人工智能医疗器械质量评价测试集样本量分析
2021-09-03孟祥峰王浩李佳戈
孟祥峰,王浩,李佳戈
中国食品药品检定研究院 光机电室,北京 100050
引言
随着人工智能技术的发展,人工智能医疗器械得到了飞速的发展,目前在国内外已有多种类型及用途的人工智能医疗器械上市,种类及数量呈上升趋势。2018年4月11日,美国FDA批准了IDx公司IDx-DR糖尿病视网膜病筛查软件,这是美国FDA批准的第一款采用新一代人工智能技术的糖网筛查软件产品。随后在辅助诊断、辅助筛查等诸多领域,基于影像、信号、文本等多种数据模态的产品出现[1-3]。2020年8月10日,我国两款糖尿病视网膜病变眼底图像辅助诊断软件产品获批上市[4];2020年11月,又有两款肺结节CT影像辅助检测软件获批上市。
我国人工智能医疗器械产品功能不断增加、快速迭代,目前还有多个产品处于注册临床试验状态,不久以后将迎来人工智能产品上市的爆发期。大量产品的上市,将给市场监管带来压力。目前对于人工智能医疗器械的评价方法已经有相关机构展开了研究[5-13],《人工智能医疗器械质量要求和评价 第1部分:术语》《人工智能医疗器械质量要求和评价 第2部分:数据集通用要求》两项标准已完成审定[14],即将发布。
人工智能医疗器械在特定训练集训练或测试时,会得到较好的效果,然而在新的数据集上的表现很难保证,即说明其泛化能力差,鲁棒性能有待提高。目前对其性能指标的评价主要通过利用产品在封闭测试集上的表现进行,因此封闭测试集的样本量及样本构成必须进行合理的设计。本文对数据集的样本量进行分析,在一定的样品构成情况下(对应特定应用场景),分析国内已上市辅助诊断产品对于测试集样本量的需求,在满足测试的条件下,节约社会资源,以小样本达到性能准确评价的目的。
1 试验设计
建立一个测试集,需严格控制各类偏倚,设计标注流程,投入很大的人力物力,在人工智能产品不断多样化、模态与病种不断聚合的情况下,为快速、有效地实现产品验证,首先需考虑资源问题。人工智能医疗器械测试集样本量的估计是基于主要评价指标的相应假设进行的,样本量的大小和构成应与产品预期要应用的目标群体匹配,测试集样本应能很好地代表目标人群参数。适合的样本量可有助于研究者用合理的资源发现有意义的性能差异;过少的样本量难以准确地发现测试的科学问题;而过多的样本量会造成资源的浪费[15-18]。
以诊断试验为例,在临床评价试验中,其评价指标为灵敏度和特异度,可用灵敏度或特异度计算总体的样本量[19]。
为保证灵敏度的抽样误差不大于允差,样本量应不低于式(1)的计算结果。

为保证特异度的抽样误差不大于允差,样本量应不低于式(2)的计算结果。
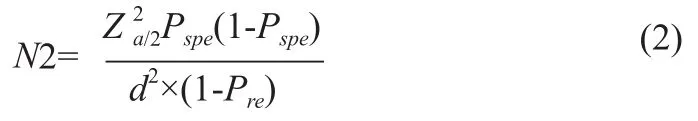
本文测试采用回顾性数据对产品进行性能验证,参考临床评价试验中的样本量计算方案,观测该方法样本量估算是否满足测试需求。
1.1 试验1:糖尿病视网膜病变眼底图像辅助诊断软件测试
根据卫健委和中华医学会的统计,我国糖尿病视网膜病变在糖尿病患者人群中的发病率约为25%[20],以此作为数据库的患病率,假设产品预期灵敏度和特异度为90%,置信区间95%,允许误差5%,因此根据公式,二者的最大值是单次测试样本数量的最低要求。对于糖尿病视网膜病变眼底图像辅助诊断软件,以灵敏度计算测试集样本量,样本最低数量为554例,以特异度计算测试集样本量,样本最低数量为185例。
选取某一糖尿病视网膜病变眼底图像辅助诊断软件,在特定阴阳性比例情况下,采用分层随机抽样,阴阳性比例保持不变,设置18个不同样本量,见表1,分别进行灵敏度、特异度测试,并对结果进行波动分析。
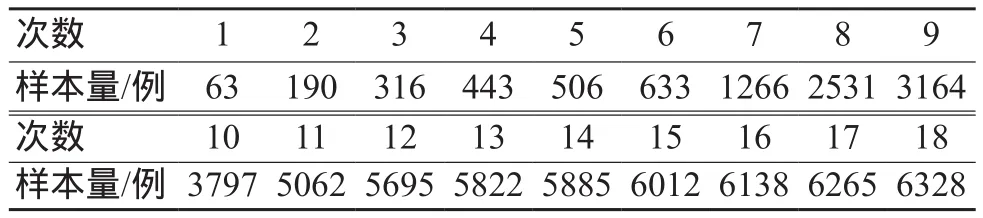
表1 糖尿病视网膜病变眼底图像辅助诊断软件不同样本量设置
1.2 试验2:肺部CT影像辅助诊断软件测试
肺癌的早期诊断和早期治疗是提高患者生存率、降低医疗负担的关键。近年来,我国人工智能在肺结节检测上是研究的热点。但肺结节不一定意味着是肿瘤,此外肺结节的发病率目前没有具体的流行病学统计,如果以结节为单位估算召回率和精确度,按照式(1)和式(2)较难进行样本量估算。本文从实际检测角度出发,对肺部CT影像辅助诊断软件的测试样本量进行估计和推测。
本文对某两个肺部CT影像辅助诊断软件,在测试集中(每个病例平均结节个数为10个)按照病例随机抽样,设置14个不同样本量(表2),分别进行召回率、精确度测试,并对结果进行波动分析。
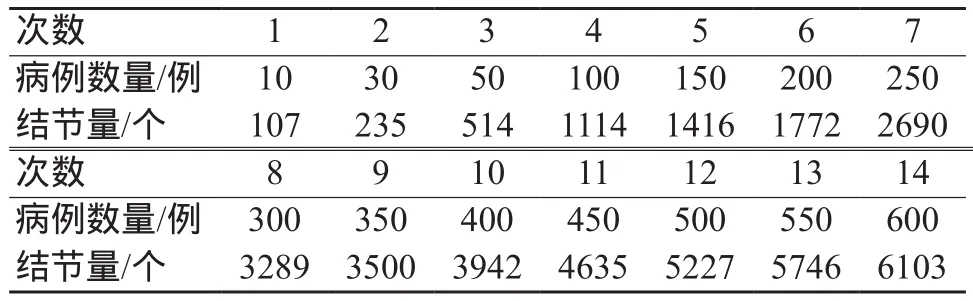
表2 肺部CT影像辅助诊断软件不同样本量设置
2 试验结果
2.1 试验1测试结果
糖尿病视网膜病变眼底图像辅助诊断软件在不同样本量下灵敏度和特异度的测试结果如图1所示。波动值的计算公式为式(3),灵敏度的波动度为11%,506例及以后的波动度为0.6%,633例及以后的波动度为0.4%;特异度波动度为2.6%,506例及以后的波动度为1.5%,633例及以后的波动度为0.6%。

图1 糖尿病视网膜病变眼底图像辅助诊断软件测试结果

式中,Pmax为测量结果最大值;Pmin为测量结果最小值;P为测量过过平均值;S为波动度。
2.2 试验2测试结果
肺部CT影像辅助诊断软件两个样品在不同样本量下召回率和精确度的测试结果如图2~3所示。样品1召回率的波动度为10.9%,精确度的波动为6.1%;400例(3942个结节)及以后召回率的波动度为1.5%,精确度的波动为0.7%;450例(4635个结节)及以后召回率的波动度为0.8%,精确度的波动为0.4%。样品2召回率的波动度为5.5%,精确度的波动为2.4%;300例(2940个结节)及以后召回率的波动度为0.6%,精确度的波动为1.1%;350例(3625个结节)及以后召回率的波动度为0.5%,精确度的波动为0.9%。

图2 样品1测试结果
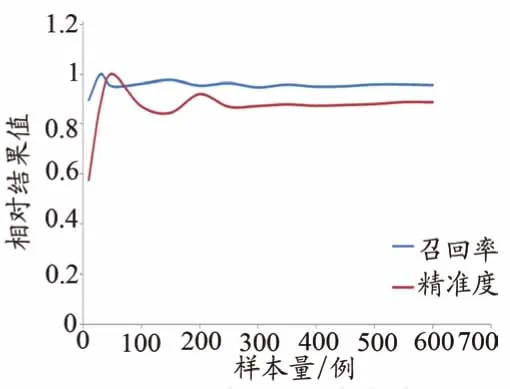
图3 样品2测试结果
2.3 试验结果分析
从图1~3可知,随着样本量的增加,被测参数的波动不断减小,当样本量达到一定数量时,被测参数的波动趋于稳定,说明在测试过程中找到这个拐点即可保证统计结果准确性,也可不必追求更高数量的测试集。如果假设1%的波动能够满足测试要求,那么对于糖尿病视网膜病变眼底图像辅助诊断软件,本文试验能够同时满足灵敏度和特异度的最低限为633例。测量结果与理论计算值相近。即说明对于人工智能产品基于回顾性样本的测试集测试,其样本量的估算可按照本文式(1)~(2)的方法进行估计。
对于肺部CT影像辅助诊断软件,如果假设1%的波动能够满足测试要求,那么样品1的样本量为450例(4635个结节),样品2为350例(3625个结节)。二者结果的差异也体现了产品性能的差异,从图2~3可知,样品2整体波动量比样品1低了2倍,样品2的性能要优于样品1。造成差异的原因可能是产品的鲁棒性能和泛化能力对结果的影响,产品抽样更细分的构成如结节尺寸、结节类型、数据质量等,这些都会对测试结果带来影响,因此在实际评价中也应考虑测试集中各种维度抽样带来的统计偏倚。产品的鲁棒性能、泛化能力越强,对于测试集数量的依赖程度越低。采用测试集对人工智能的评价是一种统计的评价方式,应该在测试集数量的选取上考虑实际应用场景,以预计测试指标和发病率等情况为基础进行估计。
3 讨论
本文通过对糖尿病视网膜病变眼底图像辅助诊断软件及肺部CT影像辅助诊断软件两类产品性能评价的试验,测算其测试集样本量。考虑实际抽样的偏差,以本实验<1%的波动推算,抽样数量以百位向前取整,推荐糖尿病视网膜病变眼底图像辅助诊断软件的测试集样本量不低于700例,肺部CT影像辅助诊断软件的测试集样本量不低于500例(5300个结节)。
目前对于人工智能医疗器械的功能越来越多,应用场景也不尽相同。因此需要组建各类测试集对产品质量进行检测。测试集区别于训练集,测试集更突出对于检测结果的客观性、代表性和权威性,因此它的建设需要投入大量的人力、物力等社会资源。现有的方法多建议选取大量的数据作为测试集,以保证评估结果有统计学意义,但是针对应用场景不定,无流行病学统计的病种,大量数据的样本量是多少很难把握。本文通过理论计算和试验验证相结合的方法,给出了目前两类已取得医疗器械注册证产品的测试集样本量,这将有利于指导企业自检或第三方检验机构检测对于测试集样本量的构成,而不必追求大样本量进行测试,节约社会资源。
4 结论
人工智能辅助诊断软件样本量的估算方法可参考临床评价诊断试验的样本量估算方法。在没有流行病学统计的情况下,可根据产品的预期用途、应用场景进行发病率的推测,来估计样本量。但人工智能医疗器械的模态已经从影像扩展到信号、文本,甚至是多模态,适用病种也包含多种,按照上述方法确定样本量依然是个难题,需进一步研究。本文通过理论计算和实际验证的方式,给出目前已上市的两类人工智能辅助诊断产品的测试集样本量估计,为人工智能医疗器械的测试集样本量的研究提供了研究基础,具有实际应用价值。
