一种基于注意机制和卷积神经网络的视觉模型
2021-09-07李鹤喜李记花李威龙
李鹤喜,李记花,李威龙
(五邑大学 智能制造学部,广东 江门 529020)
1 引 言
随着深度学习技术[1~4]的广泛研究,基于卷积神经网络(convolutional neural network,CNN)的计算机视觉技术有了突破性的进展。CNN在图像识别、图像分割、目标检测等许多应用领域取得了显著成绩。以往相关人员设计卷积神经网络模型一直在追求更高的识别率,这些深度网络通常通过简单的卷积层叠加来实现,模型的识别精度确实不断地被提升,网络模型也就越来越深。但网络通常会包含很多冗余参数,计算量也随之增大,使得网络训练越来越慢[5~8]。在实际应用中,计算能力有限、内存资源有限等的移动设备也很难部署这些深度卷积神经网络。
视觉注意机制是指视觉焦点主要集中在显著性区域而忽略其他不重要区域。故将其应用到目标识别中,能够增强目标在场景中的显著性,有效减少背景信息的干扰。传统的注意机制模型主要是利用高斯金字塔计算图像的颜色特征图、亮度特征图和方向特征图,并结合不同尺度的特征图获得亮度、颜色和方向显著图,最后相加得到最终的显著区域[9]。目前,越来越多的人将注意机制引入到卷积神经网络模型中。Jaderberg M等[10]提出的空间注意力模型(spatial transformer network,STN)可对网络模型的数据进行空间操作,使网络能够进行特征图的空间变换,从而通过确定空间位置信息来提高网络精度。Hu J等[11]提出的通道注意力模型(squeeze-and-excitation networks,SE)通过学习的方式可以自动获取到每个特征通道的重要程度,然后根据不同重要程度去提升有用的特征并抑制对当前任务用处不大的特征来提高网络精度。Woo S等[12]提出的空间通道注意力模型(convolutional block attention module,CBAM)是从通道和空间两个不同维度所计算出的特征图来进行特征的自适应学习来提高网络精度。STN模型忽略了通道之间的关系;SE模型没有捕捉到空间信息;CBAM模型虽然同时考虑到通道和空间信息,但其通道注意和空间注意是分离的,计算时相互独立,忽略了通道和空间的交互信息。
本文提出了一种深度可分离卷积(depthwise separable convolution,DSC)结合3重注意机制模块(triple attention module,TAM)的方法,称其为DSC-TAM方法并通过大量实验对比改进算法和原始算法在图像识别率和参数量的差异,验证了该算法的有效实用性。
2 深度可分离卷积
CNN是一种常见的深度学习架构,它通过卷积处理能够从原始图像中提取有效特征,因而被广泛用于各种视觉模型的建立[13]。传统的标准卷积是对所有的输入特征进行卷积运算得到一系列输出,如图1所示,其模型规模和计算量都很庞大。DSC是一种将标准卷积分解成深度卷积和逐点卷积的算法[14],它将计算分成两步完成。首先是深度卷积操作,对每一个输入通道用单个滤波器进行滤波,然后采用1×1像素逐点卷积操作并结合所有深度卷积得到输出,这种分解能够大量的减少计算量以及模型的规模,实现了卷积模型的轻量化。其计算过程如图2所示,第1层为深度卷积,主要是进行空间相关性的计算,对特征进行有效的提取;第2层是逐点卷积,是主要是通过输入通道的线性组合来调整输出特征通道数。

图1 标准卷积过程Fig.1 Standard convolution process
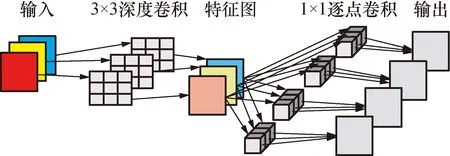
图2 深度可分离卷积过程Fig.2 Deep convolution process
假设输入和输出的特征图一样,采用的卷积核是Dk×Dk,则标准卷积的计算量为
Dk·Dk·M·N·Df·Df
(1)
式中:Dk表示卷积核k的长和宽;M表示输入特征图的通道数;N表示输出特征图的通道数;Df表示输入与输出特征图f的宽度与高度。
深度卷积的计算量为
Dk·Dk·M·Df·Df
(2)
逐点卷积的计算量为
M·N·Df·Df
(3)
故深度可分离卷积的总计算量为
Dk·Dk·M·Df·Df+M·N·Df·Df
(4)
由式(1)和式(4)可得出深度可分离卷积和标准卷积之比:
(5)
由以上公式可以看出,深度可分离卷积输出特性与标准卷积输出特性具有相同的大小,深度可分离卷积可以显著地减少参数量和计算代价,计算消耗的比例只与卷积核的数量N和它的尺寸大小Dk有关,当N和Dk越大,DSC呈现的效率越高。
3 注意机制
人类的视觉处理能力是有限的,不可能同时处理所有的信息,注意力主要集中在特征显著的区域,机器视觉也是利用这种注意机制来有效地提高工作效率[15]。复杂场景下图像的信息量很大,且图像中最重要的信息一般集中在很小的区域,所以能够利用视觉注意机制快速准确地获取图像中有效的信息,在视觉模型的建立过程中显得尤为重要。
3.1 通道注意力模块
卷积神经网络中,一张图片最初会由(R、G、B)3个通道来表示,经过卷积层后会产生新的通道,每个通道的信息是不同的[16]。通道注意力模块是利用特征的通道间的关系,生成通道注意图。由于特征图的每个通道都被认为是一个特征检测器,所以通道的注意力集中在给定输入图像包含“什么”是有意义的。为了学习通道注意力的有效表示,首先通过全局平均池化和全局最大池化来聚合空间维度信息,为每个通道生成2个特征描述符。然后将这2个特征描述符输入到一个共享的多层感知器中,以生成更具代表性的特征向量。接着通过元素求和操作输出合成特征向量,最后利用sigmoid函数得到最终的通道注意图。通道注意力模块流程图如图3所示,通道注意力计算公式如公式(6)所示。
Mc(F)=σ(MLP(Avg Pool(F))+MLP(Max Pool(F))
(6)


图3 通道注意力模块Fig.3 Channel attention module
3.2 空间注意力模块
与通道注意力模块不同的是,空间注意力模块主要集中于对当前任务有价值的地方,是对通道注意力的补充。为了计算空间注意力,首先通过全局平均池化和全局最大池化操作为每个位置生成两个特征描述符。然后将两个特征描述符集中在一起,通过7×7像素的卷积运算得到空间注意图。最后,使用sigmoid函数将空间注意力映射缩放到0~1之间。空间注意模块流程图如图4所示。空间注意力计算公式如下:
Ms(F)=σ(f7×7([Avg Pool(F);Max Pool(F)]))
(7)


图4 空间注意力模块Fig.4 Spatial attention module
3.3 通道空间注意力模块
通道空间注意力模块就是同时使用空间注意力机制和通道注意力机制两种维度,其主要思想就是将从通道和空间2个不同维度所计算出的特征图与卷积神经网络所产生的特征图相乘来进行特征的自适应学习,其模型图如图5所示。假设F为输入的特征图,则通道和空间注意力模块所做的运算分别为
(8)
式中:Mc表示基于通道维度的注意提取操作;Ms表示基于空间维度的注意提取操作;⊗表示按元素的叉乘。

图5 通道空间注意力模块Fig.5 Channel-space attention module
3.4 3重注意力模块
很多注意机制模型证明了通道注意机制和空间注意机制的重要性,而未关注到其交互的重要性。传统的通道注意力的计算方法是先计算一个权值,然后使用权值对输入张量中每个通道的标量进行缩放得到特征图,这种方法导致了空间信息的大量丢失,因此在单像素通道上计算注意力时,通道维数和空间维数之间的相互依赖性也不存在。文献[12]引入空间注意作为通道注意的补充模块。该方法的通道注意和空间注意是分离的,计算时相互独立,没有考虑两者之间的任何关系。基于以上这些原因,提出了通道空间交互作用的概念,通过捕捉空间维度和输入张量通道维度之间的交互作用,解决了这一缺陷。提出了3重注意机制模块,从3个分支维度计算注意力权值,其模型图如图6所示。第1个分支是计算通道注意力权值;第2个分支计算空间注意力权值,第3个分支是计算通道和空间的交互。然后将3个分支所产生的特征张量加权相加后求平均值。
(9)
式中:Mcs表示通道空间交互提取操作;w1、w2和w3分别是3个分支计算出注意权重;y1、y2和y3分别是3个分支的注意图。
最后输出组合特征3重注意力模块图如图6所示。
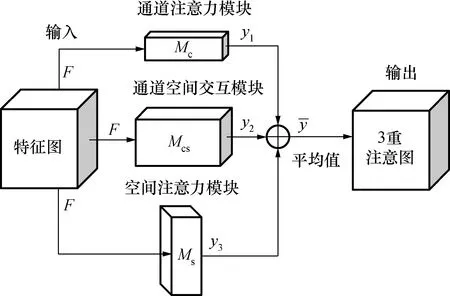
图6 3重注意力模块Fig.6 Triple attention module
4 改进网络
本文对深度可分离卷积和注意机制模块进行了改进,设计了一个新的网络结构。该网络以深度可分离卷积为主,同时引入3重注意机制模块。其中深度可分离卷积用于减少网络参数,而3重注意机制模块用于增强网络的特征提取能力。该结构在保证良好准确度的同时缩小了训练时间,优化了模型性能。该网络结构主要由深度可分离卷积、3重注意力模块2部分组成,如图7所示。

图7 模型结构图Fig.7 Model structure drawing
先使用深度可分离卷积提取特征,然后分为3个子网络同时进行运算。第1个子网络计算空间注意力,首先将逐点卷积后的特征图分别进行最大池化和平均池化,然后将经过2种池化后的特征进行连接,最后进行7×7的卷积得到空间注意图。第2个子网络计算通道空间注意图,首先将逐点卷积后的特征图进行转置操作,接着输入到最大池化和平均池化层,最后将经过池化后的特征进行连接并输入到全连接层得到通道空间注意图。第3个子网络计算通道注意图,首先将逐点卷积后的特征图分别进行最大池化和平均池化,然后将经过2种池化后的特征输入多层感知机,最后对多层感知机输出的2个特征图进行元素求和操作得到通道注意图。将这3个子网络产生的特征图相加并求平均值得到输出。改进后的主体网络结构如表1所示。
5 试验结果与分析
5.1 数据集
实验数据集共收集了16 834张常见的物品图片,42个类别的图像,每个类别包含400张左右,大小为640像素×480像素的图像,训练集为14 308张,测试集为2 526张。图8为部分物品图像集。
5.2 试验结果与分析
本文所有实验均在Windows10环境下进行,所使用的主机装有1块NVIDIA GeForce GTX 1080Ti显卡,采用Keras框架进行实验。网络的训练参数设置如下:批次batch_size为64,循环次数epochs为30,初始学习率为0.01,每10个epoch学习率缩小10倍,权重衰减值为0.000 1。

表1 主体网络Tab.1 The main network 像素

图8 部分物品图像集Fig.8 Part of the item image set
实验比较了5种网络模型:深度可分离卷积(DSC)、深度可分离卷积-空间注意(DSC-STN)、深度可分离卷积-通道注意(DSC-SE)、深度可分离卷积-通道空间注意(DSC-CBAM)和本文提出的深度可分离卷积-3重注意(DSC-TAM)模型算法。其效果对比如图表2所示,M为计算机存储单位。

表2 不同模型算法效果对比Tab.2 Effect comparison of different algorithm models
从表2中可以看出,DSC-TAM的准确率高于DSC、DSC-STN、DSC-SE、DSC-CBAM这4种模型,可达99.63%;参数量和模型规模与同样采用注意机制模块的DSC-STN、DSC-SE、DSC-CBAM相比更低,平均模型规模降低13%,略高于无注意机制的DSC模型。这说明本文方法综合性能优于其他模型,应用于图像识别、嵌入式机器人视觉实时性要求高的场合效果会更好。
表3是在本文改进模型中不同位置加入注意机制模块,从表中可以看出添加TAM模块不仅可以提高准确率并且还能减少训练时间。

表3 注意机制对比实验Tab.3 Attention mechanism contrast experiment
6 结 论
提出了一种基于注意机制和神经网络视觉模型。采用深度可分离卷积处理降低了模型的大小,使卷积神经网络轻量化,采用的TAM模块通过通道注意机制和空间注意机制以及交互信息的融合能够有效地提高网络特征提取能力。在基准数据集上完成的试验表明:采用的轻量化视觉模型与目前流行的模型相比,在网络识别的准确率和优化参数量上都取得了较好的性能,识别准确率为99.63%,模型规模降低了13%。
