一种基于CEEMDAN-LSTM组合的水体溶解氧预测方法*
2021-08-24黄健明骆德汉
李 港 ,幸 兴 ,黄健明 ,骆德汉
(1.广东工业大学 信息工程学院,广东 广州 510006;2.广东瑞德智能科技股份有限公司,广东 佛山528000;3.广州华匠科技有限公司,广东 佛山 511457)
0 引言
溶解氧(Dissolved Oxygen,DO)在水体中的含量能够反映出水体的污染程度、生物的生长状况,是衡量水质优劣的重要指标之一。而水质的好坏直接影响水生生物的生长及其产品品质。所以,对DO进行精准监测、预测和预防是非常有必要的。水产养殖池塘中的水是一个开放、非线性、动态、复杂的系统,水质很容易受到物理、化学、生物和人类活动等许多因子的影响。所以,运用现代化信息技术寻找适合水质监测和预测的方法变得尤为迫切[1]。
水质参数的预测本质上是时间序列预测问题,目前,国内外已有多种建模方法被用于预测时间序列,并取得了不错的效果。文献[2]设计了一种ARIMA与神经网络相结合的水质参数预测混合模型。文献[3]针对传统溶解氧预测方法预测精度低和鲁棒性差的问题,提出了一种基于改进粒子群算法和最小二乘支持向量回归模型相结合的溶解氧预测模型。文献[4]为了提高水产养殖过程中的溶解氧预测精度,提出了基于PCA和LSTM的水产养殖溶解氧预测模型。文献[5]针对水培养殖系统的溶解氧预测问题,提出了一种基于遗传算法和模糊神经网络的溶解氧预测模型。文献[6]为了提高不同水质参数预测模型的精度和稳定性,同时处理长期依赖问题,提出了一种基于改进的Dempster/Shafer(D-S)证据理论和三种RNN的集成预测方法。
现代智能算法取得了良好预测效果,但溶解氧序列具有非线性和非平稳性的特点,势必会影响上述方法的预测性能,所以对溶解氧序列进行降噪处理十分必要。CEEMDAN分解获得的各IMF(Intrinsic Mode Functions)相对简单且相互独立,为充分提取IMF子序列的波动特征提供了有利条件,进而提升预测建模精度。另一方面,LSTM通过引入门控单元系统,解决了传统RNN模型训练中梯度爆炸和梯度消失问题,在提取序列数据中的长期依赖关系方面极具优势,可利用前期“记忆”为当前决策提供支持,是当前复杂高维时序数据分析中最成功的非线性建模方法之一,也是近年来数据建模领域的研究热点。
本文在CEEMDAN和LSTM的基础上,提出了一种混合模型,该模型首先通过CEEMDAN对溶解氧时间序列进行预处理,然后通过LSTM对其分量进行预测。最后的预测是通过整合各分量预测结果得到的。用所提出的CEEMDAN-LSTM组合预测模型、LSTM模型、ARIMA模型、GRU模型以及 CEEMDAN-GRU组合预测模型在实验数据中进行了预测,实验结果表明,与其他模型相比,本文提出的模型在溶解氧含量预测方面具有很大的优越性。
1 基本理论
1.1 CEEMDAN理论
CEEMDAN的提出,来源于对EMD(经验模态分解)算法的改进。EMD是由美籍华人 Huang[7]提出的一种新型方法,用来处理具有非线性、非平稳特征的信号。它能够较好地对不同尺度下的特征信息进行提取,不再需要提前进行分析和研究,根据信号本身的特征就能进行自适应分解。但EMD分解过程中,会出现干扰最终分解效果的模态(频率)混叠现象。
而 EEMD(总体经验模态分解)算法的出现,通过在分解过程中加入服从正态均匀分布的白噪声,克服了EMD模态混叠的缺陷,保证了分解的有效性[8]。但是在这个过程中引入的噪声在多次平均后仍可能影响到子序列,最后影响预测精度。为了平滑干扰脉冲,CEEMDAN算法引入了自适应白噪声,使得分解过程更加完整有效,也降低了重构误差[9]。具体到本文的溶解氧含量预测问题中,分解步骤如下:
(1)在原始溶解氧序列 Do(t)中添加不同幅值 ∂的白噪声wi(t),得到用来进行分解的信号,可以用式(1)表示:


(3)用式(3)求得第一个剩余分量 r1(t),对于信号r1(t)+α1EMD1(wi(t))利用 EMD算法进行进一步分解,得到第二个IMF分量,如式(4)所示。定义操作符EMDj(·)为经过 EMD分解后的第j个 IMF分量。
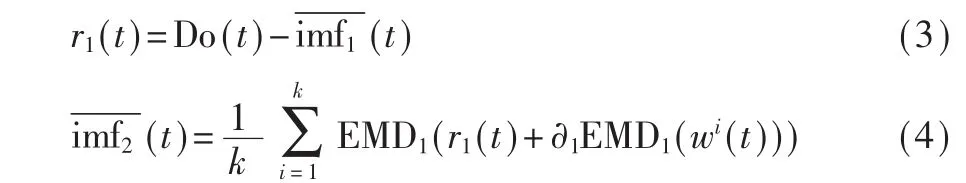


(5)重复步骤(4),直到剩余分量 rk(t)满足以下停止条件:

其中 T为溶解氧序列 Do(t)的长度,阈值 S按照经验设置为0.2[10]。最后得到分解完成的信号,描述为如式(8)所示:

1.2 LSTM预测模型
由于传统RNN存在着梯度消失和爆炸问题,Hochreiter[11]提出了一种递归神经网络(RNNs)的改进形式,很好地解决了这个问题,这就是LSTM(Long Short-Term Memory),非常适合处理和预测长时间序列,其结构如图1所示。

图1 LSTM结构图
LSTM体系结构的巧妙之处就在于通过增加遗忘门、更新门、输入门和输出门,使得自循环的权重是可以变化的;以及增加了一个称为cell的存储器单元,通过对这些门的操作,信息可以存储在单元中、写入单元或从单元中读取。具体计算方程如下:

式中,Wx和 bx,x∈(f,u,i,o) 分别是各自门的权值矩阵和偏置;上一单元的输出yt-1和当前单元的输入xt集中作为LSTM的输入;Ct-1和Ct分别表示先前和当前状态;σ表示sigmoid激活函数,tanh表示hyperbolic tangent激活函数。
2 CEEMDAN-LSTM模型
2.1 组合预测方法框架
以往的研究发现,CEEMDAN方法在时间序列分解方面具有优势,而LSTM方法在长时间序列预测方面具有优势[12]。因此,本文将这两种方法结合起来,提出了一种用于溶解氧时间序列预测的CEEMDAN-LSTM组合方法,包括分解、分量预测和集成3个过程,具体流程图如图2所示。

图2 CEEMDAN-LSTM流程图
在第一阶段,使用CEEMDAN方法将原始溶解氧时间序列分解为n+1个分量,包括n个IMF和一个剩余分量。
在第二阶段,利用长短期记忆(LSTM)建立各分量的预测模型。然后,使用建立的模型对每个分量进行预测,最终得到不同频率分量的预测结果。
在第三阶段,将所有分量的预测结果汇总为最终结果。虽然有许多方法可以聚合所有预测结果,但在本研究中,以相等的权重将所有分量的预测结果相加。
2.2 模型评价指标
本文所述CEEMDAN-LSTM模型的训练和测试,都是在经过预处理之后的溶解氧时间序列中进行的,为了对模型进行更加清晰的评估,选取了一些指标进行评价,分别是均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分误差(MAPE)和拟合优度(R2),计算公式如下:


3 实验及结果分析
3.1 实验准备
3.1.1 数据集
实验数据来源于某河流上的水质实时监测站,采集的数据类型包括耗氧量、氨氮化合物、PH值和溶解氧。监测频率为每天一次,共计3 000天的数据,单位为mg/L,本文用到的只有溶解氧含量这一数据。
观察数据集中的数据发现没有缺省值和零值,所以不需要进行插值处理,在数据预处理过程中主要考虑异常值检测。本文首先对数据进行归一化处理,之 后采用了孤立森 林(Isolation Forest,iForest)算法进行异常值检测[13]。iForest不再基于距离或密度来检测异常,消除了之前的主要计算成本;具有线性时间复杂度、低常数和低内存需求;其扩展能力也使它适用于超大数据量和高维问题。
本文设置异常比例为0.025,最后得到检测结果如图3所示。
从图3中发现总共找出70个异常值,对于这些异常值采用剔除的方式进行处理,处理完的数据规格为 2 930×1。

图3 异常值检测结果图
3.1.2 对比模型
为了验证所提出模型的优越性,除单个LSTM模型外,本文还与以下几种模型及它们与CEEMDAN算法的复合模型进行了对比:
(1)ARIMA模型:ARIMA(自回归移动平均模型)是由Box和Jenkins提出,其使用要求时间序列必须是稳定的,如果不是,则需要将非平稳时间序列通过差分法转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归,建立模型[14]。
(2)GRU模型:和 LSTM 一样,GRU(Gated Recurrent Unit)是传统RNN的变体,但它具有比LSTM更简单的结构,而且更容易计算和训练[15]。不过它们都能有效获取到长序列之间的关联,并缓解传统RNN存在的梯度消失或爆炸问题。
(3)CEEMDAN-GRU模型:为了验证同为RNN变体的GRU和CEEMDAN算法组合的性能,将本文所提出的CEEMDAN-LSTM模型中用到LSTM的部分替换为GRU,就得到了CEEMDAN-GRU模型。
3.1.3 平台和环境参数
本文所使用计算机的配置如下:处理器为Intel Core i5-8265U,CPU频率为1.6 GHz;内存为 8.00 GB;操作系统为Windows 10(64 bit);程序设计语言为Ppython 3.8;集成开发环境为PyCharm Community Edition 2020.2.3。
本文模型仿真在Keras框架的基础上实现。模型训练的过程是使损失函数最小化,因此在定义损失函数后,设置合适的优化器来解决参数优化问题对实验结果非常重要。目前的深度学习库中有许多优化算法可供选择,如随机梯度下降(SGD)、自适应矩估计(Adam)和均方根传递(RMSProp)。理想的优化算法不仅可以利用训练样本尽快得到最优模型,而且可以防止过度拟合。为了选择最佳的优化器,本文进行了对比实验,比较了不同优化器在训练LSTM模型时的均方误差(MSE)损失。通过对比实验发现Adam方法是最好的,Adam作为一种有效的随机优化方法得到了广泛的应用。因此,在训练模型的过程中采用Adam优化算法,可以更快地收敛到好的结果。对于激活函数,由于网络结构不是很复杂,选择默认的tanh作为激活函数。在本研究中,LSTM的输入是 2 484×6×1的数据。
3.2 试验结果分析
3.2.1 仿真分析
首先,对于经过预处理之后的原始溶解氧时间序列 Do(t),用上文所提到的CEEMDAN方法进行分解。如图4所示,是溶解氧时间序列经过CEEMDAN分解后的IMF和剩余分量。

图4 CEEMDAN分解结果
图4中第一行所示即为数据集原始溶解氧时间序列Do(t),具有高度的非线性和非平稳性;其下方的IMF0~IMF6为7个IMF分量,波动频率逐渐降低;最下面的r为剩余分量。
分别对所得分量建立LSTM预测模型。对于每个分量,取前85%的数据作为训练集,后15%的数据作为测试集,数据规格分别为2 490×1和 440×1。对于划分好的数据集,根据所构建的网络模型结构进行数据重构,本文设置回望窗口为6,即以前6个数据预测第6+1个数据,重构完的训练集输入和输出规格分别为2 484×6×1和 2 484×1, 测试集输入和输出规格分别为 434×6×1和 434×1。模型在训练集上进行训练,完成之后保存模型并在测试集上进行检测。
由此,得到了各分量预测结果。接下来,对所有预测结果进行叠加求和,就得到原始变量的最终预测结果。
溶解氧时间序列在CEEMDAN-LSTM模型的预测下,得到的最终预测结果如图5所示。图中实线是真实数据,虚线是模型的预测数据。

图5 CEEMDAN-LSTM模型预测结果
根据模型评价指标,所提出的CEEMDAN-LSTM模型的均方根误差(RMSE)为 0.024 5,平均绝对误差(MAE)为 0.016 6,平均绝对百分误差(MAPE)为0.065 2,拟合优度(R2)为 0.985 6。不管是从图像上还是从数据上,都可以看出模型很好地预测了数据的走向,使用CEEMDAN-LSTM预测模型可以很好地利用前期输入的数据预测之后一段时间的数据。
3.2.2 模型对比分析
为了研究该方法的性能,本文和其他方法进行了对比,预测结果曲线对比如图6所示。此外,还对各预测模型的预测值和真实值进行了严格的定量分析,具体统计结果如表1所示。
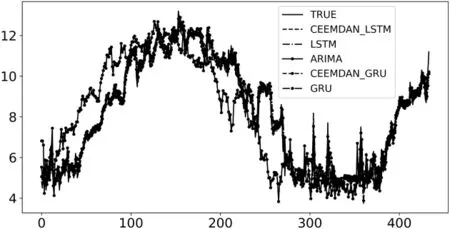
图6 各模型预测结果对比图

表1 各模型评价指标对比
从图6可以看出,ARIMA模型可以预测出数据走向,但是存在很大的时差,其余模型都有较好的预测效果,但是在图中无法肉眼辨别优劣,所以结合表1中的模型评价参数进行比较。其中,从RMSE、MAE和MAPE这三个评价指标来看,其数值越接近于0,效果越好。另外,根据评价指标 R2来看,其数值越接近于1,则模型效果越好。综合上述四个评价指标考虑,可以得出结论,本文提出的CEEMDAN-LSTM模型在水体溶解氧含量预测问题上具有更好的表现。
4 结论
为了提高水体溶解氧时间序列的预测性能,提出了一种CEEMDAN和LSTM相结合的混合预测模型CEEMDAN-LSTM。该方法利用CEEMDAN将一个复杂的溶解氧时间序列分解为多个分量,然后利用基于LSTM的预测模型分别对每个分量进行预测,最终的预测结果由各分量的预测结果以相等的权值累加得到。实验结果表明,该组合模型的预测效果优于本文所对比的其他预测模型,“分解与集成”框架可以显著提高溶解氧时间序列预测的性能。CEEMDAN参数的选择对预测结果有显著影响,因此,如何在时间序列分解过程中有效地选择合理的参数,将是今后研究的重点。
