基于误差补偿的中国区域加权平均温度模型研究
2021-09-13龙凤阳胡伍生杨雪晴
龙凤阳,胡伍生,杨雪晴
(1.东南大学 交通学院,江苏 南京 211189;2.南昌大学 共青学院工程技术系,江西 共青城 332020)
水汽是地球大气中一种高度可变的成分,在天气和气候系统中扮演着关键的角色。传统的水汽探测技术包括水汽辐射计、探空仪和卫星遥感等,由于分辨率的限制,它们已不能满足日益增长的气象应用需求。全球导航卫星系统(Global Navigation Satellite System,GNSS)探测水汽具有成本低、精度高、时空分辨率高、全天候工作等特点,比传统的水汽探测技术更具吸引力[1]。在地基GNSS遥感水汽中,将对流层天顶湿延迟(ZWD)转换为大气可降水量(PWV)时,大气加权平均温度(Tm)是影响转换精度的一个关键因素,当Tm的误差为±5 K时,通常会导致1.6%~2.3%的PWV估计误差。利用气象探空资料和再分析数据可以计算Tm,但气象探空资料的时空分辨率有限,而再分析数据本身也有不确定性。根据Tm与地表气温(TS)的关系构建Tm模型有助于提高ZWD-PWV反演的实用性和效率,Bevis等利用北美地区13个探空站8 718条大气垂直廓线数据,建立用于Tm估计的线性公式(Bevis模型)[2]。但利用一个统一的线性公式计算Tm既没有考虑地理位置的差异,也不能顾及Tm的季节性变化规律,为此国内外很多学者开展了Bevis模型的本地化研究,如龚绍琦通过分析中国区域Tm分布的时空特性建立了逐季节、分区域的线性回归模型[3],李建国等建立了适合中国东部地区使用的逐月Tm-TS模型[4],朱明晨等建立了适用于江苏区域的按年积日分段拟合的Tm-TS模型[5]。我国幅员辽阔,地形地貌复杂,气候系统变化多样,气象探空站点分布极不均匀,利用少数探空站点建立的Tm模型只能适用于某一区域,急需一个高精度的Tm模型来开展全国范围内的GNSS水汽遥感。神经网络在解决多输入参数非线性优化问题上具有很大的优势,笔者采用基于神经网络的误差补偿技术构建了一个适用于中国区域的Tm模型,提高了Tm的计算精度。
1 Tm的计算原理及其影响因素分析
1.1 Tm 的计算原理
Tm定义为沿天顶方向的水汽压(e)与绝对温度(T)的积分函数[2]。
(1)
气象探空站释放的探空气球最多可以提供20 km以上高度包括大气温度、湿度等的廓线数据,而地球大气的水汽主要分布在距地面高度12 km以下,因此可以利用探空数据通过数值积分法计算Tm,式(1)可以离散化为:
(2)
式中:ei,Ti,hi和ei+1,Ti+1,hi+1分别表示探空数据上下两层的水汽压、气温和高度值。
气象探空站的大气廓线数据都是经过实际测量的,经常被用来检验Tm模型的精度。此外,利用式(2)计算探空站的Tm值还需要对原始数据进行预处理,将异常值剔除。
1.2 Tm 的关联因素
Tm的变化既存在明显的周期特性,也有很强的空间分布特性[6],另外Tm与地表气象参数尤其是地表气温(TS)之间存在较强的相关性。因此,对Tm的建模可以从两方面着手:①考虑Tm的空间分布和季节性变化规律,建立格网化的经验模型,比较有代表性的是GPT2w模型[7];②考虑Tm与地表气象参数的相关性,建立线性回归模型,最具代表性的是Bevis模型。为更好地检验本文构建的融合模型的精度,采用中国及毗邻区域探空站2003—2013年的数据,按照15°N~25°N、25°N~35°N、35°N~45°N、45°N~55°N的纬度区间,根据算式Tm=a+bTS分别进行整体的线性回归拟合,得到各个纬度区间的回归系数,如表1所示。文中将表1中的Tm-TS关系式命名为LTm模型。
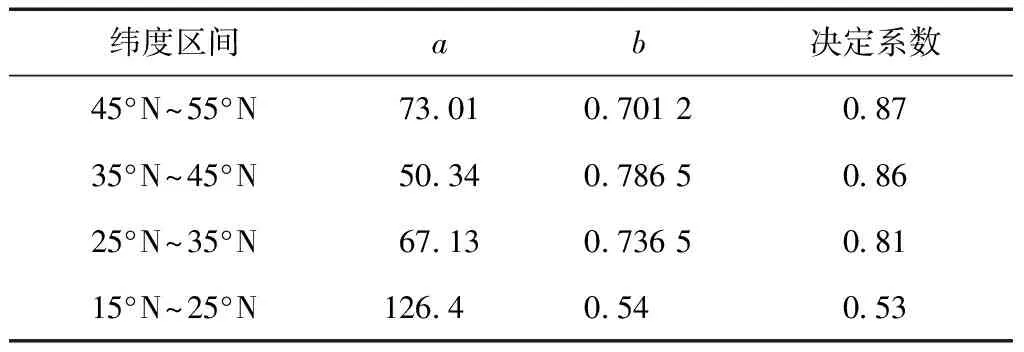
表1 不同纬度区间Tm-TS拟合系数及统计信息
从表1中各纬度区间的决定系数可以看出,低纬度地区Tm-TS的相关性很弱,纬度越高Tm-TS的相关性越强。但由于纬度较高的地区Tm随季节变化的幅度很大,使得在这一区域利用Tm-TS关系建立的模型精度较低,如何提高这些区域Tm模型的精度是目前很多相关研究者关注的问题,也是本文的研究目标。
2 基于误差补偿的Tm模型
2.1 GPT2w/IGPT2w模型
GPT2w模型是一个非常优秀的用于对流层延迟计算的经验模型,它同时还提供地表气温、温度递减率、大气压、水汽压、水汽衰减因子、加权平均温度等“副产品”。GPT2w计算Tm的基本模型可以表达为:
(3)
GPT2w模型考虑了加权平均温度的年周期和半年周期变化,并提供分辨率分别为1°×1°和5°×5°(纬度×经度)的两套网格形式的模型参数Ai(i=0,1,2,3,4),这些参数都是通过ECMWF的再分析数据计算得到的,用户只需提供年积日、纬度、经度就可以计算Tm值[7]。
但GPT2w模型没有考虑高程对Tm计算结果的影响,在实际使用时存在较大的误差。文献[8]研究中国区域的Tm随高度的变化规律,通过引入一个随季节变化的高程递减率因子(γ)先对GPT2w模型计算的4个格网点的Tm进行改正,再采用双线性内插至目标点位置,其中格网点的高度改正式为:
社区学习共同体是指社区居民基于共同的兴趣爱好及学习需求,以自主、协商、交流、融通、共享为基本特征而形成的一种自我学习、自我管理、自我服务的自组织[3]。社区学习共同体具有社会资本属性,是社会资本的天然集合体和承载者。其社会资本属性呈现如下特点。
(4)


表2 中国区域GPT2w模型的高度改正系数
2.2 基于误差补偿的Tm 融合模型的构建
GPT2w和IGPT2w-1模型是利用ECMWF的再分析资料建立的,它们能够较好地反映Tm的空间和季节变化规律。再分析资料虽然融合了探空站的数据且能够反映气象参数的时空变化规律和趋势,但我国复杂的地形地貌和多变的气候系统使得再分析数据与实测资料相比存在较大的不确定性[9],IGPT2w-1模型计算的Tm与实际观测积分得到的Tm相比在部分区域仍存在较大误差。另外,文献[10]从Tm的定义出发证明了Tm-TS的非线性关系,利用线性方程建立的Tm模型同样也存在较大的误差。
任何数学模型都可能存在一定的模型误差,对模型误差进行补偿可以使模型更好地逼近函数关系真值。神经网络技术在进行模型误差补偿时,不受人为假定函数关系的约束,可以克服传统补偿方法的局限性,已经被广泛应用于模型优化中[11]。本文利用基于神经网络的模型误差补偿技术,融合IGPT2w-1模型和实测地表气温等信息,构建适用于中国区域的Tm模型。建模步骤如下:
1)IGPT2w-1模型误差的计算。输入纬度、经度、高度、年积日等参数,利用IGPT2w-1模型计算Tm_IGPT2w,并根据气象探空资料的实测数据积分得到的Tm_obs计算模型误差。
ΔTm=Tm_obs-Tm_IGPT2w.
(5)
2)模型结构的确定。考虑到Tm和地表气温TS之间较强的相关性,文中采用地表气温(TS)、年积日(DOY),目标点的纬度、经度、高程和IGPT2w-1模型值(Tm_IGPT2w)作为输入参数,以模型误差ΔTm作为输出,构建融合模型,模型结构如图1所示。
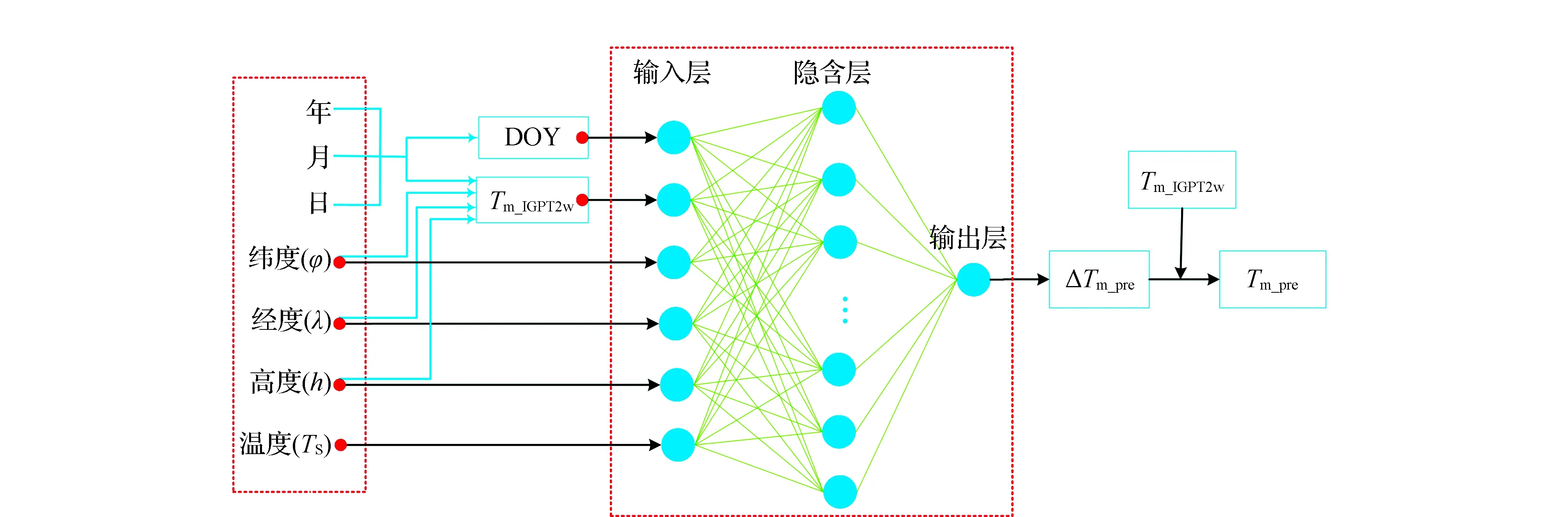
图1 融合模型的网络结构
3)数据集的准备。模型的建立需要数据驱动,本文建立融合模型共采用了中国及毗邻区域的80个气象探空站2003—2013年的数据,计算了307 002条大气垂直廓线的Tm值。训练前必须先进行归一化处理。分布在中国境内的其余74个站的数据被用来检验模型精度。训练站点和测试站点的分布情况如图2所示,由于我国青藏高原地区气象探空站点的分布较为稀疏,为了保证融合模型中“测站高度”参数的正常使用,将位于青藏高原的CHM00055299号站的数据既用作训练,也用于验证模型精度。
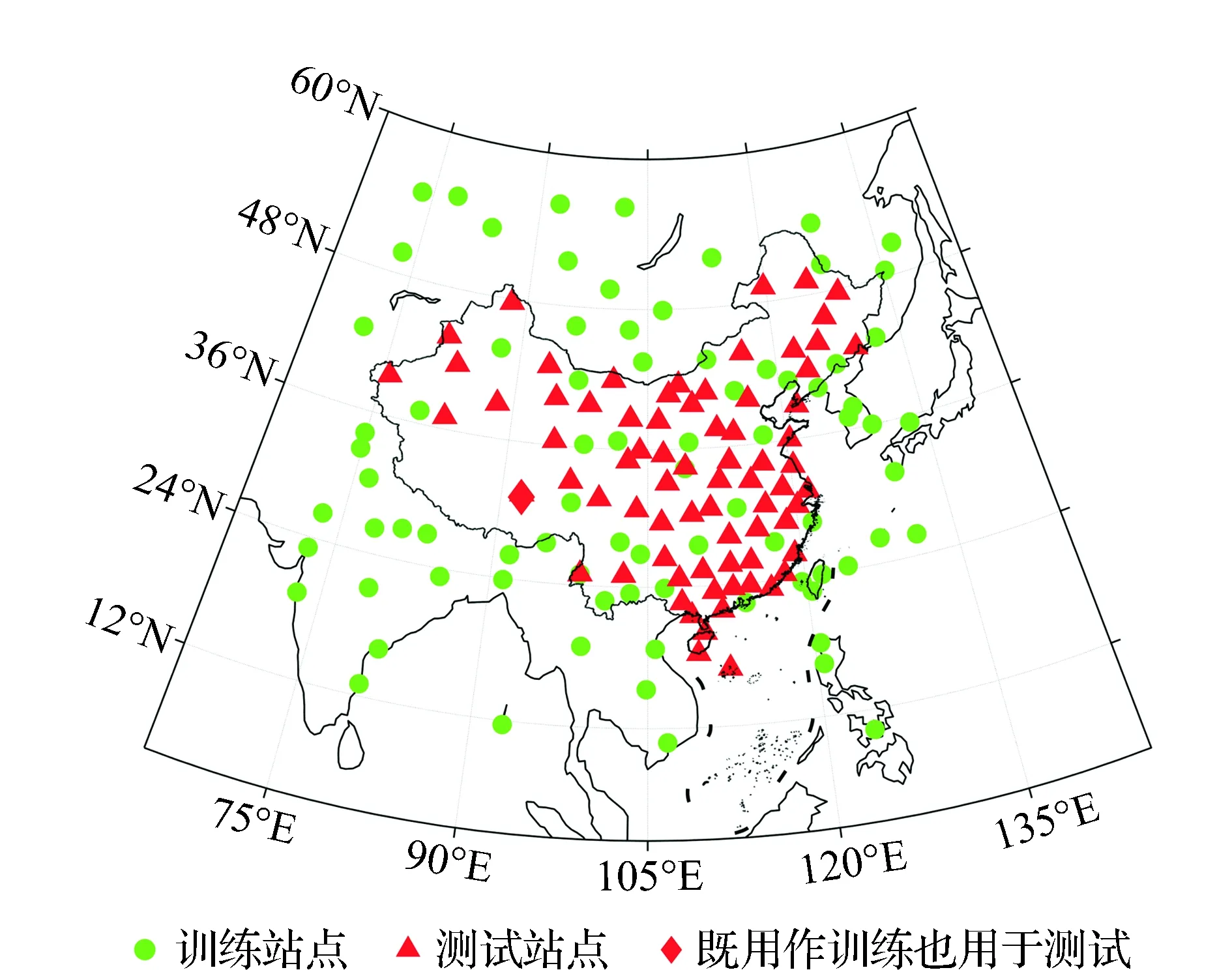
图2 训练站点和测试站点分布

5)模型的参数化表达。经过神经网络训练可以得到输入层与隐含层的连接权值W(1)和偏置b(1),以及隐含层到输出层的权值W(2)和偏置b(2),最终融合模型的参数化表达式为:
(6)
(7)
其中,m,n表示输入层神经元个数和隐含层神经元个数。ΔTm_pre是神经网络预测的模型误差值,Tm_IGPT2w是IGPT2w-1模型的计算值。训练好的权值和偏置参数可以直接提供给用户使用,用户只需输入纬度、经度、高程、年积日、地表气温就可以计算相应的Tm值,本文将融合模型命名为CTm。
3 模型精度检验
神经网络的最优网络结构通常需要经过一系列的敏感性测试才能最终确定,本文将隐含层神经元个数设置为4~15个分别进行训练,采用平均偏差误差(MBE)、均方根误差(RMSE)、相关系数(R)和散射指数(SI)评价CTm模型各个网络结构的性能。
(8)
(9)
(10)
(11)
本文提取了中国区域74个气象探空站点2014—2018年共5年的数据进行验证,这些站点与建立融合模型采用的训练站点的位置和时间节点不同,共计算了207 871条大气垂直廓线从地表附近至对流层顶积分的Tm值。得到CTm模型各网络结构的性能指标如图3和图4所示。

图3 各网络结构的MBE和RMSE值

图4 各网络结构的R和SI值
由图3和图4可以看到,当隐含层神经元个数为7~14个时,模型的性能较为稳定,MBE均在-0.2~0 K之间,RMSE值也均维持在3.3 K左右,相关系数在0.952左右,散射指数保持在0.012以下;但当隐含层神经元个数在6个以下或14个以上时,模型的性能表现欠佳。因此,隐含层神经元个数可以取为7~14个。为了降低模型复杂度,以及避免因隐含层神经元个数过多带来的“过拟合”风险,文中将隐含层神经元个数设置为7个,这样就确定了一个6×7×1的网络结构。
为了进一步检验模型精度,将文中建立的融合模型(CTm模型)与IGPT2w-1、Bevis和LTm模型进行对比分析。表3列出了4个模型的精度统计情况。
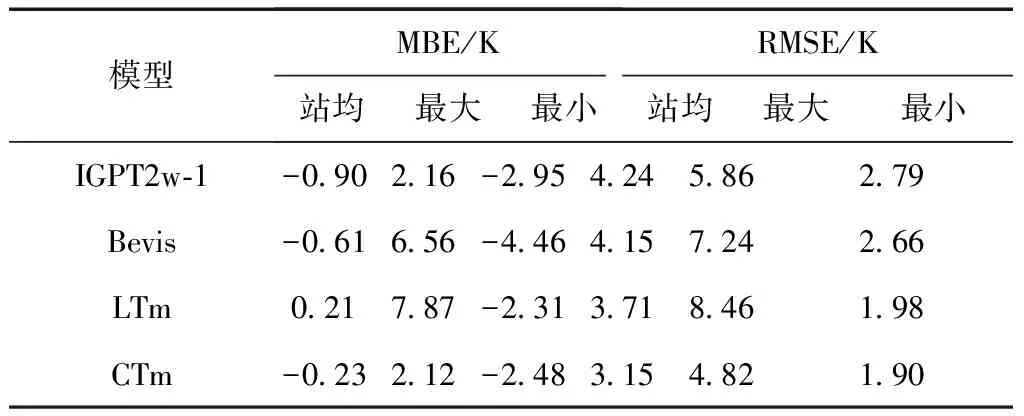
表3 各模型精度对比
由表3可以看到,LTm和CTm的平均偏差均较小,其中CTm模型的MBE最大为2.12 K,优于其他3个模型,最小为-2.48 K,优于IGPT2w-1和Bevis模型;从RMSE来看,4个模型中,CTm模型的各站点平均RMSE最小,仅为3.15 K,分别比IGPT2w-1、Bevis、LTm模型提高了26%、24%和15%,最大RMSE也比其他3个模型更小。为进一步分析融合模型在不同地理位置的精度,绘制了74个探空站点的MBE和RMSE分布,如图5和图6所示。
由图5和图6可以看到,CTm和IGPT2w-1模型的MBE分布表现最好,而Bevis和LTm模型在我国的西北部地区存在较大的偏差,这一区域海拔较高,地形地貌复杂,不考虑地面起伏而只顾及Tm-TS关系的模型在这一区域偏差较大。另外,Bevis模型在中国的东南部区域表现出较大的负偏差,进一步说明了Bevis模型在中国区域的不适用性。从RMSE来看,CTm模型在4个模型中表现出了最好的性能,即使在西北部地区也能达到4 K以下,相反IGPT2w-1模型在新疆-内蒙古-东北一线的精度较差,RMSE基本在5 K以上,Bevis和LTm模型在这一区域的表现也欠佳。此外,Bevis和LTm模型没有顾及高程的影响,在青藏高原上的3个海拔较高的站点均存在较大的误差。图7进一步列出了4种模型在不同纬度区间的MBE和RMSE值。

图5 测试站点MBE分布
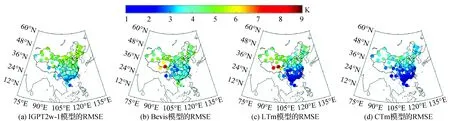
图6 测试站点RMSE分布

图7 不同纬度区间各模型精度对比
由图7可以看到,LTm和CTm模型的MBE在各个纬度区间都很小,而Bevis模型在中国区域的15°N~30°N之间存在很大的负偏差,IGPT2w-1在45°N以下平均偏差为 -1 K左右;再比较RMSE,CTm模型在各个纬度区间均表现出最佳的性能,在15°N~30°N之间的低纬度地区,LTm与CTm的RMSE相差不大且均比IGPT2w-1和Bevis小,但在30°N~50°N的纬度区间内,CTm和LTm的差距开始变得明显,CTm相比LTm精度有了很大提高。
4 结果和讨论
文中利用中国及毗邻区域80个气象探空站点2003—2013年的数据,建立了一个适用于中国区域的基于神经网络模型误差补偿技术的Tm融合模型,利用中国区域其余74个探空站2014—2018年的数据进行验证,并与其他3种模型对比,得出结论如下:
1)Bevis模型在中国区域存在较大的偏差,基于Tm-TS关系建立的本地化线性拟合模型相对Bevis有更好的表现,尤其是在30°N以下的低纬度地区;
2)基于Tm-TS关系构建的本地化线性拟合模型比格网化的经验模型(IGPT2w-1)更有优势,但这一优势在30°N~40°N区域范围内并不明显;
3)融合模型综合考虑了地理位置、季节对Tm的影响,以及地表气温与Tm的相关性,并借助了神经网络强大的非线性映射能力,模型精度相比其他3种模型都有大幅度提高,比IGPT2w-1、Bevis和LTm模型分别提高了26%、24%和15%,而且在中国西北部地区的Tm估计精度得到了明显的改善。
文中只基于中国及毗邻区域的数据集构建了一个统一的适用于中国区域的Tm模型,但这一方法同样也可适用于全球。由于全球的地形地貌和气候系统更为复杂多样,在下一步工作中,可对全球区域划分网格,每个网格训练一套参数进而构建一个全球适用且顾及Tm-TS复杂关系的融合模型。
