基于改进DSets 的无参数雷达信号分选算法
2021-08-31刘鲁涛王璐璐陈涛
刘鲁涛,王璐璐,陈涛
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
0 引 言
随着电子信号的发展和进步,电磁环境变得越来越密集和复杂,使得雷达信号分选成为电子情报和电子战不可或缺的部分。雷达信号分选是将随机的雷达信号脉冲从其自身雷达信号源中分离出来[1]。现阶段主要通过预分选与主分选相结合来完成对混合雷达脉冲信号的分选,接收机接收 到 的 脉 冲 描 述 字 (pulse description word, PDW)主要有载频、脉宽、方位角、脉幅和到达时间这5 个参数,其中脉幅受环境影响较大,通常使用载频、脉宽和方位角这3 个参数进行预分选[2-3]。然而,给出精确预分选结果的前提是能够正确分选,故其在整个分选过程中显得尤为重要。
预分选算法主要分为3 大类:划分聚类法、网格聚类法和密度聚类法[4]。划分聚类算法中最具有代表性的是K 均值聚类(K-means) 算法[5]和模糊C 均值聚类(FCM)算法[6],其中FCM 算法本质上是对K-means 算法的改进。网格聚类法是将给定的脉冲数据集先划分为若干类(类型数量≤数据集),然后通过迭代重定位技术重新划分,直至找到局部最优的聚类方法。密度聚类法是以数据集在空间分布上的稠密程度为依据而进行的聚类,多以基于密度的噪声应用空间聚类 (densitybased spatial clustering of applications with noise,DBSCAN)算法为基础[7-8]。
尽管上述聚类算法高效准确地完成了对雷达信号脉冲的聚类,但是这些算法聚类性能严重依赖于聚类参数、阈值等的选取,例如聚类半径、聚类数目等。因此,本文将使用直方图均衡化后的DSets 算法(该算法不需要输入任何参数就能直接给出聚类结果),然后针对DSets 原有算法的过度分割问题,提出将D-S 证据理论[9-10]应用于初始聚类结果,给出融合后的最终聚类结果。
1 相关理论研究
1.1 主导集(DSets)算法
DSets 聚类将主导集定义为主导集图论的概念,并试图顺序提取聚类。主导集是满足簇的高内部相似性和低外部相似性约束的数据子集,因此可以被视为簇。通过博弈动力学检测到主导集并从输入数据中删除内部数据,在剩余数据中重复此过程,直到满足停止标准为止,以此来获得输入数据的分区。其中,每个分区对应一个聚类,且簇的数量是自动确定的。DSets 聚类使用数据的成对相似性矩阵作为输入,对数据的表示形式没有要求。

下面给出DSet 定义,一个非空子集S∈V满足以下条件可以被称为主导集:
1)任意非空子集T∈S,均有W(T)>0;
2)任意顶点i∈S,均有wS(i)>0;
3)任意i∉S, 均有wS∪{i}(i)<0。
在定义中,前2 个条件对应于DSet 的高度内部相似性,第3 个条件则指出若包含任何来自外部的数据,内部相似性将被破坏。在这些条件共同作用下,DSet 将成为数据的最大一致性子集。
文献[11] 中给出了求解DSet 的简单方法。集群内部相干性的自然表示方法是f(x)=xTAx,其中xT表示转置。由此,可以将聚类问题公式化为寻找使f最大化的向量x的问题:

1.2 图像增强技术
直方图均衡化是一种典型的图像增强技术。它通过应用灰度变换来增强图像对比度,使图像的直方图扁平化。经过变换后,图像的直方图变成了原始图像的累积直方图的缩放版本。直方图均衡化变换的具体方法如下:

1.3 D-S 证据理论数据融合
D-S 证据理论是贝叶斯推理方法的推广,能够较好地描述“不确定”和“不知道”类型问题,因此可以采用D-S 证据理论对DSets 聚类结果PDW参数进行融合处理,以此消除DSets 算法的过度分割问题[12]。

D-S 证据理论计算一组证据的特征属性与各个框架属性的相似度,利用D-S 组合规则得出测量数据与框架的总体相似度来进行识别。计算不同信号总体的相似度,可将其中一个视为识别框架,通过计算两者的总体相似度,并与阈值比较来判定是否关联。
1.4 F 均值(F-measure)
评估聚类的指标有很多,其中F-measure 即F 均值是常用的一种聚类指标。为了描述F-measure,先给出2 个概念公式。
准确率:


2 算法流程
2.1 直方图均衡化
脉冲描述字(PDW)主要包括5 个参数:方位角(doa)、载频(cf)、脉宽(pw)、脉幅(pa)和到达时间(toa),在进行雷达信号预分选时,通常会选择doa,cf和pw这3 个参数。
DSets 算法在进行脉冲聚类预分选时是顺序提取集群。首先,计算3 个参数的复合相似性矩阵;然后,再将处理后的相似性矩阵输入到算法中,根据集群性质,通过进化博弈论中发展起来的复制因子动力学求解聚类结果;最后,将求解的结果进行基于D-S 证据理论的数据融合,给出最终聚类结果。图1 所示为改进后DSets-DS 算法流程。
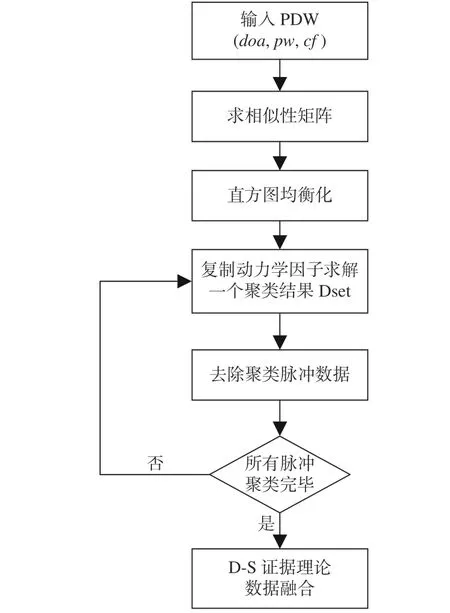
图1 DSets-DS 算法流程图Fig. 1 Flowchart of DSets-DS algorithm



从相似性度量s(pulsei,pulsej)计算公式可以看出,不同的 σ会导致不同的相似性度量,同时导致不同的相似性矩阵。尽管DSets 算法不需要明确地输入任何参数,但实际上它也依赖于参数σ。因此,为了得到一个无参数聚类,必须消除参数σ对算法的依赖。
从文献[11] 中可见,不同 σ得到的相似性矩阵之间的差异主要在于相似性对比,这些差异与不同灰度对比度的图像之间的差异非常相似。因此,利用图像增强技术可以使不同的 σ生成相同的相似性矩阵,从而得到相同的聚类结果。
s1(pulsei,pulsej)的相对大小只取决于元素之间的距离,与 σ无关。即将相似性矩阵A中的元素s1(pulsei,pulsej) 按递增顺序排列,在不同 σ条件下得到的排序相同。通过式(6) 完成直方图均衡化,以此来消除相似性矩阵A对 参数 σ的依赖,直方图均衡化后的相似性矩阵记为Ahisteq。为了便于表达,本文在下文使用DSets-histeq 表示DSets聚类算法,该算法在聚类之前将直方图均衡化应用于相似性矩阵。
由直方图均衡化处理后的相似性矩阵给出集群内部相干性的自然表示方法:f(x)=xTAhisteqx。然后,利用进化博弈论中发展起来的复制因子动力学求解 maxf(x),得到一个聚类结果DSet 并提取,如式(15)所示。

2.2 D-S 证据理论融合
由于DSets 算法对集群内部的元素有一个强密度约束,所以会导致聚类结果存在过度分割现象,将同一个聚类结果中的元素分割成2 个或2 个以上的聚类结果,所以在进行DSets 算法后,还需要对求得的聚类结果使用D-S 证据理论技术进行相似性融合。

然后,再根据m1与方位角的相似度属性,得到总体支持度,如式(20)所示。

5)转到步骤3),直到完成所有脉冲聚类;
6)对分类结果进行基于D-S 证据理论的融合,给出最终聚类结果。
3 仿真实验
本节经软件仿真对算法进行可行性验证,通过对设定的雷达信号进行聚类来测试算法的聚类效果。由于DSets 算法完成了对雷达脉冲的无参数聚类,因此通过仿真测试本算法是否能达到目标。此外,还与现有算法的结果进行了对比,以进一步验证本算法的聚类性能。
3.1 直方图均衡化
为了验证直方图均衡化能否消除对 σ的依赖,在仿真中,将直方图均衡化前后的仿真结果进行比较。输入为无虚假脉冲的5 部雷达信号的混合脉冲,共计400 个。为了使实验结果更具有说服力,完成了多次蒙特卡洛仿真实验,且取平均值作为仿真结果的输出。本文通过式(13)计算F-measure 来评估聚类质量,并报告聚类结果。
直方图均衡化对DSets 算法的影响如图2 所示,其中 σ的实际值等于d¯与横坐标相应值的乘积,这适用于本文中水平轴为 σ的其他图形。从图中可以看出,在使用直方图均衡化后大大降低了DSets 算法对参数 σ的依赖。

图2 直方图均衡化对DSets 算法的影响Fig. 2 Influence of histogram equalization on DSets algorithm
3.2 改进算法与DSets-histeq 对比
为了查看DSets-DS 算法是否解决了过度分割的问题,本文给出了DSets-histeq 和DSets-DS 算法在相同输入下的聚类结果对比(图3)。输入设定为由3 部和4 部雷达组成的混合脉冲序列,虚假脉冲比例为0。
图3 中同一个颜色的点代表聚类结果为同一个类别中的脉冲。从图中可以看出,本算法已经解决了过度分割的问题。为了更直观地给出2 种算法的实际聚类数目,在表1 中分别给出了仿真获得的集群数量。由表可见,DSets-DS 算法的集群数量比DSets-histeq 的集群数量少得多,且更接近于实际情况,进一步验证了改进的DSets-DS 算法在克服过度分割方面的有效性。
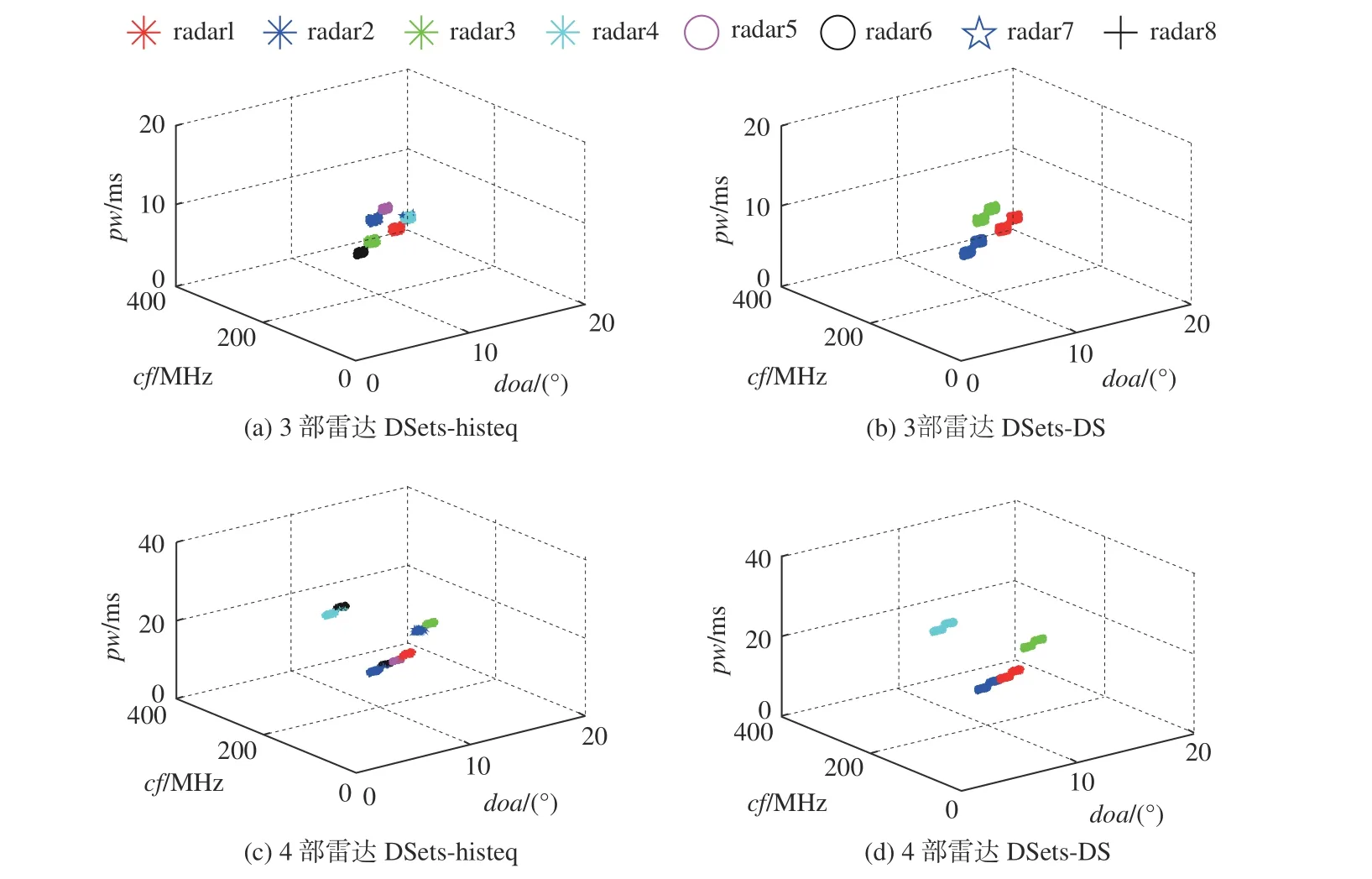
图3 雷达混合脉冲聚类结果Fig. 3 Results of radar mixed pulse clustering

表1 两种算法分选结果Table 1 The sorting number of two algorithms
图4 所示为DSets-DS 与DSets-histeq 算法的仿真结果对比图。从图中可以看出,随着虚假脉冲比例的增加,2 种算法的性能都有所下降,但是本文算法下降幅度较小,且性能始终优于DSetshisteq 算法。其原因在于,本文算法使用了D-S证据理论对聚类结果进行融合,提高了算法的准确率。可见,将D-S 证据理论应用于DSets-histeq算法是有效的。

图4 改进算法与DSets-histeq 算法对比Fig. 4 Comparison of the improved algorithm with DSets- histeq algorithm
3.3 与已有算法对比
为了评估本文算法在高虚假脉冲比例条件下的分选性能,图5 给出了其与K-means 算法在不同虚假脉冲比例条件下的结果对比。图中,纵坐标为多次F-measure 平均值。从图中可以看出,随着虚假脉冲比例的增加,2 种算法的分选性能都有不同程度的下降,但是本文算法在不同虚假脉冲比例的条件下性能都优于K-means,这是因为DSets 聚类倾向于生成超小簇,然后使用D-S 证据理论将生成的超小簇进行融合得到最终聚类结果,所以DSets-DS 算法不会将虚假脉冲聚类,这样得到的聚类结果受虚假脉冲比例的影响较小。此外,在虚假脉冲比例低于50%的情况下,本文算法分选正确率在93.13%以上。

图5 改进算法与K-means 算法对比Fig. 5 Comparison of the improved algorithm with K-means algorithm
4 结 论
由于截获的雷达信号没有先验信息,外界输入的参数严重影响常规聚类算法的性能。本文使用的DSets 算法经过直方图均衡化后不需要人为输入任何参数就可以直接完成聚类,然后将D-S证据理论应用于DSets-histeq 聚类结果,解决了DSets-histeq 算法过度分割的问题。通过实验仿真验证,在没有任何输入参数及先验信息的情况下,算法可以有效地完成对复杂环境中的雷达脉冲信号聚类,实现了无参数聚类,经过D-S 证据理论融合后的结果,不存在过度分割的问题。对比已有雷达脉冲聚类算法,改进的DSets 算法有更好的聚类性能,且在虚假脉冲比例低于50%的情况下,算法分选正确率在93.13%以上。
尽管算法完成了无参数聚类,但是由于得到的聚类结果中的脉冲间具有高度相似性,所以对于捷变频等复杂调制体制雷达聚类具有局限性,这将是今后的研究方向。
