基于卷积神经网络的手写汉字识别方法
2021-09-16肖婷婷
肖婷婷
(华东理工大学,上海201424)
随着中国工业4.0的到来,手写汉字识别HCCR应用变得广泛。1996年Nag和Casey使用的模板匹配法识别出1000个印刷体,引起了HCCR研究的热潮。高学等人在风险最小化准则上建立基于SVM的模型[1],并分析了识别手写汉字遇到的特殊问题。手写汉字具有随意的特点,和印刷体的规范差距甚远,采集合适的字体较困难,且字形复杂,有较多形似字。因此,传统HCCR流程中的预处理、特征提取效果不好,而CNN能够自动提取特征,适合处理非线性关系,对比而言是个好选择[2]。有其他研究者改进了CNN,如Graham等,针对较少的数据集提出了解决方案,进行了知识路径积分特征分析,充分利用了联机时笔画的时序信息,提高了准确率[3]。除CNN外,有其他深度学习的方法也获得了好的效果,DBN更适合处理一维的数据,需要预训练,这两方面均弱于CNN,在HCCR方面,CNN效果更好[4],因而有人提出了CNN和DBN结合的方法[5]。手写单字的技术已较成熟,但手写文本行依旧是难点,LSTM和RNN适合提取序列信息,解决难题可能性大。
1 数据集特点及预处理
本文采用的是CASIA-HWDB数据集,其中脱机部分比如版本1.0和1.1总共有至少7599个汉字,而minist只要处理10个阿拉伯数字,可见汉字识别的难度之大。
先将数据转成tfrecord格式,同时记录标签,图像,图像的长与宽。并且图片尺寸并不该作为变量输入到模型,故将所有图像都转为64×64像素。且图片的每一个像素点的范围是0~255,统一将其转为以0为中心,1为半径的分布,转为zero-centered数据,加快收敛,若输入全为正或负,导致梯度只往一个方向更新,阶梯状梯度会减慢收敛,会大大影响深度神经网络。
2 基于Keras的手写数字识别模型
Keras由Python编写,是tensorflow结合CNTK后端等的高层API,降低了tensorflow编写网络的难度,Keras会自行根据是否有支持的显卡切换CPU和GPU,有模块化、简单化、扩展性好的显著优点。支持神经网络的常见方法,比如数据的预处理,神经网络训练,评估和预测,支持Sequential模型和函数化模型。本文运用了层的堆叠Sequential模型,通过层的组合来搭建模型。Keras最大优点和开发重点,就是能快速搭建神经网络。
2.1 多层神经网络模型
多层神经网络模型(MLP)是包括输入层、隐藏层、输出层的前馈神经网络。MLP可看作一个有向图,每两个神经元之间连接的权重是边权,输入层接受特征的输入,整体是从输入层往输出层方向,直到传输到输出层。误差反向传播BP算法用权重梯度更新权重,而权重梯度根据输出层预测值和实际标签的偏差,利用链式求导法则求偏差对权重的导数,中间变量为隐藏层的各输出变量。
以一个神经元为例,若x为输入列向量,w为权重向量,b为偏置,y为输出,则:

其中M为x的行数,g(x)代表激活函数,有利于处理非线性的问题。激活函数的种类如表1。sigmoid导数大于0,最大为0.25,至少每一层会被缩小1/4,特别是当sigmoid输入过大或过小,导数趋于0,梯度减小快。导数涉及到幂的运算,深层网络耗时增加。输出数据非0中心,会导致后续梯度下降时呈现阶梯状。tanh的函数图像是中心对称的,但仍存在sigmoid另两个问题。relu正的输入数据的梯度为1,缓解了梯度消失的问题,不涉及幂运算,负数的梯度为0,降低了过拟合的可能性,但造成了一定可能性的梯度消失,因而提出了leaky relu等激活函数。

表1 不同的激活函数
2.2 CNN网络
本文构建网络主要思想是局部感受野,权重共享,池化三部分。局部感受野是使用一个卷积核和原图像部分(尺寸和卷积核的大小一致)进行卷积,此处涉及的局部区域,一个卷积核一次卷积只提取了部分区域的特征。而同一个卷积核以一定的步长值沿着x轴和y轴滑动,遍历了整个图片,代表图片的所有小区域共享一个卷积核,卷积核中的元素就是权重和偏移量。手写字识别只提取一种特征是不够的,提取不同特征就需要不同的卷积核,卷积核的数值不同,代表对某个区域的敏感度不同。而权重共享最大的优点就是大大减少了模型参数,减小了计算量,对深层网络更有利。池化是某个区域取最大值或者均等值将区域的信息转为一个数值,对卷积层的输出进行了简化。池化保留了区域相对整体的信息,但丧失了更精确的位置数据。
3 超参数的选择
使用tensorflow2.1框架,cuda10.1版本并行处理,cudnn7,英伟达GTX1050显卡运算。
batch_size设为512,训练81代,得出损失大小和训练集的准确率。使用softmax激活,将输出层的范围从(-∞,+∞)转为(0,1),是每个样本属于各类的概率。将某个样本的特征量作为输入,得到T个类别分别对应的概率,概率最大的类别作为预测标签。实验使用了一个batch的数据平均损失来反向传播,输出了准确率。类别使用onehot编码,只有下标为真实标签的值1,其他均为0,交叉熵作为损失指标。
错误预测比正确损失大,较大错误程度的预测比小的损失更大。网络总体是为了训练出权重矩阵和偏置,使尽量多的样本概率最大的类别是真实类别。模型的优化器选取了RMSProp,缓解了山谷震荡问题。山谷点的邻域内,即使横轴仍在往一个方向更新,但是纵轴却是来回震荡,甚至可能无法收敛,需要降低纵轴更新速度。w为权重,α为学习率,β为平滑系数,ε为极小值,公式如下:

β起平滑作用,震荡大的方向,s值大,步长减小,震荡小的方向则增加了步长。β通常用0.999,ε典型值为10-8。
4 预测结果和分析
分析图1得到,第一层卷积使用了relu激活函数的CNN模型起初损失函数减少快,epochs越大,损失函数降低得越平缓,最终收敛,训练集的准确率达到98.42%。激活函数换为sigmoid,损失函数呈现略微上升的趋势,迭代了81代后未收敛,准确率始终小于1%,出现了gradient vanishing现象。tanh激活函数下,收敛但在经过相同代数,比relu的损失大。一方面,sigmoid导数最大值为0.25,而tanh导数最大值为1,故使用sigmoid激活函数更易梯度消失。另一方面,relu正数输入的导数为1,比tanh多数情况大,故更快收敛。实验得到损失误差和准确率如表2,sigmoid损失最大,relu最小。
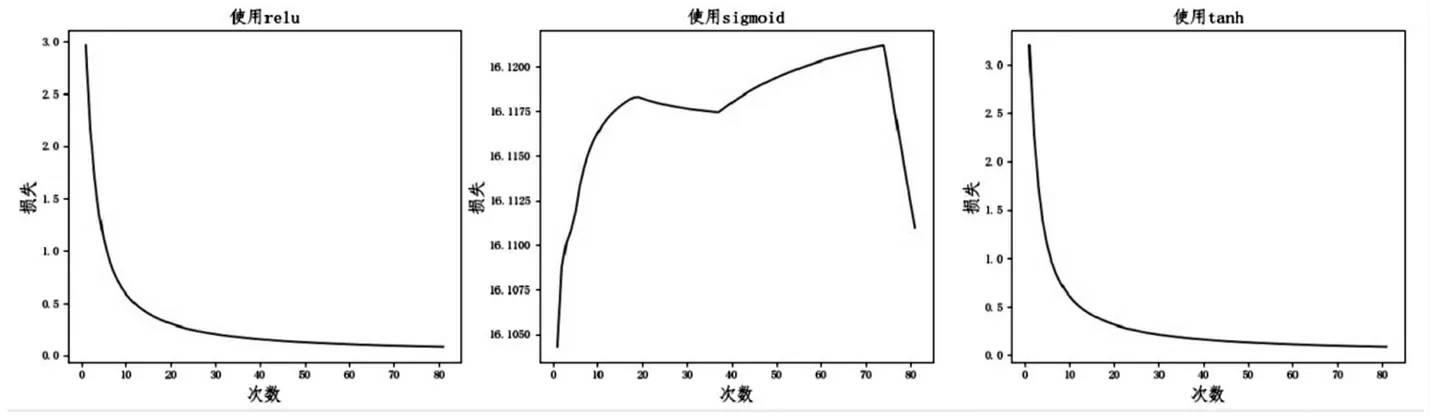
图1 使用不同激活函数的CNN网络训练过程
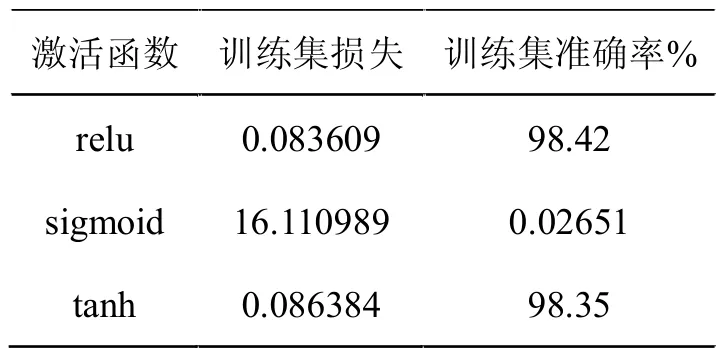
表2 激活函数效果对比
5 结束语
本文将HWDB1.1数据集预处理后,构建了一个简单而有效的卷积神经网络,使用softmax loss计算损失,模型优化使用RMSProp,根据第一层卷积层的不同激活函数,观察训练集的准确率。实验表明,relu激活函数在训练同等epochs下,分类效果最好。sigmoid易出现梯度消失的问题,可使用batch normalization,改用leaky relu等激活函数。
