一种新颖的混沌动态团队博弈算法
2021-09-08胡红萍邹娜娜马利兵
胡红萍,邹娜娜,马利兵,史 娜
(中北大学 理学院,山西 太原 030051)
0 引 言
现实世界的很多领域存在很多优化问题, 例如统计物理学[1]、 计算机科学[2]、 人工智能[3]、 模式识别[4]等. 对于优化问题,传统的优化技术难以找到全局最优解,例如爬山(Hill-Climbing)、 随机搜索(Random Search)和模拟退火(Simulated Annealing,SA)[5]等. 元启发算法的提出给优化问题提供了解决问题的一种思路. 遗传算法(GA)[6-7]是1992年由Holland提出的利用染色体和基因寻找全局最优解的第一个进化算法. 粒子群优化算法(PSO)[8-12]是1995年由Kennedy等人提出的模拟鸟类觅食的社会行为用以找到全局最优解的优化算法. 正余弦算法(SCA)[13-14]是2016年由Seyedali Mirjalili提出的一种新的基于群体的优化算法,用于解决优化问题,初始化种群,并使用基于正弦和余弦函数的数学模型向外或向最佳解波动. 人工树算法(AT)[15-16]是2017年由Li等人提出的模拟树的生长规律提出的一种基于种群的算法. 这些启发式算法还有例如人工鱼群算法[17]、 果蝇优化算法[18-19]、 飞蛾扑火优化算法[19]和鲸优化算法[20-21], 但这些算法不能解决所有的优化问题.
学者们对这些元启发算法不断改进,通过优化人工神经网络的参数构建多种模型来解决各种实际问题,例如:改进的指数递减惯性权重的PSO优化径向基神经网络来实现空气指数的预测[9], 基于改进的动态PSO和AdaBoost算法优化广义回归神经网络来实现上证指数的预测[10],混沌的动态加权PSO[12]用于函数优化,且克服了早熟收敛和易陷入局部最优解的缺点,在鲸优化算法中引入了混沌理论,提高了全局收敛的速度,获得了更好的性能[22].
2018年提出的团队博弈算法(Team Game Algorithm,TGA)[23]是一种基于竞赛策略的元启发优化算法,这些竞赛策略包括足球、 排球、 篮球、 水球等. 本文在TGA中引入了混沌参数以强化TGA的性能,这样就得到了混沌的动态TGA,记为CDTGA. 通过10个基准函数验证CDTGA的性能,并将CDTGA与BP神经网络(BPNN)相结合建立预测美国流感样疾病(Influence-Like Illness, ILI)的预测模型CDTGA-BPNN,并将CDTGA与PSO, SCA, AT和TGA进行了比较,且将CDTGA-BPNN与BPNN, PSO-BPNN, SCA-BPNN, AT-BPNN和TGA-BPNN进行了比较.
1 团队博弈算法
团队博弈算法(Team Game Algorithm, TGA)[23]是2018年由M.J. Mahmoodabadi等人提出的一种基于竞赛策略的元启发优化算法. 在TGA中,球员是个体的角色,他们的表现将通过耐力来衡量,耐力用优化方法中的适应度来表示. 个体包括两队的球员,并相互联系. 队友之间的合作是为了争取进球. 耐力越强的球员在球场上呆的时间越长,也越有可能一直呆到比赛结束.
在TGA中,每个个体包括三类算子:传球、 犯规和替补,其中传球是一种逻辑算子,犯规是一种随机算子,替补是在疲惫的队中所采用的算子. 一个队只有通过传球才有希望赢得比赛,比赛中的最优球员也有可能在输了的队中.
在搜索空间中,任意给出n个球员为
式中:xi是第i个球员;D是xi的维数.

A={x1A,x2A,…,xnA},
(1)
B={x1B,x2B,…,xnB}.
(2)
显然,A∪B=X. 替补队员的个数是任意的,他们坐在替补座位等待教练的命令进行替补.
球任意给了一个队,在比赛中执行三种算子:传球、 犯规和替补.
1) 传球算子
传球算子定义为
xi(t+1)=xi(t)+γCi(t+1),
(3)
Ci(t+1)=2xcap(t)-Ci(t)-xrand(t),
(4)
式中:xi(t)为东道主队中的第i个球员的位置;C为拿球的球员、 任意球员xrand(t)和队长xcap(t)之间的交流方式;γ是分量在 [0,1]内的任意数的向量.
2) 犯规算子
犯规算子是球员的错误,只有当概率条件满足时才执行. 在这个算子中,拿球的球员与对方球队的球员相互接触. 这种接触的结果是改变拿球球员的分量,公式为

(5)

3) 替补算子. 在迭代过程中通过检查球员的适应度引进替补算子. 如果在一定的迭代次数内球员的适应度没有得到改进,该球员被新的替补球员替换,替补球员参加比赛.
另外,检查拿球的球员的位置. 一旦他离开了比赛场地,该位置将被重置为任意向量.
在TGA的结构中,球员观察彼此的性能,从他们犯规算子中进行学习以改进其适应度; 替补算子的作用是阻止算法陷入局部最优值.
2 混沌动态TGA
将动态参数引入到TGA中,得到动态的TGA,记为DTGA.


(6)
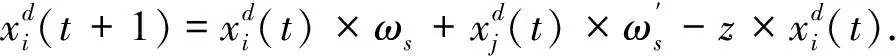
(7)


(8)

(9)
式中:s是第s次迭代;Maxgen是最大迭代次数. 因为动态参数是在混沌理论的基础上选择的,因此,将DTGA称为混沌的动态TGA, 记为CDTGA.
3 实 验
3.1 函数优化
本节所选用的10个基准函数见表1.

表1 10个基准函数
表1 中列出了7个单峰函数f1,f2,f3,f4,f5,f6,f7和3个多峰函数f8,f9,f10的名称、 数学表达式、 变量的范围和最小值.
为了验证CDTGA的有效性,选取PSO,AT,TGA作为比较算法. 这四种算法中,最大迭代次数为4 000或10 000,种群大小为50,每个函数的变量的个数n=30. PSO 的惯性权重选取CDTGA的动态参数ωs.
在TGA和CDTGA中,执行替补算子满足的条件是迭代2 000次适应度没有变换. 分别独立运行PSO,AT,TGA和CDTGA各30次,得到的数值结果如表2 和表3 所示.

表2 10个基准函数在最大迭代次数为4 000时的数值结果
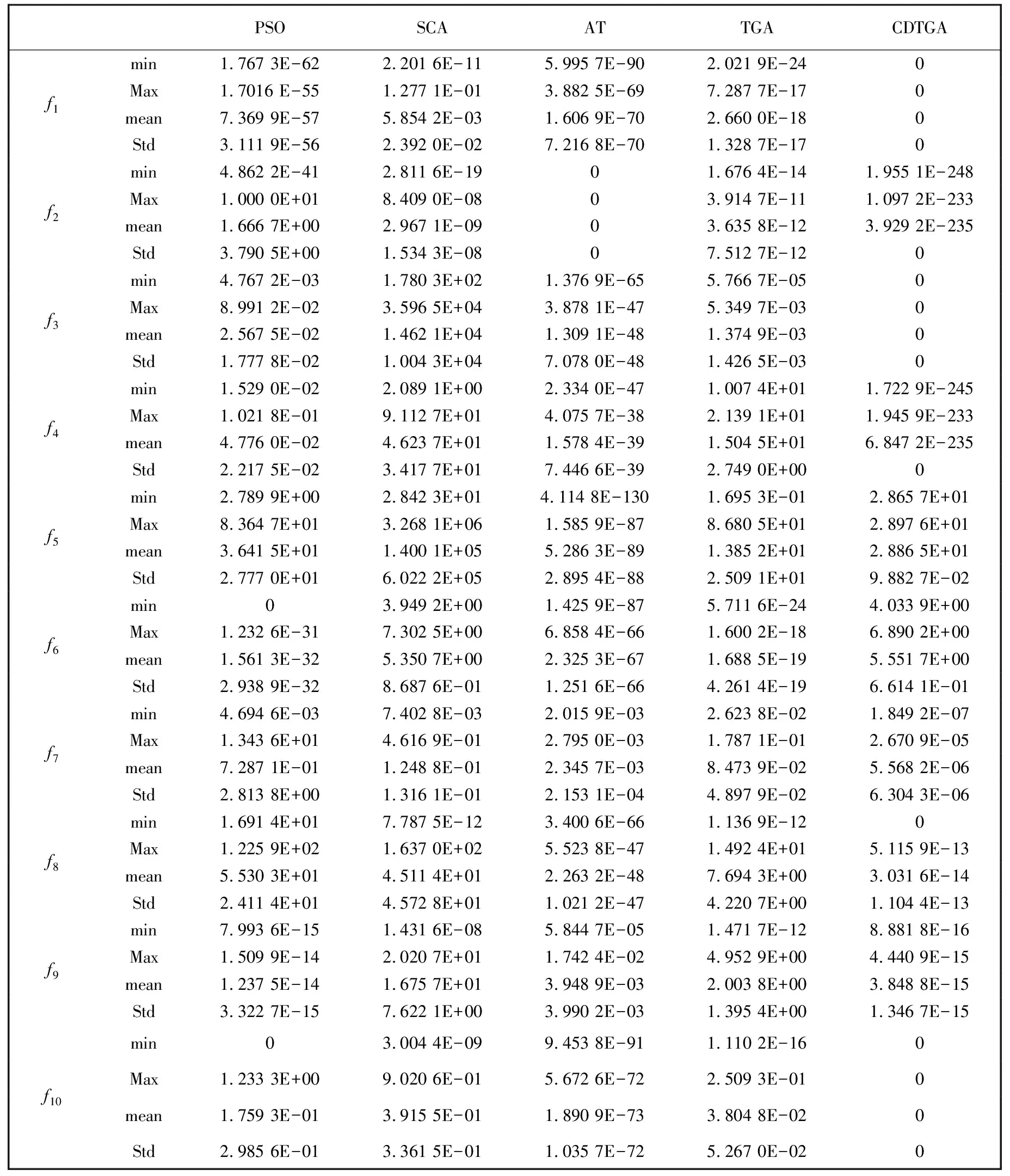
表3 10个基准函数在最大迭代次数为10 000时的数值结果
表2 和表3 列出了30次运行结果的最小值、 最大值、 平均值和标准差. 由表2 和表3 可以看到,CDTGA得到的f1,f3,f4,f7,f8,f9和f10的最小值、 最大值、 平均值和标准差均不超过PSO,SCA,AT和TGA得到的最小值、 最大值、 平均值和标准差. 两个表的比较结果表明,本文所提出的CDTGA优于PSO,SCA,AT和TGA,且改进了TGA,是一种较好的算法.
3.2 基于CDTGA优化的BP神经网络的流感样疾病预测
3.2.1 预测模型

在网络训练过程中将预测值与实际值之间的均方根误差(Mean Square Error, MSE)作为CDTGA-BPNN的适应度函数,定义为

(10)

3.2.2 数据
本文所采用的美国CDC流感样疾病的数据是从网站https://gis.cdc.gov/grasp/fluview/fluportaldashboard.html下载的,这些数据包括由健康与公共事业(Health and Human Services,HHS)定义的10个区从2002年第40周到2017年第36周的780周的数据.
在利用CDTGA-BPNN预测CDC的流感样疾病之前,需要将这些流感样疾病预处理为区间[-1,1]中的值,处理方式为
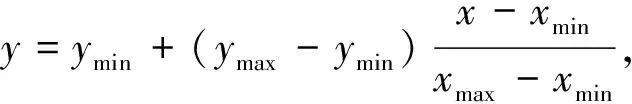
(11)
式中:x为预处理之前的原始数据;xmin和xmax分别为预处理之前原始数据的最小值和最大值;y为预处理后的数据;ymin和ymax分别为预处理之后原始数据的最小值和最大值.本文中,ymin=-1,ymax=1.
本文考虑了美国CDC定义的10个区的未加权的%ILI,选取前5周未加权的%ILI预测第6周的未加权的%ILI,预测模型的评价标准为均方误差(Mean Squared Error, MSE)[8], 相对均方误差(Relative Mean Squared Error,RMSE)[8],平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)[8].

(12)

(13)

(14)
3.2.3 模型
本节选取从2002年第40周到2017年第36周的780周的未加权的%ILI 数据,利用前5周的未加权的%ILI预测第6周的未加权的 %ILI. 这样就获得了779个5维向量. 将这779个向量最初90%的向量作为训练样本,剩余的向量作为测试样本.
所建立的BPNN的结构为p-m-r,其中p是输入向量的维数,m是隐含层神经元的节点个数,r是输出层神经元的个数.本文中p=5,r=1.经过大量的实验,选取m=10,最大迭代次数为5 000,动量因子为0.95, 学习率为0.002. 为了与CDTGA-BPNN作比较,本文分别选取PSO,SCA,AT和TGA优化BPNN 的参数,得到模型: PSO-BPNN, SCA-BPNN, AT-BPNN和TGA-BPNN. 将这5种模型独立运行10次. 模型PSO-BPNN, SCA-BPNN, AT-BPNN, TGA-BPNN和CDTGA-BPNN的BPNN部分的参数设置与BPNN的参数设置相同. PSO, SCA, AT, TGA和CDTGA的种群大小为50,最大迭代次数为500. 模型PSO-BPNN中,惯性权重选取如式(8)所示.
3.2.4 预测结果
首先利用式(11)将原始数据处理成标准数据. 对于上述选择的参数,利用训练样本训练BPNN, PSO-BPNN, SCA-BPNN, AT-BPNN, TGA-BPNN和CDTGA-BPNN,得到测试样本的输出,通过反归一化得到测试样本的预测值,并得到每个模型的评价指标MSE,RMSE和MAPE. 每种模型独立运行10次,得到测试样本的平均MSE, RMSE和MAPE,如表4 所示.
表4 列出了10个区的预测值与实际值之间的平均MSE,RMSE和MAPE. 通过比较可以发现,本文所提出的模型CDTGA-BPNN优于模型BPNN,PSO-BPNN,SCA-BPNN,AT-BPNN和TGA-BPNN. 从表4 可以看到, CDTGA-BPNN 在区1~区6和区8具有最小的平均MSE,RMSE和MAPE,区1~区6和区8具有最小的MSE,分别为0.039 2, 0.129 6, 0.128 8, 0.163 5, 0.068 6, 0.108 6, 0.041 5; 区1~区6和区8具有最小的RMSE,分别为0.031 1, 0.013 8, 0.014 9, 0.019 8, 0.015 6, 0.016 0, 0.034 8; 区1~区6和区8具有最小的MAPE,分别为13.899 8%, 9.298 2%, 9.879 8%, 11.692 9%, 10.298 4%, 9.336 8%, 13.327 8%,说明模型CDTGA-BPNN适合这7个区的未加权的%ILI预测. 但PSO-BPNN适合区9 的未加权的%ILI预测,具有最小的平均MSE=0.039 2,MSE=0.011 5,MAPE=8.550 5%. 对于区7, PSO-BPNN是具有最小平均RMSE的模型, AT-BPNN是具有最小MSE的模型,TGA-BPNN是具有最小MAPE的模型. 对于区10, PSO-BPNN是具有最小平均MSE的模型, TGA-BPNN是具有最小RMSE和MAPE的模型.

表4 10个区测试样本的平均MSE,RMSE和MAP
为了综合考虑所提出模型的性能,我们将这10个区的MSE,RMSE和MAPE取平均作为整个美国未加权的%ILI的MSE,RMSE和MAPE,如表5 所示. 从表5 可见,CDTGA-BPNN的MSE=0.100 5,RMSE=0.070 7和MAPE=15.190 4%,低于其它比较的模型BPNN, PSO-BPNN, SCA-BPNN, AT-BPNN和TGA-BPNN的MSE,RMSE和MAPE, 表明CDTGA-BPNN优于BPNN, PSO-BPNN, SCA-BPNN, AT-BPNN和GTA-BPNN.

表5 整个美国测试样本的平均MSE,RMSE和MAPE
4 结 论
本文在团队博弈算法的基础上提出了混沌的动态团队博弈算法CDTGA,通过10个基准函数验证了CDTGA的有效性. 为了克服BPNN初始权值的任意性,将CDTGA与BPNN相结合建立了预测模型CDTGA-BPNN来预测美国CDC未加权的%ILI. 比较结果表明,模型CDTGA-BPNN优于模型BPNN, PSO-BPNN, SCA-BPNN, AT-BPNN和TGA-BPNN,CDTGA适合找到函数的全局最优解且适于与BP神经网络相结合预测流感样疾病,由此可得到一些启示:群智能算法能够求解优化问题,并可与不同的神经网络相结合实现预测和分类. 另外,可以提出更多新的或改进的算法,并与人工神经网络相结合以应用于更多领域.
