利用密集卷积神经网络的语音变换欺骗检测
2021-09-02苏卓艺朱铮宇
王 泳,苏卓艺,朱铮宇,2
(1.广东技术师范大学 网络空间安全学院,广东 广州 510665;2.华南理工大学 音频、语音与视觉处理实验室,广东 广州 510641)
语音欺骗可以分为两类[1]:① 假冒欺骗,即利用某种手段产生或获得被假冒的目标人物的语音,从而令识别系统误判该语音为被假冒人所说,主要包括语音转换(Voice Conversion,VC)、语音合成(Speech Synthesis,SS)和语音重播等操作;② 隐藏欺骗,即通过变换说话人的声音(没有模仿任何目标人物)令识别系统无法判断该说话人的身份,此类操作一般也统称为语音变换(Voice Transformation,VT)欺骗。已有研究[2-3]表明,两类欺骗均可轻易骗过目前的说话人识别(Automatic Speaker Recognition,ASR)系统,对社会安全构成威胁。
目前相关的安全研究主要集中在假冒欺骗的检测上[4-21],而对VT欺骗的检测研究则相对非常不足。文献[22-24]提出利用梅尔频率倒谱系数特征和支持向量机分类器的VT检测算法,跨数据库的识别率低于90%,且该方法计算量非常大。LIANG等人提出一种基于卷积神经网络(Convolutional Neural Network,CNN)[25]的VT检测方法,但准确率小于95%,表明实际应用中仍需要改进。
事实上,假冒欺骗通常需要大量的目标说话人的语音信息,实现成本相对较高;而隐藏欺骗不需要任何额外的信息,且已有成熟的算法产生自然度极高的欺骗语音,已集成在众多的音频、语音处理工具中,相较假冒欺骗更多地运用在各种欺诈案件之中。因此,研究VT隐藏欺骗的检测具有重要的理论和实用价值。另一方面,目前已有的检测方法一般采用人工设计特征和分类识别结合的传统机器学习方法,特征设计比较困难且不稳定,影响检测效果。综合以上情况,并鉴于深度学习框架具有自动提取深度特征的功能,笔者提出了一种基于密集卷积神经网络的VT欺骗检测方法,总共包含135层的网络层,该网络通过最大化短路径的连接强化数据传输,可同时利用深层和浅层边缘特征进行分类,抑制退化现象。
1 欺骗检测特征
语音欺骗操作涉及改变信号的频域成分。由傅里叶变换性质可知,频域的变化会带来信号的时长(节奏)变化。但通常情况下,欺骗操作希望保持时长(节奏)不变。另外,由于频域的离散化,离散傅里叶变换得到的系数一般并非真实频率,而是与真实频率有一定误差。为此,众多音频处理工具中的VT操作是基于相位-声码器原理,即利用短时傅里叶变换(STFT)中的相位信息估计信号的真实频率(瞬时频率),并进而修改瞬时频率。此方法既能提高频率估计精度,从而得到听觉更自然的变换语音,同时亦打破由傅里叶变换造成的时域和频域之间的关联,在伸缩瞬时频率的同时保持节奏不变。VT操作[26]的一般过程如下。
(1) 对信号x(n)分帧、加窗(窗函数可采用汉宁窗或海明窗):
(1)
(2) 计算瞬时幅值:
(2)
(3) 通过本帧与前一帧的相位关系计算瞬时频率:
(3)
其中,Fs是抽样频率,Δ是相对中心频率的偏移频率。具体计算过程与文中内容无关,不再赘述;若有兴趣则请参阅文献[26]。
(4) 频谱伸缩。首先是瞬时幅值线性插值:
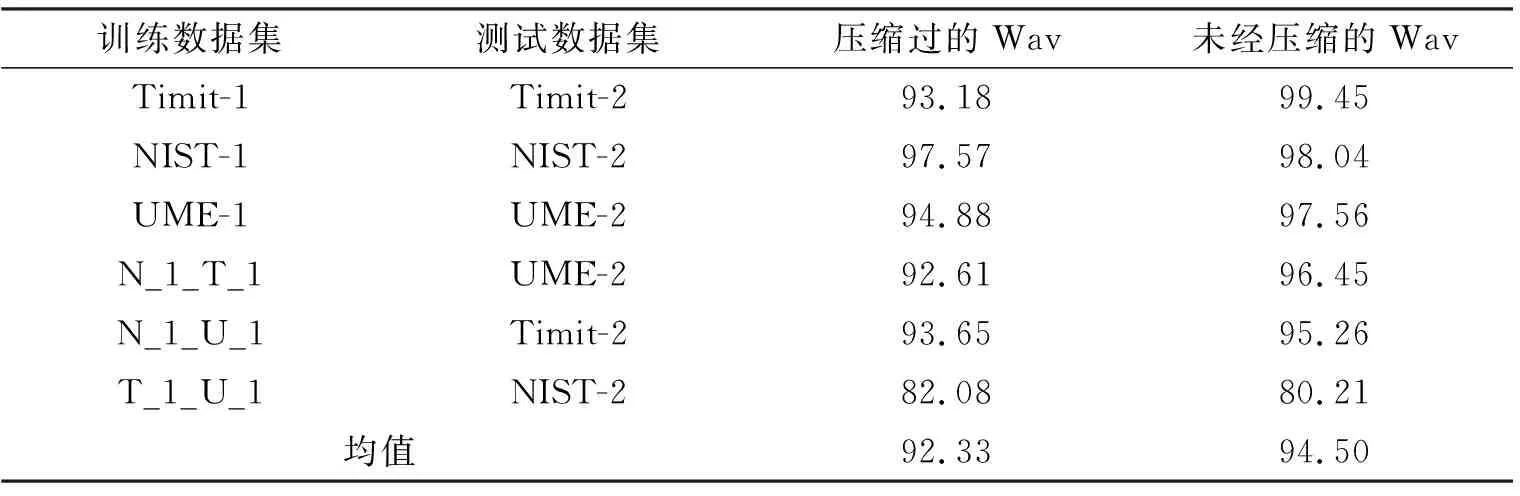
|F(k′)|=μ|F(k)|+(1-μ)|F(k+1)|, 0≤k (4) 接着进行频线搬移: ω′(kα)=ω(k)α, 0≤k (5) 在不会引起误会的前提下,仍记搬移之后的瞬时频率为ω(k)。 (5) 由瞬时频率计算瞬时相位φ(k),获得变换后的快速傅里叶变换系数: F(k)=|F(k)|exp[jφ(k)] 。 (6) (6) 对F(k)进行快速傅里叶变换反变换,即可获得变换后的信号。 根据语音学原理,α可以表示为以半音s为自变量的方程[27],其表达式为 α(s)=2s/12, (7) 其中,可以取[-12,+12]范围内的任何整数值,代表不同的伪装程度。伪装程度过低,会与原始语音非常接近;伪装程度过高,容易引起不自然的听觉效应,这两种情况均不容达到欺骗目的。因此,文中考虑的伪装程度为s取[-8,-4]和[+4,+8]两个范围内的值,这两个范围具有最强的欺骗效果。 根据前面描述的VT欺骗原理,VT操作会向语音信号的频谱引入变化,这些频率成分的变化可以作为区别原始语音和伪装语音的依据。另外,直接的时域采样数据的特征分布通常非常稀疏,并不适用于卷积神经网络,而时频图的语音特征分布则相对密集,更有利于神经网络提取特征。因此,笔者将时频图作为网络的输入数据。 常规的卷积神经网络为前一层网络的输出Xl-1传送到下一层作为输入,经过非线性操作Hl输出Xl,即 Xl=Hl(Xl-1) 。 (8) 此非线性操作一般包括卷积、池化以及激活函数。 一般情况下,为了提取到更深层的特征用于分类,会设计出层数较多的模型。但随着网络层数的加深,网络在训练过程中的前传信号和梯度信号在经过若干层之后会逐渐消失,从而会出现训练到一定程度时,训练精度随着训练次数的增加而缓慢升高,而测试精度却反而下降的情况,称为退化现象。为解决退化问题,残差网络(ResNets)[28]、高速公路网络(Highway Networks)[29]和分形网络(FractalNets)[30]中都提出了一种数据短路径(Skip-Layer)技术来使得信号可以在输入层和输出层之间高速流通。核心思路是通过创建一个跨层连接来连通网络中的前后层,从而抑制退化现象,即 Xl=Hl(Xl-1)+Xl-n, (9) 其中,Xl-1代表短路径。 然而,这种连接方式导致许多网络层贡献很小,却占用大量计算。为此,笔者进一步拓展加入短路径这种思路,提出了一种改进结构的密集卷积神经网络(DenseNet)。具体做法是:为了最大化网络中所有层之间的信息流,将网络中的所有层两两进行连接,使得网络中每一层都接受它前面所有层的特征作为输入[31]。即在此结构中,任何层都直接连接到网络中的所有后续的层,其表达式为 Xl=Hl([X0,X1,…,Xl-1]) , (10) 其中,X0,X1,…,Xl-1表示l层前面所有层的输出,[…]表示连续操作。此外,密集卷积神经网络中每个网络层都有k个特征映射,得到k个特征图,k通常设置为一个较小的值。 这种密集连接方式相对于前面提到的网络具有显著的优势:① 每层的输出特征图都是之后所有层的输入,保证了层间最大的信息流,增强了特征传播;② 网络层变得更窄(即k值变小),减少了参数数量,减轻了退化问题,并且支持有限神经元的复用。另外,参数数量减少亦产生正则化效果,对过拟合有一定的抑制作用;③ 不需要重新学习冗余的特征图,更利于模型的训练。 基于2.1节介绍的网络结构,笔者进一步构建135层密集神经网络分类模型(135-DenseNet),结构如图1所示。输入是语音信号的时频图,图片大小为90×88。本网络使用长宽等长的卷积核和池化,较适合长宽等长的输入图片。利用Matlab中的spectrogram计算时频图,当片段长度为1 s、采样率为8 kHz且窗长度取127时,获得的视频图大小为90×88,最接近正方形,故输入时频图取90×88。网络由1个初始化层(initial layer)、3个密集模块(dense block)、2个转换层(transition layer)、1个全局池化层(global pooling layer)以及1个线性层(linear layer)组成。3个密集模块分别由6层、12层和48层瓶颈层(bottleneck layer)组成。线性层是一个完整的全连接层,利用softmax输出“真实”和“欺骗”两个概率。 各层的内部结构如图2所示。图2中k表示的是卷积核的数量。每个卷积瓶颈层包含2个卷积层,每个转换层包含1个卷积层,这样整个网络总共包含2×(6+12+48)+1+1+1=135个卷积层。值得注意的是,瓶颈层包含1个1×1卷积层和1个3×3卷积层,对比一般的两个3×3的卷积层减少了计算。转换层的作用是连接两个相邻的模块且可以减少特征图的大小。 笔者以其中一段语音作为例子,其原始语音及欺骗语音的时频图以及图1中模块1的特征映射在图3中给出。笔者知道,通常原始语音的时域特征分布过于稀疏,不利于卷积神经网络提取特征。而从图3(a)中可以看出,时频图具有相对集中的纹理结构,意味着特征相对集中,更有利于神经网络的特征提取。从图3(b)和(c)中可以看出,该神经网络能有效地捕获有用特征。 实验中使用了3种语料库,分别是Timit(6 300个片段,630个说话人)、NIST(3 560个片段,356个说话人)和UME(4 040个片段,202个说话人)。语料库都是WAV格式,8 kHz采样率,16 bit量化和单声道。每个语料库分为以下两组: (1) 训练集:Timit-1(3 000个片段),NIST-1(2 000个片段),UME-1(2 040个片段); (2) 测试集:Timit-2(3 300个片段),NIST-2(1 560个片段),UME-2(2 000个片段)。 每个片段被进一步切割成多个1 s的片段。每组1 s片段的数量如表1所示。 (a) 原始语音时频图 (b) 欺骗语音(变换工具Audacity,伪装程度系数S取+6)时频图 (d) 欺骗语音时频图经由神经网络模块1后的特征映射 表1 每个语料库中的1 s片段数 本实验考虑Audacity、Cool Edit、PRAAT和RTISI等4种常见的欺骗方法(工具),伪装因子在[-8,-4]和[+4,+8]之间。由于欺骗样本的数量是真实样本的40倍,为解决此数据不平衡的问题,在计算真实语音的时频图时,每次移动200个采样点计算一个频谱图,使真实样本的数量与欺骗样本的数量相等。 笔者使用ADAM优化器来训练带有L2正则化的密集卷积神经网络损失函数,其中β1和β2分别为第1指数和第2指数衰减率估计,大小为0.900和0.999。学习率和舍弃率分别设置为0.000 1和0.300 0。训练批次数为100 000次,批次大小为64个。采用检测准确率d来测量模型的性能,即 d=(Gd+Sd)/(G+S) , (11) 其中,G和S分别为测试集中真实和欺骗片段的数量,Gd和Sd分别为从G中正确检测到的真实片段和从S中正确检测到的欺骗片段的数量。 测试集和训练集来自同一个语料库。该方法的检测结果和其他方法的结果如表2所示。从表2可以看到,笔者方法的平均检测准确率比LIANG等人采用传统CNN模型的方法高2.58%,比WU等人提出的MFCC-SVM方法高3.66%。 笔者提出的方法优于另外两种方法,是因为DenseNet模型比常规的CNN拥有更多的网络层,它可以提取更多更深层次的特征以作分类。此外,在常规的CNN中,决策仅仅是由深度特征决定的。但在DenseNet中,由于连接方式密集,决策既具有深度特征又参考了早期的边缘特征,从而进一步提高了检测的准确率。 表2 同源语料库测试的检测准确率 % 在现实场景中,测试语音和训练语音可能有不同的来源,所以它们可能具有不同的特征。因此,笔者进行了跨语料库的评估,以测试所提方法的泛化能力。实验选取3个语料库中的一个作为测试数据集,另外两个库作为训练数据集,实验结果如表3所示。笔者可以看到,实验1和实验2具有优良的结果,但实验3并不理想。笔者分析的原因是NIST的数据量远大于表1所示的另外两组,其训练得到的模型具有更好的泛化能力。在LIANG等人的方法[25]中,实验1的准确率约为94.37%,而笔者的准确率约为96.45%,说明笔者提出的方法优于LIANG等人的方法。其他两个方案的结果没有在LIANG等人的实验中显示。 表3 跨语料库检测准确率 % 在实际应用中,录音和传输过程可能会引入噪声,影响检测的准确率。在这部分,笔者将高斯白噪声加入到数据集中以评估其对噪声的鲁棒性。具体来说,笔者在每个干净的语音训练集上分别加入10 dB、20 dB和30 dB的高斯噪声,然后利用加噪数据集和干净数据集对网络进行训练。 在测试中,笔者在每个干净测试集上分别加入10 dB、15 dB、20 dB和30 dB的高斯噪声,然后测试每个加噪测试集和每个干净测试集的正确率,如表4所示。从表4第4列可以看出,即使在加入10 dB信噪比噪声的情况下,准确率基本保持在90%左右,说明笔者的方法对噪声攻击具有良好的鲁棒性。需要注意的是,15 dB噪声的数据集是没有出现在训练集中的,其测试结果在第4列的数据中显示。笔者可以看到,与第3、5、6、7列中的其他条件相比,即使没有15 dB的训练样本,亦获得较高的测试准确率。 表4 噪声条件下的检测准确率 % 由于音频压缩在存储与传输中几乎是必需的,在本节中测试文中方法对MP 3压缩的鲁棒性。笔者分别对训练集和测试集进行MP 3压缩,压缩比为16∶1,实验准确率如表5所示。在压缩情况下,平均准确率约为92%,与非压缩情况相比,经过压缩的语音检测准确率只有轻微的下降,说明该方法具有较强的抗压缩能力。 表5 在压缩和非压缩情况下的检测准确率 % 笔者提出了一种基于密集卷积神经网络的欺骗语音检测方法。所设计的135层密集神经网络能自动提取浅层的特征以及深层的边缘特征并用于分类。实验结果表明,其检测性能优于目前已有的方法。并且通过对卷积核的优化和瓶颈层的使用提高了计算效率。未来的工作将集中在应用更深层次的网络结构来提取更深层次的特征,进一步提高准确率。
2 模型框架说明
2.1 密集神经网络
2.2 135层密集神经网络
3 实验结果
3.1 实验语料库和设置




3.2 同源语料库测试

3.3 跨语料库评估

3.4 噪声鲁棒性

3.5 压缩鲁棒性
4 结束语
