一种主辅路径注意力补偿的脑卒中病灶分割方法
2021-09-02回海生张雪英吴泽林李凤莲
回海生,张雪英,吴泽林,李凤莲
(太原理工大学 信息与计算机学院,山西 太原 030024)
全球脑卒中的发病率逐年增加,每年新增脑卒中发病人次达到1 030万。自2015年起,脑卒中已经成为除慢性病外位列前三的致死疾病[1-2]。在脑卒中发病时,准确的脑卒中病情诊断和及时针对病变大小、位置的介入治疗可以有效地降低致残和致死率。因此,快速、准确的脑卒中病灶分割方法有重要的临床意义。由于病灶的手动分割非常耗时,对于核磁共振影像(Magnetic Resonance Imaging,MRI)中单个形状复杂的大病灶,需要耗费熟练标记者数个小时才能完成精确的标注和校验[3]。因此,迫切需要一种快速、准确的自动脑卒中病灶分割方法,以在短时间内可以治疗更多的患者。卷积神经网络(Convolutional Neural Networks,CNN)及其持续发展的网络结构在语义分割任务中具有出色的性能[4-5]。但是,这些基于卷积神经网络的网络模型需要数量较大的标注数据进行训练,而医学图像的数据标注成本很大。U-Net的出现[6]在一定程度上解决了上述问题,它通过跳跃连接在对称的编码和解码器之间建立不同尺度的特征融合通道,使网络可以更好地利用图像的全局和局部特征,非常适用于少量数据标注的医学图像分割任务。标准的5级U-Net特征通道总数多达上千个,待训练参数数目较多,在训练过程中编码和解码路径需要反复提取深层特征。由于深层特征的抽象性和低分辨率特性,导致训练难度增加,甚至训练不稳定、不充分。文献[7]中提出了Attention U-Net模型,其使用注意力门(Attention Gate,AG)生成网格化的注意力系数图,用以隐式地抑制输入图像中不相关的区域,突出显式对特定任务有用的特征,实现对目标区域的定位和捕获,降低训练难度,提高分割精度。
虽然 Attention U-Net在诸多分割任务中都取得了不错的成绩,但也存在明显的不足。首先,在其解码器结构中,深层特征含有更多的病灶位置信息和判别信息。用于生成深层注意力系数图的特征通道数可达1 024个,其中大部分通道的病灶特征并不明显,甚至无效,Attention U-Net缺少对有效特征通道进行选择或者加权调整的机制。其次,自注意力机制本身也有明显的不足。由于用于约束关注区域的注意力系数图是由分割网络中浅层特征与其衍生出的深层特征通过特定运算生成的,当病灶较小且病灶特征不明显的时候,浅层特征不能很好地学习病灶特征,从而使注意力系数图的关注区域偏离病灶区域,影响分割结果。为解决以上问题,基于全局注意力上采样(Global Attention Upsample,GAU)模块[8]和Attention U-Net,笔者构建了GAU-A-UNet模型。基于该模型提出一种主、辅路径注意力补偿网络(Primary-Auxiliary Path Attention Compensation Network,PAPAC-Net);为了实现PAPAC-Net主、辅路网络各自的功能,提出了加权的二进制交叉熵特维尔斯基(Weighted Binary Cross Entropy and Tversky,WBCE-Tversky)和容限(Tolerance)损失函数。
1 模型和方法
1.1 GAU-A-UNet模型
网络结构如图1(a)所示,其左侧编码路径结构与Attention U-Net相同;右侧解码路径基于注意力门和全局注意力上采样进行了重新设计,即用全局注意力上采样替换了Attention U-Net解码路径各层的解码操作,对各层特征实现了通道间的全局加权调整,又通过4个全局注意力上采样逐层上采样实现了与解码器相同的功能。该模型仅在解码路径的第2和第3级上使用注意力门模块施加空间注意力,是因为第1级注意力门模块太靠近输出,所以进行下文提出的注意力补偿易影响分割结果;而第4级注意力门的特征信号分辨率太低,单个像素对应的感受野太大,进行注意力补偿会引起巨大波动。
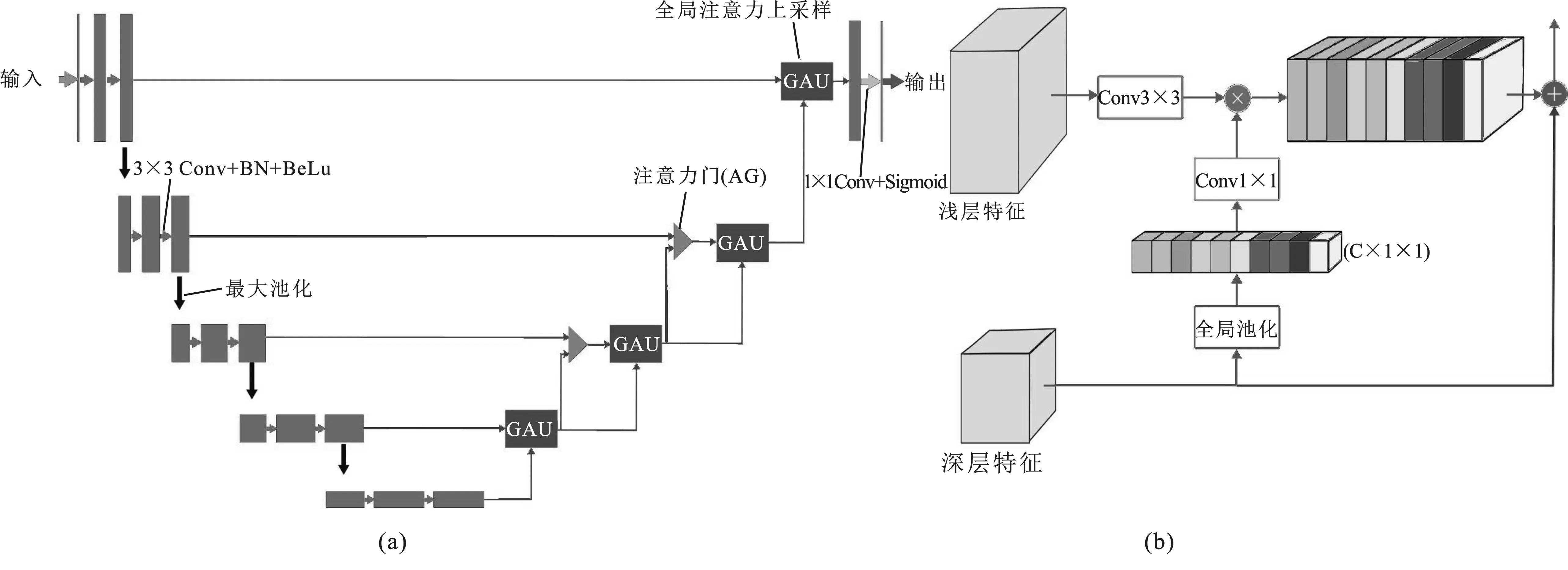
图1 GAU-A-UNet与GAU模块结构示意图
图1(b)的GAU模块[8]能够利用深层特征空间定位信息感知力强的特点,生成全局上下文信息对浅层特征进行加权调整,突出具有详细定位细节的浅层特征,抑制病灶位置信息不明显的浅层特征,逐层对浅层特征加权选择,从而在解码阶段逐层修复病灶定位的细节信息。笔者将全局注意力上采样与Attention U-Net 结合,提出了GAU-A-UNet分割模型,既适用于仅有少量数据的医疗影像分割任务,又能够利用注意力门提供的空间注意力信息,同时还能利用全局注意力上采样对不同层级的特征信号进行全局加权调整。
1.2 主、辅路径注意力补偿网络
该模型在进行病灶特征学习的过程中,当病灶与健康组织特征区分度不明显时,基于病灶边缘、纹理的浅层特征极易发生学习错误,后继由浅层特征逐级生成的深层特征同样也会发生偏差。这将导致由浅层特征和深层特征共同产生的注意力信号发生错误,从而使关注区域发生错误,影响模型的分割性能。为了解决上述问题,笔者提出了PAPAC-Net网络结构,其由结构上完全相同的两个自注意力基本分割网络构成,简称主网络和辅网络。为实现注意力补偿功能,使用完全相同的输入数据和训练目标对不同的主、辅损失函数进行模型训练。主网络使用一种能够实现严格分割的损失函数训练,以实现对病灶区域的精确分割并输出最终分割结果;而辅网络使用一种能够实现注意力宽松化的损失函数训练,从而生成一个覆盖面积更大、更宽松的辅助注意力补偿系数图(Auxiliary Attention Compensation Coefficient Map,AACCM),以有效地弥补主网络特征学习错误带来的注意力损失。如图2(a)所示,PAPAC-Net包含上下两个完全相同的基本分割网络 GAU-A-UNet,分别为主、辅网络,其同时使用完全相同的输入数据进行训练。在训练过程中,辅网络通过图中的垂直连接线将生成的宽松AACCM补偿到主网络的注意力门中,从而在主网络生成的注意力系数图发生错误时实现有效补偿,最终由主网络完成病灶分割并输出分割结果。
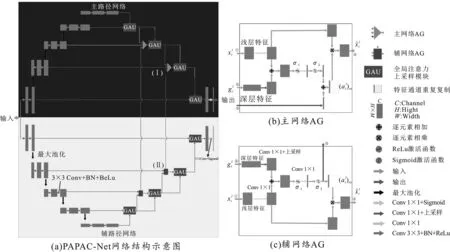
图2 PAPAC-Net与主、辅网络注意力门的结构示意图
辅网络对主网络补偿作用的有效性分3种情况讨论。首先,当主网络注意力系数学习不充分时,关注区域部分正确,辅网络加性补偿面积更大的关注区域后,修正了主网络注意力系数的关注区域,可以提升分割性能;其次,当主网络注意力系数的关注区域完全正确时,虽然辅网络加性补偿面积更大的关注区域,但依然在主网络正确的关注区域处叠加了最高的权重,对分割性能无影响;再次,当主网络注意力系数的关注区域错误时,辅网络生成的宽松化的辅助注意力系数关注区域同样错误,对分割结果无影响。总体来说,最终数据集整体的平均分割性能得到了提升。图2(b)和(c)分别对应给出了图2(a)标记为(I)和(II)的注意力门结构图。如在图2(c)中,①和②是辅网络注意力门的输入,分别对应浅层和深层特征信号,它们通过使用加性注意力[7]生成注意力系数图来决定需要关注的病灶区域。在对注意力系数图进行特征通道复制重采样后,将其与浅层特征信号进行相乘,得到注意力门输出的特征信号④并送入解码路径。图中标记为③的特征信号为辅网络的AACCM,通过图2(a)中的连接线送往主网络相同层级、相同位置的标记为(I)的注意力门进行注意力系数补偿。图2(b)为主网络进行注意力补偿的注意力门的结构图,结构与辅网络基本一致,仅仅是在生成最终的注意力系数图时,将来自辅网络的AACCM和当前主网络的注意力门生成的注意力系数图进行了加性融合操作。需要注意的是,首先主、辅网络必须使用完全相同的基本分割模型和同时输入完全相同的训练数据,以保证两个网络的注意力系数图的特征区域一一对应;其次,由于两个网络训练过程是彼此独立的,辅网络对主网络注意力系数图的补偿虽然使主网络局部增大了关注区域,但是这种补偿产生宽松关注区域的运算并没有参与到主网络的整个训练和反向传播中,主网络依然按照严格分割病灶的目标进行训练,因此不会因为补偿了大面积的注意力系数图而生成假阳性过高的分割结果。这种补偿仅仅是对局部注意力图错误的补偿,以使网络在正确约束下更容易找到病灶,是对约束操作的补偿,并不是对最终结果的直接补偿。
1.3 主、辅网络损失函数
如上所述,通过在主网络和辅网络上使用不同的混合损失函数进行训练,从而实现各自不同的功能。首先,为了使主网络生成比较严格的注意力系数图,笔者提出了WBCE-Tversky混合损失函数对主网络进行训练;其次,为了使辅网络生成覆盖面积更大、更宽松的辅助注意力系数图以补偿主网络可能发生的注意力系数图错误,还提出了容限损失函数对辅网络进行训练。
1.3.1 WBCE-Tversky损失函数
Tversky损失函数的定义如下:
(1)
其中,p0(i)g1(i)代表像素i是病灶却被判定为不是病灶,p1(i)g0(i)代表像素i不是病灶却被判定为是病灶,分别对应了预测结果的假阴性(False Negatives,FN)和假阳性(False Positives,FP)。通过配置Tversky损失函数β值的大小,可以在假阳性和假阴性之间取得权衡。由于脑卒中病灶体积远远小于正常组织,以ATLAS数据集[3]中的239个核磁共振影像为例,病灶和健康组织的比例大致是3∶1 000,即分割网络会因为数据不平衡性使模型更多的关注负类,将病灶预测为非病灶,带来较高的假阴性。通过增大β可以有效地降低假阴性,减少病灶被预测为非病变的倾向,以提升对不平衡数据分割的准确性。然而当式(1)中分母值为极小值时,会导致反向传播和求导的不稳定。为了解决这个问题,引入了加权的二进制交叉熵(Weighted Binary Cross-Entropy,WBCE)损失函数[9],其表达式为
(2)

Floss(β)=Wloss+Tloss(β) 。
(3)
1.3.2 容限损失函数
为了实现PAPAC-Net中的注意力系数图的补偿操作,辅网络需要生成一个覆盖面积更大、更宽松的AACCM。这种覆盖面积更大的注意力系数图,相当于在真实病灶区域的基础上增大了关注面积,即有目的、适度的、有约束的产生一定的假阳性,提升一定的假阳率F(False Positives Rate,FPR)。考虑到假阳率F=1-S,在模型的评价指标中,特异性S(Specificity)代表了负例被正确识别成负例的比例。特异性越小,假阳率越大,辅助注意力系数图越宽松。因此需要设计一个损失函数,在进行模型训练时可以有目的的、适度的降低网络的特异性,以生成一个适度宽松的辅助注意力系数图去实现PAPAC-Net辅网络的补偿功能。于是提出了“特异性减小项”R(Specificity Reducing Item,SRI),表达式如下:
(4)
由于损失函数的训练目标是使其值尽可能变得最小,即使式(4)中的S值 和δ的差的平方趋近于0,使S值逼近δ值,因此可以通过设定一个适度小的δ值,从而适度地减小模型的特异性,提升假阳率值,以生成适度宽松的辅助注意力系数图。然而,仅仅使用SRI去训练辅网络是不够的,因为其无法满足“有目的、有约束”的要求,否则可能会生成一个任意位置、任意形状的具有较高假阳率的辅助注意力系数图,无法正确地补偿主网络。为了有目的地约束SRI,将其和Tversky损失函数组合,提出了容限损失函数:
(5)
通过加入超参数λ来控制SRI项在总体损失函数中的权重,同样对Tversky损失函数项进行二次方以平衡公式的计算。引入Tversky损失函数,可以保证容限损失函数在生成较高假阳率、增大关注区的时候,其关注区域的位置、轮廓都不会与正确病灶产生较大偏离。作为训练约束,Tversky损失函数的参数β取值和WBCE-Tversky损失函数保持一致即可。
2 实验结果与分析
本章节2.1至节2.5首先使用开源脑卒中病灶分割数据集ATLAS对所提出的GAU-A-Unet和PAPAC-Net网络的构建原理和超参数选取进行详细验证和说明,并在节2.5给出不同模型在该数据集的对比实验结果,以验证方法的有效性;然后节2.6使用另一个缺血性脑卒中病变分割(Ischemic Stroke Lesion Segmentation,ISLES)数据集(2018年版本)进一步验证所提出方法的有效性。
2.1 实验设计
所有实验将使用相同的实验数据集划分方法、软硬件环境、参数设置和评价指标。ALTAS包含239个核磁共振影像数据,使用六折嵌套交叉验证(Nested-Cross-Validation)对该数据集根据病灶体积大小的分布规律,按照约4∶1∶1的比例划分为训练集、验证集和测试集。ISLES包含5种影像格式的94组影像数据,使用五折嵌套交叉验证,按照3∶1∶1的比例划分。选用Lookahead优化器[10]进行训练,该优化器在兼顾动态调整学习速率、加速梯度下降的基础上,提高了优化过程的稳定性。初始学习率设定为1×10-4。每次独立训练(包括使用不同网络结构、不同损失函数配置和不同交叉验证数据)的最大训练迭代次数设为100,使用“提前停止”(Early Stopping)的回调函数来控制模型的停止和参数的保存。当损失函数的损失值减少不超过0.001时,停止训练。实验采用Keras深度学习框架,使用英伟达GTX1080TI进行硬件加速训练。在训练过程中,没有进行数据扩张。由于所有的核磁共振影像数据在原始数据集已经进行过大脑影像的配准、图像归一化以及偏场矫正,所以不再进行额外的预处理操作,仅仅通过裁剪多余背景黑边来改变原始图像尺寸,以适应网络结构的输入要求。使用Dice相似度系数(Dice Similarity Coefficient,DSC)、F2得分(F2-score,F2)、准确率PRE(Precision)、召回率RE(Recall)和假阳率作为评价指标。由于脑卒中“漏检”的代价和成本昂贵,召回率显得更为重要,而F2恰好能够偏向于关注召回率;假阳率能够反映假阳性的水平,仅用于PAPAC-Net以等效评价所生成注意力系数图的宽松化水平,间接测量辅网络辅助补偿注意力系数的宽松化水平,以及证明补偿操作不会给主网络的分割结果带来较高的假阳性。
2.2 GAU-A-UNet在ALTAS数据集上的实验结果
将GAU-A-UNet与U-Net、Attention U-Net进行对比实验。从表1实验结果可以看出,GAU-A-UNet比Attention U-Net的DSC和F2明显提升,同时模型参数总数有所减少。证明了同样作为自注意力分割模型,所提出的GAU-A-UNet对比Attention U-Net能够提高脑卒中病灶的分割精度,并且降低了模型的复杂度。

表1 GAU-A-UNet模型对比验证
2.3 PAPAC-Net损失函数的超参数取值
为了测试和验证WBCE-Tversky损失函数用于训练PAPAC-Net的主网络的分割效果,并确定超参数β的最佳值,按照从0.5到1.0的范围以0.05的步长对其取值进行对比实验,并与单独使用WBCE和Tversky损失函数进行对比以证明其性能的提升。基于GAU-A-UNet使用上述不同损失函数和参数取值进行对比实验,并将实验结果根据β的不同取值画成了折线图(如图3所示)。WBCE损失函数无超参数β值的实验结果如下:DSC为48.31%、F2为47.45%、PR为65.17%和RE为46.66%。对比WBCE实验结果及图3(a)和图3(b),可以看出在不同β取值下,WBCE-Tversky损失函数的DSC和F2总体上均高于Tversky和WBCE损失函数。当β=0.8时,WBCE-Tversky损失函数取得最佳分割表现。由于Tversky通过调整β值可以起到权衡调整准确率和召回率的作用,较大的β可以抑制假阴性,提升假阳性,从而提升了召回率。因此,随着β的增大,准确率逐渐减小,召回率逐渐增大,这和图3(c)与图3(d)的实验结果一致。图3中WBCE-Tversky损失函数在准确率上整体好于Tversky损失函数,而在召回率上略低于Tversky损失函数。同时对比WBCE实验结果及图3(c)和图3(d)可以看出,当β=0.8时,WBCE-Tversky损失函数在准确率和召回率之间取得了平衡,均取得了折中的取值。综上,使用β=0.8的WBCE-Tversky损失函数训练PAPAC-Net的主网络,可以实现病灶的精确分割,同时也将β=0.8作为辅网络的容限损失函数用于约束宽松化注意力系数图的Tversky部分的参数取值。

图3 不同参数配置下的WBCE-Tversky和Tversky损失函数性能对比
前文提到,在PAPAC-Net的辅网络上使用容限损失函数以生成适度的、有约束的、覆盖面积更大、更宽松的AACCM,为此需要对参数β、λ和δ进行适当取值。在式(5)中,β来自Tvesrky,起到约束作用,将β值按照图3的实验结果设为0.8。而δ为式(4)中设定的特异性的逼近目标值。δ越小,所得到的假阳率越大,即得到的注意力系数图越宽松。因此将参数δ的取值范围设定为0.6、0.7、0.8或0.9,用于生成不同宽松化水平的AACCM。将参数λ的取值范围设定为1、2、3、4或5,用于调节SRI项在容限损失函数中的比重。依然在GAU-A-UNet上进行训练,并将实验结果画成了折线图,如图4所示。在图4(a)中,当δ值保持不变时,λ值越大,假阳率越高,这是因为较大的λ值为SRI项提供了更大的权重;而当λ保持不变时,δ值越小,假阳率越高,这是因为特异性以δ值作为训练目标,越小的δ值就会生成越小的特异性值。而F=1-S,因此随着特异性值的减小,假阳率会增大。
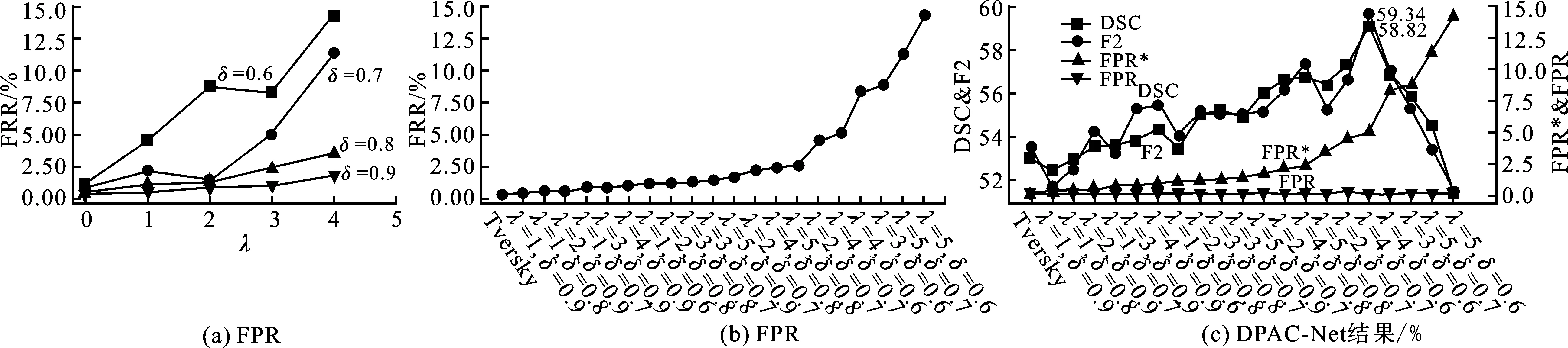
图4 不同δ和λ配置容限损失函数下的假阳率值曲线
将不同λ和δ取值对应的假阳率进行升序排序,如图4(b)所示,可以看出随着参数配置的变化,假阳率逐渐升高。当λ=5,δ=0.6时,假阳率取得了最大值,高达15.06%。从图4(a)可以看出,对于一对λ和δ的取值,其产生的假阳率与使用相邻较大(或较小)的λ和相邻较小(或较大)的δ产生的假阳率有时候数值会比较接近,也就是说假阳率的大小是λ和δ共同作用的结果。
2.4 PAPAC-Net在ATLAS数据集上的实验结果
本节依然使用节2.1的实验条件进行对比实验,以确定在PAPAC-Net上具有最佳的补偿效果和分割性能的λ和δ取值。将图4(b)升序排序后对应的λ和δ的配置组合应用到PAPAC-Net的辅网络中进行模型训练和验证,得到图4(c)所示的实验结果。其中FPR*为图4(b)中的假阳率升序排序后的结果,其代表了单独训练GAU-A-UNet时不同超参数组合的容限所产生的假阳率值,即等价于AACCM的宽松化水平。通过图4(c)可以看出,随着辅网络的FPR*值的升高,PAPAC-Net的DSC和F2逐渐升高,这说明随着AACCM的宽松程度的提升,其对主网络的补偿效果越来越明显。当λ=4和δ=0.7时,DSC和F2取得最大值。随着FPR*的值进一步增大,分割性能又逐渐下降。这说明并不是宽松化程度越高就越好。当FPR*值持续增大到较高水平时,会对主网络产生负作用,导致分割性能急剧下降。从图4(c)中可以看出,PAPAC-Net的主网络分割结果的假阳率值并没有因为辅网络宽松的AACCM具有较高FPR*值而同样变高,无论辅网络使用什么样的超参数组合,主网络分割结果的假阳率值都相对来说较低,这说明辅网络生成的宽松的AACCM补偿主网络的时候,并不会直接影响主网络的分割结果,它只是作为一个起到约束作用的辅助补偿系数出现的,不参与到主网络的梯度运算和反向传播,主网络依然遵循其进行严格分割的训练目的,不会生成较高的假阳性。综上,当PAPAC-Net的主网络选用β=0.8的WCBE-Tversky损失函数,辅网络选用β=0.8、λ=4和δ=0.7的容限损失函数时,可以实现对ATLAS数据集最高的分割精度。需要注意的是,主、辅网络损失函数的超参数β、λ和δ的取值与数据集的不平衡度有关,需要进行实验选取。
2.5 ATLAS数据集验证结果和计算效率对比
基于ATLAS数据集,文献[11]中提出一种在编码阶段融合了2D和3D的卷积特征的维度融合UNet(Dimension Fusion UNet,D-UNet)的结构;文献[12]中提出一种基于跨层融合和上下文推理的CLCI-Net的方法。上述文献结果将作为文中实验的性能参考。此外,使用以下模型进行对比实验以验证所提出PAPAC-Net的分割性能:① U-Net[6];② Attention U-Net[7];③ GAU-A-UNet;④ PAPAC-Net。其中①、②和③均采用β=0.8的WBCE-Tversky损失函数进行训练。实验结果如表2所示。
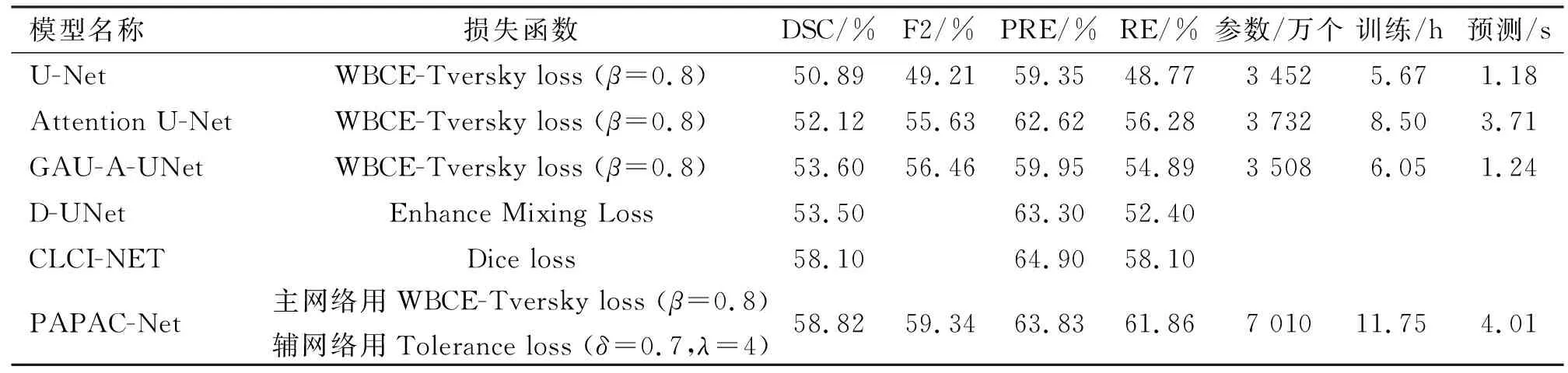
表2 ATLAS数据集上不同方法分割结果和运算效率对比
可以看出,从无注意力到有自注意力机制(对比U-Net和GAU-A-UNet),DSC仅提升2.71%;从单路径网络到主辅路径补偿网络(对比GAU-A-UNet和PAPAC-Net),DSC提升了5.22%。证明所提方法能够明显地克服在病灶特征不明显时自注意力模型潜在的生成错误注意力系数的问题。同时对比当前其他文献方法,PAPAC-Net比D-UNet提升了5.32%,比CLCI-NET提升了0.72%,说明了文中的方法在目前主流方法中依然具有出色的性能。在运算效率方面,从表中待训练参数数目可以看出,在单路径注意力模型中,Attention U-Net比U-Net 仅仅多了280万个,但是训练时间比U-Net增加了近50%。一个患者的核磁共振影像数据(本实验为176个2D图像切片)的预测时间也增大了2倍,这是因为基于注意力门模块的多通道矩阵点乘和相加运算需要消耗大量的GPU运算资源,从而使Attention U-Net训练和预测效率变低。而笔者提出的GAU-A-UNet使用全局注意力上采样代替解码路径注意力门模块,不仅减少了总的参数规模,同时降低了对GPU运算资源的消耗,因此GAU-A-UNet注意力模型在训练时间和预测时间上大幅度低于Attention U-Net。这使得在双路径注意力模型中,即便基于GAU-A-UNet的PAPAC-Net待训练参数数目几乎翻一倍,PAPAC-Net的训练时间也仅仅比Attention U-Net增加不到40%,预测时间几乎没变。考虑到PAPAC-Net比Attention U-Net的DSC提升了6.7%,分割性能的显著提升,弥补了训练时间的增加。
2.6 ISLES数据集上不同方法验证结果对比
为了进一步验证所提方法的有效性,选用了另一个脑卒中病灶分割数据集ISLES,基于表2中的前4个模型进行对比实验,并将StrokeNet模型[13-14]作为本实验的性能参考。该文献提出一种3D残差网络,利用多级的3D精炼模块自动聚合3D卷积层中的局部细节和时空上下文信息,从而显著地提高性能,且该网络使用Focal Loss[15]进行训练来解决数据不平衡问题。实验结果如表3所示,可以得出和表2一致的实验结论。这里需要注意的是,对于不同的数据集PAPAC-Net,主、辅路径损失函数的超参数选取与各数据集的不平衡度相关,经过对比实验选取超参数β=0.7、λ=4和δ=0.8,可以使PAPAC-Net在ISLES数据集取得最佳分割性能。

表3 ISLES数据集上不同方法分割结果对比
3 总 结
笔者提出了PAPAC-Net网络结构,通过在其主、辅网络上使用不同功能的损失函数,实现辅网络生成宽松的AACCM对主网络注意力系数图进行补偿,从而解决了当病灶特征不明显时,主网络生成错误的注意力系数图而影响模型分割性能的问题。为了实现上述功能,分别提出了WBCE-Tversky和容限损失函数,用以训练主、辅网络。实验证明,所提出的PAPAC-Net模型,比单独使用GAU-A-UNet时DSC提升了5.22%,证明了主、辅路径双通道注意力补偿方法相对于单通道注意力方法在分割性能上有明显的提升。同时对比其他文献的方法,实验结果也证明了所提方法的有效性。需要注意的是,尽管笔者提出的方法在ATLAS数据集上对比了D-UNet、CLCI-Net,在ISLES数据集上对比了StrokeNet,但考虑到训练集、验证集、测试集的划分方法以及各自使用的损失函数不同,因此虽然所提方法在对比中达到了更好的分割结果,也仅表明笔者提出的方法达到了目前同样研究中的较高水平。
在未来的工作中,将基于其他适用于不平衡数据的损失函数,例如基于StrokeNet所采用的Focal损失函数设计和改进损失函数用于PAPAC-Net训练,从而进一步提升分割性能。
