基于多任务学习的无参考超分辨图像质量评估
2021-08-24刘锡泽李志龙何欣泽
刘锡泽 ,李志龙 ,何欣泽 ,范 红
(1.东华大学 信息科学与技术学院,上海 201620;2.OPPO研究院,上海 200030;3.上海大学 通信与信息工程学院,上海 200444)
0 引言
单幅图像超分辨率重建(Single Image Super-Resolution Reconstruction,SISR)是图像复原的一种,其通过信号处理或者图像处理的方法,将低分辨率(Low-Resolution,LR)图像转化为高分辨率(High-Resolution,HR)图像[1]。目前,SISR被广泛应用在医学影像、遥感图像、视频监控等领域当中。近年来,许多SISR算法相继被提出,因此需要一种可靠的方式来衡量各种算法重建图像的质量好坏。
最可靠的图像质量评估方式是主观评分,但这种方式需要耗费大量的人力和时间,所以往往使用客观评价指标来对超分辨(Super-Resolution,SR)图像进行质量评估。最常用的图像客观评价指标是峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似度(Structural Similarity,SSIM)。但在 SISR领域中,这两个指标与人眼感知的一致性较低[2]。因此研究者们提出了一系列基于人类视觉系统(Human Visual System,HVS)的图像质量评估算法,如信息保真度(Information Fidelity Criterion,IFC)[3]、特征相似度(Feature Similarity,FSIM)[4]等算法,在图像质量评估数据库中的性能超过了PSNR、SSIM等传统算法。
由于以上算法都是全参考图像质量评估算法,需要HR图像的信息,在显示中HR图像往往是不可获得的,因此需要开发一种有效的无参考图像质量评估算法。Ma等人[5]针对SR图像提出了一种基于两阶段回归模型的图像质量评估算法,并创建了第一个SR图像质量评估数据库,包含用9种SR算法重建的1 680张SR图像与每张图像的主观质量分数。近年来,卷积神经网络(Convolutional Neural Network,CNN)被广泛应用在图像质量评估任务当中:Fang等人[6]首先提出了基于 CNN的 SR图像质量评估网络,Bare等人[7]和 Lin等人[8]分别在 CNN中引入残差连接和注意力机制,并取得了先进的性能。最近,Zhou等人[9]提出了用于SR图像质量评估的QADS数据集,包含用21种SR算法重建的980张SR图像。
本文提出一种基于多任务学习的无参考SR图像质量评估网络,并在其中融合先进的协调注意力模块,在QADS数据集中的结果表明,本文算法的结果与图像主观评分保持了较高的一致性。
1 提出方法
1.1 网络结构
本文提出的网络结构如图1所示。网络的输入是从SR图像中裁剪的大小为32×32的小块,小块首先经过由8个卷积层、3个最大池化层、4个协调注意力模块(Coordinate Attention Block,CAB)组成的特征提取阶段,此阶段输出大小为 256×4×4的特征图张量,然后按通道维度进行全局平均池化、全局最大池化、全局最小池化操作,再在通道维度进行拼接,输出大小为 768×1×1的张量,之后输入到全连接层,进行两个任务的预测。

图1 网络总体结构图
其中,任务2用来预测每个小块的质量分数,是网络的主要任务。在预测一张图像的分数时,用图像裁剪出的所有32×32小块的质量分数的平均值作为整张图像的质量分数。任务1用来预测每个小块的局部频率特征,输出为27维的特征向量,任务1中第一个全连接层会与任务2中的第一个全连接层进行拼接操作。任务1的目的是用图像的局部频域特征来辅助网络进行图像质量分数的预测,实验证明这种多任务学习的方式可以使网络预测的分数有更好的准确性和泛化性。
1.2 局部频率特征
Ma等人[5]预测SR图像质量分数时,将图像分为不重叠的7×7大小的小块,进行离散余弦变换(Discrete Cosine Transform,DCT),并用广义高斯分布(Generalized Gaussian Distribution,GGD)[10]拟合 DCT 系数,最后取所有小块DCT特征的平均值作为图像的局部频率特征。对每个训练图像都计算其局部频率特征当作模型任务1的标签。用GGD拟合DCT系数的过程如式(1)所示:


进一步,将每个小块按图2分为三组,计算每组 的 归 一 化 偏 差(i=1,2,3),然 后 计 算的 方 差 作为DCT块的第三个统计特征。

图2 DCT小块分块示意图
分别在原始训练图像、经σ=0.5的高斯滤波器滤波一次和两次的训练图像中以7×7大小分块提取三种DCT特征,再取所有小块的平均值、前10%平均值、后10%平均值作为最终的局部频率特征,最终的特征为27维的向量。
1.3 协调注意力模块
SE-block[11]、CBAM[12]等注意力模块已经被证明能在图像分类、图像超分辨率等任务中提高网络的性能[13-14]。文献[8]首先将 SE-block模块融合到 SR图像质量评估网络当中。为解决传统的SE-block等注意力模块只考虑图像的通道信息,忽略空间信息、使用全局池化导致丢失过多信息等缺点,文献[15]提出了一种新的协调注意力模块(Coordinate Attention Block,CAB)。本文将协调注意力模块融合到提出的网络中,提高了预测分数的准确率。协调注意力模块如图3所示。
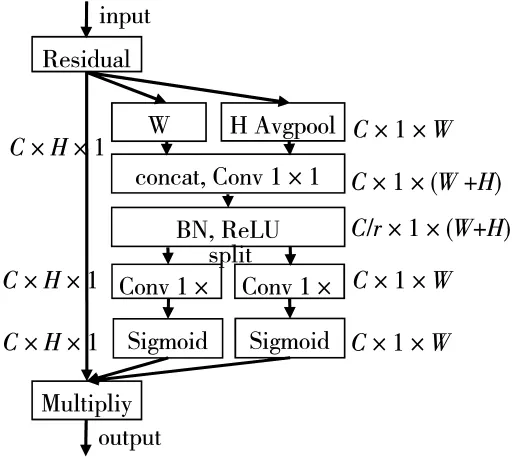
图3 CAB示意图
与传统的SE-block不同,CAB在第一步将二维的全局平均池化操作分解成两个一维的池化操作,生成W、H两个方向上的特征描述符。这样做可以保留特征的空间位置信息,使网络更精确地捕捉感兴趣的目标。高度为h时第c个通道的输出可以用式(2)表示:
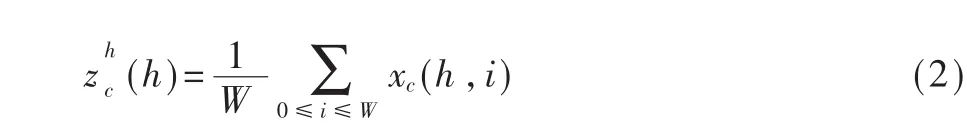
宽度为w时第c个通道的输出可以用式(3)表示:

第二步,CAB将两个方向上的特征描述符连接起来,用收缩率为r的1×1卷积层进行卷积操作,此过程如式(4)所示:

其中,f为包含 W、H两个方向信息的特征图,δ为ReLU函数,F1为 1×1卷积操作。
第三步,将f按空间维度分解成两个特征张量fh和fw,再用两组1×1卷积层对特征图进行卷积,形成W、H两个方向上的注意力权重 gh与 gw,此过程如式(5)、式(6)所示:

其中 Fh与 Fw为 1×1卷积操作,σ为 Sigmoid激活函数。
最后,将W、H两个方向上的注意力权重与CAB的输入进行加权,最终的输出如式(7)所示:
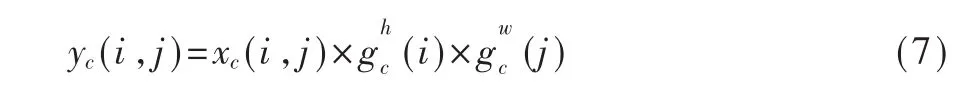
2 实验结果及分析
2.1 数据与实验准备
本次实验采用QADS数据集作为训练和测试数据集。数据集包括20张原始 HR图像,包含 2、3、4三种放大倍数,21种SISR方法重建的980张SR图像和它们的主观质量分数,质量分数区间在[0,1]区间内,分数越高表明图片质量越好。
实验前,先将QADS数据集中的980张SR图像裁剪为不重叠的 32×32小块,再按文献[7]种提出的标签分发方式计算每一个小块的质量分数,计算方式如式(8)所示:

其中Sp为小块的质量分数,Simage为SR图像的质量分数,MSEp为原始HR图像和SR图像在小块的32×32区域上的均方误差,MSEaverage为一张 SR图像所有小块与原始HR图像均方误差的平均值。在数据集中随机选取90%图像作为训练集,10%图像作为测试集,进行10折交叉验证,最后记录所有实验的平均结果。
实验采用Windows 10操作系统,PyTorch 1.7.1深度学习框架,结合并行计算框架CUDA10.1对实验进行加速。采用的硬件设备为运行内存为8 GB的 Intel®Xeon®CPU E5-2678 v3@2.50 GHz处理器,显存为12 GB的NVIDIA Tesla K80显卡。
模型训练时,设置每次迭代的batch size为32,总共迭代 40个 epoch,每迭代 10个 epoch将学习率将为原来的十分之一。模型使用带动量项的SGD作为优化器,初始学习率设置为0.01,momentum参数设置为 0.9,weight_decay参数设置为 0.000 1,为了防止梯度爆炸,将超过0.1的梯度值固定为0.1。
训练时,损失函数使用L1损失,表达式如式(9)所示:
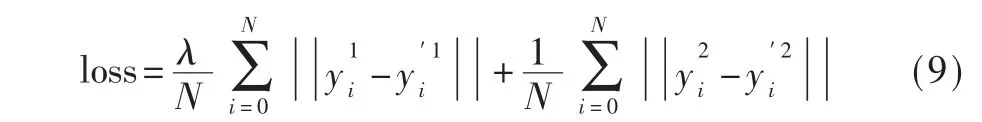
其中 N 为 batch size,y1、y′1分别代表任务 1 的实际值和预测值,y2、y′2分别代表任务 2的实际值和预测值。λ为控制任务1所占权重的超参数。
2.2 对比实验分析
实验选择使用斯皮尔曼等级相关系数(Spearman Rank Order Coefficient,SROCC)、 肯 德 尔 等 级 相 关 系(Kendal Rank Order Coefficient,KROCC)、皮 尔 逊 线 性相关系数(Pearson Linear Correlation Coefficient,PLCC)来评估算法结果与真实标签的一致性,三种系数越大,表明一致性越好。
2.2.1 消融研究
为了研究多任务学习和协调注意力模块对模型性能的影响,采用不含多任务学习与协调注意力模块的模型作为第一种基线模型,在此基础上加入协调注意力模块作为第二种注意力模型,用两种模型与本文提出的模型在相同的训练数据与参数对比下进行实验,结果如表1所示。
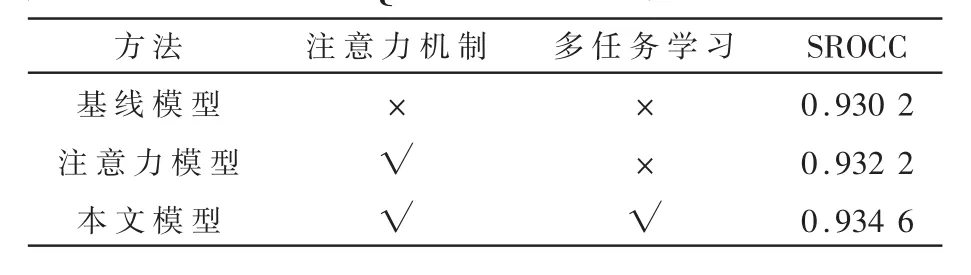
表1 三种模型在QADS数据集中的平均SROCC
结果显示,含有注意力机制和多任务学习的模型效果最好,仅含有注意力机制的模型次之,基线模型效果最差,表明在网络中加入协调注意力模块与多任务学习均可提升模型的预测效果。
2.2.2 值选取
在损失函数中,λ为控制两种任务权重的超参数,λ越大,任务1在模型训练时所占的权重越高。为了选取最佳权重,本文对不同λ值的模型进行对比实验,结果如表2所示。
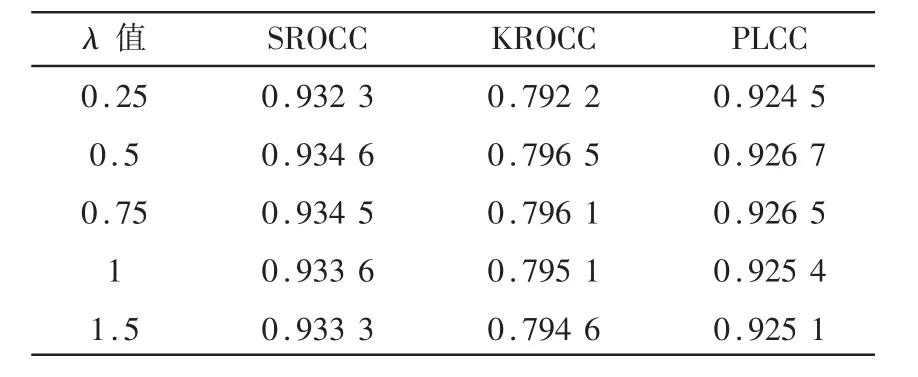
表2 不同λ值的模型在数据集中的各种指标对比
结果显示,λ值取0.5时,模型性能达到了最优。原因可能是当λ值太大时,局部频率特征预测任务所占权重越高,对质量分数预测任务产生不良的影响;当λ值太小时,局部频率特征预测任务对质量分数预测任务的帮助有限。因此本文最终选择的λ值为 0.5。
2.3 与其他算法的对比
本文选取了文献[6]、文献[7]、文献[8]三种目前有先进性能的无参考SR图像质量评估算法作为对比算法,为了保持训练数据和训练环境的一致,按原始论文参数设置在我们的环境中重新训练网络,在10折交叉验证中每折的训练数据是一致的。最终的实验结果如表3所示。

表3 不同方法在数据集中的各种指标对比
结果显示,本文算法在各种指标上的结果都明显超过了对比的三种算法,表明本文算法与人眼主观打分保持了最优的一致性。
3 结论
本文提出了一种基于多任务学习的无参考SR图像质量评估网络,将局部频率特征预测任务融合到模型当中,辅助模型进行图像质量分数的预测,提升模型预测准确率。进一步,本文在模型中加入先进的协调注意力模块,使模型可以更精确地定位到对分数预测影响更大的目标像素。本文对比实验证明了将多任务学习与注意力模块加入到模型当中的有效性,与其他算法的对比结果证明了本文算法与主观打分保持了较高的一致性。下一步的工作目标是发掘更有效的图像特征来进行多任务学习的预测。
