: 基础LDA 模型未考虑词项的区分程度,如果一个词项在大部分主题下都以高频出现,那么这个词项不能作为特征词来代表主题。文本具有稀疏性,直接去除对主题没有区分度的词项会对模型产生一定的影响,为此提出新的模型[14],将二项分布引入到LDA 基础模型之中,增加词项的判别能力,并将其并行化。 对单词进行采样,将同一个单词隶属于不同话题看作是相互独立的,用γ表示词项的判别能力。如果话题z 含有词项w,那么γw,z=1;如果不含有w,则γw,z=0。可以看出,γ是一个服从二项分布的参数: 其中,λw代表单词w在所有话题上的分布。本文假设λw~Beta(a,b),因为α与β参数已被使用,所以本文中用a、b参数表示贝塔分布中的参数: 其中,Υ={Υw,1,Υw,2,…,Υw,K}。 可以推断如下:如果某词项w 在各个话题中均匀出现时,λw值较大时对话题的区分程度不大;相反,如果某词项w仅集中在某一个或少部分话题中出现,则此词项的λw值较小。因此,采用来表示词项判别力,将更大的权重分派给判别力大的词项以减小判别力小的词对聚类的影响。使用ω∈[0,1]对ω进行正则化表示如下: 在引入λw后,改进LDA 的概率模型如图4 所示。 Fig.4 Improved LDA probability model图4 改进后的LDA 概率模型 改进LDA 模型采样过程如下: 对话题分布进行采样: 选择文档话题:zd~Multi(θd); 吉布斯采样可以通过迭代对高维概率模型进行求解,每次迭代仅仅采样当前维度的值,将其他维度的值固定。算法一直迭代直到收敛为止,最终输出需要估计的参数。在LDA 算法中即输出φ与θ。 经过一系列推导变换,可以得到新模型的吉布斯采样更新后的公式: 初始时刻,为文档的每个词项进行主题zi的随机分配。然后统计zi下的词项w 的个数,以及文档i下含有主题zi中词项的个数。每一轮都根据公式估计每个词对于每个主题分配到的概率,然后用此概率分布进行新主题采样;同时对每个词均采用同样的方法进行词的主题更新。如果各个主题中词项的分布以及训练文档在各个主题下的分布更新收敛,就将模型中的参数输出。 经过吉布斯采样过程后求得θ参数与φ参数的表达式: 选用网上现有的API 就可以方便地进行数据分页爬取,本文选用Jsoup 进行数据爬取,获取的数据源是东方财富网。考虑到短文本限制,在数据选取上只爬取标题,选取对应的标签,爬取约8 000 条数据。 爬取到的大量数据质量差别很大,有些短文本仅仅包含两三个无用且没有实际意义的词汇,这样的低质量数据对模型干扰很大,在数据预处理时应将其去掉,在去除了大量低质量数据后再选择合适的算法。 在进行特征选择之前要对训练集中的每篇文档进行分词,采用的分词工具是IKAnalyzer。IKAnalyzer 是一个开源的基于Java 语言开发的轻量级中文分词工具包。分词结果如图5 所示。 Fig.5 Word segmentation results图5 分词结果 现有的特征抽取[16]方法很多,包括信息增益IG、局部文档频率和全局文档频率,对于文本分类选用局部DF 或者IG 都能达到良好的效果。 首先根据IG 或者局部DF 完成普通的特征选取,然后经过训练得到基于LDA 的隐主题模型,对隐主题对应的高比重单词进行特征加强,即对于原来特征选择中没有出现的单词加入到LDA 主题模型中,完成LDA 拓展文本特征选取。 为了完成LDA 拓展的特征选取,先训练LDA 得到隐藏的主题。找到每个主题下对应的关键词项。LDA 模块使用GitHub 上成熟的LdaGibbsSampler 的API 模块。为了得到短文本的LDA 主题模型,需要将这上千条数据划分为上千个单独的短文本文档。 本实验采用精确度(ACC)、归一化互信息(NMI)和成对F 测度值(PWF)[17]作为评价指标。精确度主要用来评价实验中类标签和真实标签相比预测正确的概率。归一化互信息是评价聚类效果常用的指标,用来表示预测的实验结果与真实结果的相近程度。F 测度是评价分类器好坏的重要指标,是准确度(precision)和召回率(recall)的调和平均值。F 测度计算公式如式(19)所示。 在本文实验中,所有数据集上都设置α=50/K,β=0.01,a=10,b=30。本文分别对比LDA 和改进的LDA 以及VSM模型,实验结果如表2 所示。 Table 2 Clustering results表2 聚类结果 从实验结果可以看出,LDA 在聚类效果上比SVM 效果好,具有判别学习能力的LDA 聚类效果比基础LDA 模型有很大改善。 LDA 模型是一种基于概率分布的主题模型,本文对此模型进行改进,将不同词项对于不同的话题区分程度融合进去。实验表明,在聚类性能方面具有判别学习能力的LDA 比基础的LDA 和VSM 模型都有提高。 上述模型都属于机器学习模型,目前流行的深度学习在处理文本方面也有许多需要提高的地方。深度学习[18]最初之所以在图像和语音领域取得巨大成功,一个很重要的原因是图像和语音的原始数据都是连续和稠密的,都有局部相关性。应用深度学习解决大规模文本分类问题最重要的是解决文本表示[19],再利用CNN/RNN[20]等网络结构自动获取特征表达能力,去掉繁杂的人工特征,端到端地解决问题。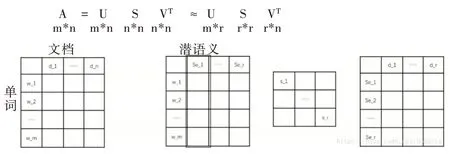



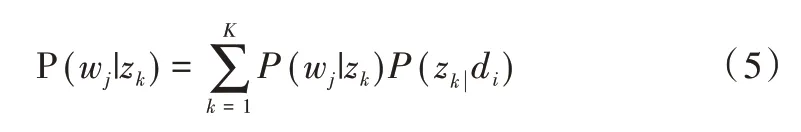



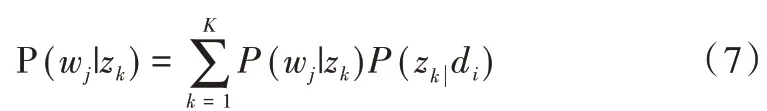
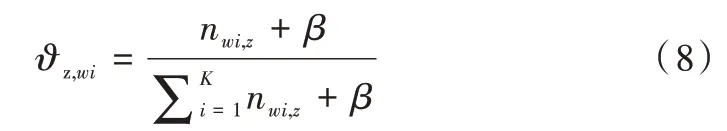

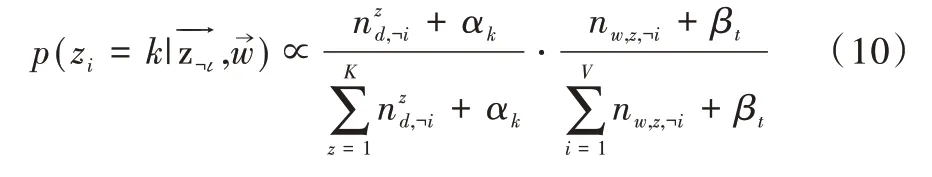
2 LDA 模型改进
2.1 模型改进过程



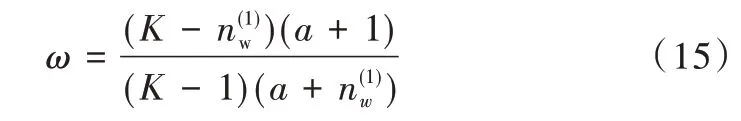

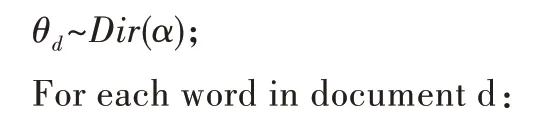
2.2 吉布斯采样求解
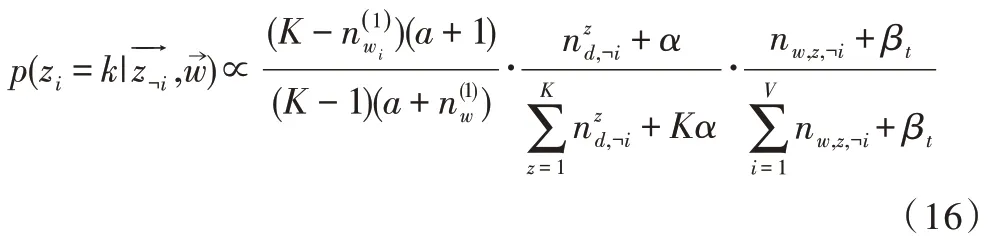
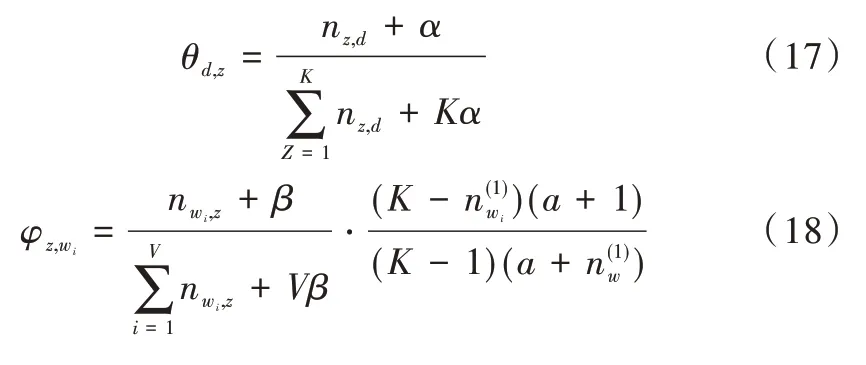
3 实验
3.1 数据爬取
3.2 数据预处理
3.3 文本分词

3.4 特征选取
3.5 LDA 隐主题抽取
3.6 评价指标


4 结语
