大规模黑箱优化问题元启发式求解方法研究进展
2021-08-31江璞玉刘均周奇程远胜
江璞玉,刘均,周奇,程远胜*
1 华中科技大学 船舶与海洋工程学院,湖北 武汉 430074
2 华中科技大学 航空航天学院,湖北 武汉 430074
0 引 言
船舶优化设计是业界十分关注的问题之一,例如船舶水动力性能的优化[1-2]、舱段结构优化[3-4]、声性能优化[5]等。船舶优化设计的目标函数或约束条件通常是由数值仿真方法(例如计算流体动力学(CFD)方法、有限元方法(FEM)、边界元方法(BEM)等)计算得到,一般具有如下显著特点:一是无法采用显式解析式得到;二是计算时间较长。学界将具有前者特点的优化问题称为黑箱(black-box)优化问题,后者称为昂贵优化问题。通常,将单一目标约束优化问题定义如下:

式中,y=f(x)为 目标函数,x=(x1,···,xd)为设计变量,下标d表示设计变量的维度;gi(x),hj(x)分别为第i个不等式约束和第j个等式约束;n,m分别表示不等式约束和等式约束的个数。
由于约束优化问题可以通过惩罚函数法(penalty function method, PFM)、拉格朗 日 乘子(Lagrange multiplier)法等转化成无约束优化问题,故不失一般性,本文主要讨论单一目标无约束优化问题。
对于黑箱优化问题,式(1)中的目标函数或约束函数解析式与梯度无法获得,传统的基于梯度的优化方法不再适用于黑箱优化问题的直接求解。而元启发式算法(meta-heuristic algorithm)通过对决策空间的部分子集进行采样来搜索优化解,具有不需要目标函数的梯度信息和适用性广等特点[6],故成为了解决黑箱优化问题的有效途径。其中,代表性的元启发式算法有遗传算法(genetic algorithm, GA)[7]、差分进化(differential evolution, DE) 算法[8]、粒子群算法(particle swarm optimization, PSO)[9]、进化策略(evolutionary strategies,ES)[10]等。图1 所示为元启发式算法的流程图。

图1 元启发式算法流程图Fig. 1 Flowchart of meta-heuristic algorithm
如果黑箱优化问题设计变量的维度很高,则称之为大规模黑箱优化问题(large-scale black-box optimization problem, LBOP),例如,大型船舶的中剖面优化、舱段结构优化。对于求解LBOP 问题,若以各板列板的厚度、骨材间距和骨材型号作为设计变量,可能会有成百上千的设计变量,就目前而言,求解包括了如此多设计变量的优化问题将非常具有挑战性。鉴于黑箱优化问题的特性,元启发式算法仍然是优秀的求解算法之一。然而,对于求解LBOP 问题,在低维优化问题上表现优异的大部分算法的性能下降十分严重。其原因是,随着维度的增加,设计空间体积也随之呈指数增长。若设计方案的目标函数评价没有达到足够的次数,现有优化算法就很难对如此巨大的空间进行充分探索。关于设计变量的维度达到多少可定义为大规模优化问题,目前尚无定论。但对于进化计算,一般认为设计变量的维度达到1 000~5 000 即可定为LBOP 问题[11]。
可见,提出高效求解LBOP 问题的元启发式算法,对于提高船舶优化设计效率、缩减设计周期以及提升设计质量都具有重大意义。本文拟对目前处理LBOP 问题的元启发式算法进行总结分析,提出未来可能的研究方向或重点,以便为相关领域感兴趣的学者提供参考。
1 处理大规模优化问题的方法
一般地,根据是否基于分解策略方法来处理LBOP 问题,可以将元启发式算法分为两个大类,表1 列出了归纳汇总的相关文献,下文将分别对这两个大类算法中的代表性算法进行综述。

表1 大规模黑箱优化问题元启发式算法研究文献汇总Table 1 Summary of research advances using meta-heuristic algorithms for LBOPs
1.1 不使用分解策略的方法
此类方法中将LBOP 问题作为一个整体来处理,通常是结合局部搜索、缩减搜索空间、改进进化算子等途径来克服LBOP 问题引起的各种困难。具有代表性的是MA-SW-Chains 算法[40],该算法曾在IEEE CEC 2010 年年会LBOP 问题竞赛中获奖,性能十分优秀。MA-SW-Chains 算法也是对MA-CMA-Chains 算法[41]的改进,属于文化基因算法(memetic algorithm,MA),通常是指进化算法(evolutionary algorithm,EA) 和 局 部 搜 索 的 混 合体。MA-SW-Chains 算法在GA 中使用了SW (Solis-Wets)算法[119]作为局部搜索方法,通过建立不同的局部搜索链,给种群中每个个体分配一个取决于其特征的局部搜索强度,以此提高算法对LBOP问题的优化性能。而不使用分解策略的元启发式算法又主要分为EA 算法和群智能算法(swarm intelligence algorithm,SIA) 两类,其中又以DE 和PSO 为两个代表性算法。下文将主要介绍基于DE 和PSO 算法的元启发式算法。
1.1.1 基于DE 的改进算法
DE 算法是EA 算法中的典型算法之一,其一般流程如图2 所示。

图2 差分进化算法流程图Fig. 2 Flowchart of differential evolution algorithm
DE 算法因其良好的全局搜索能力和易于使用的特点,成为了被研究的热门算法。事实上,图1所示流程也是绝大多数EA 算法的流程,只需要将DE 算子变为其他的进化算子来产生后代即可。DE 算法的核心操作在于交叉和变异算子(crossover and mutation operator),大 部 分 对DE 的改进都着重改进交叉和变异算子,以此增强处理LBOP 的能力。例如,拥有可选外部库的自适应差分进化(adaptive differential evolution with optional external archive,Jade)算法就是对DE 算法的改进[12],其框架与基本DE 框架大体相同。与后者相比,Jade 算法增加了额外的样本库A,用以存储进化过程中被淘汰的个体。Jade 算法改进了基本DE 的变异算子,将其改为如下形式:
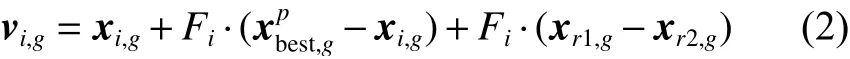

Takahama 等[13]提出了一种函数模态检测方法,通过在种群中心点和最佳个体形成的直线上进行采样,以此来判断该直线上的目标函数是单峰还是多峰,并根据判断结果自适应地调整DE变异算子中缩放因子的值。Brest 等[14]提出的自适应差分进化算法(self-adaptive differential evolution algorithm, SaDE)使用种群规模缩减技术,根据随机选取的向量适应度值,可以以一定概率改变缩放因子的符号。Wang 等[15]提出的量化正交交叉DE 算法首先量化两个父代个体的搜索范围,再根据量化结果调整交叉和变异算子中各参数因子的值。Zamuda 等[16]还提出了一种使用对数正态自适应控制参数的合作协同差分进化(differential evolution combined with cooperative coevolution)算法。Yang 等[17]则在研究分析以往的自适应方法,并结合其他方法优点的基础上,提出了一种通用的差分进化参数自适应框架。徐广治[18]提出了多级扰动的DE 算法,该算法利用随机正态分布对个体最优解进行扰动,以此来增加种群多样性。关于改进DE 算法进化算子的研究还有文献[19-21, 28]等,限于篇幅,这里不再赘述。
除上述着重于改进DE 算子的研究外,其他研究还包括注重DE 算法与其他算法混合使用[42-43],以及改变原有的单一种群进化机制[22-23]等。
1.1.2 基于PSO 的改进算法
SIA 算法是与EA 算法类似的另一种元启发式算法,其中PSO 算法是SIA 算法的代表性算法。图3 所示为经典的PSO 算法流程图。
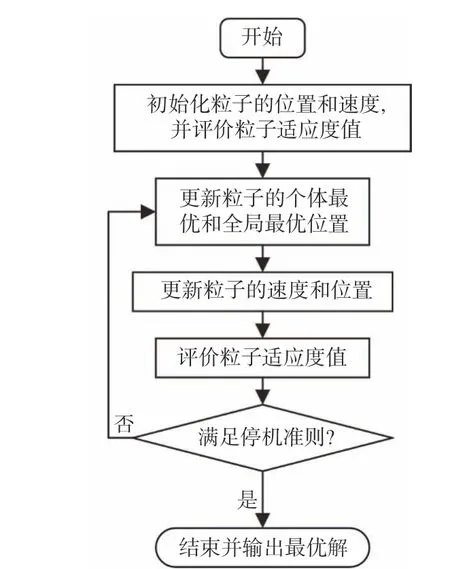
图3 粒子群算法流程Fig. 3 Flowchart of particle swarm optimization
在PSO 算法中,粒子的位置和速度更新手段是该算法的核心。改进方向也都集中于此。Yang等[29]还提出了一种PSO 算法的变体——基于层次的学习粒子群算法(level-based learning swarm optimizer, LLSO),该算法中种群按照其适应度值的大小进行排序,并分成多个层级,其中,除最好一层的粒子直接进入下一代之外,其他粒子的位置和速度按式(3)更新。

此外,LLSO 算法还包括一种自适应调整层数和控制参数 φ的可动态变化的基于层次学习粒子 群 算 法(dynamic level-based learning swarm optimizer,DLLSO)[29]。Hsieh 等[30]提出基于高效种群利 用 策 略 的 粒 子 群 (efficient population utilization strategy for particle swarm optimization, EPUS-PSO)算法,定义了种群管理器和解共享策略。其中,种群管理器能够自适应地根据当前优化情况去除种群中的冗余粒子或增加新粒子,而在解共享策略中,将标准PSO 算法速度更新方程的第3 项——个体历史最优位置(pbest),按一定的概率改变为另一个粒子的个体历史最优位置。同时,作者还提出了一种搜索范围的共享策略,用于跳出局部最优解。
García-Nieto 等[31]提出了采用速度调整和重启策略的PSO 算法,该算法中的速度调整策略用于控制粒子在有限区域内定向运动,而重启策略用于防止出现早熟问题,若整个种群中粒子适应度标准差或目标函数值总体变化非常低,则执行重启策略。Cheng 等[32]使用基于成对的随机竞争机制的竞争粒子群算法(competitive particle swarm optimizer,CSO)来求解LBOP 问题。在算法的每轮优化中,从当前种群中随机选择粒子开展竞争,获胜粒子被传递到下一种群中,通过向获胜粒子学习,更新失败粒子的下一个位置及其速度。
周建宏[33]提出了通过对搜索的子空间进行叠加来覆盖整个搜索空间的频繁覆盖策略,并将该策略与随机漂移粒子群优化算法和具有量子行为的PSO 算法的变体相结合。Chu 等[34]对高维复杂优化问题中的随机、吸收和反射3 种边界处理方法进行了分析比较。Tian 等[36]基于CSO 算法提出了一种新的两阶段粒子位置的更新策略,用于处理大规模多目标优化问题,其效率优于基于问题 的 转 换 算 法(problem-based transformation algorithm)、基于决策变量聚类的算法(decision variable clustering-based algorithm)、PSO 算法和分布式 估 计 算 法(estimation of distribution algorithm,EDA)等。
Deng 等[39]根据学习者与榜样间适配度差最大化的原理,提出了一种改进PSO 算法,即RBLSO(ranking-based biased learning swarm optimizer)算法,该算法含排名配对学习(ranking paired learning,RPL)和偏心学习(biased center learning,BCL)两种学习策略。其中:RPL 策略是让较差粒子根据其排名从较好粒子中对等学习,以加快收敛速度;BCL 策略是让每个粒子都向整个种群的适应度加权中心(偏置中心)学习,以加强算法的探索能力。
Huang 等[37]提出了用于控制PSO 算法收敛速度的策略,当检测到算法收敛速度过快或过慢时,自适应地调整算法的收敛速度。计算结果表明,该策略可以帮助PSO 算法在收敛速度与种群多样性间保持平衡。Wang 等[38]提出的DGLDPSO(dynamic group learning distributed particle swarm optimization) 算法是将整个种群分为若干组,通过“主-从”分布式模型共同进化,该算法采用动态组学习策略(dynamic group learning,DGL)平衡多样性和收敛性。此外,DGLDPSO 算法被应用到了大规模云的工作流调度优化中,作者结合资源特性还进一步提出了自适应重编号策略(adaptive renumber strategy,ARS)。
总之,相比于基于DE 的方法,基于PSO 的方法收敛速度通常更快,但更易陷入局部最优。
1.1.3 其他算法
除了DE 和PSO 分别作为EA 及SIA 算法的典型算法得到了大量研究外,还有研究将其他算法改进后用于提升所研算法求解LBOP 问题时的性能。例如,协方差矩阵自适应进化策略(covariance matrix adaptation evolution strategy,CMA-ES)[120]在处理中、低维问题时有着卓越的性能,但在处理LBOP 问题时,随着维度的增加,协方差矩阵计算复杂度也随之迅速增加。因此,Ros 和Hansen[44]提出了sep-CMA-ES 算法,该算法只计算协方差矩阵的对角元素,以降低计算复杂度,即计算复杂度仅随问题的维度线性增加,从而解决了CMAES 算法在处理高维问题时的可用性。但是,Omidvar 等[121]将sep-CMA-ES 算法与几种CCEA 算法进行比较后,发现当LBOP 问题的维度增加时,sep-CMA-ES 算法的性能明显下降。为此,Li 等[49]提出了一种CMA-ES 算法的快速变体,通过使用一个低阶矩阵与几个向量逼近协方差矩阵,并使用其中2 个向量生成新解,实现了计算复杂度随问题的维度线性增加,试验结果表明其优于其他CMA-ES 优化算法的变体。
除了上述文献研究总结得到的方法外,还有大量未使用分解策略的元启发式算法。例如,多重 轨 迹 搜 索(multiple trajectory search,MTS)[46]、LSEDA-gl (EDA for large scalar global optimization)[47]、基于对立的差分进化(opposition-based differential evolution,ODE)[24]、SOUPDE (shuffle or update parallel differential evolution)[25]、改进社会 蜘蛛算法(improved social spider algorithm, ISSA)[48]等。关于不使用分解策略的方法更为详尽的总结可见文献[122-123]。
总体上,未使用分解策略的方法可以通过以下途径提高对LBOP 问题的搜索性能:1)加入局部搜索策略,例如MA-SSW-Chains[45], μDSDE (micro differential evolution with a directional local search)[26],jDEsps (self-adaptive differential evolution algorithm with a small and varying population size)[27]等;2)改进交叉、变异、选择等进化算子,例如融合了反向学习的PSO算法(GOPSO)[35],GaDE (generalized adaptive differential evolution)[17]等;3)混合不同算法,以取长补短,例如MOS-CEC 2013[42]。
1.2 使用分解策略的方法

基于分解策略求解LBOP 问题的算法采用了“分而治之”(divide-and-conquer)的思想。首先,将LBOP 问题分解为一系列较低维的子问题,然后,分别对子问题进行优化,最终,迭代逼近真实的最优解。这里,以最小化问题为例,若函数f(x1,···,xd)满足以下条件:则称函数f(x1,···,xd)是可分的[124-125],亦即若一个函数单独优化各维度的变量得到的最优解与其他变量的取值无关,且等于该函数全局最优解在该维度上的取值,则认为该函数是可分的。根据函数可分的定义,可以得到加法可分的定义。加法可分的函数可以方便地表示许多具有模块化性质的实际工程问题[126],其数学形式简单,有利于理论推导。
若函数f(x1,···,xd)可以写为如式(5)所示的形式,则称之为部分加法可分的函数。

式中:xi为函数fi的 决策向量,且xi之间无相互重叠的决策变量,即xi互斥;x=〈x1,···,xd〉,为全局决策变量;s为独立子问题的个数。若所有独立的子问题都是一维的,则将函数f(x)称为完全加法可分的。若独立的子问题的个数只有一个,则称f(x)为完全不可分的。
1.2.1 合作协同进化算法
合作协同进化算法(cooperative co-evolutionary algorithm,CCEA)运用生物协同演化的思想将问题分解为一系列子问题(即子种群),此方法在解决LBOP 问题时表现出了高效性,是解决LBOP问题的主要和热门方法之一。文献[127]对2018年以前提出的CCEA 算法进行了较为详细和全面的总结。在此基础上,本节对2018 年至今在求解LBOP 问题方面采用CCEA 算法所取得的研究进展进行总结补充,如表2 所示。

表2 合作协同进化算法研究文献汇总Table 2 Summary of research advances of CCEA
图4 所示为典型的CCEA 算法的框架[129]。

图4 合作协同进化算法框架Fig. 4 Framework of cooperative co-evolutionary algorithm
如图4 所示,CCEA 算法将一个高维问题分解为s个低维子问题,并为每个子问题建立一个用于进化的对应子种群,以串行或并行方式,利用EA 算法对每个子种群单独优化(称为一轮优化)。由于每个子问题的决策变量仅是全部决策变量的一部分,所以在优化子问题评价某个体的适应度值时,需要从对应的合作者库中选择合作者(图中浅蓝色的个体部分),补齐剩余的设计变量,使其形成一个完整的解以评价其适应度值。合作者库是根据合作者信息池构建,而后者又是由各子问题中选出的代表解(图中深蓝色的个体部分)组成的,二者在优化过程中不断更新,不同子种群之间就可以以此方式实现信息交换。值得指出的是,每个子种群可选择多个代表解,并将其纳入合作者信息池。评价子种群个体适应度值时,也可以与多个合作者形成多个完整的解,来综合评价其适应度值。总之,通过不断重复上述一轮优化过程,直至获得最终的优化解。对于CCEA的研究方向主要有分组策略、合作者选择策略等,下文将分别介绍此方面的研究工作。
1) 分组策略研究。
很显然,如何分组及分组的正确与否对于算法性能有着重大的影响。若本来彼此之间无相互影响(可分)的变量被分到同一个子问题内,将无法体现“分而治之”方法的优势。若本来彼此之间存在相互影响(不可分)的变量被分到不同的子问题内,将会丢失子问题的适应度函数特性,使得合作者的改变引起子问题适应度函数特性的大幅度改变,并且算法也将收敛到纳什均衡(Nash equilibrium),而非全局最优解[51]。第1 个合作协同进化算法CCGA 由Potter 和De Jong[50]提出,该算法是将一个d维问题分解为d个一维子问题,并使用GA 算法轮流对子问题进行优化。这种最原始的分组方法在处理不可分问题(例如Rosenbrock 和Griewank 函数[11])时的性能非常差。
关于分组策略的研究内容大致可分为动态和静态分组方法两类。其中,动态分组方法指的是原问题的分组在协同进化优化过程中会发生变化的方法。
(1) 动态分组方法。
随机分组(random grouping)是这类分解方法的代表。Yang 等[51]结合随机分组和CCEA 算法提出了DECC-G 算法,该算法将一个n维LBOP问题随机分为k组,每个子问题包含n/k维度的变量。具体而言,每个协同进化框架在循环开始前(即下一轮子问题开始优化前),将再次将包含n维的问题重新随机分成k组,以开始下一轮优化。通过每轮优化之间不断改变分组方案,以此提高不可分变量被分到同一组中的概率。此外,DECC-G 算法还在每轮优化结束后,为各子问题分配一个权重,然后,分别对整个大种群的最优、最差、随机的个体优化该权重值,以得到更好的全局最优解。
学者们基于DECC-G 算法提出了许多提高DECC-G 性能的算法。例如,多层合作协同进化(multilevel cooperative coevolution,MLCC)[52]使用分组方案库来代替DECC-G 算法中每轮优化都重新分组的策略。该算法中,分组方案库中每个方案的概率选择取决于此方案的历史性能表现,即历史性能表现好的方案具有更大的被选中的概率。然而,Omidvar 等[53]指出,MLCC 算法继承自DECC-G 算法的自适应优化权重部分,对算法性能几乎无提升,而将已使用的函数计算次数用于更频繁的重新随机分组将更有效。最后,还有不少基于随机分组或改进DECC-G 算法的研究[54-56],但限于篇幅,不再赘述。
除了随机分组外,还有Ray 和Yao[57]提出的一种基于相关矩阵的分组方法。此方法在最开始的几轮优化中未使用分解方法,而是直接采用EA 算法对原问题整体优化,然后计算种群中前50%个体的相关矩阵,并根据相关矩阵分组。对于相关系数大于某个阈值的设计变量,可将其分配到同一组,分组完成后,再采用正常的CCEA算法进行优化。自适应可变分区的协同进化算法(CCEA with adaptive partitioning, CCEA-AVP)[58]是对Ray 和Yao 所提方法的改进,二者的区别在于,前者在协同进化的每一轮优化开始前都会利用已经计算过的个体来更新相关矩阵,并根据更新后的相关矩阵重新分组。但是,有研究也指出基于相关矩阵的方法计算资源消耗太大,且无法识别非线性相关的不可分变量[121,130]。
(2) 静态分组方法。
静态分组方法指的是一旦分组方案确定,例如将n维的问题分解为n个一维的子问题,或者将n维的问题分解为k个n/k维的问题,则在后续优化过程中分组方案不再发生变化的分组方法。很显然,静态分组这种先入为主的分解方法效果并不理想,故许多研究者提出了不少自动分辨可分与不可分变量的算法。例如,Weicker 等[131]提出了一种判断相互影响变量的简单方法,其假设best为当前已知最优解,new为协同进化的优化器对第i维变量优化后的个体,rand为种群中随机选择的个体。通过式(6),可以生成两个新的个体x′和x,其第j维的值由下式给出:

若x′的 目标 函 数 值f(x′)优 于x的目 标 函数值f(x),则可认为第j个变量和第k个变量相互影响的概率增加了。
基于上述思想,Chen 等[59]提出了基于变量交互学习的合作协同进化(cooperative co-evolution with variable interaction learning,CCVIL)算法。该算法分为学习阶段和优化阶段,其中,在学习阶段利用与文献[131] 中类似方法识别不可分变量并分组。Omidvar 等[60]则提出了Delta 分组方法与基于Delta 值的合作协同进化框架,其中,Delta 值由连续两轮优化中的每个维度的绝对变化量计算得到,基于此,再根据对应的Delta 值对决策变量进行排序,最终,按排序后的delta 值对变量进行分组。然而,Omidvar 等[61]的研究也表明,若存在多个不可分离的子问题,Delta 分组的性能会下降。因此,作者又提出采用差分分组(differential grouping,DG)方法从数学上推导出如下定理。

则xp和xq是不可分的,p和q为被选择用于判断的两个维度下标。其中:
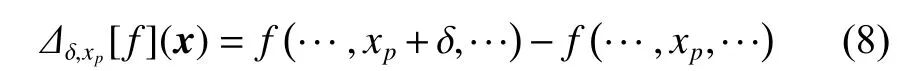
上述推导的定理非常重要,因为它是DG 方法的核心理论,Omidvar 等[61]证明了由该定理可以推导出使用非线性检测用于实数编码遗传算法的联动 识 别(linkage identification by nonlinearity check for real-coded genetic algorithms,LINC-R)算 法[128]。
虽然DG 方法可大幅度提高分组的正确率,但也有不足之处:1)处理完全可分的问题时的计算资源消耗太大;2)无法对有重叠变量的子问题进行检测;3)对数值计算的舍入误差非常敏感;4)需要使用者事先定义一个阈值。
为了解决上述缺陷,许多学者开展了提高DG方法的效率和性能的研究。例如,提出了DG 方法的两种变体形式-全局差分分组(globaldif-ferential grouping, GDG)[62]和扩展差分分组(extended differential grouping, XDG)[63]。XDG 方 法 是 通过确定变量间的间接相互作用来处理Rosenbrock函数,但缺点是它继承了DG 的敏感性特点,且其判断变量交互作用的方法可能会将可分离的变量视为不可分离的变量。
GDG 方法是通过考虑计算误差来解决DG存在的敏感性问题,但该方法使用某个全局参数来检测所有的交互作用,使其不适合于不平衡的函数。不仅如此,GDG 方法还需要通过检查所有变量对的交互作用,来解决识别子问题间存在重叠变量的函数。为此,Omidvar 等[64]又提出了DG方法的升级版DG2,在方法中引入了一个“原始交互结构矩阵”。首先,其自适应寻找阈值;然后,将原始交互结构矩阵转换为设计交互矩阵;最后,通过设计交互矩阵决定最终的分组方案。结果显示,DG2 方法可以有效缓解原有方法存在的上述4 个缺点。
在其他分组策略方面,刘礼文[65]提出了一种再分组策略的算法,即将原问题分解为一系列子问题后,对维度仍较高的子问题再分组。此外,有学者还另外提出了一系列DG 类型的算法(详见文献[66-69]),以进一步降低DG 算法计算资源的消耗。而且,还有学者将设计变量和目标变量视为随机变量,首先利用统计模型统计分析变量和/或目标函数,再根据不同统计值对变量进行分组,这些统计值包括Pearson 相关系数[70]、互信息(mutual information)[71]、最大信息系数(maximum information coefficient, MIC)[72]、Kullback-Leibler 散度[73]等。
2) 合作者选择策略研究。
除了研究分组策略外,还有大量学者专注于合作者选择策略的研究。如上所述,在对原问题进行分解后,使用CCEA 算法优化每个子问题时需要从其他子问题中选择合作者凑成一个完整的解来评估适应度。因此,如何从子问题中选择合适的合作者对于算法性能有着重要的影响。
第1 种策略也是最简单直观的,其选择每个子问题中的最优个体作为合作者,将子问题个体与剩余子问题中的最优个体凑成完整的解来评价该个体的适应度(详见文献[50-51, 61, 74])。从研究结果来看,采用此策略处理完全可分的问题时非常有效,但对于不可分问题可能会导致算法陷入纳什均衡或局部最优[75-76]。
第2 种策略是随机选择每个子问题中的个体作为合作者,将该个体与剩余子问题中随机选择的个体凑成完整的解来评价子问题个体的适应度。采用该策略能有效保持种群的多样性且可防止算法早熟的问题,具体可见文献[77-80]。从研究结果来看,采用此策略处理外部环境改变很快的动态优化问题时的表现好于选择最优个体的策略,但随机选择合作者会降低算法的收敛速度[81]。
第3 种策略即所谓精英选择策略,其也被视为第1 和第2 种策略的结合体。该策略首先从每个子问题中挑选前K个最优个体形成合作者池,然后从合作者池中随机选取个体形成完整的解[82]。值得指出的是,当K=1 时,此策略退化为第1 种策略;当K等于子种群个体数时,则退化为第2 种策略。其次,K值不一定保持不变,例如,在算法初始阶段可以选取较大的K值以保证多样性,而后期阶段可以选取较小的K值以提高收敛速度。另外,对于选择单一合作者的策略,还包括类 似 于GA 算 法 中 的 轮 盘 赌/锦 标 赛 选 择 策 略[78,83]、固定选择合作者策略[84-85]、邻域选择策略[85]等,限于篇幅,不再赘述。
除了选择单一合作者外,也可选择多个合作者,与当前个体形成多个完整的解来对个体进行评估。为此,一种策略是选出剩余子问题中的所有个体作为合作者,具体详见文献[76, 86-87]。在子种群个体数足够大时,此策略的优点是可保证收敛到全局最优[87],但缺点是计算资源消耗巨大。例如,假设有s个子问题,每个子种群个体数为Np,则在优化某一个子问题的过程中,仅仅评价一个个体的适应度就需要Nps-1次的真实函数计算。另一种策略是构建合作者库,例如基于帕累托支配的合作协同进化算法(pCCEA)[88]是以非支配者库为基础选择合作者。在每代种群中,pCCEA算法用非支配者库中的所有个体来评估子种群中的每个个体,即生成Na个完整解(其中,Na是子种群非支配者库中的个体数)。然而,pCCEA 算法的缺点是,随着算法的推进,Na趋于无穷大。而改进后的合作协同进化算法(iCCEA)[79]通过记录“信息量大 ”的合作者,即记录能够改变另一个子种群中两个个体的相对等级的个体解决了合作者数量趋于无穷大的问题。为此,文献[89-91]提出了大小固定的共享参考库,所有子种群从库中选择合作者。
3) 其他策略研究。
除了研究分组策略和合作者选择策略外,关于合作协同进化策略的研究还包括但不限于如下内容:
(1) 适应度评价策略。如上所述,选择单一合作者策略基本上都是选择与单一合作者凑成完整解的目标函数值作为适应度值,但是,当有多个合作者时,就会有多种评价适应度的方法。例如,若有多个合作者形成多个完整的解时,可选取多个完整解目标函数之中的最优值[89]、平均值[92]、最差值[93]作为其适应度值,或基于帕累托支配的概 念 分 配 适 应 度 值[88-89,94-95]。常 规 进 化 算 法 中 使 用的适应度评价技术(例如,适应度继承[96-97]、小生境技术[98-100]等)也可应用于CCEA 算法。
(2) 计算资源分配策略。即给每个单独优化的子问题分配计算资源,包括均匀分配[50]、随机分配[101]、基于对原问题贡献程度的分配[102-105]等。
1.2.2 其他算法
CCEA 算法是基于分解思想的最典型、研究最多的算法之一。此外,仍有部分同样利用了分解思想不属于CCEA 的算法,例如代表性的EDA算法[106]。EDA 算法通过概率模型描述候选解的空间分布,利用有希望的解集来估计变量分布和变量相互作用,然后,根据学习到的变量分布及变量之间的相互作用,生成新候选解[107]。最简单的EDA 算法(例如紧致遗传算法(compact genetic algorithm, cGA)[108]、基于种群的增量学习(population-based incremental learning,PBIL)[109]等)中每个变量都是独立的,不过,这些算法不适合处理不可分的问题。
Dong 等[110]提出的采用模型复杂度控制技术的EDA 算法(EDA-MCC)首先根据线性相关系数来识别交互作用较弱的变量,然后将剩余的交互作用较强的变量强行划分为若干个不重叠的子集,以减小搜索空间。EDA-MCC 算法还可对所有的变量子集进行不同概率模型的演化。结果表明,在一批基准测试函数上,EDA-MCC 算法的性能优于传统的EDA 算法和其他一些高效的算法。Xu 等[111]进一步对EDA-MCC 算法进行了改进,其采用互信息代替线性相关系数来识别交互作用较弱的变量,这样可以检测到变量间的非线性依赖关系。
Yang 等[112]结合分解策略与代理模型技术,提出了一种自我评价进化(self-evaluation evolution,SEE)算法, 即将多维度问题相应地划分为一维多个子问题,通过局部搜索算子分别对每个子问题进行演化,通过训练每对子代和父代的一部分得到简单的代理模型,从而高效地实现子代解的适应度评价。最近,Yang 等[113]还采用并行计算技术以增强SEE 算法,进一步发展出一种高效算法-自然并行的分而治之算法(naturally paralleled divide-and-conquer, NPDC)。
在基于原问题分解的条件分布来处理不可分问题的算法中,因子化分布算法(factorized distribution algorithm,FDA)[114-115]在加法可分问题上表现较好,但需要问题架构的先验知识,计算成本极高。
此外,还有一部分研究是利用专门设计的进化运算符、表征和机制,将变量分成若干组。例如,Schaffer 和Morishima[116]在个体染色体的每个基因上附加一个标志位,用以指示交叉点,相邻的两个交叉点间的基因被合并为同一组。在此基础上,Levenick[117]扩展了上述方法,引入额外的标志位以表示选择一个位置作为交叉点的概率。
Smith 和Fogarty[118]提出采用联动进化遗传算子(linkage evolving genetic operator,LEGO)自适应调整变量的分组。该方法通过为每个基因施加两个布尔标志来表示其在染色体上与哪一个邻居(左邻或右邻)相互作用,而相互作用的邻接基因被认为是同一组的一部分。
Wu 等[132]提出的新混合算法则是采用现有分组算法将LBOP 问题划分为若干个小规模问题,采用设计的改进自适应离散扫描方法对全部搜索空间进行粗略扫描,且着重搜索存在希望的区域。该混合搜索方法可自适应选择一维搜索方案或协方差矩阵自适应进化策略,以分别解决可分离问题、部分(加法)可分问题或不可分问题的子问题。
2 代理模型辅助的大规模优化算法
在实际工程应用中,计算目标函数通常非常耗时。例如,对船舶冲击动力响应的仿真计算,一次计算可能需要数小时到几十小时不等,故也将这种目标函数计算非常耗时的优化问题称为昂贵的优化问题。目前,LBOP 问题相关算法所需目标函数计算次数仍高达106数量级,这种计算成本是不可接受的。因此,有学者引入代理模型来有效解决时间成本高昂的问题。对于元启发式算法而言,代理模型几乎可以在元启发式算法的所有阶段使用,如图5 所示。图中,灰色框表示代理模型与元启发式算法交互的阶段。
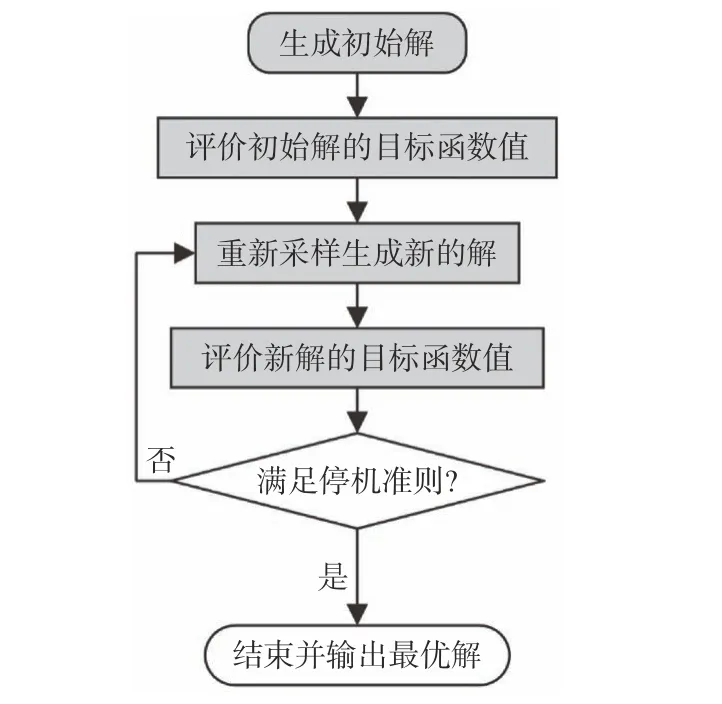
图5 代理模型与元启发式算法交互示意图Fig. 5 Diagram of interaction between surrogate modle and metaheuristic algorithm
代理模型可用于指导初始解的生成、辅助评价解的目标函数值、指导新生成解的采样策略等。对于昂贵的优化问题,最常用方法是采用代理模型替代昂贵的耗时计算。对于低维昂贵的优化问题,目前的研究已相当成熟,典型方法可分为代理模型辅助的进化算法(surrogate-assisted evolutionary algorithm)[133]和贝叶斯优化框架(Bayesian optimization framework)[134-135]。有关这两类算法可详见文献[136-137]。但是,传统上适用于低维昂贵的优化问题的方法却不能用于求解昂贵的LBOP 问题,其原因主要在于如下困难:1)随着求解问题的维度增加,优化算法的搜索能力大幅降低,即使采用本文所述大规模优化算法可提高算法在高维的搜索能力,但仍难以找到真实的全局最优解;2)随着求解问题的维度增加,代理模型的精度会迅速下降,构建代理模型所需样本点数也会迅速增加。不仅如此,代理模型本身的计算复杂度也会随着维度的增加而增加。
目前,关于代理模型辅助LBOP 问题的研究并不多见[138-140]。与上文类似,这些研究同样可以分为使用和不使用分解策略两大类,表3 按此分类给出了求解LBOP 问题时使用代理模型辅助元启发式算法的典型文献。表中,RBF(radial basis function)为径向基模型, GP(Gaussian process)为高斯过程模型。

表3 代理模型辅助元启发式算法的文献分类Table 3 Summary of surrogate model assisted meta-heuristic algorithms
2.1 不使用分解策略的方法
原则上,对于不使用分解策略的方法求解低维的昂贵优化问题,直接使用代理模型拟合目标函数值(也称适应度近似)的方法仍可以使用。然而,由于代理模型在高维空间中的精度会迅速下降,以及建模成本显著上升,采用适应度近似的方法求解LBOP 问题的效果会严重下降,此时,可以考虑使用其他代理模型。
例如,根据父代适应度拟合子代的适应度值(也称适应度继承)和利用不同精度代理模型迁移个体间的适应度(也称适应度迁移);或使用代理模型指导交叉变异操作、初始种群生成等。另外,还可以采取降维的方式,结合整体与局部代理模型等各种途径来缓解“维数灾难”的问题。其中,部分研究采用的是基于高维空间到低维空间映射的降维方法(例如文献[138,140]中使用的Sammon 映射方法)。然而,降维也意味着会丢失一定数量的设计变量对目标函数的影响,研究证明此方法仅适用于中等规模的优化问题(50~100个变量)[138-140]。
为了获取全局最优解,Sun 等[141]提出了代理模型辅助合作的粒子群优化(surrogate-assisted cooperative swarm optimization, SA-COSO)算法,即通过代理模型辅助的PSO 算法与代理模型辅助社会学习的粒子群优化算法(social learning-based PSO, SL-PSO)合作来搜索全局最优解。PSO 与SL-PSO 之间的合作包含两个方面:一是其共享由真实函数评估过的有希望的解;二是SL-PSO 算法侧重于全局搜索,PSO 算法侧重于局部搜索。Yu 等[142]提出一种类似于SA-COSO 的算法以提高SA-COSO 算法的性能,Sun 等[139]使用基于适应度近似的竞争群优化算法(competitive swarm optimizer, CSO)处理500 个决策变量的问题,算法采用适应度继承策略[55]替代部分昂贵的适应度评估,该适应度继承的方法也可以被视为局部代理模型。研究表明,相比未采用任何适应度近似策略的CSO 算法,采用代理模型辅助的CSO 算法对500 个变量的基准测试函数计算得到的结果更好,或者至少有竞争力。
Werth 等[147]提出的窗口式优化方法是根据变量相互作用关系对问题进行初步分组,算法每次迭代都在一个滑动窗口(该窗口仅包含所有设计变量的一个子集)内完成。初步研究结果表明,运用这种窗口式优化方法优化5 个高达1 000 维度的问题是有效的。Fu 等[143]提出的采用随机特征选择技术的代理模型辅助进化算法(surrogateassisted evolutionary algorithm with random feature selection,SAEA-RFS)则是利用随机特征选择技术形成的若干子问题进行序贯优化,来优化LBOP问题。
在降低代理模型建模成本方面,陈祺东[144]提出的代理模型辅助量子粒子群算法(surrogate-assisted quantum-behaved particle swarm optimization,SAQPSO),也称SAQPSO-WS 算法,其基于曼哈顿距离(Manhattan distance)方法在优化过程中逐渐丢弃目标函数值不佳的样本点,以此降低代理模型的建模成本。
Wang 等[145]提出的全局和局部代理模型辅助差分进化算法(evolutionary sampling assisted optimization,ESAO)可以交替进行全局和局部搜索,将RBF 模型作为全局代理模型,而将RBF 模型与Kriging 模型作为局部搜索模型。数值实验表明,RBF 比Kriging 更适合作为局部代理模型。
Dong 等[146]提出的代理模型辅助灰狼优化(surrogate-assisted grey wolf optimization,SAGWO)算法在初始阶段基于样本识别出原始狼群和狼首,用于拟合高维空间,在搜索阶段则利用灰狼优化全局搜索,结合多起点局部搜索策略在重点区域局部搜索。SAGWO 算法根据从RBF 模型中获取的知识在每次循环内辅助生成新的狼首,并根据狼首所在位置改变狼群位置,从而达到平衡开发和探索的目的。
综上所述,目前采用不使用分解策略的算法的研究一般都仅局限于约200 维度的高维优化问题,而对于上千维度的LBOP 问题则几乎没有涉及。
2.2 使用分解策略的方法
对于使用分解策略的方法,很自然地会想到能够缓解所谓“维数灾难”问题的代理模型与CCEA 算法结合的算法。CCEA 算法的特点是,首先将LBOP 问题分解为一系列低维子问题,有效降低训练代理模型时的维度(也即避免代理模型直接拟合原有高维问题),然后再拟合低维子问题的适应度函数。尽管针对LBOP 问题的算法研究促进发展出了一些有效的CCEA 算法,但却鲜有关于CCEA 算法与代理模型结合的研究,特别是涉及LBOP 问题时。目前,两者相结合的算法研究仍处于比较初级的阶段,也就是直接在子问题优化过程中使用代理模型来替代原有的适应度函数计算。
Ren 等[148]提出的RBF 模型、基于成功历史的自适应差分进化算法(success-history based adaptive differential evolution,SHADE)和代理模型辅助的合作协同进化算法(surrogate model assisted cooperative coevolution,SACC)三者结合的混合算法(RBF-SHADE-SACC)中,RBF 模型作为各子问题的代理模型,SHADE 算法则为各子问题的优化器。对子问题优化过程中,只有代理模型预测值较优的个体才会被用于真实目标函数的计算,其他个体则直接使用RBF 模型进行适应度计算。值得指出的是,RBF-SHADE-SACC 算法默认原问题的理想分组情况已知,但这在实际应用中很难实现。
在Blanchard 等[149]提出的SACC-EAM(surrogate-assisted cooperative co-evolutionary algorithm of Minamo)算法中,将RBF 作为代理模型,Jade 算法作为子问题的优化器,使用随机分组策略。该算法在使用Jade 算法优化子问题的过程中,RBF 被用于替代耗时的真实函数计算,最优解的评估采用的是真实函数,并将其加入到代理模型样本点库。其后,Blanchard 等[150]又提出了改进SACCEAM 的SACC-EAM-II 算法,通过使用递归差分分组 (recursive differential grouping,RDG) 策 略代替原有的分组策略,以达到提高算法性能的目的。
De Falcon 等[151]提出的基于随机分组策略的SACC 算法框架将Jade 算法作为优化器,在优化子问题的过程中可以使用全局代理模型或局部代理模型。其研究主要在于各参数对SACC 框架的影响,结果表明:在大多数问题中,降低子问题的维度(2~4 维)能够显著提升收敛性,每个子问题的最佳进化代数会随着目标函数的不同而不同;其次,若由GP、RBF、支持向量机回归(support vector regression, SVR)作为全局代理模型,而二次多项式近似(quadratic polynomial approximation, QPA)作为局部代理模型时,总体上性能表现最好的代理模型是GP 和RBF;在大多数情况下,SVR 模型早期收敛速度更快,并且对于多模态函数,SACC算法性能提升不大。
综上所述,对于不使用分解策略的算法,由于“维数灾难”问题不能再像低维问题一样采用代理模型直接替换适应度评估,而是需要采取降维、局部搜索等特殊的改进方法。由结果可见,这种方法在应用于解决中高维问题(500 维以下)时的效果较好,超过500 维度的LBOP 问题得到的优化解仍不够理想;采用使用分解策略的算法由于分解机制可以在分解后的低维子问题中直接采用代理模型替换子问题的适应度计算,因此其研究一般都涉及到了约1 000 维度的LBOP 问题。然而,这种算法只是在子问题中机械地套用了低维问题的方法,而未考虑分解策略的特点。虽然相比于不使用代理模型的算法这种方法可节省计算资源,但是针对LBOP 问题获得的优化解与真实的优化解仍然存在较大差距。
鉴此,代理模型辅助大规模元启发式算法仍然具有很大的改进空间,故有比较大的研究价值。
3 结论与展望
近年来,LBOP 问题引起了各领域研究者的广泛兴趣,本文总结了目前有关LBOP 问题的元启发式算法的研究进展。总体上,用于求解LBOP问题的元启发式算法可以按照是否使用了分解策略进行分类。不使用分解策略的算法需要通过添加局部搜索、混合不同算法等策略来提高算法在求解LBOP 问题时的性能;而使用分解策略的算法则主要考虑分解策略带给算法的新特性,从这些新特性着手提高算法效率,例如,提出高效的分组策略、资源分配策略等。在算法性能方面,这两类算法无明显的优劣之分。
对于昂贵的LBOP 问题,使用代理模型仍然是绝大部分研究的首选方案。由于LBOP 问题本身的复杂度,无论算法是否使用了分解策略,运用代理模型辅助元启发式算法来求解LBOP 问题仍比较困难,故有较大的提升空间。总之,元启发式算法在求解LBOP 问题时还将面临如下主要挑战:
1) 设计空间体积随着维度的增加呈现指数增加的趋势。
2) 高维空间中目标函数的特性变得复杂,例如从单模态函数变为多模态函数。
3) 优化算法的搜索能力在高维空间中被削弱。
4) 优化成本高昂。
通过大量的文献分析和归纳总结,以及基于对实际工程应用的需求思考,本文认为LBOP 问题的未来研究方向可以概括为:
1) 进一步提升解决LBOP 问题的算法性能。目前,对于LBOP 问题现有算法仍需要大量的函数计算次数,并且得到的优化解与真实的优化解之间仍存在较大差距。
2) 求解大规模多目标优化及大规模约束优化问题。目前,对于无约束单一目标的LBOP 问题仍不能得到理想的解决方案,因此解决复杂的大规模约束优化问题更加困难。
3) 昂贵的LBOP 问题的研究。与目前研究主要使用廉价的测试函数不同,实际工程应用中的LBOP 问题通常昂贵,现有算法所需要的目标函数计算次数仍然巨大。代理模型辅助的元启发式算法似乎是比较有希望的解决方案。
4) 大规模优化算法在实际工程问题中的应用研究。在开展研究时,可以结合设计对象的专业先验知识指导变量分组,以提高优化效率。例如:对于大型船舶复杂横剖面优化设计问题,可以将上层建筑的设计变量分为一组,主船体设计变量根据垂向高度分成若干个组;对于船舶舱段优化设计问题,可以根据板架分组(例如甲板、舷侧、船底,平台,纵舱壁等);对于船舶的艏部型线的优化问题,可以按照附体型线(例如球鼻艏型线、艏部主船体型线)分组。
