基于正常域名及其可信度的DGA检测方法
2021-09-08卫清才宋礼鹏
卫清才,宋礼鹏
(1. 中北大学 大数据学院,山西 太原 030051; 2. 中北大学 大数据与网络安全研究所,山西 太原 030051)
0 引 言
随着联网设备增多,采用域名生成算法(Domain Generation Algorithm, DGA)作为通讯机制的僵尸网络规模和危害不断扩大,因此如何有效检测DGA域名成为打击僵尸网络的重要方向[1]. 现有DGA检测模型虽然已经在二分类任务中有较高的精确率,但在实际应用中仍存在两点不足. 首先,训练必须依赖于正常域名和DGA域名,而DGA域名数据获取困难、 有效期短,因此,模型更新滞后,可用性低. 其次,现有模型只能检测训练集中使用的DGA域名家族,对未知类型的DGA家族检测效果很差,这是因为模型在训练过程中需要学习训练数据的特征,因此,必定会深度拟合训练集所含的DGA域名家族,进而丧失对其他未知DGA域名家族的检测能力[2-6].
本文针对以上问题提出一种仅利用正常域名及其可信度作为训练数据且能有效识别未知DGA域名家族的检测模型ProfDGA. 该方法的核心思想是让模型仅学习正常域名的特征,这样模型泛化性能就不受限于DGA域名的特征,进而使模型具备发现新型DGA家族的能力. ProfDGA通过对经验风险函数的变形,将训练时损失函数中与DGA域名相关的变量用正常域名及其可信度替换,这样模型就可以在不直接依赖DGA域名数据的条件下完成训练,仅直接学习正常域名特征,这本质上是将分类问题转化为异常检测问题.
1 相关工作
通过在僵尸主机与C&C服务器上运行相同的域名生成算法产生大量随机的域名,然后C&C服务器从生成的域名集合中选择一个域名子集注册为C&C服务器地址,而僵尸主机通过遍历整个域名集合来确定C&C服务器地址,实现数据传输,这种技术被称为Domain-Flux机制. 通过上述机制,僵尸网络的C&C服务器可以动态更换域名地址,在绕过了黑名单防御机制的同时隐藏了真实的IP地址,确保了整个网络的连通和可控[7]. 鉴于DGA域名在僵尸网络中的广泛应用,及其在僵尸网络检测分类中的重要意义,安全研究人员已经对DGA域名检测进行了深入的研究.
为了躲避监管并防止他人通过抢注域名的方式劫持网络,DGA域名的有效时间短,变化速度快. 正是由于DGA域名这一特性,所以模型检测新型DGA家族的能力有更为重要的价值. 依据文献[8],在有数据可查的43种DGA家族中16个家族的有效时间小于3 d,有5个DGA家族的域名时效长度为7 d~30 d,仅有Gozi,Pushdo两个DGA家族的域名有效时长大于30 d,具体的域名有效时长分布如图1 所示.

图1 域名有效时长分布
DGA域名检测按照所用原始数据的不同可以分为两大类:基于域名关联特征的检测和基于域名自身特征的检测.
基于域名关联特征的检测主要是结合域名的注册记录、 结构特征、 DNS记录等多维度的数据进行关联分析. Samuel Schüppen等[2]提出了一种基于随机森林的分类模型FANCI. 他们从NXDomain记录及正常域名中提取域名的结构特征、 字符统计特征、 语言学特征、 响应信息等多维数据来训练模型. FANCI模型在实验数据集上的准确率为99.93%,在真实数据集上的最高误报率仅为0.064%. Ryan R. Curtin等[3]通过smashword评分来衡量DGA域名所含单词与英文单词的相似度. 他们利用smashword评分并结合域名注册信息训练出了基于RNN(Recurrent Neural Networks)的DGA域名检测模型,该模型对于最难识别的matsnu_dga家族的检测准确率为95%,误报率为0.5%.
基于域名自身特征的检测是通过挖掘域名中包含的深层信息来区分正常域名与DGA域名. Jonathan Woodbridge等[4]首次将LSTM网络应用于DGA域名检测模型. Woodbridge将训练数据预处理后输入词嵌入层进行向量化表示,然后通过一个深层的LSTM网络来拟合DGA域名和正常域名的特征,最后通过sigmoid层输出样本为正常域名的概率. 该模型在DGA域名二分类任务中有较好的表现,AUC值达到了0.9993,但其对基于词表组合类型的DGA域名检测效果较差. Highnam K等[5]针对文献[4]模型的缺陷,提出了一种基于Bagging思想、 通过组合CNN模型和LSTM模型的集成深度模型Bibo. 该模型并行训练两个深度学习模型并采用Bagging方式将其融合起来实现了对基于词典的DGA家族的有效检测. 经过对真实网络流量的分析,该模型发现了5个商业检测工具都未能识别的DGA域名. Namgung J等[6]则提出了带注意力机制的基于CNN+BiLSTM模型的检测模型. 该模型通过一维卷积层代替了域名嵌入表示的过程,并利用注意力机制和双向BiLSTM模型同时学习DGA域名序列双向的特征信息,最终达到了0.966 6的F1值.
综上所述,现有模型虽然已有较好的检测效果,但都是针对训练所用的DGA家族,没有考虑对未知DGA家族的识别能力. 然而在实际网络中,DGA域名种类多、 变化快、 有效时间短,因此,模型识别新型DGA家族的能力有更高的实用价值,更能有效打击DGA域名.
2 ProfDGA模型
为了增强模型的泛化性能,本文的核心思路是降低DGA域名对模型训练的影响,即如何在尽量保证模型性能的基础上,减少训练集中的DGA域名数据,甚至仅利用正常域名完成模型训练. 为了解决这一问题,本文提出了基于LSTM网络并采用Positive-Confidence框架训练的DGA域名分类模型ProfDGA.
2.1 Positive-Confidence框架
针对数据集极度不均衡情景下负样本太少,模型训练不可靠的问题,Takashi Ishida等[9]提出了一种改进的经验风险最小化框架,并将其应用于MNIST图像分类任务.
在Positive-Confidence框架中,假设样本数据为d维向量x∈Rd,样本类别标签为y∈{-1,+1},数据服从未知分布p(x,y).现在要训练一个分类模型g(x),使得经验损失R(g)最小化,其定义为
R(g)=Ep(x,y)[l(yg(x))],
(1)
式中:l(yg(x))是损失函数;Ep(x,y)表示基于p(x,y) 的期望.将R(g)展开得到

(2)
式中:p(x|y)表示随机变量x基于y的分布.将R(g)进一步变形可以得到
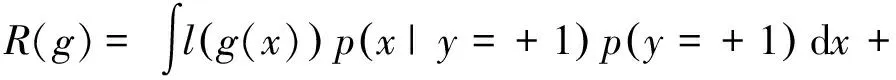

π+E+[l(g(x))]+π-E-[l(-g(x))],
(3)
其中,
π+E+[l(g(x))]=

π-E-[l(g(x))]=

式中:π-表示p(y=-1);E-表示Ep(x|y=-1),即随机变量基于p(x|y=-1)的期望.同理,π+表示p(y=+1);E+表示Ep(x|y=+1).
存在以下等式变换
π+p(x|y=+1)+π-p(x|y=-1)=
p(x,y=+1)+p(x,y=-1)=p(x)=

(4)

R(g)=π+·E+[l(g(x))]=

(5)
由于在优化过程中π+仅影响数值大小,可以被视为常数,因此,可以得到最终的优化目标为
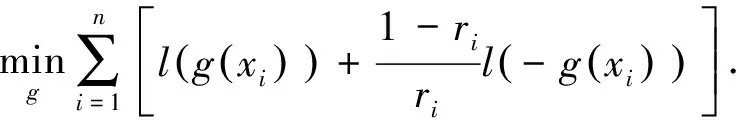
(6)
通过对经验风险函数的变形,模型训练时的损失函数就仅包含正样本及其对应可信度的函数.
2.2 Long Short-Term Memory
LSTM (长短期记忆网络)[10]是Hochreiter和Schmidhuber设计发展的一种深度循环神经网络. LSTM的提出主要是为了解决普通循环神经网络训练长序列过程中的梯度消失和梯度爆炸问题. LSTM通过在内部引入门控结构来控制数据的传输状态,能够在训练过程中记住需要长时间保存的信息,忘记不重要的信息,因而在各类序列任务中有优异的表现,被广泛应用于自然语言处理、 文本挖掘等领域.
相比于RNN模型,LSTM中存在的门控结构可以实现对序列数据的选择性记忆,因此,可以缓解无效特征对模型的干扰,同时可以实现相隔较远的信息间的传递; 相比于GRU模型,虽然LSTM更为复杂、 训练速度慢,但其可以实现短期记忆和长期记忆的学习,在传递全局状态的同时也会传递当前细胞状态,能够选择性地使用细胞状态,因此,灵活性更强,特征学习能力也较强. 综合考虑以上两方面,本文将LSTM作为基础模型来进行训练.
2.3 ProfDGA模型
针对现有模型的缺陷,本文提出了仅利用正常域名及其可信度作为训练数据的ProfDGA模型,模型训练过程如图2 所示.
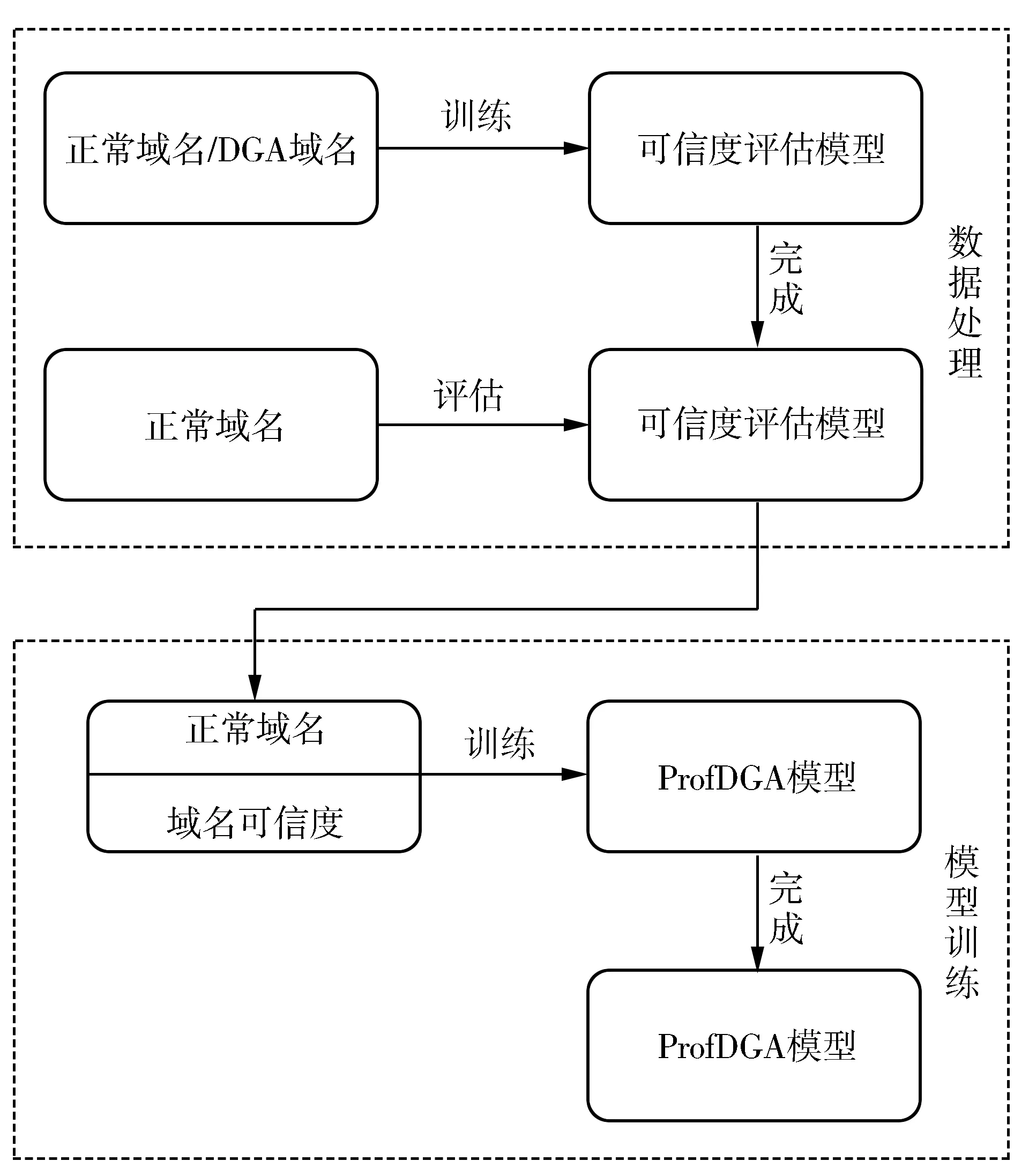
图2 ProfDGA模型训练过程
ProfDGA模型在训练阶段,首先对正常域给出一个可信度评分,将正常域名转化为数值向量后嵌入Embedding层来表示,其次,通过一个LSTM层来学习深层特征,最后,通过Dense层输出模型结果. 在计算模型损失时,构造的损失函数为
式中:r表示样本可信度. 通过优化器不断降低模型的损失,就可以在仅利用正常域名及其可信度的情况下完成模型的训练. ProfDGA模型训练流程如算法1和2所示.
算法1 ProfDGA模型训练
输入:正样本数据x_ train _p,正样本可信度数据r,正样本标签y_train_p,测试数据x_test,测试标签y_test,训练轮次max_epoch.
输出:ProfDGA模型.
算法描述:
1) 初始化模型model和优化器optimizer;
2) 将全部训练数据x_ train _p输入模型model中训练,完成模型的一轮训练,得到模型的输出out;
3) 将模型输出out依据构建的公式计算当前损失loss=sum(-out-1.*LogSigmoid(-1.*out) * 1./r);
4) 依据优化器optimizer对模型损失进行优化;
5) 检查是否达到定义的最大训练轮次,若不是则返回步骤2),若是则停止训练,进入步骤6);
6) 将全部的测试数据x_test输入训练好的模型model中得到预测结果y_pred;
7) 将预测结果y_pred与真实标签y_test对比得到模型评估报告.
正样本可信度r可以通过以下方式给出:将正样本输入训练好的可信度评估模型,由其给出样本为正常域名的可信度估值,即:r=confidence(x_train_p).
可信度评估模型confidence首先会利用数值化后的正负样本x_train_p、 x_train_n进行监督学习,在模型拟合了训练数据集后对所用的x_train_p样本进行可信度评分,即模型在训练完成后对训练中所用正样本进行评分. 可信度评估模型为每个正常域名设定一个分值,以此表示其为正常域名的概率,采用的方法是通过该模型对其监督学习过程中所用正常域名进行评分得到,因此,理论上可以采用任意的分类模型,本文使用LogisticRegression模型作为可信度评估模型,在实现任务目标的同时兼顾了模型复杂性、 运算效率的考量,整个流程如算法 2 所示.
算法2confidence模型训练流程
输入:正样本数据x_train_p,负样本数据x_train_n,正样本标签y_train_p,负样本标签y_train_n.
输出:可信度评估模型confidence,正样本可信度r.
算法描述:
1) 初始化可信度评估模型confidence;
2) 将正样本x_train_p,负样本x_train_n输入定义的模型进监督学习confidence(x_train_p, x_train_n, y_train_p, y_train_n);
3) 利用训练好的评估模型对训练所用正样本进行可信度评分r=confidence(x_train_p).
本文实验代码均使用Python的Pytorch框架和scikit-learn框架编写,所用硬件环境及依赖包版本如表1 所示.

表1 实验配置
3 实验与分析
3.1 数据集和评估指标
在数据集方面,本文使用DGArchive[11]数据集作为DGA域名数据集. DGArchive数据集是由Daniel Plohmann[8]维护的一个公开DGA数据库,被广泛应用于各类DGA研究中. 本文使用Tranco[12]数据集作为正常域名数据集. Tranco数据集是由Victor Le Pochat等[13]提出的最新的安全域名排行,该排行综合分析Aleax[14], Cisco Umbrella[15],Majestic[16],Quantcast[17]4个数据源,具备更高的可靠性.
在评估指标方面,本文通过分析混淆矩阵来评估模型性能,其定义如表2 所示.
为了更直观地体现模型性能,本实验选用精确率、 召回率及F1-Score作为模型评估的指标.
精确率也称为查准率,表示模型预测为正类的样本中真正的正类样本所占比例,其定义为

表2 混淆矩阵
召回率也称为查全率,表示模型正确预测为正类的样本数与真正正类样本数的比例,其定义为
F1-Score是Precision和Recall的调和平均值,综合考虑了两者的关系,F1-Score越高表示模型综合性能越好,其定义为
3.2 实验设计及结果
为了验证所提模型的性能,选择DGA检测领域中经典的LSTM模型和最新的GRU模型作为本文实验对照的模型,分别记为LSTMDGA和GRUDGA,将本文提出的模型记为ProfDGA. 整个实验分为两部分:同型测试和异型测试.
3.2.1 同型测试
同型测试指模型对与训练集中DGA域名同一家族的DGA的检测. 该测试主要评估模型对于相同类型AGD的检测效果,验证仅使用正常域名和置信度训练模型的可行性. 实验流程如下:
1) 选取bedep_dga和tranco分别作为正负样本数据集. 随机将正负样本数据集划分为训练集、 验证集和测试集.
2) 利用训练集训练LSTMDGA、 GRUDGA和ProfDGA模型,并通过验证集调整模型的超参数. 超参数搜索采用GirdSearch策略,结果如表3 所示.

表3 超参数列表
3) 利用测试集分别评估LSTMDGA、 GRUDGA和ProfDGA模型,用以检测模型对bedep家族未出现在训练集中的域名的识别能力,结果如表4 所示.

表4 同型测试结果
从表4 可以看出,同型测试阶段,Woodbridge提出的基于LSTM的DGA模型对于同一家族域名的检测精确率为98%,F1值为0.975,而新提出的深度模型GRUDGA有着更为优异的表现,F1值为0.980,达到了DGA域名二分类任务中的先进水平. 相比而言,本文所提的ProfDGA模型在仅利用正常域名和其可信度的情况下对于bedep家族未见过的域名仍能达到90%的检测精度和0.945的F1值,有较好的性能.
相较于LSTMDGA模型和GRUDGA模型,ProfDGA模型虽然损失了一定的检测准确性,但其优势在于训练过程中仅需要正常域名及其可信度,模型训练不直接依赖于DGA数据,因此,模型可以完成快速的更新迭代. 此外,更重要的是,只要能通过合适的方法直接对正常域名进行可信度评分,模型的训练就能完全摆脱对DGA数据的依赖,而这点有更高的实际应用价值.
3.2.2 异型测试
异型测试指模型对与训练集DGA不同家族的域名的检测. 该测试主要评估模型的泛化能力,体现模型发现新型DGA家族的能力,这对于模型的实际应用有更重要的价值.
本文利用同型测试阶段得到的LSTMDGA,GRUDGA和ProfDGA模型去识别其他类型的DGA家族,测试结果如表5 所示.

表5 异型测试结果
由表5 可知,在异型测试阶段,本文所提出的ProfDGA模型对于新型DGA家族有着优异的检测效果. ProfDGA对多个新型DGA家族均有较强的检测能力,平均精确率为76.6%,远高于LSTMDGA的56.3%和GRUDGA的55.5%. 对于downloader,volatilecedar,suppobox这3类DGA,ProfDGA模型的准确率依次为64.7%,87.6%,80.3%,而LSTMDGA和GRUDGA已经完全丧失了检测能力,三项指标均为0. 虽然GURDGA模型对conficker和fobber家族的检测效果优于ProfDGA,但在全部测试的11种DGA家族中,本文所提ProfDGA模型在 9个家族中胜出,泛化性和鲁棒性更为优异.
综合表4 和表5 可以看到:虽然在同型测试阶段,仅利用正常域名训练的ProfDGA未能达到最好的检测指标,但是在异型测试阶段,ProfDGA有着远超LSTMDGA和GRUDGA的优异表现,平均精确率、 平均召回率、 平均F1-score值分别达到76.6%,69.2%,0.708,而GRUDGA对应指标为55.5%,21.5%,0.276,LSTMDGA更是仅有56.2%,15.0%,0.217. 对于matsnu家族、 gameover家族, ProfDGA模型的F1-score比LSTMDGA模型分别增加了0.752和0.779,提升效果显著,比GRUDGA模型分别提高了0.824和0.031. 综上所述,ProfDGA模型仅利用正常域名及其可信度作为训练数据,在牺牲一些同型测试检测精度的情况下,就可以有效增强模型的泛化能力,使其具备检测未知类型DGA的能力,因此,其在实际应用中有更重要的价值.
4 结 论
本文针对现有DGA检测模型泛化能力弱,只适用于检测与训练数据同一家族DAG域名的问题,提出了只利用正常域名训练,有较强泛化能力的DGA域名检测模型. 通过实验验证了仅利用正常域名及其可信度进行DGA域名识别的可行性,与现有方法相比,所提模型能够有效发现新型DGA家族,实际应用价值更高.
本文提出的模型虽然有较好的泛化能力,但是模型的检测精度仍有较大的提升空间,这将是以后需要重点研究的方向.
