连分式插值结合卷积神经网络的超分辨率重建
2021-09-06杨悦,谢辛,何蕾,胡敏
杨 悦, 谢 辛, 何 蕾, 胡 敏
(1.合肥工业大学 数学学院,安徽 合肥 230601; 2.重庆大学 计算机学院,重庆 400044;3.合肥工业大学 计算机与信息学院,安徽 合肥 230601)
近年来,由于计算机科学的发展蒸蒸日上,越来越多的领域如生物医学、遥感测绘和视频通讯等都在广泛应用数字图像处理技术,图像超分辨率(super-resolution,SR)重建是其中的一个热门研究分支,已被大规模地运用于物体检测、人脸识别和行人检测等重要领域。图像超分辨率重建是从多幅低分辨率(low-resolution,LR)图像中重建出一幅高分辨率(hgih-resolution,HR)图像。目前图像超分辨率的主要方法[1]有基于插值、基于重建和基于学习的方法。
基于插值的方法利用图像空间域中邻近像素点的像素值确定待插值点的像素值,最常见的有最近邻插值、双线性插值与双三次插值[2]。文献[3]提出了一种结合边缘拟合算子的空间非线性插值算法模型;文献[4]提出了一种基于小波的图像重建方法。基于插值的图像超分辨率重建方法便于处理,但是由于没有充足的先验知识和图像的观测模型,重建后的图像边缘模糊,且整体视觉效果不佳[5]。
基于重构的超分辨率重建方法从构建图像的退化模型出发,把多幅低分辨率图像作为一致性约束,再结合低分辨率图像的先验知识进行超分辨率重建,该方法主要有频域法和空域法。文献[6]最早利用傅里叶变换的平移特性提出频域法。由于频域法缺乏充分的先验知识,目前最流行的是空域法。经典的空域法有:非均匀插值法[7]、凸影投射法[8]和最大后验概率[9]。
基于学习的超分辨率重建方法通过机器学习从大量相对应的低分辨率与高分辨率图像组之间得到映射关系,再基于这种映射关系输入低分辨率图像预测得到重建的高分辨率图像[10]。文献[11]提出了一种基于样本学习的图像超分辨率重建算法;文献[12]提出基于稀疏表示的图像超分辨率算法。近年来,深度学习在图像超分辨率重建领域表现出了巨大的潜力[13],文献[14]首次利用三层卷积神经网络(convolutional neural networks,CNN)在低分辨率图像LR和高分辨率图像HR之间建立了端到端映射的轻量级超分辨率模型;文献[15]通过结合卷积神经网络和残差网络[16]建立了深度达20层的卷积网络结构VDSR。然而网络深度的增加带来网络参数增加、梯度弥散和计算运行成本增大等问题。此后文献[17]将递归神经网络结构[18]应用于超分辨率重建中,大幅减少了网络参数,提高了重建效率;文献[19]提出使用浅通道和深通道分别重构图像的轮廓信息和纹理细节。
上述基于深度学习的超分辨率模型均属于原始图像输入网络前需经过插值预处理把图像放大到规定目标尺寸的基于插值预处理的模型[20],且均使用双三次插值进行预处理,导致输入卷积神经网络前的预处理图像过度平滑和模糊,重建后的图像易丢失一些细节以至于边缘过于平滑。
为了不增加网络深度且能够提高网络性能,如图1所示,本文以轻量级网络基于卷积神经网络的超分辨率重建算法(super-resolution convolutional neural net work,SRCNN)算法[21]为模型,采用Newton-Thiele型混合连分式插值函数[22]对输入的原始低分辨率图像进行插值预处理,以达到充分利用低分辨率图像纹理细节特征的目的。因为SRCNN算法在重建与优化的过程中采用易于收敛到局部最优的随机梯度下降法(stochastic gradient descent,SGD)[23]最小化损失函数,所以本文利用Radam自适应优化算法[24]和余弦衰减法[25]收敛损失函数,提高灵敏度避免产生较大的震荡,进一步提升重建图像的质量。

图1 超分辨率重建的卷积神经网络结构图
1 超分辨率的卷积神经网络
1.1 预处理
把原始低分辨率图像输入到三层卷积神经网络之前,对其进行插值预处理到与高分辨率图像同样的尺寸。在SRCNN算法中,预处理时采用简单的低通滤波器双三次插值函数,在插值时可能会抑制高频成分丢失一些重要的纹理细节,以致于重建后的图像边缘产生较多的模糊或出现阶梯失真现象。考虑到双三次插值函数不足以很好地恢复图像的纹理特征,因此本文使用非线性插值函数即Newton-Thiele型混合连分式插值函数,插值后的图像不仅能够保留更多的高频纹理细节[26],而且重建后的效果图其边缘纹理会更加逼真,也更能符合人类的视觉机制。
Newton-Thiele型插值函数是将Newton插值多项式与Thiele型插值连分式混合而成的。
设
i=0,…,m;j=0,…,n}。
令
φNT[xp,…,xq,xi,xj;yk]=
φNT[xp,…,xq;yk,yl]=
φNT[xp,…,xq;yr,…,ys,yk,yl]=
(yl-yk)/{φNT[xp,…,xq;yr,…,ys,yl]-
φNT[xp,…,xq;yr,…,ys,yk]}。
称由上式定义的φNT[xp,…,xq;yr,…,ys]为函数f(x,y)在网格点{xp,…,xq}×{yr,…,ys}上的Newton-Thiele型混合差商。

(x-x0)…(x-xm-1)Am(y),
Ai(y)=φNT[x0,…xi;y0]+
其中,φNT[x0,…,xi;y0,…,yj]为Newton-Thiele型混合差商。
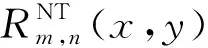
1.2 特征提取
特征提取[21]是从低分辨率图像中提取重叠的图像块,并将每个图像块表示为一个高维向量,类似于传统方法中用一组提前训练好的基,如PCA、DCT等[27]表示这些图像块,它们由一组特征图组成, 特征图数量等于向量的维度。
在卷积神经网络中,本文的第1层操作在形式上可以表示为:
F1(Y)=max(0,W1*Y+B1),
其中:W1为滤波器;B1为偏置项;*表示卷积操作;W1为大小是c×f1×f1的n1个滤波器,c为输入图像的通道数量,f1为滤波器的空间大小,n1为滤波器的数量。即W1对图像执行n1次卷积,得到n1个特征图,卷积核大小均为c×f1×f1;B1为一个与滤波器相关的n1维向量。滤波后再使用线性纠正单元(max(0,x),ReLu)[28]。
1.3 非线性映射
在第1层卷积操作中, 本文对每个图像块提取了n1个特征。 而在第2层中, 本文利用卷积层把每个n1维向量非线性地映射到另一个n2维向量上,输出的每一个n2维向量都相当于重建的高分辨率图像块。第2层的操作可表示为:
F2(Y)=max(0,W2*F1(Y)+B2),
其中:W2对应了n2个卷积核大小为n2×f2×f2的滤波器;B2为n2维的偏差。
1.4 图像重建
预测的高分辨率重叠图像块通常以平均的方式来生成最终的完整图像[29]。平均这一步骤可以看作是在一组特征图上一个预定义的滤波器。第3层的操作可表示为:
F3(Y)=W3*F2(Y)+B3,
其中:W3为一个大小是n2×f3×f3×c的线性滤波器;B3为c维的偏差。
1.5 训练与优化
为了学习端到端的映射函数F,本文通过最小化损失函数来估计卷积神经网络参数Θ={W1,W2,W3,B1,B2,B3},本文采用SRCNN算法中的均方误差(mean square error,MSE)作为损失函数,其形式如下:
其中:n为训练样本的数量;Yi为LR;Xi为HR;i为遍历整个训练集的图像的序号。
在训练中SRCNN算法使用SGD算法收敛损失函数。为了减少震荡并提高优化效率,SGD算法每经过数轮迭代就更换一个较小的学习率。手动调节学习率工作量较大且很难快速找到当前模型环境下的最佳值。若设置的学习率过小,会使得优化进程缓慢;若学习率过大,会导致震荡且难以逼近最优解甚至逐渐远离最优解[30]。
为了解决上述问题,本文利用余弦衰减法,通过余弦函数逐渐降低学习率,即
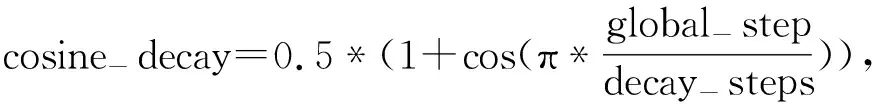
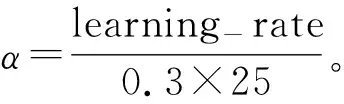
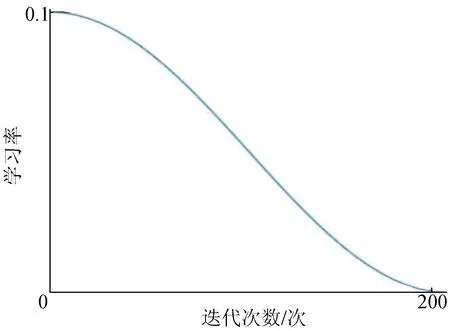
图2 余弦衰减图
同时,本文采用通过控制自适应率的方差动态地调整梯度下降方向的Radam优化算法,即
ρ∞←2/(1-β2)-1,
gt←θt-1f(θt-1),
mt←β1mt-1+(1-β1)gt,
当ρ∞>4时,则
当ρ∞≤4时,则使用非自适应动量更新参数,即
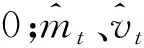
2 实验结果及分析
2.1 网络模型与参数
通过大量的实验验证了本文提出的超分辨率模型性能更优。受SRCNN算法启发,为了均衡卷积神经网络的训练速度与性能,实验中仅使用最基本的3层卷积网络,即卷积神经网络层所对应的滤波器的尺寸大小分别为f1=9,f2=1,f3=5,所对应的滤波器数量为n1=64,n2=32。本算法采用标准的91幅图像[10]和BSDS300[31]作为实验的训练集,每一层的权重均使用Xavier均匀分布[32]进行初始化,并把每一层的偏置项初始化都设置为0,共迭代2×105次,epoch=1 000,batch-size=128,数据集大小为35 230。
2.2 综合量化测评
本文依次使用双三次插值[2]、基于稀疏表示的图像超分辨率算法、SRCNN算法、基于局部样本自相似性的图像和视频放大算法[33]、通过自适应稀疏域选择和自适应正则化实现图像的去模糊和超分辨率[34]重建Set5和Set14测试集[35]进行对比实验,并使用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)作为衡量图像质量的指标。超分辨率重建方法在Set14和Set5测试集上的客观测评PSNR和SSIM结果对比见表1、表2所列,本文的方法比传统的超分辨率重建方法有明显的优势,其中在Set5测试集上的平均PSNR值和SSIM值分别为36.45 dB和0.95,比同样使用卷积神经网络的SRCNN算法高出4.74 dB和0.02。

表1 在Set14测试集上×2的PSNR和SSIM
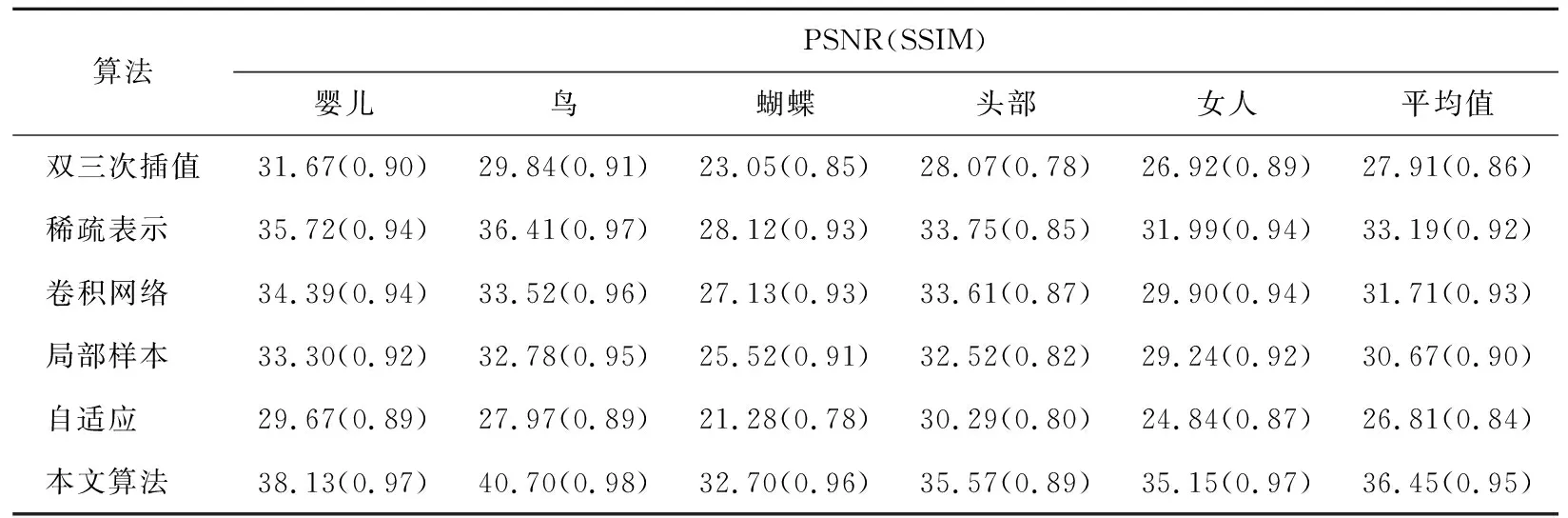
表2 在Set5测试集上×2的PSNR和SSIM
采用双三次插值预处理低分辨率图像的SRCNN算法,分别使用SGD算法和Radam算法进行优化的PSNR迭代效果,如图3所示。从图3可以看出,使用SGD算法收敛时引起的震荡很大,而Radam自适应优化算法收敛时则非常平稳。

图3 Set14上SGD算法和Radam算法重建效果对比
注:PSNR的单位为dB。
注:PSNR的单位为dB。
本文算法与其他算法重建效果对比如图4所示。图4中:图4a为原图;图4b为局部放大原图;图4c为双三次插值算法结果;图4d为基于局部样本自适应算法结果;图4e为基于稀疏表示结果;图4f为基于自适应稀疏和自适应正则化算法结果;图4g为基于卷积神经网络算法结果;图4h为本文算法结果。
从图4中可以看出,本文算法比其他算法能够重建出更加清晰且拥有丰富分明纹理细节特征的高分辨率图像。
不仅如此,放大后的SRCNN算法重建图像边缘处(图4中蝴蝶翅膀条纹)有明显的振铃模糊现象,但是本文算法很好地改善了这些问题,并且在人的视觉效果上更为突出。
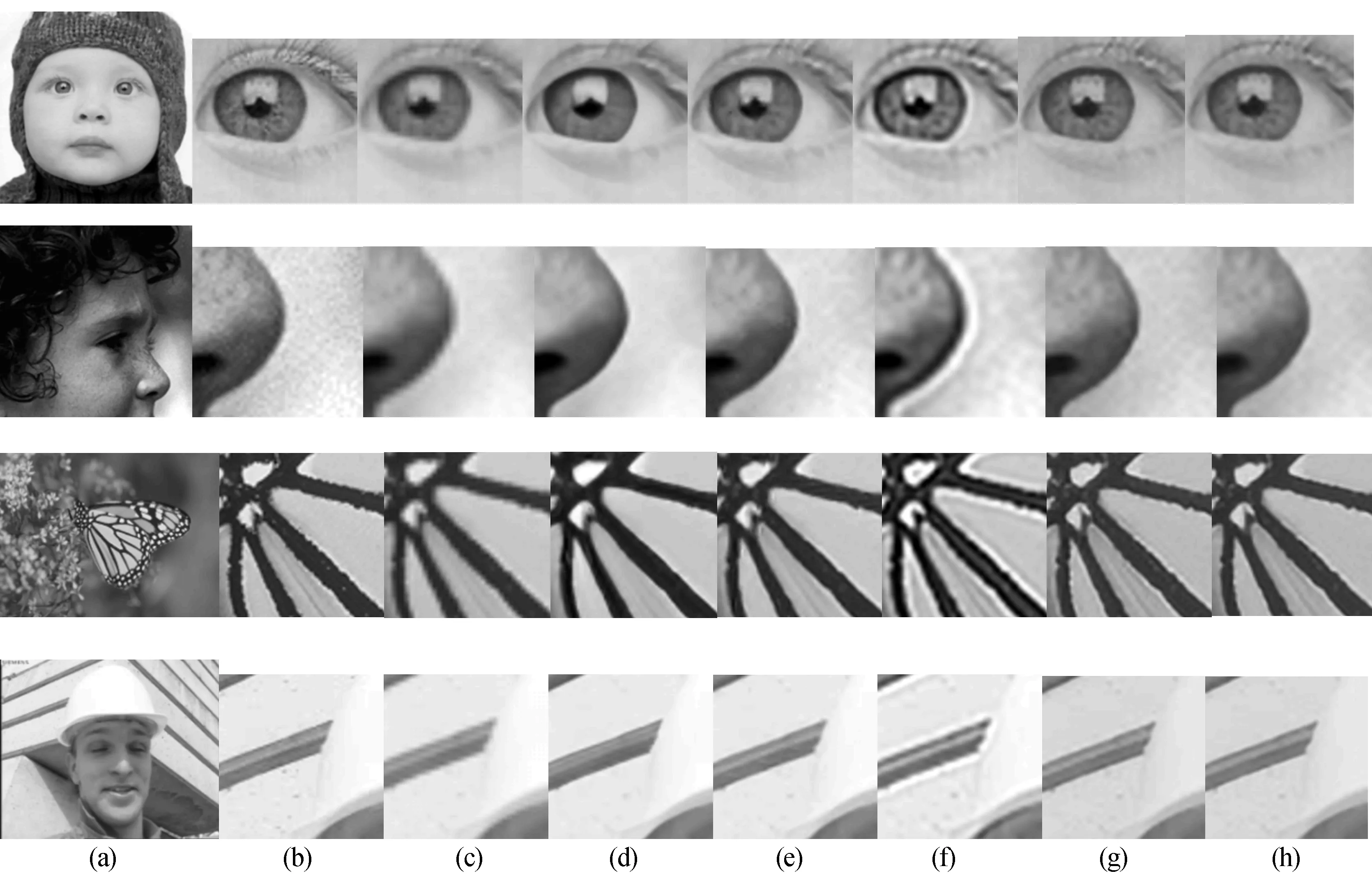
图4 本文算法与其他算法重建效果对比×2
3 结 论
本文提出了一种连分式结合卷积神经网络的超分辨率重建方法,以解决基于卷积神经网络的超分辨率算法在插值预处理原始低分辨率图像时损失一些重要的纹理细节的问题。本文在预处理时使用Newton-Thiele型混合连分式插值函数,引入更多的非线性因素,突破了目前深度学习超分辨率领域采用双三次插值函数预处理图像的局限性,分析了在网络重建与优化过程中使用随机梯度下降法的不足之处,并采用能够在收敛时根据自适应率的方差动态地更新调整梯度方向的Radam优化算法和通过余弦函数来逐渐降低学习率的余弦衰减法以最小化损失函数。实验结果表明,本文方法可以恢复更丰富的纹理细节特征,相比于其他传统方法在客观评价和主观视觉效果上均有明显的优势。除此之外,本文方法能够有效避免SRCNN算法重建的图像纹理细节处出现模糊失真的振铃现象,重建出更高质量的高分辨率图像。后续工作可以进一步探索加深网络的深度来提取更多不同层次的图像特征,以及改进优化方法和参数初始化设置来提高完善网络的速度与性能。
