基于生成对抗网络的网络入侵检测系统
2021-09-08王怀彬
陈 阳,王怀彬
(天津理工大学计算机科学与工程学院,天津300384)
随着科学技术的发展,互联网也越来越普及。在工作和生活上,人们已经离不开互联网,因此互联网安全问题变得很重要。与此同时,互联网的攻击方式越来越多样化,攻击频率也越来越高,一旦出现重大的安全隐患,将造成无法估量的损失。如何确保网络环境的安全,已经成为不可忽视的重要问题,而其中的关键点在于能否检测到网络中的攻击行为。
传统的网络安全防护体系,如防火墙、杀毒软件等不足以应付现如今大量的网络入侵行为,但网络入侵检测技术却提供了很好的补充。入侵检测技术通过收集和分析网络中传输的数据信息,来检测网络是否遭到攻击,确认网络环境是否安全。这是一种主动的安全防御技术,在保障网络安全性方面有很好的作用,因此,有多种机器学习方法应用到了这种技术之中。
传统的机器学习方法如K近邻(K-nearest neighbor,KNN)[1],支持向量机(support vector machine,SVM)[2-3],BP神经网络模型(BP neural network,BPNN)[4],随机森林(random forests,RF)[5]等,都有着较好的检测能力,但也有着各自的不足。主要原因是传统机器学习属于浅层学习,在数据量较小并且在有标签的数据集上效果不错,一旦出现大量数据并且是无标签的非线性数据时,检测效果并不尽如人意。所以深度学习开始被人们重视,深度学习的方法开始被用于网络安全领域,如文献[6]用卷积神经网络(convolutional neural networks,CNN)来做入侵检测,降低了误报率;文献[7]用深度信念网络(deep belief nets,DBN)来做入侵检测,提高了一定的检测率;文献[8]用递归神经网络(recurrent neural network,RNN)来入侵检测,提高了准确率等。相比于传统的机器学习,深度学习提高了入侵检测的能力。
目前,基于深度学习的网络入侵检测研究都集中在RNN、DBN、CNN等判别模型,很少使用生成模型作为入侵检测模型,并且以上模型需要有标签的数据集,需要明确知道异常数据及正常数据。但是在真实的网络环境中,正常的访问数量是远多于入侵行为的,正常数据和异常数据存在严重分布不平衡,正常数据更容易获得,异常数据往往很难获得。针对这一情况,本文提出基于生成对抗网络的网络入侵检测系统GAN-NIDS,本模型会生成尽可能类似于输入数据的“假数据”。在训练阶段,只使用正常数据,使生成模型记住正常数据的特征分布。在测试阶段,正常数据通过模型后生成的数据与原数据差别较小,而异常数据通过模型后生成偏差较大的数据,通过对比生成数据与原始数据之间的差距就能找出异常数据。
1 相关算法
1.1 生成对抗网络
生成对抗网络(generative adversarial networks,GANs)是Goodfellow等人[9]首先提出的,它由生成器(generator)和判别器(discriminator)两部分组成。生成器捕获数据分布特征,输入噪声z,生成与真实数据x相似的假数据x′;判别器输入真实数据x和假数据x′,判断输入数据的真假。生成器和判别器构成了一个动态的“博弈过程”,在这个过程中,判别器要更准确地判断输入数据是真实的还是伪造的,而生成器需要去欺骗判别器,让判别器把自己生成的数据认定为真实的。随着网络训练的不断进行,生成器生成的数据越来越接近真实数据,最终判别器无法分辨出输入数据是来自真实数据还是生成数据,达到纳什平衡,这样就训练出了一个良好的生成模型(图1)。

图1 生成对抗网络的结构图Fig.1 Structure diagram of GAN
生成对抗网络的损失函数为交叉熵损失函数,具体形式为式(1)。其中,E*表示分布函数的期望;pdata(x)表示真实样本分布;pz(z)表示创建的随机噪声分布。在训练时,判别器对真实数据x判别为1,对假数据x′判别为0。在优化D时,固定G的参数,即最大化V(D,G),此时判别器D对真实数据x的判断D(x)尽可能地向1靠近,对于假数据D(G(z))尽可能向0靠近;在优化G时,固定住D的参数,即最小化V(D,G),此时G为了使D(G(z))更接近于1,则会生成更接近于真实的数据。
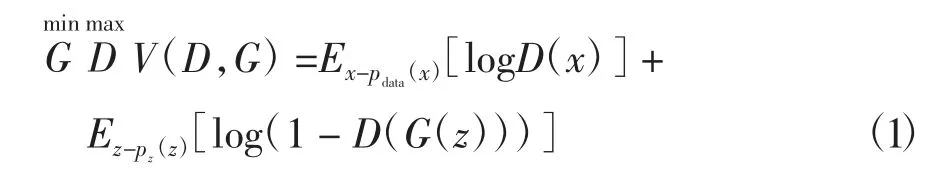
1.2 Anomaly GAN思想
文献[10]首次提出使用GAN来做图像的异常检测,原因是异常图像难以获得,而正常图像更容易获得。方法是使用生成对抗网络,学习正常图像的数据分布特征,输入正常图像,则生成的图像就和输入的原始图像相差不大,输入异常图像,则生成的图像和原始图像差距明显。
为了实现这一效果,在训练阶段,只输入正常的图像,模型只能记住正常图像的特征分布;在测试阶段,固定住在训练阶段得到的生成器参数,根据生成图片和原始图片之间的距离去更新输入GAN的噪声,最终输出一个与原始图片尽可能相似的图片,如果输入的是异常图片,这种差异明显。
2 基于生成对抗网络的网络入侵检测系统
本文结合Anomaly GAN的思想,将此方法应用于入侵检测,因原始方法在测试阶段仍需要对输入噪声进行更新,效率不高,所以对原始模型进行改进。将输入数据改为原始数据,并将原始数据进行压缩,提取出原始数据的压缩特征z,再把z进行解压缩,恢复成与原始数据同纬度的“生成数据”,即把GAN的生成器变成一个编码器和一个解码器,经过压缩-解压的步骤,网络结构能够学习到正常数据的分布特征。在训练阶段把所需的参数训练完成,测试阶段只需要进行检测即可。
本文使用的GAN是DCGAN(deep convolutional GAN),DCGAN会进行卷积操作,能记住数据的维度特征。先将数据整形成min×min×1的矩阵来输入网络,不过数据集结构特征位数不足以恰好整形成一个矩阵,为了不填充大量的无意义数据,所以在编码器之前加入一个全连接的线性结构fc1,先将数据维度扩充到256位大小。因最终需要进行输入输出数据的对比,则在解码器之后加入全连接结构fc2,将输出数据转换为与输入数据同维度的数据,方便进行输入输出数据的损失(loss)计算。图2是本模型的流程图。

图2 生成对抗网络的网络入侵检测模型的流程图Fig.2 Flow chart of network intrusion detection system based on generative adversarial networks
2.1 模型构建
本模型由生成器G和判别器D两部分构成。生成器中的编码器要进行卷积操作,提取数据特征;解码器要进行反卷积操作,生成所需假数据,模型具体的层数和所用到的参数如表1、表2所示。

表1 生成器的参数表Tab.1 Parameter table of generator

表2 判别器的参数表Tab.2 Parameter table of discriminator
由以上表格的参数来构建最终模型,模型的网络结构示意图如图3所示。整体分为生成器G和判别器D,生成器G由全连接fc1、编码器Encoder、解码器Decoder、全连接fc2共4个部分构成。解码器D由全连接fc3、编码器Encoder共两个部分构成。

图3 GAN-NIDS模型的结构图Fig.3 Structure diagram of GAN-NIDS
2.2 损失函数
如图4所示,本模型的损失函数除了原始的GAN的交叉熵损失之外,还有两个额外添加的loss。

图4 损失函数Fig.4 Loss function
1)重构loss。输入数据x与生成数据x′之间的距离。

2)特征loss。将判别器最后的Sigmoid层之前的所有层当作一个判别依据,将判别器在输入原始数据时得到的f(x),与输入生成数据时得到的f(G(x))作为得分,则他们之间的距离为
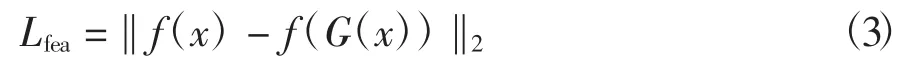
2.3 模型训练
模型对生成器G和判别器D同时训练,分别用与生成器有关的Lcon和Lfea对生成器的参数进行更新,用与判别器有关的Lfea对判别器的参数进行更新,同时用交叉熵损失对生成器和判别器进行更新,具体的训练步骤如下。
步骤1:将经过预处理的122维数据输入到第一个线性全连接网络中,网络对数据维度进行扩充处理,使之变成256维度,进而转换为16×16×1的矩阵;
步骤2:将16×16×1的矩阵数据输入到编码器中,进行卷积操作,压缩数据成深度特征z;
步骤3:将被压缩的数据输入到解码器中,进行反卷积操作,将数据解压为16×16×1维度的矩阵;
步骤4:将矩阵输入到第二个线性结构中进行放缩,变成初始大小的122维特征假数据;
步骤5:将真实数据x与假数据x′放入判别器中进行判别;
步骤6:计算3种损失函数,利用反向BP算法,进行学习,对网络结构参数进行更新。
2.4 判别依据
将模型的重构loss和特征loss作为最终的判别依据,正常数据经过模型生成的数据与原始数据差距较小,异常数据经过模型生成的数据与原始数据差距较大,把它们之间的欧氏距离Dcon=‖x-x′‖1以及经过判别器判别得分之后的差距Dfea=‖f(x)-f(G(x))‖2结合起来A(x)=Dcon+Dfea,设定一个阈值w,一旦A(x)>w则认定为异常数据。
3 实验结果
3.1 数据集
本文使用数据集KDD99,其中包含训练集和测试集。该数据集有大量的正常数据和异常数据,每条数据包括41个特征位和1个标志位,标志位指出是否是异常数据。异常数据分为4种类型,分别是DoS、R2L、U2R和Probing。
3.2 数据预处理
3.2.1 One-hot编码
KDD99数据集包含字符型和数值型的数据,但是字符型数据无法在网络中进行学习计算,需先行转换,将字符型数据转换成数值型数据。数据集共包含3种字符型的特征,分别是protocol_type,service和flag。以protocol_type为例,共包含3种字符类型,使用数值“1,0,0”“0,1,0”“0,0,1”进行独立编码,在进行距离计算时,两两之间的距离为1,不会有不同特征之间距离不同的问题。同理,service共70个不同字符,flag共11个不同字符,使用独立编码后,使数据集进行了扩充,将原本41个特征维度,扩充到了122个特征维度。
3.2.2 归一化
KDD99数据集的不同特征的取值范围不同,有的相差很大,在学习中,大特征会覆盖小特征,使之趋向于个别特征而不是整体特征,不利于网络结构的合理收敛,所以要对数值特征进行归一化处理。本文采用最大-最小归一化,将所有特征取值区间映射到[0,1]上,每个特征都会对整体模型的参数训练产生影响。变换函数如下:

其中:x是输入特征;x′是归一化后的特征;min为此特征中的最小值;max为此特征中的最大值。
3.3 评估指标
本文用准确率、检测率和误报率对实验结果进行评估。准确率acc表示所有分类正确的样本占总样本的比例,检测率dr表示正确分类的异常的样本占所有异常样本的比例,误报率far表示被误以为是异常的正常样本占所有正常样本的比例。各个公式如下:

其中:TN是正常数据被预测为正常的个数;TP是异常数据被预测为异常的个数;FN是异常数据被预测为正常的个数;FP是正常数据被预测为异常的个数。
3.4 实验结果
为了对本系统的性能进行验证,分别与部分传统机器学习方法以及一些深度学习方法作对比。具体实验结果如图5、图6、图7所示。
通过图5、图6、图7可知,本算法的准确率和检测率明显高于传统的机器学习,而且比起一些深度学习的模型也有优势,并且本模型的误报率除了比RF算法的高之外,也相对于其他算法更低。

图5 准确率Fig.5 Accuracy rate

图6 检测率Fig.6 Detection rate

图7 误报率Fig.7 False alarm rate
4 结论
本文提出了基于生成对抗网络的网络入侵检测系统,主要目的是解决异常数据不容易获取,而正常数据相对更容易得到的问题。在训练阶段只使用正常数据,使网络结构能记住正常数据的特征结构,只能生成相似于正常数据的“假数据”。在测试阶段,如果输入异常数据,则模型生成的“假数据”与原始数据差异明显,以此通过生成模型实现了入侵检测系统,并且这种方式的检测能力优于传统的机器学习以及一些深度学习模型。理论上,数据量越大,正常数据越多,本文模型的检测能力就越高,这更适应于真实的网络环境。不过生成对抗网络本身不利于收敛的问题对于模型的性能有一定的影响,稳定性是今后需要克服的问题。此外,本文使用的数据集是KDD99,数据集年代久远,不包含新型攻击类型,今后需要在更多的数据集上进行验证。
