基于特征集聚和卷积神经网络的恶意PDF文档检测方法
2021-08-24俞远哲王金双
俞远哲,王金双,邹 霞
(陆军工程大学 指挥控制工程学院,江苏 南京210001)
0 引言
PDF(Portable Document Format)文档的使用非常广泛,但随着版本的更新换代,PDF文档包含的功能也变得多种多样,其中一些鲜为人知的功能(如文件嵌入、JavaScript代码执行、动态表单等)越来越多地被不法分子利用,来实施恶意网络攻击行为[1]。APT(Advanced Persistent Threat)攻击[2]常常借助恶意PDF文档这一媒介,通过社会工程学、水坑攻击、钓鱼攻击等手段,构造巧妙伪装的恶意文档,诱骗受害者下载,从而侵入或破坏计算机系统。相比传统的可执行恶意程序攻击,恶意文档攻击具有更强的迷惑性。
近年来,基于机器学习的恶意PDF文档检测技术被广泛使用。相比于传统签名匹配检测,它能够及时发现新型恶意文档且检测模型更新方便迅速。其中基于静态检测的机器学习方法,具有高效、成本低、解释性强等特点。而深度学习相较于机器学习算法,更强调学习数据中的隐藏信息,如特征的相关性。
前期研究利用传统的机器学习模型如SVM、随机森林等,对小规模的数据分类效果较好,但是当数据维度(包括特征维度及样本维度)过大时,需要耗费大量的资源进行学习。而卷积神经网络通过卷积核来实现高维数据的处理,提取局部特征;通过池化操作,来提取一块区域内的主要特征,能降低参数数量,减少冗余,防止模型的过拟合;最后通过全连接层,将局部特征根据权值整合成完整的特征。但是实际应用中,文档特征与图像特征不同,因为文档特征提取的顺序不同,不相邻的两类特征之间也存在一定的相关性,而卷积核提取的是局部相邻特征,损失了部分全局信息,降低了文档特征的表征能力。
因此,本文设计了一个基于特征集聚和卷积神经网络的训练模型。首先通过特征集聚来挖掘特征间的潜在相似度,提升特征的表征能力。同时实现了特征降维,提高了模型训练的效率。再利用卷积神经网络挖掘聚合特征之间的关系,自动地从数据中学习训练得到一个成熟的检测模型。
本文的主要工作如下:
(1)以静态检测技术为基础,提取文档的常规特征和结构特征进行集聚,以Ward最小方差聚类方法评估两类特征间的潜在相似度。Ward方法是一种层次聚类算法,它较于其他聚类的优势在于不依赖于聚类初始点的选择,并能最小化两类特征合并时导致的平方误差,使得每次合并的都是最相似的两类特征。通过将潜在的相似特征以迭代的方式合并得到聚合特征,实现了特征的聚类,降低了特征空间维度,提升了模型的训练效率和特征的表征能力。
(2)将文档的特征值送入CNN模型,利用三个不同大小的卷积核来发掘特征空间里不同范围的特征向量所包含的隐藏信息。将三者得到的特征图合并,并采用最大值池化的方法将特征值整合,最后通过全连接输出得到结果。同时在池化层与全连接层之间加入了Dropout层,起到减少特征冗余避免过拟合的发生。
1 相关工作
传统的恶意PDF文档检测方法主要基于签名识别和启发式规则匹配[3],优点是误报率低,但局限于对病毒库中已有的恶意样本进行检测,面对未知恶意文档反应迟缓,攻击者可以通过伪造新的恶意文档来绕过检测。2003年,Goel[4]提出了基于Kolmogorov复杂度度量的签名匹配技术,通过计算信息距离,用于恶意文档的相似性度量,从而对未知文档进行检测;2010年,Baccas[5]通过分析恶意 PDF样本,根据对象标签建立了一个规则和特征库,以筛选过滤恶意文档。但是这类方法维护成本和周期长,制定的规则过于依赖专家经验,容易漏报变异较大的或是新型恶意文档。
基于机器学习的静态检测技术主要利用元数据[6]、JavaScript脚本特征[7]、文档结构[8]等特征进行识别。它主要可以分为三类:
(1)对文档进行二进制分析,使用N-gram方法提取特征送入分类器模型训练预测。2013年Pareek等人[6]提出了基于熵和N-gram分析的PDF文档检测方法,通过将文档转化为一个二进制序列,计算其熵值,对于熵值不在置信区间内的可疑文档进行N-gram分析检测。研究表明恶意文档的熵值普遍较低,该方法优势在于无需解析文档内容,但是对文档的特征分析不够,攻击者可以通过在良性文档嵌入恶意脚本的方式构造恶意文档,使得文档的熵值变化不大,从而逃避检测。2018年,Kumar等人[9]提出使用图像相似性技术将文件先转化为二进制代码,再转化为灰度图像使用卷积神经网络进行分析。2020年Fettaya等人[10]将文档字节序列特征送入卷积神经网络进行检测。该类方法无需任何预处理和特征提取,但是由于文档大小不固定,文档的二进制序列长度也不一致,当长度差异较大时,容易出现语义截断的问题。
(2)对文档内容中的标签、页数、编码、JavaScript脚本等进行解析,如2018年Jason Zhang提出了MLPdf[11],它同时选取了PDF内容特征和结构特征,送入多层感知器(MLP)中进行学习检测。
(3)根据文档结构特征进行分析,如Srndic和Laskov提出了 Hidost[12],通过对象之间的引用关系构造了PDF结构树,然后从PDF的结构树中提取每个对象的最短结构路径,并将这些路径的二进制计数作为特征,送入决策树模型和SVM模型进行训练评估。
静态检测无需执行文档程序,具有特征提取方便、检测效率高的特点,但同时文档的静态信息也容易被攻击者所混淆[13],影响分类器的检测结果。
2 本文方法
2.1 检测框架
本文提出了一种基于特征集聚和卷积神经网络的恶意PDF文档检测方法CNN-FAG,其整体框架如图1所示。首先,特征提取模块使用PeePDF[14]对PDF文件进行结构解析,得到结构特征;使用PDFid[15]解析文档获得常规特征。其次,特征集聚模块将两大类特征依据Ward方法合并,得到特征向量。最后,学习检测模块基于CNN模型对特征学习检测,并进行模型评价。
2.2 特征提取模块
本文所选用的特征包括常规特征和结构特征,常规特征指描述PDF文档本身的内容特征,如对象标签、JavaScript代码、压缩数据等。这些特征能直接从文档的静态信息中抽取得到,无需分析代码逻辑。
2.2.1 常规特征
基于对PDF格式的分析,本文涉及的常规特征主要包括 14个,包括 Page、Encrypt等,其含义及安全相关性如表1所示。这些特征单独一个无法完全对恶意PDF文档进行分类,但是综合所有特征就会更容易进行分类。例如,大多数恶意文档通常只包含一页,恶意文档越小越容易在网络上进行快速的大规模扩散,但是也有一部分恶意文档为了进行针对性的攻击,通过在正常文档的基础上嵌入恶意脚本,使得具有恶意行为的特征很难被发现。因此需要综合分析多个特征,来对文档进行更有效的分类。

表1 14个常规数据特征的含义及其安全相关性
2.2.2 结构特征
PDF结构树是以/Catalog标签为根节点,根据引用对象号指向子对象节点,以此层层递进直到没有引用对象号,即到达叶子节点,最后形成的树或森林结构如图2所示。

图2 PDF结构树
结构特征反映了PDF文档中各对象的相关性,但是无法像常规特征一样直接反映文档的恶意属性,且特征分析相对复杂。本文依靠PeePDF工具得到文档的结构树,然后提取得到结构路径,在此基础上,设计了3类特征来标识文档的属性,具体如表2所示。

表2 3个结构特征的含义及其安全相关性
2.3 特征集聚模块
通过分析前表提到的各特征的安全相关性,可知单一特征并不足以证明文档的恶意性,比如含JavaScript标签的路径占比高可能是恶意文档只包含了恶意JavaScript代码,占比低也可能是正常文档被嵌入了恶意代码。考虑到各特征之间存在一定的内在相似性,通过相似性度量合并相似特征,有助于特征降维及消除冗余。因此,本文合并常规和结构两大类特征进行集聚处理。本文使用的特征集聚方法是以各类特征作为聚类对象,使用层次聚类中的Ward方法评估两类特征间的潜在相似度,来得到聚合特征。Ward方法将每一个特征看作一类簇,以两个簇合并后其离差平方和(ESS)的增量作为两个簇间合并成本C,合并成本C最小的两个簇生成新的簇,迭代直到得到所需数目的特征簇。ESS的计算如下:
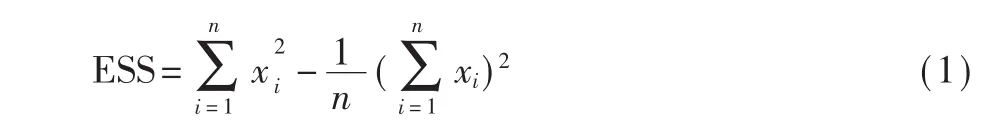
两个簇x和y的合并成本C,是由合并后的总ESS减去合并前的总ESS得到的,计算公式如下:

Ward方法的算法伪代码如下:

2.4 学习检测模块
本文使用的CNN模型结构如图3所示,输入层是样本中提取得到的N维特征向量,然后使用3个不同的卷积层对特征向量矩阵进行卷积操作。每个卷积层都由128个宽度为N的卷积核构成,卷积核的深度分别为 8、16、32。通过三个拥有不同大小卷积核的卷积层,来发掘特征空间里不同范围的特征向量所包含的隐藏信息。然后将三者得到的特征图合并,并选择最大值池化的方法将特征值整合,最后通过全连接输出得到结果。为了防止模型的过拟合,采用了ReLU作为激活函数,减轻了参数之间的相互依赖关系。同时在池化层与全连接层之间加入了Dropout层,以减少特征冗余,避免过拟合的发生。
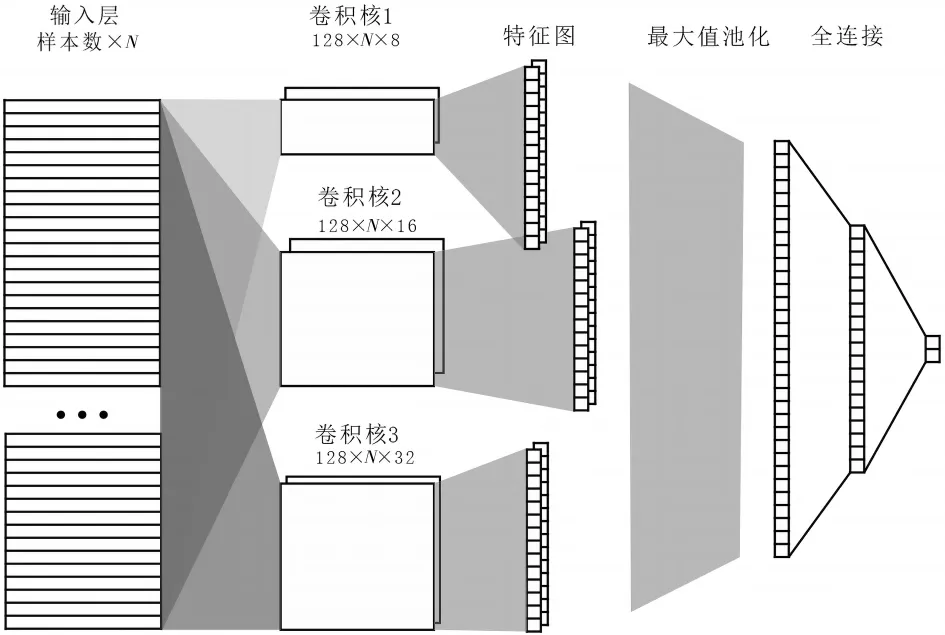
图3 CNN模型结构
3 实验结果与分析
3.1 数据、平台和评价指标
实验环境为CPU Intel(R)i7-9750H,32 GB内存,GPU为 GTX2060,硬盘为 120 GB SSD,使用 Ubuntu-16.04操作系统。实验数据集中恶意PDF文档来自于 VirusTotal[16]病毒数据库以及 Contagio数据集[17],良性样本来源于Contagio数据集。使用的良性样本数为9 093个,恶意样本数为 21 598个,统计样本数为30 691个。
本文的分类模型使用了准确率Accuracy、精确率Precision、召回率 Recall、F-score以及模型训练耗时time五个指标进行综合衡量,前四个指标的计算方法如下:

其中tp为真正例,fp为假正例,tn为真反例,fn为假反例。
3.2 检测性能测试
考虑到样本比例失衡以及数据集样本量小的情况,会更容易导致模型训练不佳,因此,以样本容量为2 000的数据集为基础,在三组不同的样本比例条件下,通过改变特征向量维度N的值,即N=2,4,6,8,10,12,17 时, 对分类器的分类准确率Accuracy、精确率Precision、召回率 Recall、F-score以及模型训练耗时time五项参数进行统计,检验模型的综合性能。
首先对样本总数为 1 800,良性恶意样本比例为1:1的数据集进行测试,测试结果如表3所示。
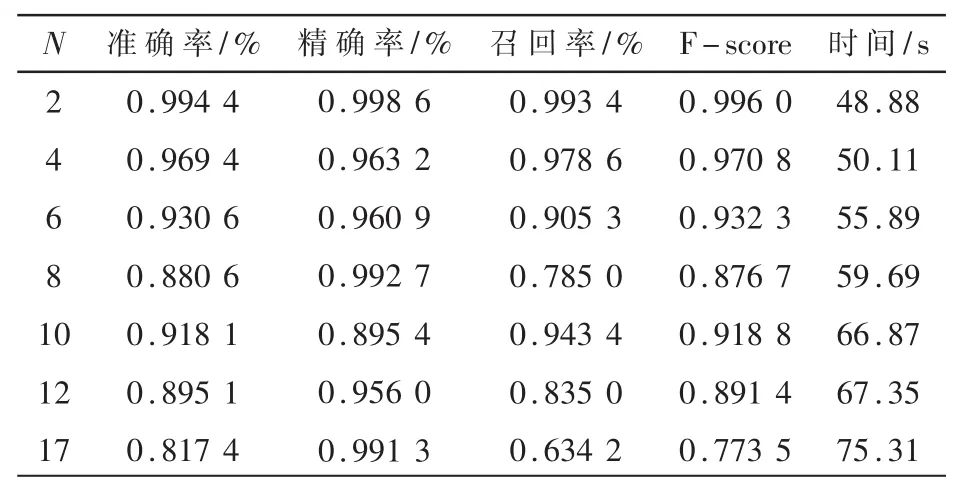
表3 样本比1:1各指标数值表
对样本总数为1 350,良性恶意样本比例为2:1的数据集进行测试,测试结果如表4所示。
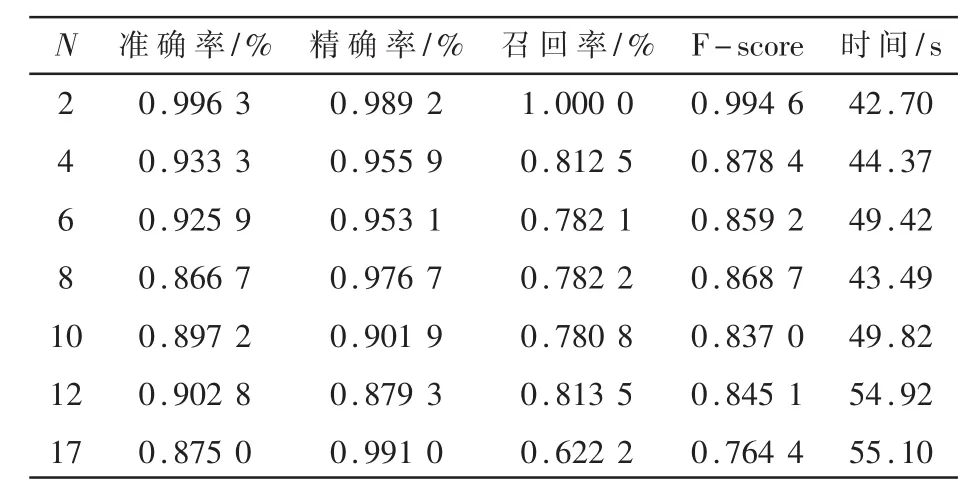
表4 样本比2:1各指标数值表
对样本总数为1 000,良性恶意样本比例为9:1的数据集进行测试,测试结果如表5所示。
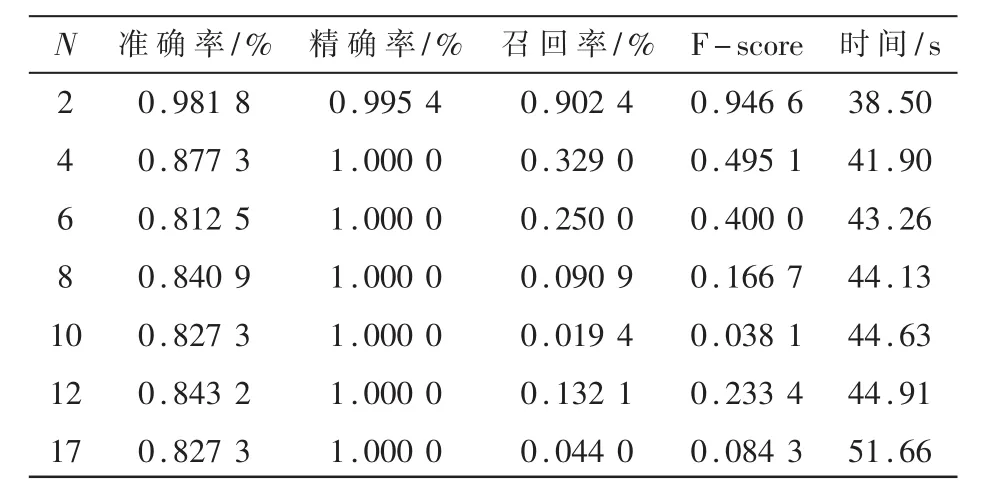
表5 样本比9:1各指标数值表
F-score对于二分类模型的结果具有较为客观的评价,为了更为直观地呈现结果,本文基于表3、表4和表5中的 F-score结果绘制了图4。
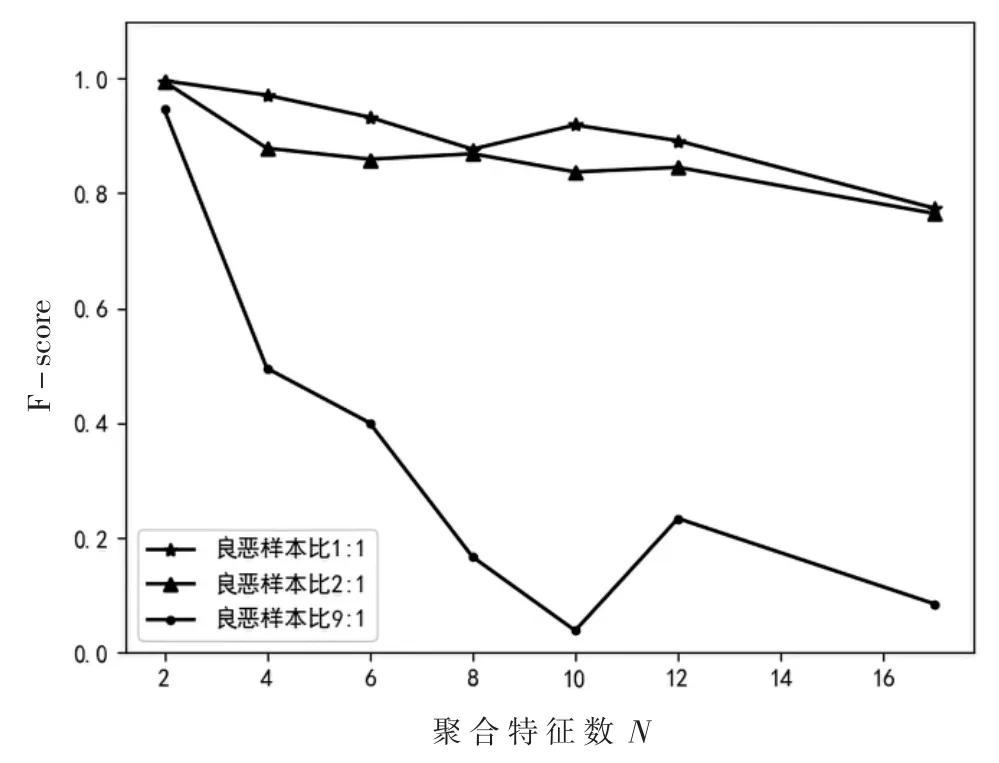
图4 F-score对比
对图4中的数据进行分析,可以发现随着聚合特征数N的增加,F-score呈下降趋势,且不同的良恶比下,聚合特征 N=2时,F-score值最高,说明模型的综合性能最高,与N=17,即未聚合特征的分类模型相比,大约有20%的显著提升。当N=10时,F-score发生了突变,为了深层次地探究影响F-score的因素,基于表 3、表 4和表 5,绘制了 Precision折线图和 Recall折线图,如图 5、图 6所示。

图5 Precision对比
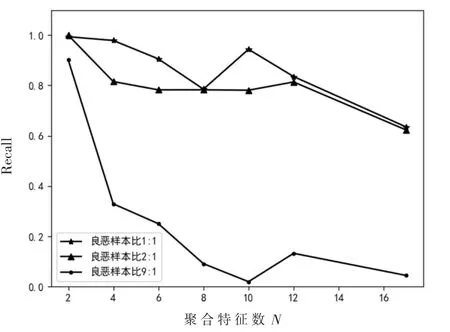
图6 Recall对比
对图5进行分析可知,在三种不同的样本比例之下,Precision变化趋势几乎相同,几乎均为 95%,说明Precision几乎不受样本比例的影响。当N=10时,各样本比例下的Precision都有明显下降,说明聚合特征数为10时,特征对模型预测的贡献比较弱,导致 Precision偏低。
对图6进行分析可知,Recall受样本比例的影响较大,当良性样本数多于恶意样本数时,Recall明显下降,也导致了F-score下降。同时可以看出,样本比例失衡容易导致模型欠拟合。当良性恶意样本比例为9:1时,初始模型的召回率只有甚至达到了5%,但是通过特征集聚,召回率提升到了 95%,说明该方法提升了模型的灵敏度和分类能力,有效缓解了模型的欠拟合问题。当聚合特征数为10,样本比例为9:1时,图像出现了拐点,召回率低则模型的分类能力差。说明此时得到的聚合特征使得模型产生了比较严重的欠拟合问题,样本比例越失衡,该问题越明显。同时因为召回率极低,导致了表5中N=10对应的F-score比较异常。综上分析可得,当训练良性恶意样本比例为1:1,聚合特征数N为2时,分类模型的效果最好。纵向比较来看,分析表3数据可得,特征集聚前后模型的准确度提升了18%,召回率提升了 36%,F-score提升了 0.22,说明特征集聚的方法提高了特征的表征能力,缓解了模型的欠拟合问题,并提升了模型的综合性能。
为检测本模型的性能,本文使用样本总数为30 691的数据集进行测试,将结果与近年来其他模型对比,如表6所示。对比可以得到,本文提出的分类模型较前人提出的方法在各指标上都有所提升。
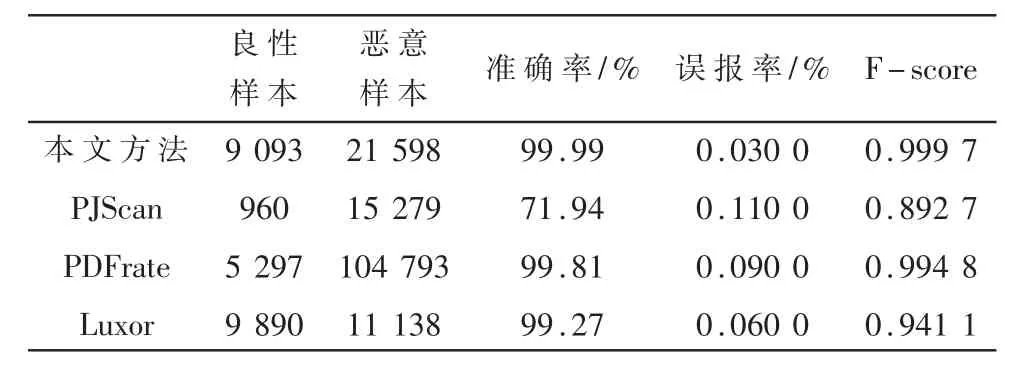
表6 各方法指标比较
4 结论
针对PDF恶意文档的传统静态检测方法特征维度高、数据集样本少导致过拟合等问题,提出了一种基于特征集聚和卷积神经网络的恶意PDF文档检测方法CNN-FAG:通过整合常规特征和结构特征,将特征数据正则化,提高模型的泛化能力,以此构造一个初始特征集,然后使用层次聚类中的Ward最小方差聚类方法得到聚合特征,最后送入CNN模型进行训练与检测。通过纵向比较和横向对比的方式对模型的检测效果进行了验证,取得了较为满意的结果。CNN-FAG实现了特征降维,缓解了模型的过拟合问题,提升了模型的综合性能。
下一步亟待改进的工作:选取更多的混淆不变特征加入初始特征集中,提高特征空间的表征能力;根据实际检测偏好需要,改变F-score中的偏好值β;增加特征维度,进一步完善分类器模型,提升分类模型的鲁棒性和综合效能。
