基于模板匹配OCR的报告自动归档系统研究
2021-08-24张辰,陈阳
张 辰,陈 阳
(1.广东省建设工程质量安全检测总站有限公司,广东 广州510500;2.广东省建筑科学研究院集团股份有限公司,广东 广州510500)
0 引言
光学字符识别(Optical Character Recognition,OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。其在文档归档应用背景下具有广阔的市场前景。OCR字符识别技术经过 多 年 发 展 ,已 有 LeNet[1]、RRPN[2]、DMPNet[3]、CTPN[4]等OCR网络结构被提出。其中,CTPN是目前应用最广的文本检测模型之一。其基本假设是单个字符相较于异质化程度更高的文本行更容易被检测,因此先对单个字符进行类似R-CNN的检测,并在检测网络中加入双向LSTM[5],使检测结果形成序列提供了文本的上下文特征,便可以将多个字符进行合并得到文本行。LeNet网络提出时间较早,在银行票据手写体字符识别方面有着长期的应用。上述网络结构可以在通用背景下有效识别场景中的字符,对于非垂直文本也能进行检测。对于大多数OCR的应用场景,并不需要对图片中的所有字符进行识别,往往只需要对部分ROI区域的字符进行检测,但OCR技术对ROI区域的位移与旋转适应性较差,需要训练单独的网络来对ROI区域进行定位。机器视觉技术在制造业领域有着广泛的应用,特别是在工件定位、视觉测量等方面有大量成熟的算法,其中,模板匹配算法则针对工业定位[6-7]的应用背景,提出了基于灰度[8]、边缘[9]、变换域[10]的模板匹配算法,能适应各种工业定位需求[11-15]。
计算机视觉技术与机器视觉技术在土木建筑行业的应用十分有限,就材料检测而言,存在大量检测报告需要进行数字归档,海量的报告归档消耗了大量的人力成本与时间成本。其中,报告种类繁多、扫描质量、人员操作不规范等问题,使得OCR技术无法同诸如银行票据识别在建材检测行业落地。
综上所述,本文针对建筑行业报告归档的实际应用,提出了机器视觉技术与计算机视觉OCR技术结合的方案。利用机器视觉领域中具有强适应性(鲁棒性)的模板匹配技术,克服检测报告扫描质量不可控、检测报告扫描结果位移与形变等诸多难题,再利用OCR技术强大的字符识别能力,构建了一套基于模板匹配技术与卷积神经网络的报告自动归档系统,所构建的系统对检测报告的正确归档率达到了95.8%。相较于人工归档,系统自动化归档可节约大量的人力成本与时间成本。
1 寻找ROI区域
报告自动归档就是对报告编号进行识别并进行重命名保存,但报告编号的位置与大小不固定,且报告的扫描质量没有统一标准,要对报告中的具体内容进行识别,就需要先对报告图像中的要素进行分类,寻找到需要进行识别处理的区域。本文使用了基于边缘的模板匹配方法来进行要素搜寻,定位ROI区域。
模板匹配的方法主要有三种:(1)基于灰度;(2)基于边缘;(3)基于变换域。基于灰度与基于变换域的模板匹配方法针对图像的线性变换具有较强的鲁棒性,匹配目标的速度快、精度高。基于变换域的方法还可以过滤频域中特定频率的信号,使其具有良好的抗噪性。但当匹配目标发生重叠、部分缺失、局部光照变化或非线性变化的情况下,上述两种方法的匹配效果较差。
基于边界的模板匹配算法的核心是图像边缘检测。边缘检测的方法很多,但主要分为两大类:基于搜索的边缘检测方法和基于零交叉的边缘检测方法。基于搜索的方法检测边缘,首先计算边缘强度的度量,通常是一阶导数表达式,如梯度大小;然后估计边缘的局部方向,如梯度方向;最后在图像上使用X方向和Y方向上的梯度或导数来匹配。基于边界的模板匹配算法主要包含两个步骤:(1)创建基于边缘的模型;(2)使用模型在图像中搜索。
1.1 创建边缘模板
(1)计算图像梯度
为了计算图像中每个像素点的梯度大小和梯度方向,本文采用了水平滤波器与垂直滤波器来检测图像中像素值变化剧烈的像素点,滤波器的构造方式如图1所示。定义待检测的点在图片中的像素坐标为(x,y),该像素点点坐标的像素值为 f(x,y),水平与垂直滤波器的输出值 Gx、Gy按式(1)与式(2)进行计算:

图1 滤波器构造示意图
像素点(x,y)的梯度大小 Mag与梯度方向 Dir可由式(3)与式(4)进行计算:
(2)梯度增强与梯度归一化
为了更好地获取图像的边缘信息,计算每个像素点的梯度信息后,可对每个像素点的梯度值进行增强与归一化处理。
定义像素点(x,y)梯度方向上左右两侧像素点的 梯 度 值 为 LeftMag(x,y)、RightMag(x,y), 所 有 像 素点中的最大梯度值记为 MaxMag,像素点(x,y)的梯度值 Mag(x,y)的增强方式按式(5)处理:
利用式(5)对所有像素点的梯度值进行处理后,边缘像素点的梯度值被归一化到了255个强度等级,而从式(5)可知,确定为非边缘像素点的梯度强度将直接被清零。根据上述处理方式,得到了归一化图像梯度图 nmsEdges,nmsEdges中任意一点的表达形式如式(6)所示:
nmsEdges(x,y)⇒width×height×Mag*(x,y) (6)式(6)中,width表示图像的像素宽度,height表示图像的像素高度,Mag*(x,y)为像素点(x,y)处的增强结果,由此可见,归一化图像梯度图nmsEdges本质上为一个三维矩阵。
(3)滞后阈值处理
在完成nmsEdges的计算之后,通过滞后阈值处理可以获得图像最终的真实边缘像素点集合。滞后阈值处理针对模糊边缘进行像素领域判断,找到模糊边缘的分界边缘,并筛选真实边缘点,排除假边缘点。
定义最大梯度对比度maxContrast与最小梯度对比度 minContrast。 当 像 素 点(x,y)处 的 Mag*(x,y)>maxContrast时,该像素点的最终边缘梯度值设定为1/Mag(x,y)。 当 maxContrast>Mag*(x,y)>minContrast时,如果该点周围八邻域的归一化梯度值均小于maxContrast,则直 接将该 点的梯度值 Mag(x,y)计 为0,从而实现对模糊边缘的边界判定,同理,如果该点的 minContrast>Mag*(x,y),则 认为 该 点为 假 边缘点,直接将其边缘梯度设定值计0。至此,对图像边缘的提取完毕,边缘提取结果示意图如图2所示。

图2 对边界的提取效果
1.2 基于边缘的模板匹配

在匹配的过程中,使用相似度Score来衡量模板与搜索图中目标的匹配程度。对于搜索图中像素点(u,v)处与模板的相似度 Scoreuv使用式(7)进行计算:

式(7)中,n表示模板中像素点的总个数,如果搜索图中某个位置的Scoreuv为1,则说明该位置的边缘图案与模板边缘完全匹配。图2(b)所展示的边缘模板进行匹配的效果如图3所示。

图3 边缘模板的匹配效果
为了加快匹配速度,可在总数为n的模板像素点中选取m个像素点参与相似度的计算,从而使得匹配过程不需要所有像素点都参与其中,以此提高模板匹配的速度。
而对m个点的选取原则采用式(8)的选取方式,其中Scorem表示搜索图像素点中的第m个点的相似度值,如果第m个点不满足式(8)所述条件,则排除该点。g表示算法搜索的贪婪度,取值范围为(0,1),贪婪度控制了点的利用率,当g设置为0时,所有相关点都需要参与到匹配计算中。g越大则表示匹配过程利用的点越少,虽然可以提高算法的运行速度,但是会使得算法的鲁棒性下降。Scoremin则表示最低相似度值,为算法的设置参数。
2 OCR数字识别网络的构建
对于文档自动归档的应用场景,其本质上可以将其定义为一个手写体数字字符识别问题,文档中主要出现的是工业字符,相对于手写体识别,其识别难度更低。因此,本文使用了LeNet网络架构来构建本文的文档字符数字识别模型,该网络在银行票据手写体字符识别得到了广泛的应用。LeNet的网络结构如图4所示。
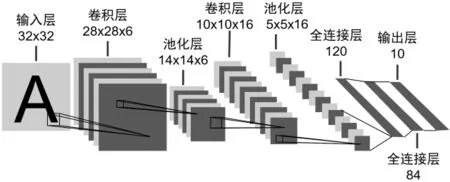
图4 LeNet网络结构
从图4可知,LeNet网络总共由输入层、输出层、两层卷积层、两层池化层以及两层全连接层组成。LeNet网络的核心就是卷积操作,图5为图像卷积运算的基本流程。其中图5(a)所示原图像尺寸为8×8,图像左半部分为深色,右半部分为浅色。Gi,j为图 5(b)所示的 3×3卷积核,将其沿着原图像长、宽方向进行卷积运算,滑动步长为1。卷积运算前,在原图像上进行一定程度的像素填充延拓,如图5(b)左图,使得输出图像仍然为8×8,所得输出特征图如图5(b)右图所示。
原图像经过卷积运算后特征图中显现出原图像的交界线。从图5可见,图5中的卷积核与上一节中的水平卷积核类似,其对边界敏感,如果对同一张图片采用不同的卷积核进行卷积运算,就可以提取图像中的高级抽象特征,且卷积操作沿着图像平面滑动,其对特征的感受能力不随其位置的变化而改变,即具有平移不变性。
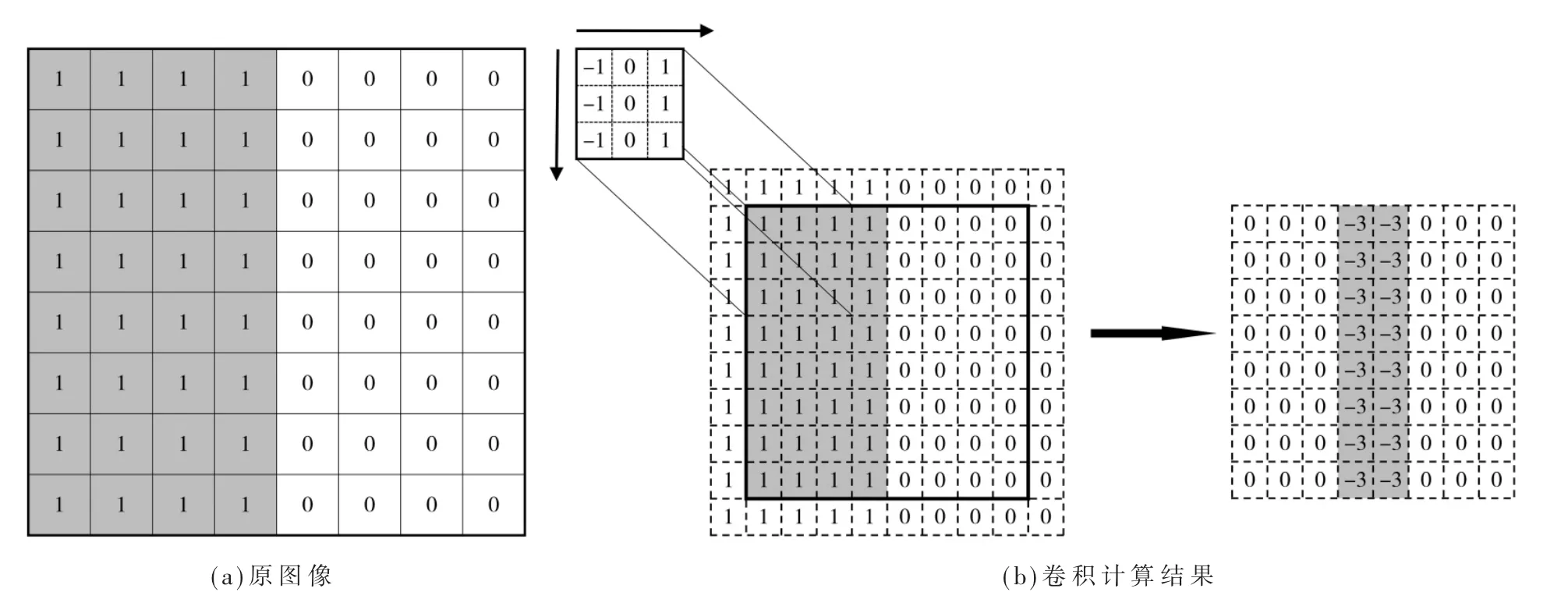
图5 卷积运算流程
池化层对输入进行池化操作,卷积操作可称为下采样,卷积过后,图像尺寸变小,而池化操作则是进行上采样,池化后图像尺寸变大。与卷积运算不同,池化的目的不是提取高级抽象特征,而是通过组合高级抽象特征以再现低级的具象特征,因此每个池化操作都对应一个卷积操作,它们之间的计算参数具有相关性。卷积与池化的对应计算流程如图6所示。

图6 池化操作与卷积操作
通过卷积/池化操作,可以容易地区分数字字符,如字符数字“1”在卷积池化后具有直线特征而不存在曲线特征,而数字字符“3”则不存在直线特征,有且仅有曲线特征。最终将特征集合输入LeNet网络的全连接层,使得LeNet能够轻松胜任OCR数字字符识别任务。
3 实验验证
本文的报告自动归档系统的运行过程主要分为两步:(1)识别“报告编号”关键字,并定位其在图像中的位置与角度;(2)根据 ROI定位结果,将识别区域进行抠图,在将抠图后的图片区域处理后输入到LeNet网络,最终得到报告编号的OCR识别结果。
3.1 ROI区域的定位
通过对报告图片的仔细分析,发现报告中可能存在干扰 ROI区域定位的要素,即“样品编号”,其与“报告编号”都存在“编号”这一共同要素,如图7所示。因此在生成边缘模板时,尽量选择清晰的图片生成模板。
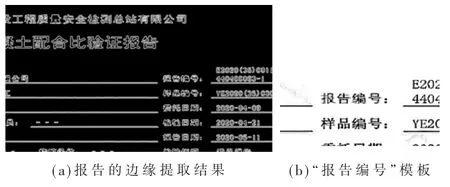
图7 生成边缘模板
由于存在共同要素“编号”,因此模板匹配的Scoremin不能低于0.5。与此同时,本文的应用背景为报告自动归档,从而代替人工,以节约人力成本。不同于高速生产线追求高速的识别,本文的应用背景更加注重算法的安全性。本文抽取了200份报告进行模板匹配测试,每张报告的图像尺寸为1 240×1 753,在Scoremin=0.7的基础上,对贪婪度g的设置进行了测试,测试结果如图8所示。
在图8中,正确定位率是指对“报告编号”的定位准确率。误定位率则是匹配结果的得分高于Scoremin,但匹配位置错误。无定位率值匹配结果低于Scoremin,因此没有定位输出结果。当贪婪度g=0.1时,表明模板的大部分像素点都参与到了匹配任务中,200份报告的平均匹配时间为1.965 s,匹配准确率为99%,没有发生误定位;当设置g=0.7时,匹配耗时为 0.034 s,匹配准确率仅为54.5%,误定位率高达45.25%。
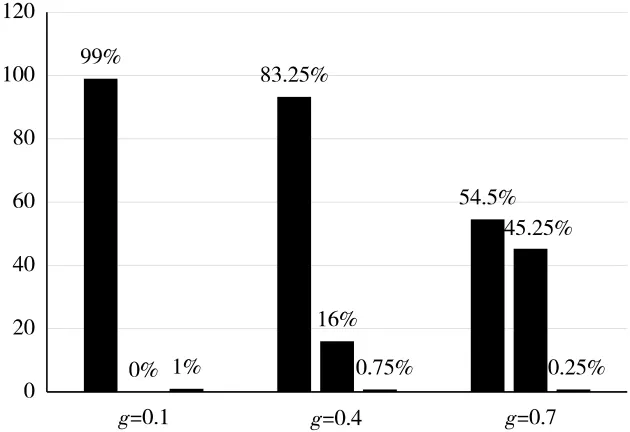
图8 不同贪婪度下的模板匹配结果
在设置 Scoremin=0.7,g=0.1的情况下,对三种报告的模板匹配结果如图9所示。基于边缘的模板匹配算法,通过设置低贪婪度与高相似度,可以准确地匹配搜索图中的目标图形,且能较好地适应匹配目标的变形与旋转,为后期的OCR数字字符识别提供了基础。

图9 模板的匹配效果
3.2 OCR数字字符识别
本文总共对报告中0~9的数字字符进行了截取,每种字符截取了80个样本,85%的样本作为卷积神经网络的训练集,10%的样本用于测试集,5%的样本用于过拟合测试集。训练终止迭代周期为1 000,初始学习率为 0.001,截止误差为0.000 1。图10展示了对LeNet网络的训练过程,前100个训练周期内网络逐渐收敛,100~300训练周期内出现小幅震荡,最终于480训练周期达到迭代停止条件,训练误差达到最低,过拟合误差开始上升,此时的训练错误率仅为1%。
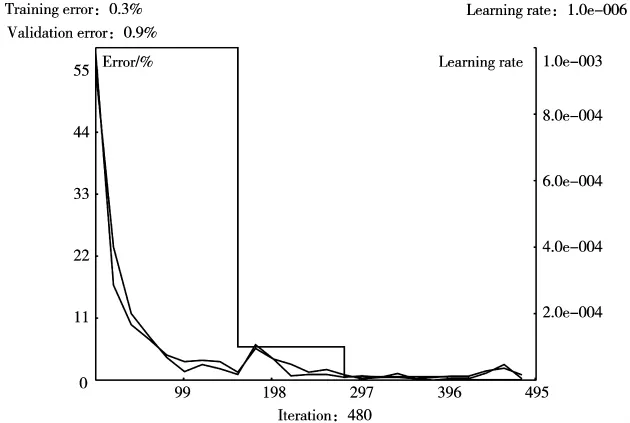
图10 卷积神经网络的训练过程
对于网络的输入图像,均归一化到了 32×32维的矩阵,输出结果为 10维列向量,表示 0~9。对网络输出的可视化展示如图11所示,本文通过LeNet网络对100份报告共900个字符进行数字字符识别,实验结果显示,LeNet网络对数字字符的正确识别率达到了96.77%,结合模板匹配算法,整个系统的综合识别率为95.8%。

图11 OCR数字字符识别可视化
4 结论
本文所构建的报告自动归档系统可以节约大量人力成本,减少了人员手动录入时间,虽然存在错误识别的情况,但检测人员只需要对重命名的文档进行检查,极大地提高了报告归档效率。通过对识别错误的报告进行分析,发现识别错误的情况多出现在印刷不均匀的数字字符上,后续工作可不断收集错误报告的字符,对网络模型进行增量式训练,以进一步提升网络的识别正确率。
