面向烟草领域的科研知识图谱服务平台关键技术研究
2021-09-26王卫军李娜郑新章刘亚丽杜一王永胜冯伟华徐华玉
王卫军,李娜,郑新章,刘亚丽,杜一,王永胜,冯伟华*,徐华玉
1 中国科学院计算机网络信息中心,北京市海淀区中关村南四街4号 100190;
2 中国科学院大学,北京市石景山区玉泉路19号(甲) 100049;
3 中国烟草总公司郑州烟草研究院,郑州高新技术产业开发区枫杨街2号 450001;
4 北京信息科技大学,北京市海淀区清河小营东路12号 100192
烟草领域通过科技创新相继部署实施了烟草基因组计划[1]、特色优质烟叶开发[2]、卷烟减害技术等一系列科技重大专项,产出了大量高水平的科研成果。目前,烟草领域已经积累了一些有价值的科研数据,如中国烟草科技信息中心的烟草文献、专利、科技成果和在研项目数据[3];国家质量监督检测中心的历年监督检测数据和真假烟鉴别数据;各中烟公司收集的卷烟辅材、香精香料、烟叶近红外和实验室产品检测数据等。烟草科研数据的不断累积,其管理和利用中不可避免地存在科研数据分散、存储格式各异以及系统之间数据共享难等问题。烟草行业涉及基因工程、植物学、农学等多学科研究领域,有效管理烟草领域各系统中的多源、异构科研数据,并挖掘出潜在的科研知识面临多重挑战,如:在已有烟草数据基础上,研究相关数据的组织与抽取方法,实现高效存储;利用已有烟草科技信息资源,融入更多第三方数据,实现符合烟草科研领域特定的数据分析与挖掘;构建面向烟草科研人员的融合多源异构数据的统一知识服务平台等。针对上述问题,在中国烟草科研大数据重大专项项目实施中,前期已经构建的烟草科研大数据标准体系[4]和烟草科研大数据资源体系[5],可以作为烟草科研知识图谱研发的重要基石。在上述标准体系之上,通过对烟草领域的科研知识以图谱方式进行组织管理、分析挖掘,可以实现对烟草领域科研项目、成果、研究人员等深层次的知识挖掘与应用。
知识图谱起源于20世纪60年代的语义网络,经历了本体理论、语义Web[6][7]、链接数据等相关技术发展历程。自2012年谷歌提出谷歌知识图谱的概念以来[8],已广泛应用于语义搜索、智能问答、辅助语言理解、辅助大数据分析等领域[9]。知识图谱本质上是一种从数据中识别、发现知识,以及推理图谱中实体之间的相互关系的可计算模型。近年来,知识图谱通过对科学研究中相关科技数据进行有效管理与组织,为科技数据深层次的分析与挖掘提供了极其重要的高质量数据支撑[10],如中国农科院[11]构建的水稻知识图谱;学术领域的链接开放数据平台SN SciGraph[12];中国科学院计算机网络信息中心的SKS大数据知识图谱平台[13]等。目前,面向科技领域进行分析及评估的工具及软件如CiteSpace、SCI2、Gephi、VOSviewer等已广泛应用于文献情报领域的相关研究中,但其在数据处理、增量更新及自动实时分析计算等方面存在不足。本平台直接从采集数据源上构建烟草领域知识模型,通过大数据流水线的清洗、处理与融合,形成高质量的大规模可分析知识图谱数据,并随数据源的不间断更新自动实现分析计算结果及可视化呈现。同时在对烟草领域数据进行深入挖掘的过程中,针对烟草数据的特点,研发科研合作社区、科研相似社区的发现机制与策略,并取得了良好的可视化效果。目前该平台已经完成安装部署,规划在烟草行业内网向用户开放。
1 面向烟草领域的科研知识图谱服务平台
1.1 烟草科研知识图谱相关技术及实现流程
知识图谱是通过使用更加规范的语义信息来提升某一领域内数据的质量,从而将异构、粗糙的数据精炼为结构化、高度关联的高质量知识。知识图谱的构建主要有两种方法[14],一种是自顶向下的方法,另外一种是自下向上的方法。面向烟草领域知识图谱的构建及应用,涉及知识建模、数据获取、知识融合、知识计算与应用等内容。根据烟草数据的特点,平台通过研发烟草数据本体及Schema模型,自顶向下进行知识图谱的构建,其相关技术及实现流程如图1所示。
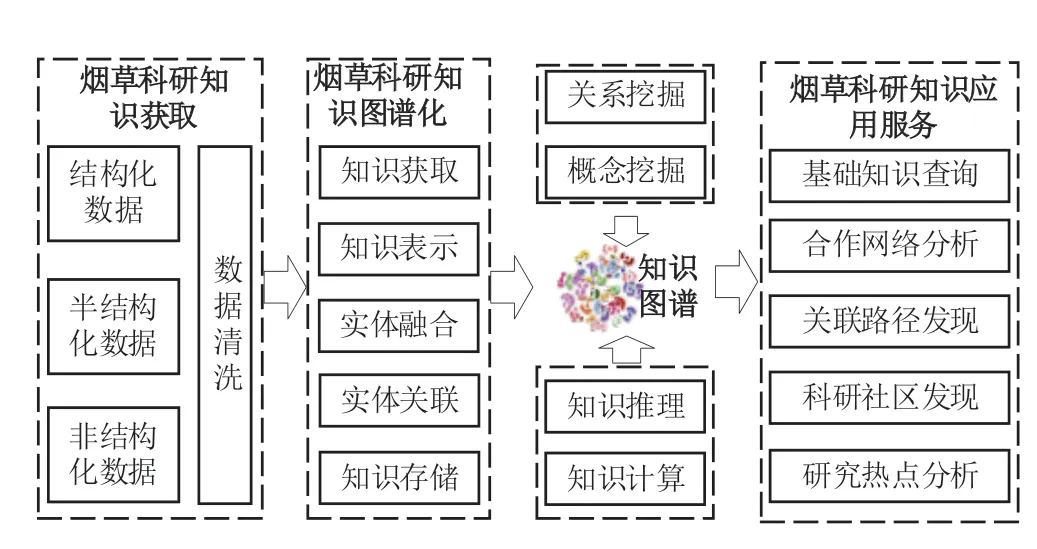
图1 烟草科研知识图谱相关技术及实现流程Fig.1 Technologies and realization process of tobacco scientific research knowledge graph
(1)烟草科研知识Schema模型。建模过程对烟草科研数据中的各种科研实体进行分析,抽象出烟草科研数据的项目(科研项目)、机构(成果所属单位或机构)、成果(论文、专利、标准、图书等)、关键词(知识点)等实体类型以及各实体类型之间的关系,构建烟草科研知识图谱的Schema模型,从概念上描述烟草领域相关概念与概念之间的关系及属性表示。
(2)异构数据清洗。抽取多源异构系统中的数据,进行初步的数据清洗,形成规范化的数据格式。烟草科研数据主要来源于烟草领域科研机构各系统中累积的烟草论文、专利、项目以及各种烟草数据信息。另外,通过制定符合法律规定的数据采集机制,采集电子数据库中关于烟草领域的数字资源,对烟草科研知识图谱中的数据形成有效补充。针对清洗处理后的异构多源数据,平台最终选用Neo4j图数据库作为存储方案。
(3)知识图谱构建、知识挖掘与推理。烟草科研知识来源于不同系统,科研实体以及知识体系不可避免地存在重复、缺失、冲突等问题。因此研发内容包括:通过对获取的数据以网络的形式进行组织,通过科研实体融合、消歧、对齐等技术,形成全局统一的知识标识体系;采用图数据库完成烟草知识的存储与管理;采用人工与机器学习技术相结合的方法,对不同知识分类体系、机构等烟草科研实体进行融合、对齐等处理;对烟草知识通过符号表示或向量表示方法,计算推理、补全烟草科研实体之间的潜在关系;通过制定一系列相关的机制维护知识图谱模式层的更新等。
(4)烟草科研知识分析及应用。在烟草知识图谱知识网络结构的基础上,采用基于图深度优先遍历算法、社区发现算法、文献计量学理论等实现机构(人员)合作、学术研究热点等知识可视化决策支持的应用。如通过社区发现算法完成科研群体的识别划分;通过图遍历算法分析机构合作情况;通过成果主题信息分析行业发展趋势等。
1.2 烟草科研知识图谱关系模型
平台从科研项目、成果、机构、科研人员、关键词等实体以及实体之间的关系、属性出发,研发烟草科研知识的Schema模型及知识的表示方案,详细的烟草科研实体及之间的关系如图2所示。基于图2的烟草科研知识图谱科研实体及关系模型,根据烟草科研知识图谱中科研实体对象的不同及实际需求,截至2020年5月,已形成了一个包含2.2万条科研项目、42.7万条科研成果、64.6万条科研人员及12万条科研机构实体的烟草知识图谱服务平台。
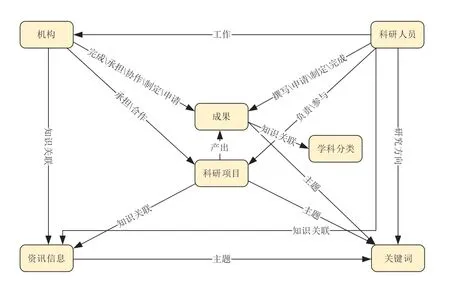
图2 烟草科研知识图谱科研实体及关系数据模型Fig.2 Scientific research entity and relational data model of tobacco scientific research knowledge graph
1.3 烟草科研知识图谱服务平台系统架构
烟草科研知识图谱服务平台基于B/S系统架构,采用多种不同的可视化方法,遵循“Overview+Detail”及“Focus+Context”设计规律,研发烟草科技信息资源知识服务系统,系统架构如图3所示。平台系统架构主要由数据源、数据服务、计算推理、应用服务、运维管理5部分组成。其中数据源部分主要包括烟草行业的科研项目、论文、专利、标准等各种结构化、非结构化、半结构化数据,以及对数据初步的整合、清洗;数据服务是整个系统平台的支撑,主要完成烟草数据的实体、关系抽取,以及对知识资源的标识、标注工作;计算推理部分主要完成对烟草图谱中数据的消歧、推理、科研实体影响力计算等;应用服务部分主要完成知识查询、合作分析、社区发现、影响力评价以及相应的可视化呈现;运维部分主要完成整个系统平台的本体维护、安全管理、大数据软件的部署及管理、数据的流水线管理等。
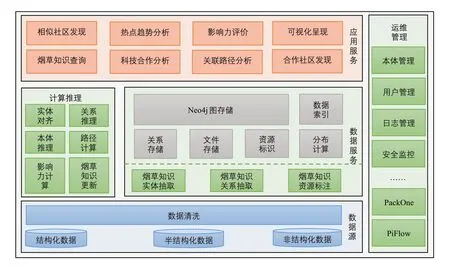
图3 烟草科研知识图谱系统架构Fig.3 System architecture of tobacco scientific research knowledge graph
其中,应用服务的可视化呈现主要基于Echarts可视化框架、Vis.js可视化框架等,并通过加载JSON数据进行可视化实现。面向海量的烟草异构数据处理,在平台研发过程中,对大数据管理工具的部署,主要采用自主研发的PackOne[13]实现主流大数据软件在云端快速弹性部署,该工具可完成Hadoop、Spark、PiFlow、Neo4j等主流大数据管理工具的快速部署;对烟草数据的处理,主要采用基于Spark自主研发的PiFlow[13]数据流水线工具,完成所见即所得的大数据采集、处理及融合。
2 烟草科研知识图谱服务平台关键技术及应用
面向烟草领域的科研知识图谱服务平台的功能可分为两类,一类是知识网络中烟草科研实体的合作网络分析、关联路径发现、热点主题分析等,另一类是科研社区发现的相关研究。其中科研社区发现涉及问题较为复杂,涉及数据计算效率、社区划分等问题,是服务平台研发中需要重点关注的问题。
2.1 知识网络实体及关系发现技术与应用
在该部分功能研发中,平台主要采用图深度优先遍历算法、共词分析理论等作为相关应用实现的关键技术。其中,图深度优先遍历算法(Depth First Search)是一种递归算法[15],主要用于解决合作网络分析、关联路径发现等问题,进而将相关科研实体及其之间的关系提取出来,并进行可视化呈现。共词分析是文献计量学中重要的内容分析方法[16],主要原理为通过对代表某一学科领域的研究主题或方向的专业术语同时出现在某一学术文献中的现象进行分析,从而获取这些专业术语所代表的学科或主题的变化趋势[17-18]。
2.1.1 科研合作网络分析
合作网络分析是指利用烟草科研知识图谱,发现与某科研机构(或科研人员)有科研合作关系的科研机构(或科研人员)。在该部分,基于图深度遍历算法,实现科研机构(或科研人员)的科研合作关系发现与分析。科研机构与科研人员合作网络分析的实现原理大致相同:
(1)指定需要进行合作分析的科研机构(或科研人员),作为合作网络关系图中的中心点。
(2)以科研机构(或科研人员)为中心点,通过限定时间范围、合作类型(项目、成果)等分析条件,分析查找环绕该中心点的科研机构(或科研人员),形成合作网络。
(3)合作图络中,合作关系的密切程度通过节点之间边的长短来表示。
以科研机构合作网络分析为例,可视化合作网络图如图4所示。
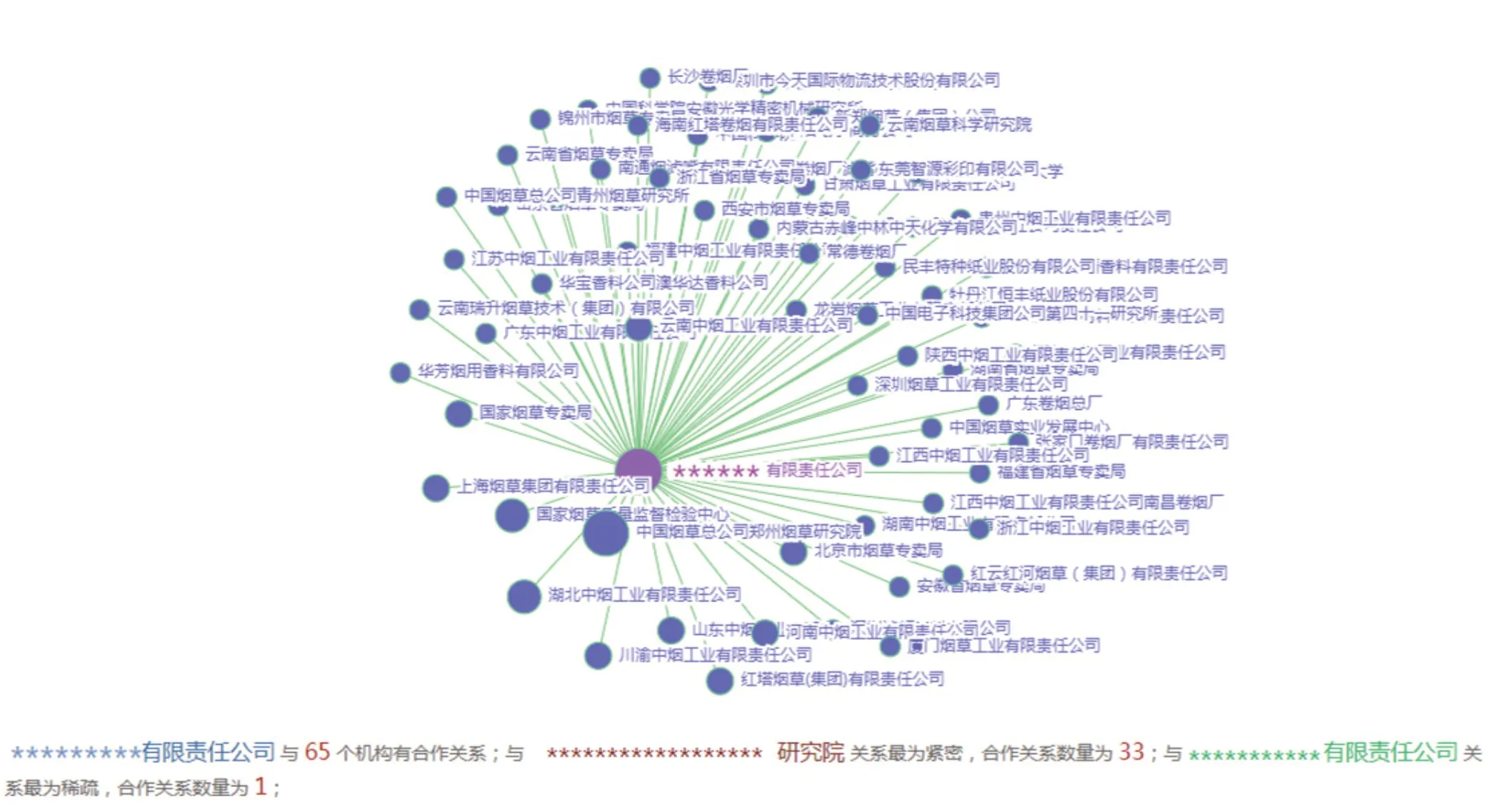
图4 科研机构合作网络分析结果Fig.4 Analysis results of research institution cooperation network
2.1.2 科研关联路径发现
关联路径发现主要指通过查询发现指定科研人员(或科研机构)之间基于知识网络的直接或间接关系路径,并用可视化网络图形式展示出来。关联路径中的知识网络实体包括:人员、机构、项目、成果。基于图深度优先遍历算法,实现原理为:
(1)通过指定的两名科研人员(或两个科研机构)作为网络图顶点,限定关联路径的条件如最大关系深度值,通过路径最大深度值,获取两名科研人员(或两个科研机构)之间存在的一条或多条关系路径。
(2)路径包括其经过的实体类型:项目、成果、单位等,关系类型:参与项目、负责项目、完成论文等。
(3)形成用于发现科研人员关系路径的网络图,并给予文字信息描述。
以科研人员关联路径发现为例,其关联路径发现的可视化结果示例如图5。
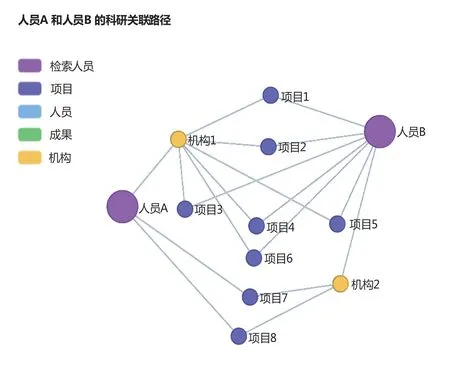
图5 科研人员关联路径发现Fig.5 Researchers association path discovery
2.1.3 科研研究热点发现
烟草研究热点发现的目的是通过对关键词进行共词分析来判断烟草科研热点的发展变化,通过关键词之间的相关性在一定程度上揭示不同研究方向或视角的内在联系。实现原理为:
(1)通过对论文或指定学科领域内的论文关键词进行频次统计,截取高于一定频次的关键词进行共词聚类分析,获得高频度出现的关键词共词,从而获得研究热点或领域内的研究热点。
(2)用特定颜色节点表示热点关键词,即在条件设定的范围内被多个条目标注的关键词。热点关键词节点的数量不多于设定的阈值。
(3)用特定颜色节点表示相关关键词。相关关键词是与热点关键词有共现关系的其它非热点关键词。
(4)图谱中所有节点的大小表示当前关键词共现频次的多少。图谱中的连线表示两个关键词间有共现关系,连线的粗细位置表示两个关键词间关联度的强弱,关联度越强的关键词在图谱中聚合的越紧密。
以国内研究为例,可视化图如图6所示。结合时间年度变化,可视化展示不同年度研究热点的变化趋势。
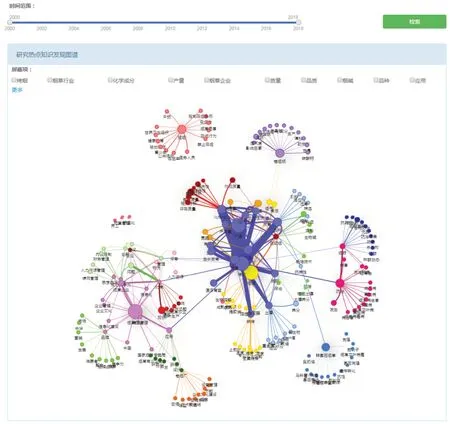
图6 基于时间变化的烟草研究热点分析与可视化Fig.6 Analysis and visualization of tobacco research hotspots based on time change
2.2 科研社区发现关键技术与应用
在烟草知识图谱科研社区发现的研发中,为提升社区发现的效率及效果,平台通过构建科研人员影响力模型,对相关数据进行过滤,并采用预计算的方式,将影响力作为属性值同步更新到图数据库中,根据更新频率定期更新该属性值,取得了良好的效果。
2.2.1 科研人员影响力模型
影响力模型构建中,平台结合烟草行业科技成果评价标准及烟草科研人员学术成果类型、数量等特征,采用多级指标体系构建科研人员影响力分析模型,评价指标体系如图7所示。影响力的计算基于对应科研人员在烟草科研领域的科研产出,每个科研人员基于某项科研产出的得分为该产出的产出得分乘以得分权重,得分权重与该科研人员在该项产出中的贡献大小有关,贡献大小可以由该产出的署名顺序确定,或者根据该产出的原始记录(例如工作日志)来确定。科研人员最终的影响力得分由其各项产出的得分累加得到,科研人员影响力得分的计算方法如公式(1):
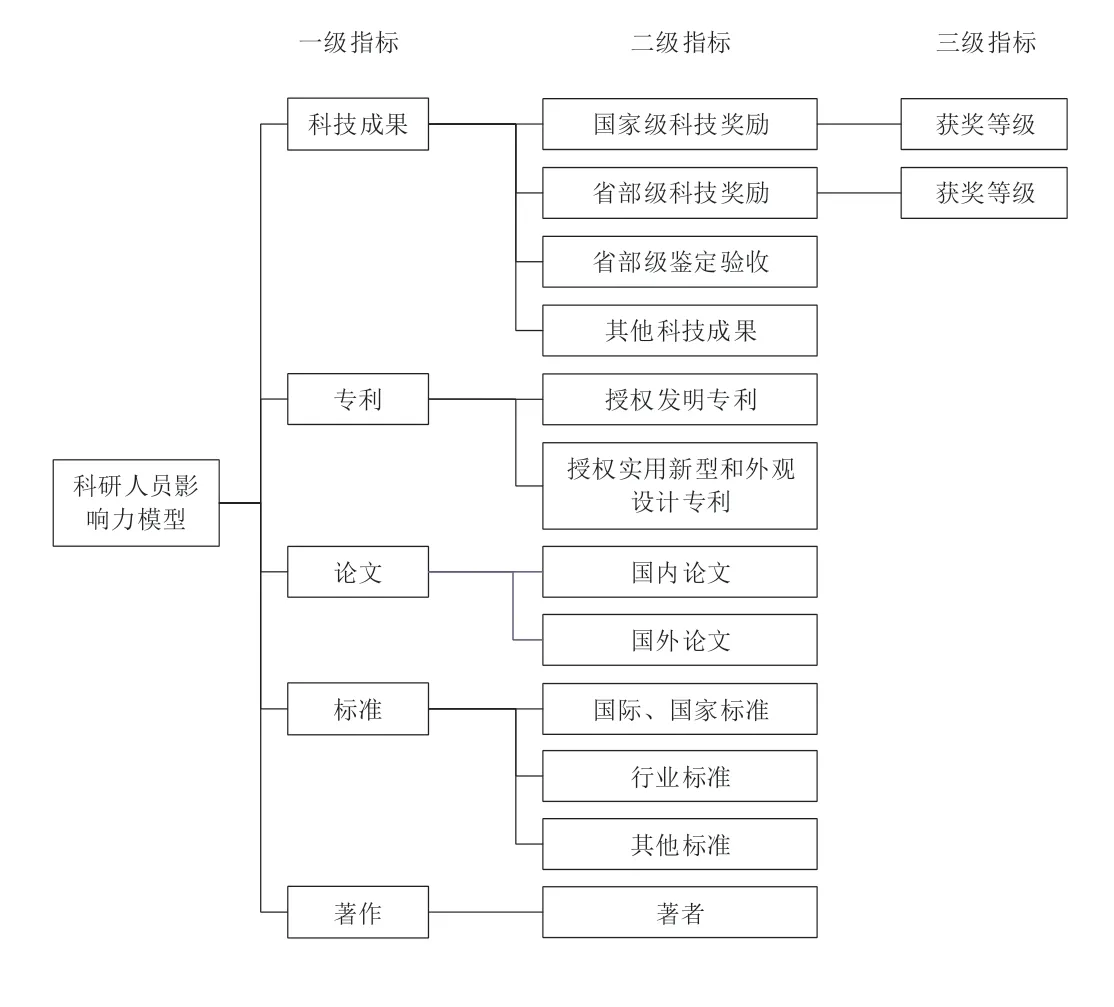
图7 科研人员影响力评价指标体系Fig.7 Evaluation index system of scientific researcher's influence
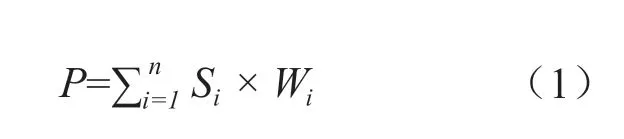
公式(1)中,P为某科研人员影响力得分,n为该科研人员的科研产出数量,Si表示该科研人员的第i个科研产出对应的最后一级指标的得分(即对应产出的产出得分),Wi表示该科研人员的第i个科研产出对应的得分权重(依据贡献大小确定)。例如,某个技术人员的科技成果获得省部级的三等奖,则该科技人员针对该项产出的人员得分将为三等奖的省部级奖励的产出得分,再乘以由该技术人员在该科技成果中所做出的贡献决定的得分权重。
2.2.2 科研人员合作社区发现
烟草科研人员合作社区是指由合作关系紧密的烟草科研人员组成的群体,在同一社区内的科研人员在学术研究上有一定的相通之处。通过科研人员合作社区发现,可发现新的研发课题、寻找研究合作伙伴、发现重要科研团队等。在烟草技术领域中,科研人员的合作数据里面存在大量边缘技术领域或其他领域活跃的科研技术人员,从而造成合作关系及合作数据复杂且庞大,社区发现计算效率低下,不利于实时或者频繁及时的更新数据。在进行社区发现前,平台对科研活动数据依据科研人员在对应科研领域的影响力等进行科研人员的过滤以解决上述问题。发现结果示例如图8,其实现原理如下:
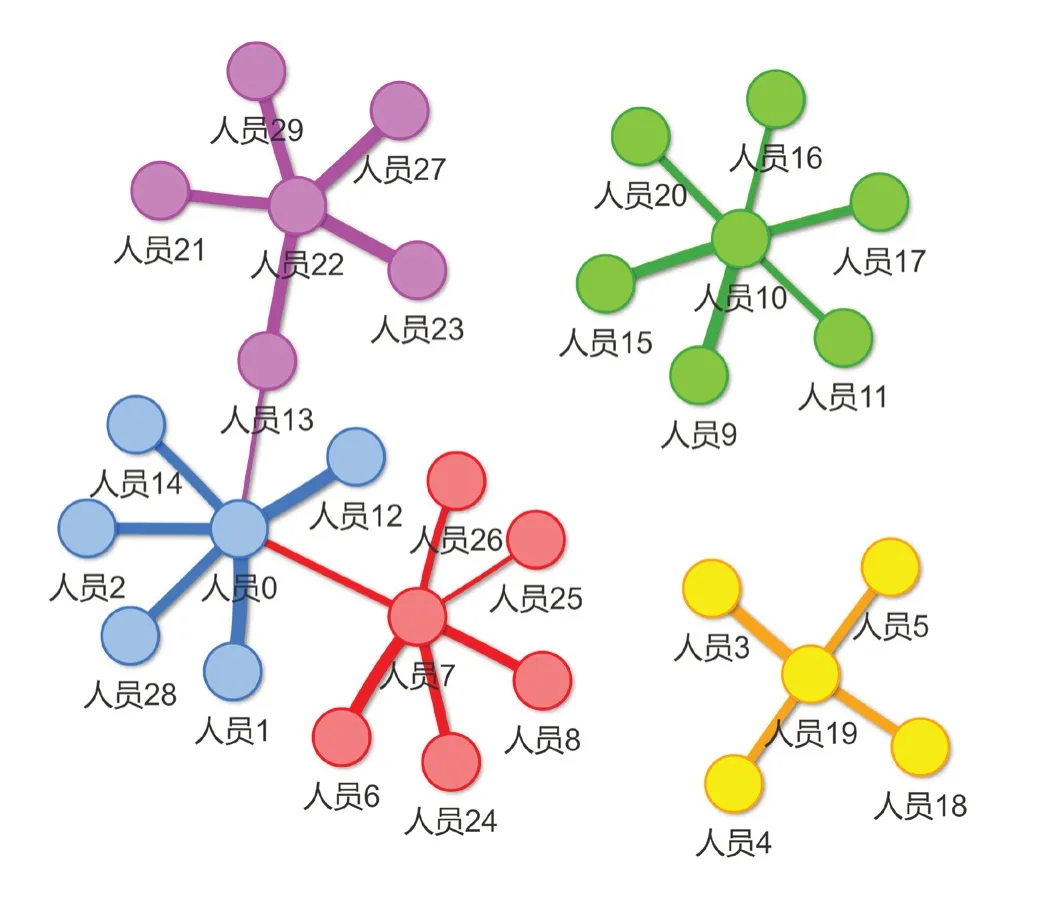
图8 科研人员合作社区发现可视化图Fig.8 Researchers collaboration community discovery visualization
(1)获取合作原始数据。科研合作数据包括科研项目和参与对应科研项目的科研人员,以及科研成果和产出对应科研成果的科研人员。
(2)依照2.2.1节的科研人员影响力模型,计算科研人员影响力。
(3)对合作数据进行筛选,所述筛选包括:以领域内影响力高于阈值(根据普莱斯定律[19]确定阈值)的科研人员作为合作图谱的生成和展示对象,从合作数据中删除科研人员影响力低于阈值的科研人员。
(4)根据筛选后的合作数据,生成科研人员合作关系网络。对于科研人员项目合作关系网络可以进行进一步的过滤,将合作次数低于设定阈值(根据普莱斯定律确定阈值)的合作关系删除(即将合作次数设置为0),降低偶然的项目合作对最终合作图谱的干扰。在此步骤中,考虑到早期的合作数据对合作社区图谱的意义和价值较低,方法对合作时间早于设定时间的合作权重进行调整,降低早期合作的影响。例如两位科研人员之间近2年的合作关系的权重为1,近2~5年的合作关系的权重为0.8,超过5年的合作关系的权重为0.5,按上述权重两位科研人员6年前的4次项目合作过滤后视为2次合作,3年前的1次合作在过滤后仅为0.8次合作。
(5)采用Louvain社区发现算法[20],基于科研人员合作关系网络及科研人员影响力,生成科研人员合作社区图谱。Louvain算法是基于模块度的社区发现算法,该算法在执行效率和效果上都表现较好,且能够发现层次性的社区结构,实现最大化整个社区网络的模块度的目标。
2.2.3 科研人员相似社区发现
科技知识图谱相似社区指的是由研究兴趣相似的若干科研人员组成的群体,是通过构建科研人员研究兴趣相似性网络,识别相似科研人员的社区结构以及社区间的关系。作者共被引分析[21-22]是科研人员相似社区发现的理论基础,其原理为:当两位不同的作者的文献同时被第三位作者的文献引用时,则可以称这两位作者存在一种共引关系。如果两位作者的共被引频次越高,则两位作者的学术关系越密切。而经常在一起被引用的作者,他们在学术研究主题的概念、理论、方法是相关的。烟草技术领域中,在科研人员所产出的论文里面,由于还引用了大量交叉技术领域或其他领域的论文,这会导致社区内的科研人员的研究方向和科研兴趣的相似性有所降低。为解决上述问题,平台采用普莱斯定律来确定核心科研人员的最低影响力分值、最低发文数和最低被引量等,对数据进行过滤。发现结果示例如图9,其实现原理如下:
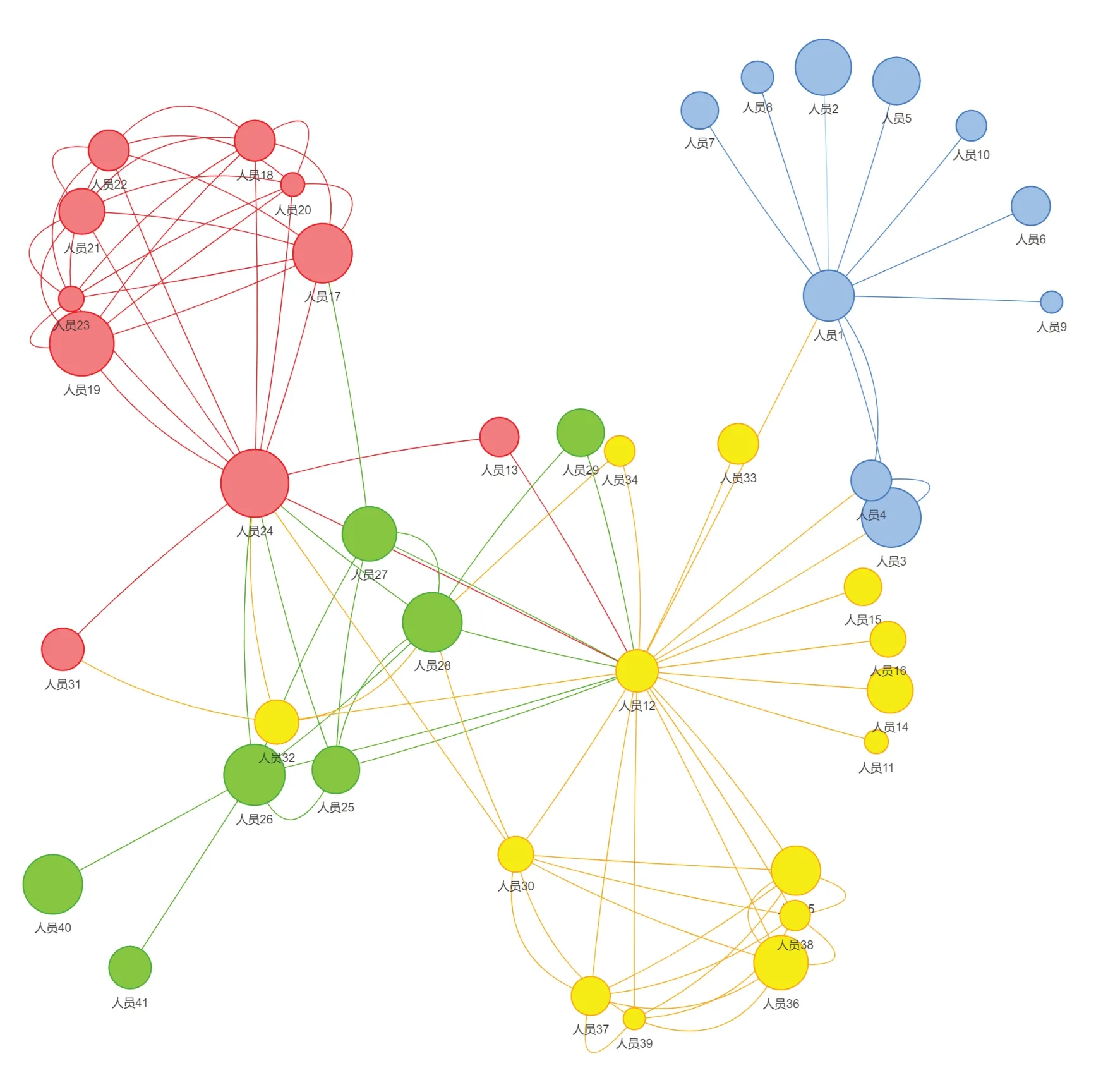
图9 科研人员相似社区发现可视化图Fig.9 Researchers similar community discovery visualization
(1)获取引用关系数据,所述引用关系数据包括科研文献、科研文献之间的引用关系以及对应科研文献的作者。
(2)依照2.2.1节的科研人员影响力模型,计算科研人员影响力。
(3)对引用关系数据进行筛选,所述筛选包括:采用普莱斯定律来确定核心科研人员的最低影响力分值、最低发文数和最低被引量,进而对数据进行过滤。
(4)根据筛选后的引用关系数据,生成作者共被引关系网络。在共被引关系网络中,如果两位作者共被引次数较少,例如只存在1次共被引,如果保留他们之间的相似关系,会使得生成的相似性网络密集型较高,故对网络中共被引次数较低的关系(阈值依据普莱斯定律确定)进行剔除。同时,对共被引关系网络进行基于时间的过滤,对两位科研人员的论文共被引时间早于设定时间的共被引关系设置权重,降低早期共被引关系的影响。
(5)采用Louvain社区发现算法,基于作者共被引关系网络及科研人员影响力,生成科研人员相似社区图谱。
3 结论
面向烟草领域的科研知识图谱服务平台的研发,可有效解决烟草科研知识异构、多源等问题,进而发现探究烟草领域的科研实体及其之间的关系,揭示烟草科研方向及科研规律。在研发过程中,通过将烟草领域知识、文献计量学相关理论、计算机相关技术相结合,解决烟草领域多源异构数据管理与利用、烟草科研知识网络分析、烟草科研社区发现等问题。并通过专家访谈等方式对烟草科研知识图谱服务平台在管理烟草科研知识中的效果进行分析,认为平台有效地解决了烟草知识深层次管理与利用问题,知识图谱技术是烟草科研知识深层次挖掘与应用的重要发展技术方向。同时认为,平台还需要在烟草知识的数据质量提升以及挖掘利用方面进行深入研究,通过研发深度学习相关算法模型,提升烟草知识实体的识别、抽取、消歧等工作的准确性,促进烟草知识图谱辅助科研决策分析的能力。
