基于IGWO-SVR短期储藏小麦品质预测模型研究
2021-09-26蒋华伟
蒋华伟 陈 斯 杨 震
(粮食信息处理与控制教育部重点试验室;河南工业大学信息科学与工程学院,郑州 450001)
为实现“藏粮于技”的国家战略目标,研究科学有效的储藏小麦品质预测方法具有重大意义。目前储藏小麦品质判别方法主要有外观色泽、食用口感、挥发性物质检测和光谱检测等。如王志军等[1]通过形态学特征和色泽参数将小麦划分为优、次、劣三类;张玉荣等[2]等研究发现馒头的食用口感会因小麦籽粒结构的破坏而发黏变差;严松等[3]采用气相色谱-质谱联用技术对小麦的挥发性气体进行检测,从而实现对不同霉变程度小麦的区分;葛宏义等[4]采用太赫兹光谱技术,对霉变、虫蛀、发芽和正常小麦进行识别。虽然这些方法可以作为判别储藏小麦品质状况的手段,但外观色泽和食用口感判别缺乏数据支撑,说服力不足;挥发性物质检测和光谱检验技术实验过程繁琐,且所需试剂或仪器较为昂贵,难以大面积普及与使用。
为探寻更为科学有效、简便精确的储藏小麦品质预测方法,近年来一些学者对小麦的生理生化指标做了大量研究,发现储藏小麦品质会随着储藏时间的增长产生变化并通过自身一些生理生化指标的变化表现出来:如Ma等[5]研究表明过氧化氢酶活性随储藏时间的增长逐渐下降;张帅兵等[6]研究发现ATP、发芽率等指标值与储藏时间密切相关。然而,小麦的一些生理生化指标测试复杂、耗费时间长、人工成本高,给检测带来了很大困难。研究还发现储藏中的小麦其自身各生理生化指标间具有一定的关联性[7],基于这一特性,本研究通过分析各指标之间的相关性关系,用多个易测指标联合反映出对小麦品质有显著影响的某一指标值,进而通过这一品质显著影响指标来判断储藏小麦的当前品质情况。线性回归[8]等传统预测方法难以实现这一研究目标,但随着机器学习领域中一些统计学方法的发展和成熟,为该方法研究与实现提供了可能。支持向量回归机是Vapnik基于结构风险最小化原理提出的一种统计学习理论[9],它不仅具有小样本学习和泛化能力强的优势,而且在一定程度上弥补了传统预测方法存在的缺陷。SVR的预测性能主要取决于模型中的核函数类型和相关参数取值[10],然而,核函数常依据经验选取,盲目性大;相关参数常通过交叉验证[11]或网格搜索[12]等方法获得,不仅费时费力,而且难以获得最优参数。为有效提高SVR在储藏小麦品质预测中的性能,本研究利用柯西核函数和改进线性核函数的性能优势构造了一种混合核函数作为SVR核函数,同时针对灰狼算法易陷入局部最优的缺陷,从收敛因子和位置更新策略上对原算法做了调整,并用改进灰狼算法对混合核函数SVR的相关参数进行优化,由此构建一种IGWO-SVM模型用于短期储藏小麦的品质预测,以实现提高储藏小麦品质预测精度的目的。
1 储藏小麦品质预测算法
1.1 构建SVR新型混合核函数
SVR通过引入核函数可以将低维空间中的输入向量映射到高维特征空间并实现线性回归。常用核函数有线性核函数、多项式核函数、径向基核函数和Sigmiod核函数[13],SVR的性能与核函数类型的选择密切相关。柯西核函数也是一种SVR核函数,它对于低维度、小样本数据有较强的处理能力,相比于常规核函数能更好的适用于小麦多指标数据的拟合训练。柯西核函数表达式如式(1)所示。
(1)
式中:xi和xj为n维的输入值;σ为柯西核函数的宽度。
尽管柯西核函数对测试点附近的小麦多指标数据有很强的影响力并能取得良好的学习效果,但当数据远离测试点时,其影响力逐渐减弱直至消失。小麦多生理生化指标数据间存在着不确定性和数据差异性,为进一步提高SVR对多指标数据的回归性能,可以考虑引入一种泛化性强的核函数与柯西核函数进行组合。研究表明线性核函数具有较强的泛化性能,而且计算简单、运算速度快,见式(2)。
K(xi,xj)=xi·xj
(2)
线性核函数适用性窄,对于小麦品质多指标数据难以实现高效映射,因此本研究基于核函数构造原则对线性核函数进行改进。由核函数性质可知:若K(xi,xj)是满足Mercer条件的核函数,则exp[K(xi,xj)]同样满足Mercer条件并可以作为SVR的核函数使用。此外,可以引入参数λ控制线性核函的幅度变化和参数r对线性核函数进行微调,以增强它的灵活性和适用性。改进后的线性核函数见式(3)。
K(xi,xj)=λ·exp(xi·xj+r)
(3)
本研究将改进后的线性核函数和柯西核函数进行组合,构造出一种新型混合核函数。由核函数封闭性可知,两个满足Mercer条件的核函数乘积同样满足Mercer条件,并可以作为SVR的核函数使用。组合得到的新型混合核函数如式(4)所示。
(4)
将混合核函数应用于支持向量回归机模型[14]中,则最优的非线性回归函数如式(5)所示。
(5)
式中:αi和αi*为Lagrange乘子;b为真实值与预测值的偏差量。
1.2 改进灰狼算法
1.2.1 收敛因子非线性控制策略
灰狼算法是一种新型群体智能优化算法,具有参数简单、自组织学习性能好的优势,在图像处理、工程建模、SVR参数优化等问题中已经得到了广泛的应用。然而,灰狼算法也存在着易于陷入局部最优解的缺陷[15]。灰狼算法寻优过程分为包围、追捕和攻击三个部分,包围过程中,算法通过收敛因子a调节系数向量A的大小,进而控制包围圈的扩散与缩小[16]。基本灰狼算法中的a随着迭代次数增加从2线性减少到0,但这种方法不仅难以有效平衡算法的全局搜索能力和局部搜索能力,而且由于实际搜索过程较为复杂,不能准确描述实际迭代搜索过程。为改善这些缺陷,本研究基于余弦函数,提供了一种新的非线性收敛因子更新公式,见式(6)。
(6)
式中:amax和amin为收敛因子a的最大值和最小值;t为当前迭代次数;T为最大迭代次数。
改进后的收敛因子在迭代前期速率减小变慢,a取得相对较大的值,能很好地提高全局搜索能力;在迭代后期收敛因子速率减小加快,a的取值相对之前较小,有效提高了局部搜索能力。
1.2.2 位置更新调整策略
狼群包围猎物之后,ω狼在α、β和δ狼的引导下对猎物进行追捕,狼群个体根据当前最优个体的位置更新其自身位置,并重新确定猎物位置[17]。然而在此过程中,原位置更新公式中的α、β、δ狼表现出同等程度重要性,无法体现α狼的领袖地位及最优解所占权重。为改善这一问题,本研究提出了一种动态比例权重和加权平均权重相结合的权重分配方法对原位置更新公式进一步调整。其中动态比例权重能清楚显示每次迭代后α、β、δ狼的重要性程度,然后经过一定加权平均,能更准确的指导狼群朝着猎物方向前行。
1)依据α、β、δ狼的适应度值并通过式(7)所示的分配策略计算出三头狼各自所占的动态比例权重,从而使α狼占据更大的权重,β狼权重相比于α狼有所减小,δ狼最小。
(7)
式中:f(Xα)、f(Xβ)和f(Xδ)分别为α、β、δ狼在当前位置适应度值,适应度值用均方误差MSE来表示;wσ、wβ和wδ分别为α、β、δ狼的动态权重。
2)分别赋予α、β、δ狼加权平均权重为5、3和2,权重总和为10。将动态比例权重与加权平均权重分配方法相结合,并对原位置更新公式进行修改,最终可以获得新的位置更新方法,如式(8)所示。
(8)
式中:X1、X2、X3是ω狼与α、β、δ狼之间的位置向量[18]。当猎物停止移动后,灰狼对猎物进行攻击,完成整个捕猎行为。
1.3 IGWO-SVR算法流程
本研究采用改进灰狼算法对混合核函数SVR的参数进行优化,以弥补传统参数选取方法的缺陷和增强SVR的回归能力。IGWO-SVR算法实现流程如图1所示。

图1 IGWO-SVR算法流程图
2 材料及数据处理
2.1 材料与测试方法
小麦的生理生化指标繁多且复杂,若全部测试并分析验证,不仅耗费时间长,而且一些试验仪器和试剂较为昂贵导致测试成本较高。因此,本研究选取了与小麦品质相关联的8个代表性的指标(脂肪酸值、降落数值、沉降值、还原糖、过氧化氢酶、电导率、丙二醛、发芽率)进行试验分析。试验所选用的小麦样本为河南省农科院培育的中筋麦周麦22,将小麦清洗干净后每500 g装入纱布并放置于人工气候培养箱,测试期间通过加湿器、空调等将环境温度控制在25 ℃左右以模拟实际储藏环境。为避免单批次数据可能出现的误差,试验将小麦样本划分为3个不同批次,并在5个不同储藏时间段(30、60、90、120、150 d)分别对各项生理生化指标进行测试。其中前两个批次的10组多指标数据作为模型的训练样本,第三个批次的5组多指标数据作为模型的测试样本。
各指标测试方法:脂肪酸值依据GB/T 15684—2015测定;降落数值依据GB/T 10361—2008测定;沉降值依据GB/T 21119—2007测定;还原糖含量依据GB/T 5009.7—2016测定;过氧化物酶依据GB/T 32102—2015测定;发芽率依据GB/T 5520—2011测定;丙二醛含量依据GB 5009181—2016测定;电导率计算公式为:电导率=(电导读数-空白读数)/小麦质量。
2.2 品质预测指标选取及相关性分析
小麦样本中各项生理生化指标数值随着时间的延续,整体上都会呈现一定的上升或下降趋势,这是由于新收获后的小麦受到呼吸作用、微生物、温湿度等因素的影响,生理生化指标所表现出的内在变化特性。相比于其他所选取的指标,脂肪酸值与小麦品质的关联性更为紧密:一方面,小麦籽粒中脂质物质会随着储藏时间的增长水解成游离的脂肪酸,然后进一步氧化生成脂、酮、醛等化合物,导致小麦品质下降;另一方面,脂肪酸值在不同品质小麦间差异较大且区分明显,最能体现小麦品质的变化情况。此外,脂肪酸值检测方法较为复杂,同时提取液使用的是苯(易燃、易爆、挥发性大、毒性大),而且受小麦本身色泽和醇溶性蛋白等因素影响,判断滴定终点时指示剂的颜色变化比较困难,这些都给脂肪酸值测试带来一定难度。综上,本研究选用脂肪酸值作为储藏小麦品质预测指标因子,其他易测指标作为影响指标因子。
储藏小麦各生理生化指标间存在一定的相关性关系。为提高训练效率,减少相关性弱的因子对试验结果的干扰,本研究采用SPSS数据分析软件对指标间相关性进行分析,从而剔除不合适的指标。脂肪酸值与其他指标间相关性分析结果如图2所示。
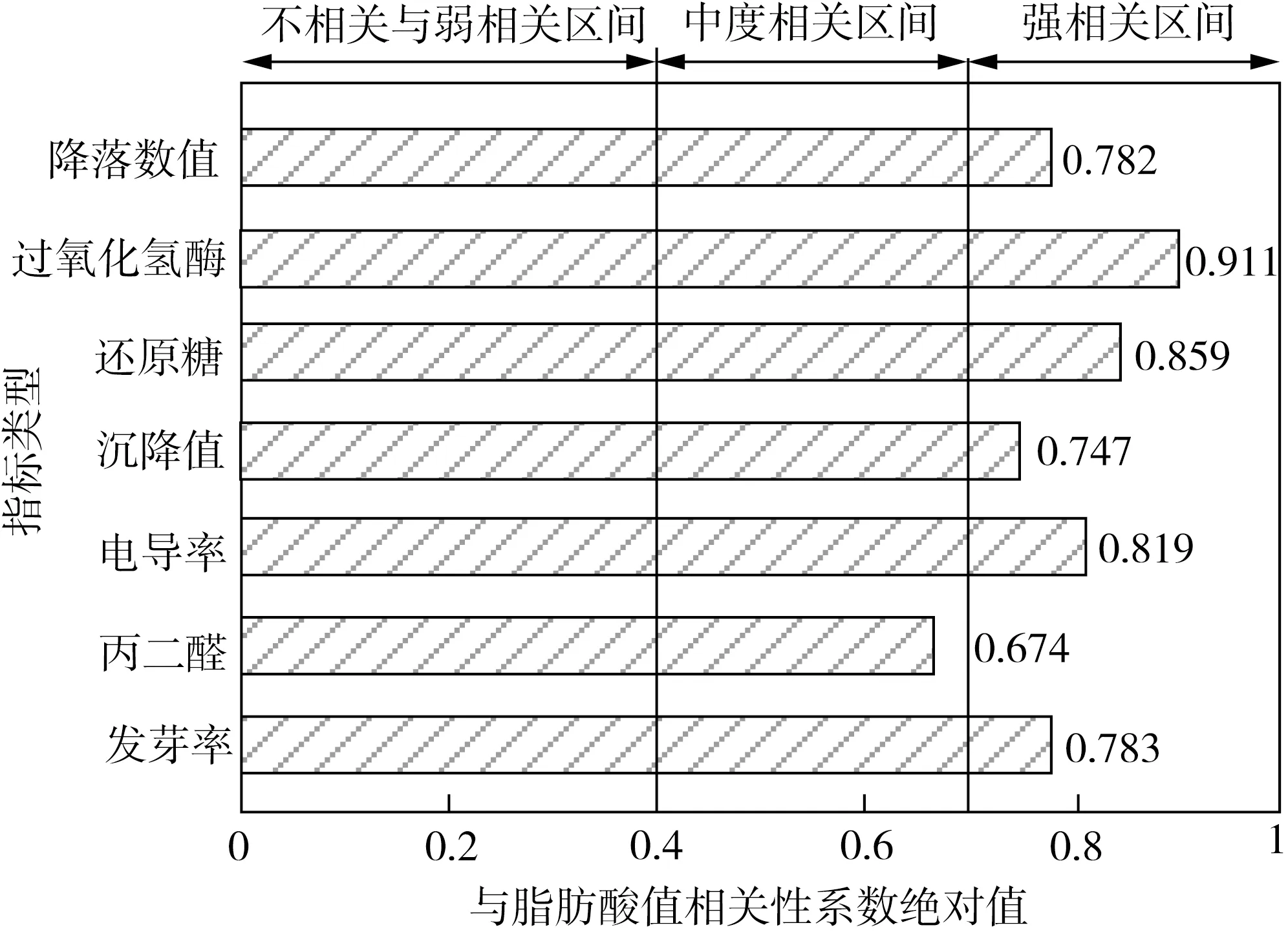
图2 脂肪酸值与其他指标间相关性系数
从图2可以看出,除丙二醛外,脂肪酸值与其他6个指标的相关性系数绝对值均大于0.7,说明这些指标间有很强的相关性关系。而丙二醛与脂肪酸值的相关性系数仅为0.674,属于中等程度相关,故可舍去该指标。然后对选取的指标进行KMO(检验统计量)和Bartlett(巴特利球体)检验以验证所选取的指标是否合适。得到KMO=0.836,显著性水平P<0.01,表明本研究所选取的小麦生理生化指标是合适的,在一定程度上避免了由于样本间相关性差异较大而对试验结果的影响。
2.3 多指标数据归一化
由于小麦各生理生化指标的单位不同且数值范围差异较大,为避免不同样本间差异所造成的试验误差,实现时间序列的延续,需要在使用预测模型对储藏小麦品质预测前需要把所有小麦多指标数据进行归一化。本研究采用式(9)所示的max-min归一化方法对小麦各原始生理生化指标数据归一化到0~1 之间。
(9)
式中:xi*和xi分别表示归一化处理前后小麦多指标数据;max和min对应每项指标样本的最大值和最小值。通过将小麦多指标数据进行归一化,也可以在一定程度上避免SVR模型的过拟合。
2.4 数据训练与分析
使用本研究构建的IGWO-SVR预测模型对预处理后得到的小麦多指标数据训练及预测,输出不同储藏时间段小麦脂肪酸值预测结果,以此判断储藏小麦品质状况。
此外,通过均方根误差(RMSE)、平均绝对百分比误差(MAPE)、判定系数(R2)这3种评价指标来评估模型的预测效果,这些评价指标对于储藏小麦品质预测精度的评价有很好的适用性,能有效判别各预测模型优劣情况,见式(10)~式(12)。
(10)
(11)
(12)

3 结果与分析
3.1 不同核函数SVR模型准确度对比分析
为分析和比较本研究所构建的混合核函数与常规核函数对小麦脂肪酸值预测准确度的影响,采用改进灰狼算法分别对线性核函数、多项式核函数、径向基核函数和混合核函数SVR模型的参数进行优化。模型训练和测试通过MATLAB R2016a和libSVM-3.22工具箱完成,实验中相关参数设置如下:初始种群规模N= 30,最大迭代次数T=100,收敛因子amax=2,amin=0,λ=1,r=1,惩罚参数C和核参数σ、g取值范围均为[0.01,100],多项式核参数d= 1,2,3。经过训练,可以得到的不同核函数SVR模型最优参数组合如表1所示,不同核函数SVR模型各储藏时间段预测值与实际值的绝对误差和平均相对误差如图3所示。
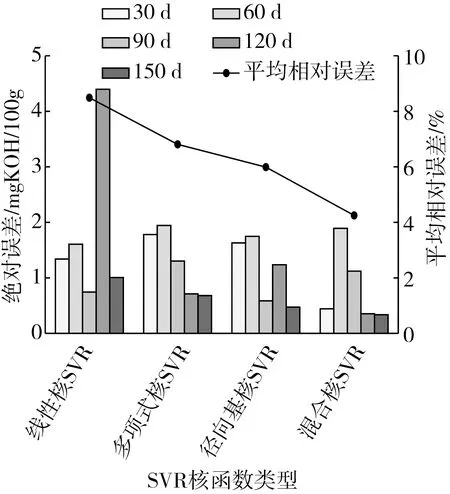
图3 不同核函数SVR模型平均相对误差和各储藏时间段绝对误差

表1 不同核函数SVR最优参数组合
从图3可以看出,采用线性核函数的SVR模型在储藏时间为120 d时预测值与实际值之间的绝对误差非常大,达到了4.397 mgKOH/100 g,且整体平均相对误差为8.49%,远高于其他模型。这是因为线性核函数仅通过内积变换,当样本足够丰富、函数复杂时不能得到较好的映射,因此难以实现对小麦多指标数据的有效训练;多项式核函数SVR和径向基核函数SVR模型的平均相对误差分别为6.81%和5.99%,由于能够有效的将小麦多指标样本数据映射到高维空间,一定程度上能实现对储藏小麦品质的有效预测;混合核函数SVR模型结合了局部性和全局性核函数的性能优势,取得了较好的预测效果:模型整体平均相对误差仅为4.25%,相比于线性核、多项式核、径向基核SVR分别下降了4.24%、2.56%和1.74%,较好的发挥了SVR的性能。结果表明本研究所构建的混合核函数性能优于传统核函数,能有效提高SVR的预测精度。
分析发现在早期的储藏小麦品质预测中(0~90 d)各模型准确度普遍较低,尤其是储藏时间60 d时各模型的预测偏差都超过了1.5 mgKOH/100 g。产生这一现象的原因是由于小麦籽粒从收获储藏到品质成熟的过程中会出现“后成熟”作用,其间小麦代谢旺盛,在合成高分子有机物的同时还会通过呼吸作用消耗本身储藏的物质,产生一系列不同程度的生理和生化反应,因此这一时期的各生理生化指标的测试数值会出现波动,从而对模型预测结果造成一定影响。
3.2 不同预测模型对比分析
为了进一步分析IGWO-SVR预测模型在储藏小麦的品质预测中的效果,本研究采用不同模型预测结果与评价指标相结合的方法,对各模型的预测效果综合评判。选取常用的网格搜索优化的SVR模型(GS-SVR)、布谷鸟算法优化的SVR模型(CS-SVR)和基本的灰狼算法优化的SVR模型(GWO-SVR)与之进行对比,对比模型中的核函数均使用径向基核函数。各模型不同时间段脂肪酸值的预测结果如图4所示,各模型评价指标统计结果如表2所示。

表2 各预测模型评价指标统计结果
由于网格搜索算法通常需要大量的训练数据,对于小样本数据GS-SVR模型没有获得很好的预测效果,模型的预测曲线震荡不平稳,RMSE和MAPE值大于其他模型,且R2值最小,表明模型整体拟合及预测效果较差;除150 d的时间段外,在其他时间段CS-SVR模型的预测值与实际值之间均存在较大偏差,评价指标结果也表明该模型整体误差偏大,难以有效描述储藏小麦的品质变化趋势;由于灰狼算法的收敛性能相比于网格搜索算法和布谷鸟算法较强,从而实现了对SVR参数更好的寻优,GWO-SVR模型预测准确度有明显提高;而IGWO-SVR模型进一步增强了灰狼算法的寻优性能和SVR核函数性能,相比于GWO-SVR,模型的预测稳定性和预测精度得到了增强,从图4可以看出它在不同储藏时间段的变化曲线与实际值的轨迹基本保持一致,波动较小,且MAPE值较GS-SVR、CS-SVR、GWO-SVR预测模型分别下降了4.88%、3.96%和2.25%,R2也更接近1,均表明该模型对储藏小麦品质有良好的预测效果。
小麦在储藏期间脂肪酸值升高的主要原因是一些游离脂类的氧化水解作用,小麦细胞膜上的三酰甘油酸和和磷脂中的结合脂肪酸在磷脂酶和脂肪酶的催化作用下不断释放出来,导致游离脂肪酸的含量不断增长,从而致使脂肪酸值增加。在良好储藏环境下,储藏时间较短的小麦一般不会发生陈化变质,属于品质优良的小麦范畴。随着时间的增长,在温湿度、微生物、小麦呼吸作用等因素共同作用下,储藏小麦的品质开始产生变化并逐渐出现陈化劣变。脂肪酸值作为品质评估指标时,本研究建立的IGWO-SVR预测模型在储藏时间为120 d和150 d的小麦预测精度远高于其他模型且与实际值非常贴近,能很好的适用于短期储藏小麦品质预测工作。
3.3 发芽率对模型有效性验证分析
为验证IGWO-SVR模型对于其他生理生化指标作为小麦品质评估指标的有效性,选取周麦22中的发芽率指标作为品质评估指标对模型进行验证。小麦发芽率随着储藏时间的延长不断降低,可用作于小麦品质的评估[19]。经相关性分析,选取脂肪酸值、还原糖、过氧化氢酶这3个生理生化指标作为影响指标因子,测得KMO=0.808、P<0.01,表明指标选取合适。使用IGWO-SVR模型对预处理后的多指标数据进行训练及预测,得到不同储藏时间段发芽率的预测结果如图5所示。

图5 不同储藏时间段发芽率预测结果
从图5中可以发现小麦的发芽率在储藏前期维持在90%左右,但随着储藏时间的增长逐渐下降到了80%。这是因为新收获的小麦种子的胚组织积累了足够多的营养物质,种子具有较高的生活力,在适宜的环境下很容易萌发;但随着储藏时间的增长,小麦通过呼吸作用会不断将有机物分解成二氧化碳和水,而且粮仓中的微生物、虫害等不良因素也会消耗种子发芽所需的营养物质,导致小麦种子活力下降甚至失去活力。一般情况下,小麦的活力指数呈现先平稳减小后逐渐下降的规律,会出现一个明显拐点(如图5中120~150 d时),拐点之后影响种子活力的各项指标迅速下降,这也是发芽率明显下降的原因。
经过对发芽率的模型计算,RMSE值为1.838 6,MAPE值为1.85%,R2值为0.931 7。相比于脂肪酸值作为品质评估指标时的模型结果,发率的模型拟合效果稍逊。这是因为脂肪酸值有6个影响指标因子,而发芽率仅有3个,训练数据少了一半,从而导致结果差一些。结合评价指标和图5来看,发芽率的模型整体误差不大,可以验证IGWO-SVR预测模型的有效性。
3.4 IGWO-SVR模型适用性验证分析
为检验本研究提出的预测模型对不同品种小麦的适用性,利用文献[20]中的郑麦9023多指标数据对该模型进行验证分析。选取脂肪酸值作为品质评估指标因子,经相关性分析后得到6个合适的影响指标因子。将郑麦9023多指标数据预处理后输入IGWO-SVR模型进行训练和预测,可得到不同储藏时间段模型预测结果如图6所示。
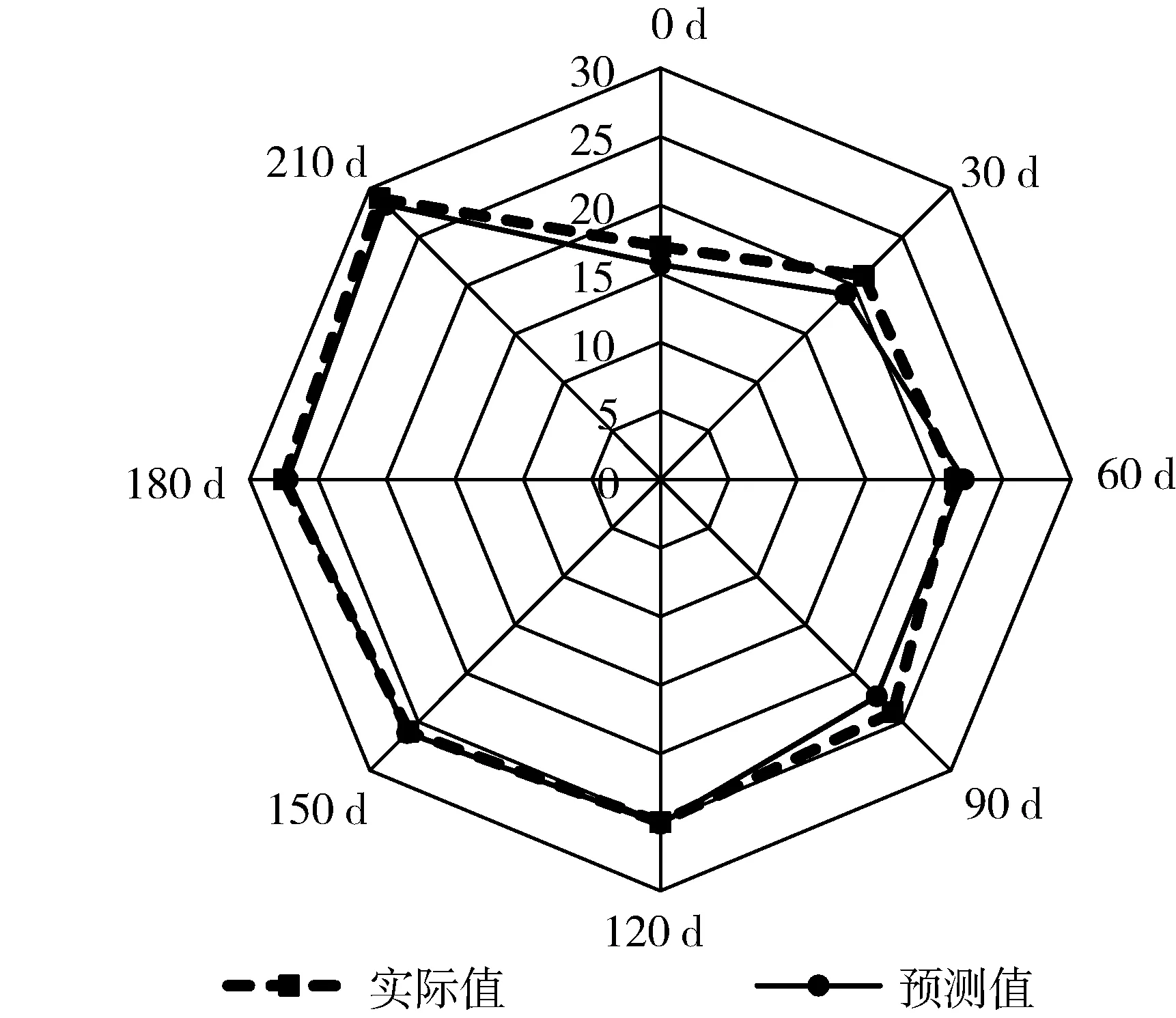
图6 郑麦9023不同储藏时间段脂肪酸值预测结果
由图6可以看出,IGWO-SVR模型保持了稳定可靠的预测性能,各储藏时间段的脂肪酸值预测结果与实际值较为接近。判定系数R2值达到了0.959 1,说明模型的拟合效果非常好,均方根误差MAPE值为3.87%,远小于10%的有效预测范围,进一步表明该模型预测精度较高,并在一定程度上避免了SVR模型的过拟合和欠拟合问题,对于短期储藏小麦的品质预测有很好的适用性。仔细观察还可以发现,在储藏时间0~90 d时,模型的预测值与实际值间存在一定的偏差,但在120~210 d的时间段,模型的预测值与实际值曲线基本一致,精度非常高。同样表明了在储藏早期由于“后成熟”作用的存在,小麦多生理生化指标数值变化规律不一,从而导致早期的预测结果不稳定并出现一定偏差;随着储藏小麦“后成熟”作用的结束,其内部各项生理生化指标值的变化趋于稳定,模型的预测精度也显著提高。本研究模型对于实际储藏小麦的品质预测工作具有很大的参考价值。
4 结论
针对储藏小麦品质精确、高效预测的迫切需要,本研究从小麦多生理生化指标的研究角度出发提出了一种IGWO-SVR模型用于短期储藏小麦的品质预测。实验结果表明,相比于线性、多项式、径向基核函数SVR模型,采用混合核函数的IGWO-SVR模型的平均相对误差分别下降了4.24%、2.56%和1.74%。同时,IGWO-SVR模型的R2值相比于GS-SVR、CS-SVR、GWO-SVR预测模型更为接近1,显示模型整体拟合效果和预测精度更优。利用发芽率作为品质评估指标对IGWO-SVR模型的有效性进行检验,MAPE值仅为1.85%,R2值为0.931 7,表明模型精度较高;通过不同品种小麦对模型适用性进行验证,MAPE值为3.87%,R2值为0.959 1,显示模型适用性良好。实验结果表明本研究模型是一种行之有效的短期储藏小麦品质预测方法,有助于小麦的安全储藏。
由于本研究所开展的实验周期较短且在恒温恒湿条件下进行的,在后续研究中,拟对在实际粮仓中获取到的小麦样本进行试验,同时加强对长储藏期小麦品质的研究,以获得性能更稳定和更高实用价值的小麦品质预测模型。
