基于多元公共品演化博弈的无人作战集群策略占优条件
2021-08-24禹明刚张东戈马子玉
禹明刚,何 明,张东戈,马子玉,康 凯
(1.陆军工程大学指挥控制工程学院,江苏 南京 210007;2.陆军工程大学通信工程学院,江苏 南京 210007)
0 引 言
随着第3次人工智能浪潮的持续推进,由单体自主智能发展而来的群体演化智能,成为人工智能2.0的重要特征之一。尤其在军事领域,无人集群(陆战场无人车集群[1-3]、水面无人艇集群[4-6]、空域蜂群[7-10])作战得到了前所未有的关注,美军已将无人集群作战列为一种能够改变作战规则的“颠覆性技术”。
目前,无人集群控制方式主要有集中控制和自主协同两类。前者依赖于地面站指令和无人机预编程,后者要求集群针对环境态势进行自主智能决策。在战场复杂电磁环境下,尤其当集群进入对方纵深之后,通信保障的展开面临极高难度,通信失效概率急剧上升[11]。此时,集中控制方式失效,无人集群必须依据对战双方情况、战场环境等,作出针对性的临机响应,依托集群内部的自组织、自协同,接续遂行军事任务。
在无人集群的自主协同进程中,资源的全局优化配置是必不可少的环节,且深刻影响自主协同效能的发挥。然而,在资源配置中,智能单元的个体利益诉求和集群全局作战需求,需要寻求一个平衡点。以集群火力打击任务为例,由于智能性的存在,每个打击单元均可独立决策,为了保证自身的战场生存能力,其将谨慎控制火力资源发射(投放)量。另一方面,在集群层面,单个打击单元提供的火力支持强度越大,越有利于集群整体作战效能的发挥。上述两者在需求上的矛盾性将催生公共资源悲剧的发生[12]。如何设计合理的集群自协同机制,避免矛盾冲突,无论是在集群控制基础领域还是现实演训/作战中,都是一项必须解决的难题。
集群自协同的本质在于解决个体间对立统一的关系,即求得收益的均衡。演化博弈理论[13-14]为解决集群自协同打开了一扇门。其中,公共物品演化博弈[15]为发掘集群的自组织机理、有效管控矛盾冲突奠定了一套理论框架。在该博弈过程中,研究如何提高合作者占比,并获取严格的合作策略占优条件,是解决公共资源悲剧,实现无人集群自主协同的重要前提。
哈佛大学Nowak教授团队[16-17]通过理论推导和模拟仿真,得到了基于模仿动态的多方博弈在弱选择强度下的策略占优条件。Antal教授团队获取了两方博弈策略占优条件[18],在此基础上,对Nowak结论进行拓展,得到了基于模仿动态的多方博弈在任何选择强度下的策略占优条件[19-20]。不同于Nowak教授团队,北京大学杜金铭团队将研究点从模仿动态[16,21]转向愿景驱动[22]策略更新机制下的策略占优条件研究。基于TARNITA[23]的研究工作,借助于统计学及计算机仿真发现弱选择强度下平均丰度独立于愿景水平值这一规律[24]。进一步地,将理论成果拓展到多方博弈,获取了基于愿景驱动的多方博弈在弱选择强度下的策略占优条件[25-26]。
上述研究,为解决集群自组织自协同提供了很好的思路,打下了坚实基础。然而,在解决无人集群自主协同问题时,仍有两点需要引起注意:一是现有成果多面向一般性的演化博弈模型,尚未聚焦于公共物品博弈,而公共物品博弈恰恰是研究无人集群策略占优条件、解决公共资源悲剧的基础理论框架;二是尚未见军事应用研究成果,目前可见公共物品博弈在环境污染[27]、城市公共资源建设[28]、文化演进[29]等方面的应用,由于军事领域的特殊性及无人集群作战的新质性,鲜有成果可循。
前期,以集群的自主协同设计为目标牵引,通过理论推导,得到了多元公共品演化博弈的平均丰度函数,并仿真分析了相关参数对平均丰度的影响[30]。平均丰度是获取策略占优条件的根本依据,因此本研究在前期研究基础上,首先采用愿景驱动规则,基于多元演化博弈框架对无人集群合作演化建模。接下来,以平均丰度函数为出发点,理论推导多元演化博弈的合作策略占优条件。然后,针对线性及门限两类典型的公共物品博弈,给出策略占优条件并进行特性分析。最后,依据特性分析结果,给出避免公共资源悲剧,实现无人集群自主协同的建议。
1 军事需求分析
无人集群自主协同示意如图1所示。

图1 无人集群自主协同示意图Fig.1 Sketch map of autonomous cooperation of unmanned swarm
无人集群的自主协同,涉及3个关键问题:一是集群智能的涌现,二是信息网络的构建,三是协同机制的设计,三者共同构建起了无人集群自主协同行为产生的基础框架。三者之间的关系如图2所示(由于信息网络的构建不在本文讨论范围,因此做了淡化处理)。

图2 无人集群自主协同行为产生的基础框架Fig.2 Basic framework of autonomous cooperative behavior in unmanned swarm
其中,从个体到群体的智能涌现是集群自主性协同行为产生的内在源动力;信息网络是集群内部信息交互发生的空间,是自主协同行为的空间载体;协同机制则是集群自主协同得以实现的最终途径。下面分别就智能涌现和协同机制展开讨论。
1.1 智能涌现
智能性(包括个体的单体智能和群体涌现智能)是分布式自主控制方式对集群的必然要求。事实上,让无人集群按照预定方案执行军事任务,这一思路本身存在先天不足。复杂环境下,战场态势瞬息万变,若对单个无人平台实施微观管理,将导致通信等资源严重过载,即响应性的控制大量无人平台将超出人类目前的技术、认知、决策能力,大概率导致作战行动失败。因此,必须将更多的决策、行动权限前移给集群自治系统,使得无人平台能够独立协调自身决策以产生支持集群目标的行为。
同时,智能化作战制胜机理的内核即为智能、自主。美国国防科学委员会指出智能和自主能力是美军无人系统中的核心能力,并分析了智能和自主能力给无人机、无人地面系统、无人海上平台和无人太空系统带来的作战效益[31]。未来无人集群作战系统将具备更高的感知、分析、计划、决策和执行能力,并朝着战场态势自主感知、作战任务自主规划、作战行动自主实施,作战协同自主联动、作战效果自主评估的方向迈进。
目前来看,无人作战力量的发展路径也正是起始于人机互动的遥控式,经历人机结合的协作式,向人机共融的自主式方向发展[32-33]。可以预见,无人集群的智能涌现也将经历有人为主、无人为辅的智能嵌入到有人为辅、无人自主的智能支撑再到仿生自主、集群攻防的智能主导演进[34]。
1.2 协同机制
无人集群作战由于其体系的区域分布性,智能自主特性以及去中心化特性,集群内部必须基于信息网络,构建起有序的协同与合作,以确保良好的战场生存能力和任务完成能力。
具备智能性的单个无人平台在与其他平台的交互中,必然会计算评估其自身的能量、损耗、成本、行为代价等因素,以最大化其自身收益,此过程不可避免地伴随着个体间的竞争,导致个体收益与集群总效用最优上的偏离。因此,协同机制设计中的一类关键问题是如何保持个体收益与集群效用的一致。
良好的协同机制设计是破解个体收益与集群总效用间矛盾的关键。目前,在经典的多智能体系统(multi-agent system,MAS)理论[35]、复杂适应系统(complex adaptive systems,CAS)理论[36]和复杂网络理论[37]框架下,组分(个体)与系统(集体)在各自优化方向上的竞争和冲突问题,有待进一步深化研究。
不同于传统的优化问题,群体协同控制问题并非简单地可以通过选择某种行为,以提高所有个体的适应能力。更复杂的情况是,不同个体在交互过程中,由于其相互间直接的影响,各个个体利益的提高往往是相互冲突的。构建在多个体对立统一基础之上的博弈论恰恰为研究群体中多个体间的交互协同提供了一种有效的研究框架。
所有个体作为博弈的参与方,各种可选行为是博弈的策略集,前两者与各策略的对应收益一起构成博弈局势。个体通过评估周围个体及环境因素的影响,选择某种策略,并在重复博弈过程中,通过自适应学习来最大化自身及群体收益[38-39]。最终,借助于经典博弈的纳什均衡或演化博弈的演化稳定策略(evolutionary stable ,ESS)来揭示群体协同机理。
2 数学模型
首先,需要明确待解问题与理论框架间的关联关系,如表1所示。

表1 概念映射关系Table 1 Relationship between concepts
2.1 多元演化博弈模型
本研究设定种群结构为混合均匀,种群规模为N,每个个体均在有限策略集{A,B}中实施选择和更新。随着演化进程的迭代滚动,A/B类型的个体在种群N中数量(即比例)将实时调整,并最终平稳收敛到某一值附近,此时即为演化稳定。
将多元演化博弈过程提炼为3个主要环节,如图3所示。

图3 多元演化博弈过程Fig.3 Procedure of multiple evolutionary game
上述过程重复推进,直到演化稳定状态。依据超几何分布的数学意义[40],A类型焦点个体X在某轮博弈中的期望收益为
(1)

(2)
具体推导过程可参见文献[30],限于篇幅此处不再展开。
2.2 愿景驱动动态
演化博弈理论框架下,策略更新机制总体上可划分为两大分支:模仿动态[21]和愿景驱动动态[41-43]。现有成果表明,无论在囚徒困境博弈还是公共物品博弈中,愿景驱动的动态机制相比于传统模仿动态,更能提高平均丰度值,进而促进合作[44-45]。在愿景驱动规则下,焦点个体从A类型更新为B类型的概率为
(3)
式中:参数α反映了个体X的愿景高低;ω为调节系数,其可调节项πA-α对PA→B的决定程度。若πA-α=0,即PA→B=1/2,那么i对于两策略具有同等的倾向性;若πA-α>0(即i的收益超出愿景值),那么PA→B<1/2,此时i对于A策略具有更高的倾向性;若πA-α<0(即i的收益不及愿景值),那么PA→B>1/2,此时i对于B策略具有更高的倾向性。
同理,焦点个体从B类型更新为A类型的概率为
(4)
在任意一种策略更新机制下,每一轮演化博弈进程里A类型个体的数量变动存在3种情况:① 数量减少1个,i→i-1;② 数量增加1个,i→i+1;③ 数量保持不变,i→i。
根据式(3)和式(4)可得对应的转移概率:
(5)
(6)
(7)
3 策略占优规则
本节首先给出平均丰度的定义,根据定义给出其数学表达式,进而基于平均丰度函数的一阶泰勒展开式,推导出合作策略占优规则。
3.1 平均丰度
定义 1平均丰度
设集群中A型作战单元数量为j,比例j/N为随机变量,令ν(j)为j/N的概率分布,则定义j/N的期望值为集群中A型作战单元的平均丰度。
由上述定义易知,合作策略A的平均丰度
(8)
平均丰度计算的关键是确定随机变量的概率分布ν(j)。对于无吸收态的马尔可夫链,ν(j)即为马尔可夫链的平稳分布φj(j∈[0,N]),而φj满足细节平衡条件[46-48]:
(9)
对式(9)进行归纳分析易得
(10)

(11)

(12)
将式(12)代入式(8)可得策略A的平均丰度展开式:
(13)
其中,
(14)
3.2 策略占优条件
定义 2策略占优
无人集群作战中,当集群内部博弈达到演化稳定状态时,若某策略的平均丰度值大于0.5,则称该策略为占优策略。
因此,合作策略占优即为
(15)
对式(15)的φj做一阶泰勒展开:
(16)
(17)
式中:
(18)
(19)
由于ω→0,因此:
(20)
(21)
(22)
(23)
(24)
(25)
将式(20)~式(25)代入式(16),得
(26)
将式(20)和式(21)代入式(26)得
(27)
由于:
(28)
策略占优条件即等价于:
(29)
由数学推导易得
(30)
结合式(24)和式(25),可得
(31)
因此,合作策略占优条件为
(32)

本节通过严格数学推导,得出了多元演化博弈策略占优条件,为下一节两类公共物品博弈特性分析,提供了理论依据。
4 演化博弈分析
本节对线性和带门限值的两类公共品博弈进行分析,获取其策略收益,仿真策略占优特性,并最终为集群自主协同机制设计给出合理化建议。
4.1 线性公共品博弈
在线性公共品博弈中,当X选择合作策略A,则群组可获得的总资源量为kc+c,成本增值后的总获益为r(kc+c),因此易得单体获益为r(kc+c)/d,然而因为X最初有c的投资,则X净获益可表征为r(kc+c)/d-c。另一种情况,X采取了B策略,对应地,上述几个参数分别变化为kc、rkc、rkc/d、rkc/d。ak与bk具体形式可表征为
(33)
(34)
收益矩阵如表2所示。

表2 线性公共品博弈收益矩阵Table 2 Pay-off matrix of liner public goods game
由于ak-bk=c(r/d-1),且一般假设1 (35) 因此,线性公共品博弈为非合作占优博弈,即演化均衡时,集群中合作策略为非占优策略,非合作者将占据主导。为分析该博弈策略占优特性,取α=1、N=100、c=1,仿真分析选择强度ω、收益系数r、愿景水平α对合作策略平均丰度XA的影响,以期总结规律,为无人集群合作策略占优管控提供参考。ω、r与XA的关系曲线如图4所示。 图4 线性公共品博弈中选择强度、收益系数与XA的关系Fig.4 Relationship between selection intensity,reward coefficient and XA in linear public goods game 图4(a)中,d分别取10和20,r=2。在选择强度ω=0时,平均丰度XA==0.5;在选择强度较小时(如图4(a)小面板所示),合作者的愿景难以满足,因此大量合作者转换策略,平均丰度出现下降趋势。随着选择强度增加,平均丰度略有提升,将逐渐稳定在0.45左右。图4(b)中,d分别取10和20,r=d/2。相比于图4(a),图4(b)中收益系数r的增加(r由2分别增加到5和10),使得平均丰度产生递减,且r增加幅度越大平均丰度降幅越大:XA(ω)|r=10XA(ω)|r=5,这是由于同时增加集群中合作单元和非合作单元的收益,将会使得“搭便车”现象更加严重,集群中大量作战单元转变为非合作者。 结论 1线性公共物品博弈中,在成本c、愿景水平α保持不变的情况下,合作者平均丰度将在弱选择强度(ω→0)和较小收益系数处保持相对较高水平。对于弱选择强度对合作的促进作用,已在生物遗传、分子进化、文化演进等领域得到现实验证[48-50],尽管目前还不清楚其作用机理。 因此,在线性公共品博弈模型下的无人集群作战管控中,虽然合作为非占优策略,然而可通过为作战集群预设ω和r较低参数值,弱化两者对策略更新的影响,以最大限度提升集群中合作者平均丰度,促进集群合作的发生。 此外,还仿真了愿景水平α与XA的关系曲线,ω分别取0、5、10、15、20,c=1,r=1.1。关系曲线如图5所示。 图5 平均丰度与愿景水平间的关系曲线Fig.5 Relationship between average abundance and aspiration level 由图5可见,随愿景水平α的增加,XA呈增加趋势,这表明愿景水平的提高,使得非合作收益更难以达到其期望水平。由式(4)可知,策略更新概率PB→A增加,更多的非合作者转变为合作者。当α足够高时,在任何选择强度下,limα→∞XA=1/2将成立。 结论 2线性公共物品博弈中,在成本c、收益系数r保持不变的情况下,合作者平均丰度将在较大愿景水平处保持相对较高水平。 因此,在线性公共品博弈模型下的无人集群作战管控中,可通过为集群预设较高α参数值,增加集群由非合作转变为合作策略的概率,以最大限度提升集群中合作者平均丰度,促进集群合作的发生。 在带门限值的公共品博弈中,只有当群组中合作策略持有者总数量不低于门限值m时,个体才会获得收益。当k≥m,且X选择合作策略A,则群组可获得的总资源量为kc+c,成本增值后的总获益为r(kc+c),因此易得单体获益为r(kc+c)/d。另一种情况,X采取了B策略,对应地,上述几个参数分别变化为kc、rkc、rkc/d、rkc/d+c。因此,ak与bk具体形式为 (36) (37) 收益矩阵如表3所示。 表3 门限公共品博弈收益矩阵Table 3 Incme matrix of public goods game with threshold 因此: (38) 不同于线性公共品博弈,式(38)并无明显的策略占优特征。接下来,试图通过计算与仿真,比较愿景驱动与模仿动态两类策略占优条件的严苛程度。 (39) 则式(39)等价于: (40) r>d-m (41) 比较式(40)与式(41)可以得到以下结论。 为分析愿景驱动下,门限公共品博弈策略占优特性,取α=1、N=100、c=1、d=10,仿真分析不同的门限值m及收益系数r对合作策略占优的影响。m、r与XA的关系曲线如图6所示。 图6 门限公共品博弈中门限值、收益系数与XA的关系Fig.6 Relationshiop between threshold value,reward coefficient and XA in public goods game with threshold 由图6(a)可知,在r=2时,当门限值m由4提升到7,合作策略的平均丰度XA不仅相应地完成了提升,而且实现了占优策略的转换(平均丰度由XA|m=4<0.5转换为XA|m=7>0.5,占优策略由B转换为A)。图6(a)右上角面板给出了几组门限值m与收益系数r间的关系,随门限值增加,合作策略占优时所需的收益系数越来越小(即所需的回报越来越少)。相比于图6(a),在图6(b)中,m仍然取4与7,然而由于r由2增加为4,因此在相同的选择强度和门限值下有XA|m=4,r=4>XA|m=4,r=2和XA|m=7,r=4>XA|m=7,r=2。 结论 3门限公共物品博弈中,在成本c、愿景水平α保持不变的情况下,较高的门限值能够促进合作,即使在较低的收益系数下;且在相同的门限值下,较高的收益系数更利于合作的产生。 因此,在门限公共品博弈模型下的无人集群作战管控中,可通过同时提高门限值m及收益系数r,以发挥愿景驱动在促进集群合作中的优势,实现集群中合作策略占优目的。 在实际的无人集群管控中,依据第2节提出的无人集群演化博弈模型及愿景驱动动态,为无人集群预设自主协同规则RC。另外,针对具体作战场景,依据本研究所获结论1至结论3,预设成本c、愿景水平α、收益系数r、门限值m等参数调整规则(r1-r3)。当地面控制站通信中断后,无人集群可根据预设规则临机作出有效响应,实现集群中合作策略的占优,以持续完成既定军事任务。 例如,在实际作战中,无人机的愿景水平α一般为定值,且弹药、通信等作战成本c难以进一步压缩。此时,无人集群可在RC框架内依据r3自动为协同进程设置较高的门限值m及收益系数r,以此提升集群稳定时(对应于演化稳定的ESS状态)合作者的占比,促成集群中合作行为的涌现及合作策略占优的实现。 无人集群的自主协同是目前军事领域新质作战力量和颠覆性技术研究的焦点。自主协同中一个关键问题是,如何设计合理机制,提高作战集群中合作者比例,以保证集群的整体作战效能。本文首先建立了基于愿景驱动的多元演化博弈模型,然后理论推导出模型的平均丰度函数及策略占优条件,在此基础上,对线性和带门限值的两类公共品博弈进行数理推导并仿真分析选择强度ω、收益系数r、愿景水平α和门限值m对策略占优的影响,获取两类博弈模型的策略占优特性,为无人集群作战的机制设计提供辅助决策。 本研究中,假设了集群结构的混合均匀性,未考虑结构对策略占优特性的影响,而在现实战场环境中,作战平台通过物理/信息链接从而形成特定的网络结构。下一步课题组将引入复杂网络思想,计算特定网络结构下的无人集群演化博弈及策略占优特性。

4.2 门限公共品博弈



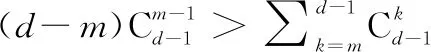
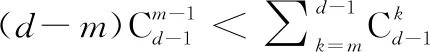

5 结 论
