基于GA-ELM的水性环氧乳化沥青黏结性能预测
2021-09-22陆由付樊振通韩冰王朝辉陈宝
陆由付,樊振通,韩冰,王朝辉*,陈宝
(1.齐鲁交通发展集团有限公司,山东 济南 250000;2.长安大学 公路学院;3.河南官渡黄河大桥开发有限公司)
1 前言
乳化沥青作为道路预防性养护常用黏层材料,具有施工简便、经济、环保等优点,但由于其存在黏度低、耐高温性差、抗老化性差等缺点,严重制约了其在重交通和特重交通道路中的应用与推广。水性环氧树脂与水性固化剂混合发生交联反应形成热固性材料,具有低VOC(挥发性有机化合物,Volatile Organic Compounds)和使用便捷性的特点。相比于沥青,它具有更高的温度稳定性、物理强度以及化学稳定性。采用水性环氧树脂改性的乳化沥青,兼具了水性环氧树脂优良的黏结性和乳化沥青的使用便捷性,显著改善了乳化沥青高温性能,增强了路面层间黏结性能。然而,水性环氧树脂改性乳化沥青是一种由环氧树脂、乳化剂、沥青和固化剂经一系列化学反应制得的混合乳液,成分较为复杂,这就导致水性环氧树脂改性乳化沥青的性能评价需要考虑多重因素影响,试验量较为庞大。为此,考虑到水性环氧树脂改性乳化沥青黏结性能评价方面,有必要建立一种模型快速预测水性环氧树脂改性乳化沥青黏结性能。
为了减少试验量和快速得到较为精确的结果,神经网络、机器学习法越来越多地用来获取材料性能变化规律。一些专家、学者陆续采用误差修正模型(ECM)、灰靶决策(GTD)、支持向量机(SVM)和径向基函数(RBF)等评价方法和算法来预测沥青材料性能。但是这些方法存在求解过程中容易陷入局部最优解、参数不易确定、训练样本要求高、训练难度较大等问题。极限学习机(Extreme Learing Machine,ELM)是一种改进的单隐层前馈神经网络,与BP神经网络模型和支SVM模型相比,具有泛化能力强、迭代次数少和精度高等特点,但由于随机给定权值,使得ELM存在稳定性差、过拟合等问题。遗传算法(Genetic Algorithm,GA)是通过选择、交叉、变异算子寻找最优解的一种进化算法,具有良好的稳定性,常用于改善神经网络模型收敛性及精确度。
因此,该文采用遗传算法(GA)优化后的极限学习机(ELM)算法,建立基于GA-ELM的水性环氧树脂改性乳化沥青的黏结性能预测模型。通过与BP神经网络和ELM等传统预测模型对比分析,发现GA-ELM模型在预测水性环氧树脂改性乳化沥青黏结拉拔强度方面具有更高的预测精度和效率。这也为水性环氧树脂改性乳化沥青黏结性能的研究提供了一种新思路。
2 数据采集与归一化处理
选取水性环氧树脂环氧值、水性环氧树脂掺量、水性固化剂胺值、水性固化剂掺量、乳化沥青针入度、乳化沥青黏度、乳化沥青软化点和测试温度作为输入参数,黏结拉拔强度作为输出参数。为提高预测模型精度,在文献[7]提供数据的基础上,补充一系列试验获得更多的样本数据,试验参数及指标如表1所示。

表1 试验参数及其指标
将100组样本数据中80组试验数据用于模型训练,20组数据用来验证模型精度。根据式(1),样本数据做归一化处理。
(1)
式中:Xi为归一化样本数据;X为初始样本数据;Xmax、Xmin分别为初始样本数据最大值、最小值。
3 预测模型构建
利用遗传算法优化极限学习机网络的输入权值和隐含层节点数,弥补极限学习机初始权值和隐含层节点数随机选取带来的缺陷,提高ELM模型的拟合精度。构建基于遗传算法优化极限学习机的水性环氧树脂改性乳化沥青黏结性能预测模型,具体步骤如下:
(1)对于已经归一化处理的输入样本X,根据式(2),计算隐含层神经元输出矩阵(H)。
H=g(WXT+b)
(2)
式中:W为输入层权值矩阵;b为隐含层阈值矩阵;g为隐含层神经元激活函数——“sigmoid”函数。
(2)根据式(3),计算ELM神经网络输出值(P)。
P=(HTβ)
(3)
式中:β为隐含层到输出层的权值矩阵,只要确定β即可唯一确定ELM神经网络。
(3)采用给定的训练输出样本(Y)替代神经网络输出值。β可以通过求解式(4)的最小二乘解获得。
(4)
(4)采用遗传算法寻找ELM的最优初始W和b。遗传算法通过适应度函数经选择、交叉和变异操作得到最小适应度值所对应个体。
(5)ELM经遗传算法优化后得到最优初始权值和阈值。设定隐含层节点个数,建立GA-ELM模型。
(6)按照式(5)~(7),误差判别标准采用平均绝对误差(Mean Absolute Error,MAE)、平均绝对百分比误差(Mean Absolute Percent Error,MAPE)和均方根误差(Root Mean Squared Error,RMSE)。利用测试集样本数据训练和评价GA-ELM模型。
(5)
(6)
(7)
式中:P为实际值;P′为预测值;n为测试样本数。
4 预测模型优化
4.1 ELM隐藏层优化
隐藏层数量的确定是ELM设计中最为关键的环节,隐藏层数量与求解问题要求、输入单元数有着直接关系。隐藏层数量过少,则模型精度和可靠性较差;隐藏层数量过多,则弱化训练后模型泛化能力。因此,基于测试集数据多次测试确定ELM预测模型较优的隐藏层数量,如图1所示。
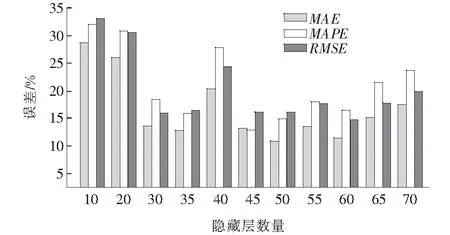
图1 ELM模型的隐藏层的优化结果
由图1可知:随着ELM模型隐藏层数量不断增加,MAE、MAPE和RMSE变化规律一致,均呈现出先减小后增大再减小再增大的趋势;隐藏层数量过少或过多时,各类误差均较大;当隐藏层数量为45~55时,误差较小。为了寻求隐藏层数量变化下各类误差极小值,多次测试隐藏层数量为45~55的误差值,结果如图2所示。
由图2可知:当隐藏层数量为45~55时,MAE和MAPE表现出先减小后增大的总体趋势;RMSE在隐藏层数量为47时出现突变值,但其总体趋势与前两者变化规律一致。当隐藏层数量为51时,MAE、MAPE和RMSE同时达到极小值,此时隐藏层数量最优。最终,确定ELM模型较优的隐藏层数量为51。此时MAE、MAPE和RMSE分别为9.77%、10.75%和12.33%,与隐藏层数量为10时相比,各类误差分别降低了65.86%、66.53%和62.83%。

图2 ELM隐藏层数量下的最小误差
4.2 GA参数优化
种群规模、终止代数、交叉概率和变异概率作为遗传算法的主要运行参数,在实际应用中,往往需要经过多次测试后才能确定出这些参数的合理取值范围。为简化训练过程,优化种群规模、交叉概率、变异概率和终止代数等参数。一般情况下,这4项运行参数建议取值范围分别为40~100、0.40~0.80、0.001~0.1和100~300。在此基础上,利用Matlab中Sheffield工具箱,多次循环测试确定遗传算法4项参数的较优数值,如图3所示。
由图3可知:随着GA的4项参数数值变化,相应误差值也呈现一定的变化规律。随着种群规模增大,误差值表现出先下降后上升的趋势,当种群规模达到40时,误差值达到极小值;误差值随交叉概率和变异概率的变化规律较为复杂,极小值分别存在于0.40~0.50和0.000 5~0.001 0之间;终止代数的增加引起误差值不断减小。结合算法测试情况,GA的种群规模、交叉概率、变异概率和终止代数的较优取值范围分别为40~50、0.40~0.50、0.000 5~0.001 0和400~500。此时,遗传算法部分已经较好地收敛至最优权值和阈值。由于其权值矩阵和阈值矩阵规模较大,其具体取值不再赘述。
5 GA-ELM模型验证
5.1 GA-ELM样本拟合
采用Pearson相关性检验方法验证GA-ELM模型的预测精度,计算测试样本真实值与预测值两者所拟合函数的判别系数R2,如图4、5所示。系统分析预测数据与实测数据的拟合优度,确定黏结拉拔强度的GA-ELM预测模型精度。

图3 GA算法参数优化结果

图4 GA-ELM模型预测精度

图5 GA-ELM样本拟合
由图4、5可知:测试集样本真实值与预测值非常接近。两者所拟合函数的相关系数R为0.998 6,大于0.8。表明预测值与实际值为强相关,预测模型的预测精度较高。另外,相应判别系数R2为0.999 3,接近于1。它表明GA-ELM预测模型在高预测精度的基础上还能保持较好的输出稳定性。
5.2 模型对比
为进一步验证GA-ELM模型的输出稳定性,分别采用BP模型、ELM模型和GA-ELM模型对该测试集20组样本数据进行预测。其中,经过多次仿真计算后,BP模型隐藏层数量设定为7,ELM模型隐藏层数量取为51。GA算法的种群规模、交叉率、变异率和终止代数分别设定为45,0.50,0.001和400。基于不同模型预测结果如图6、7所示。
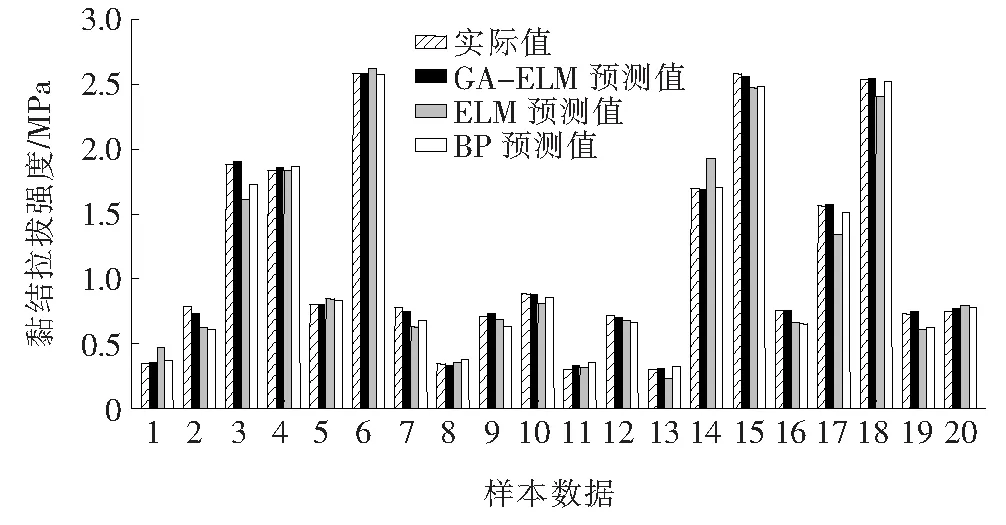
图6 不同模型黏结拉拔强度预测值
由图6、7可知:3种模型都取得了相应预测效果,但GA-ELM模型预测误差明显小于BP模型和ELM模型。GA-ELM模型的MAE、MAPE和RMSE分别为1.23%、1.76%和1.61%。与BP神经网络模型相比,GA-ELM模型的MAE、MAPE和RMSE分别降低了79.67%、78.74%和78.98%;与ELM模型相比,GA-ELM模型的MAE、MAPE和RMSE分别降低了87.41%、83.63%和86.94%。这表明与传统预测模型相比,GA-ELM模型在预测准确性和高效性等方面具有更好的优势。
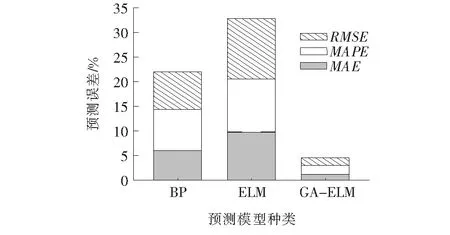
图7 不同模型预测误差
6 结论
(1)采用GA算法优化ELM模型,建立基于GA-ELM的水性环氧树脂改性乳化沥青黏结性能预测模型,预测了水性环氧树脂改性乳化沥青的黏结拉拔强度。
(2)GA-ELM模型预测水性环氧改性乳化沥青黏结拉拔强度具有较高的精确度,MAE、MAPE和RMSE分别为1.23%、1.76%和1.61%。与BP网络模型和ELM模型相比,误差降低78.74%~87.41%。
(3)GA-ELM模型为以后研究水性环氧树脂改性乳化沥青黏结性能提供了新思路,与原始ELM模型相比,遗传算法降低了GA-ELM模型的训练效率,因此在增加样本数据提高模型预测精度的同时,还需要进一步减少模型训练时间。
