基于深度网络的推荐系统偏置项改良研究
2021-08-24张天蔚
张天蔚
(山东省计算中心(国家超级计算济南中心),山东 济南 250014)
0 引言
随着互联网的迅猛发展,用户想要从海量的信息中获取自己真正感兴趣的内容已经变成了一件颇有挑战性的工作。解决这种“信息过载”问题的常用技术之一就是推荐系统[1-2]。推荐系统往往利用用户对于项目的历史交互数据信息(如评分、评论、历史购买记录等)[3]建立模型来挖掘用户与项目之间的隐性关联[4-5],从而得以为用户推荐与其喜好的历史交互项目高度相似的新项目,帮助用户筛选出其需要的信息[6-7]。
协 同 过 滤(Collaborative Filtering,CF)算 法[8]是 推荐系统中最为主流和使用最为广泛的算法之一[9]。而对于推荐系统而言,按照其最终进行推荐的方式又可以将推荐算法分为两类:评分预测推荐算法[10]与排序推荐算法[11]。作为基于历史交互项的协同过滤评分预测推荐算法的代表,矩阵分解(Matrix Factorization,MF)算法[12]将用户和项目分别抽象为向量映射到更高维度的隐空间中[13],并在最终评分预测计算环节引入偏置项来表征用户的打分习惯和项目给大众的整体印象,将偏置项合并入最终的评分预测计算中,从而提高预测的性能[14]。然而,这种针对用户和项目分别独立设置的偏置项忽视了用户与项目之间的相关性,不能准确地表征用户对于某一类项目的个人偏好,而这种偏好很可能是优先于用户日常的打分习惯的,因而影响了推荐的精确度和泛用性。
神经协同过滤(Neural Collaborative Filtering,NCF)算法[15]是协同过滤排序推荐算法的代表作之一。与评分预测推荐算法不同的是,排序推荐中,用户对于项目打分的高低不再具有实际意义,而是将用户所有产生过交互(如打分、点评等)的项目都视为该用户的“正例项目”,反之,将该用户从未产生过交互的项目都视为该用户的“负例项目”。相应地,推荐任务也改变为基于用户与其所有“正例项目”的历史交互,从用户的“负例项目”中挖掘出用户最为感兴趣的那些,并将该用户所有“负例项目”进行排序,排名靠前的项目则被认作是最值得推荐给用户的。然而在这个过程中,由于算法将无论高分评价或是低分评价的项目都同等地视为产生过交互的正例,这在一定程度上导致了推荐的不合理性。
基于对上述两个方面的观察,本文进行了基于深度网络的推荐系统偏置项改良研究。改良思路为:联合用户与其交互项目各自的特征,利用深度网络学习用户-项目关联偏置项,该偏置项可以有效表示用户对于项目的偏好;同时在学习过程中,为用户打出高分的交互项赋予权重上的增益,反之,对于那些用户打出低分的交互项则赋予权重减益。在3个真实数据集上进行了对比实验,实验结果表明,与原始的MF及NCF算法相比,该改良方案有效地提升了推荐效果。另外,为了验证该改良方案的泛用性,将对比实验的范围扩展到了另一个经典的排序推荐算法:贝叶斯个性化排序(Bayesian Personalized Ranking,BPR)[16]中,实验结果表明,与原始BPR算法相比,改良后的算法同样获得了明显的推荐性能提升。
1 相关工作
1.1 矩阵分解算法及其偏置项相关讨论
矩阵分解算法的核心思想在于,将可以唯一代表某一用户的特征(例如其在数据集中的ID编号)和可以唯一代表某一项目的特征分别抽象成两个高维度的特征向量 pu,qi∈Rd,其中 d在训练中作为一个超参数,代表向量的维度。将此两向量进行点乘后所得的标量值作为预测评分的基数值,与此同时,在评分预测过程中引入了3个偏置项来提升预测的准确性。矩阵分解算法的评分预测过程可表示为如下公式:

但是这种将用户偏置项和物品偏置项独立开来分别计算的方式仅能表示用户或项目自身的特征,而忽略了二者之间的关联性,而这在实际场景中不足以全面涵盖各种情况。例如,某男性用户在给电影打分时往往非常苛刻(即其个人用户偏置应在评分预测过程中被设置为减益项),但是却可能因为特别偏爱某部电影的主演而给该电影打出高分。在这个过程中,该电影主演构成了影响用户对项目(电影)打分的隐性关联因素,而这个关联因素是无法被用户/项目各自独立设置的偏置项所学习到的。因此,本文将矩阵分解算法中偏置项的学习方式改良为:联合用户与项目,深入挖掘二者之间的隐性关联因素,为每一个用户-项目对学习出一个关联偏置项,用于表征特定用户在面对特定项目时的个人偏好。
1.2 神经协同过滤算法及其数据设置相关讨论
与矩阵分解算法不同的是,神经协同过滤算法实现的是推荐系统中的排序推荐。正如前文所述,神经协同过滤算法在数据设置过程中不再关注用户为项目具体打出了多少分,而是将用户所有打分过的项目(无论给出了高分或低分)都视为该用户的正例项目,并由此学习用户的偏好特征。本文认为这样的处理思路在实际应用中有不合理之处,理由在于,用户给某项目打出低分(即差评),意味着用户不喜欢该项目,且大多数情况下不愿在今后再次购买该项目。然而按照神经协同过滤的数据设置方式,那些被用户打出低分的项目也会被同等地视为该用户的正例,并以之为基础挖掘用户的偏好,这将导致训练完成后的系统继续为用户推荐与这些低分项目高度相近的其他项目,而这种情况对于该用户而言毫无疑问是不合理的。
针对上述问题,一个简单有效的解决思路是,为用户给出的评分赋予实际意义,并据此设置预测过程中的偏好增益或减益。
2 基于深度网络的推荐系统偏置项改良
基于对前文所述两个相关工作及其相关可改进之处的思考,本文提出了基于深度网络的推荐系统偏置项改良方案,该方案致力于同时解决上述两个问题,提高推荐性能,并且对于评分预测推荐系统和排序预测推荐系统都适用。该改良方案如下:
依据数据集中评分(1~5分),将所有评分分为三个代表用户对项目喜好程度的类:(1)4~5分:好评类,表示用户喜爱该项目,用标签“1”代表;(2)3分:中评类,表示用户对于该项目持中立态度,没有特别明显的喜爱或厌恶情绪,用标签“0”代表;(3)1~2分:差评类,表示用户厌恶该项目,用标签“-1”代表。由此,将数据集中的评分作为了额外信息输入到推荐系统中参与学习。这里本文将此步骤设计为一个机器学习中的多分类问题,分类数为3。设置一个多层感知机(Multi-Layer Perception,MLP)来拟合这个三分类学习,并选用交叉熵(Cross-entropy cost function)作为该多分类问题学习过程中的损失函数:

本方案将用户和项目各自的向量特征(也即公式(1)中的pu,qi)融合为一个联合特征向量,将该联合特征作为输入,输入到上述MLP中进行三分类学习。同时,该联合特征向量将在接下来的评分预测或排序推荐任务的最终输出环节充当该用户-项目对的联合偏置。对于矩阵分解算法,用联合偏置代替其评分预测过程中的用户偏置与项目偏置两项(保留“平均偏差”项)。对于神经协同过滤算法而言,由于其算法本身没有考虑加入偏置项,则可以直接将该联合偏置加入到算法最终的排序评分计算环节中。
本文以基于矩阵分解算法的偏置项改良推荐系统模型为例,完整地阐述进行偏置项改良后的推荐系统运行流程。图1展示了基于矩阵分解算法的偏置项改良推荐系统模型图。

图1 基于矩阵分解算法的偏置项改良推荐系统模型图
其中分类损失(Loss of Classification)即为公式(2)所确定的 Lc,而回归损失(Loss of Regression)选用评分预测问题中最为常用的均方误差(Mean Square Error,MSE)函数:

本方案将整个模型设计为端到端(End-to-End)结构,这意味着可以在输出及误差反向传播环节统一地学习分类损失和回归损失。这里将整个模型最终的整体损失函数设计为:

其中,γ为系数,可以作为端到端模型的一个超参数,在训练过程中动态地调节分类损失在学习中所占的比重。以上即为本文设计的基于深度网络的推荐系统偏置项改良方案,上文中提到的神经协同过滤算法(NCF)可以同理地施加此改良方案。为了验证该方案的泛用性,本文在另一个推荐领域经典排序推荐算法——贝叶斯个性化排序(BPR)上也同样施加了此方案,并进行了对比实验。三组原始算法与其改良模型的实验结果对比与分析见下节。
3 实验及分析
3.1 实验运行环境
由于所设计改良方案应用了深度学习,为了更高效地运行包含深度神经网络的模型,本文选择使用GPU+CUDA的环境来进行实验。本实验运行环境如下:
操作系统:Windows 10 ver1909;
CPU:Intel® CoreTMi5-7300HQ CPU;
GPU:NVIDIA GeForce GTX 1050 Ti;
GPU显存:4 GB;
CUDA 版本:10.1。
3.2 数据集
在3个推荐领域公开数据集上进行了对比实验,其中两个来自于 MovieLens,分别为 ml-latest-small和ml-1m;另外一个数据集来自于亚马逊电商网站,为Amazon Home and Kitchen。此三个数据集的体量大小(按所含的交互行数计算)涵盖了 10万、50万和100万三个数量级,具体地,各数据集属性如表1所示。

表1 所选数据集属性展示
3.3 实验评价指标
对于矩阵分解算法(MF),由于其是一个评分预测推荐算法,属于回归问题,故本文在设计评价指标时选用了均方误差(MSE)值直接作为其评价指标,经过改良后的模型运行所得结果同样由均方误差值来进行衡量。对于神经协同过滤算法(NCF)及贝叶斯个性化排序算法(BPR),由于它们均为排序推荐算法,故本文选用了排序推荐常用的评价指标:归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)和召回率(Recall)作为评价模型性能的标准。此两个指标在计算时需提前设置统计截断位置,例如,设置截断于前 10位(用 @10表示),则表示将验证时所排好名次的所有物品取前10个参与评估。为了更好地验证改良效果,本文在实验时将截断位置设置为@50,以验证模型是否能在前50位这个较大的排序范围内获得性能提升。
3.4 实验结果及分析
3.4.1 矩阵分解算法的改良效果
表2展示了矩阵分解算法的改良效果,表中数字均为均方误差值,值越低者代表误差越小,也即性能越优良。

表2 矩阵分解算法的改良效果
可见,经过改良后的矩阵分解算法,其均方误差值在三个测试数据集上均显著降低,也即获得了明显的性能提升。
3.4.2 神经协同过滤算法的改良效果
表3展示了神经协同过滤算法的改良效果。如前文所述,本文设置了截断位为@50以评估其作为一个排序推荐算法性能是否获得提升。表格中数据内容如其对应列名所示(NDCG、Recall),此两个评价指标均为百分比(以三位小数表示),值越大则表示占比越多的正例得到了推荐,也即性能越优良。
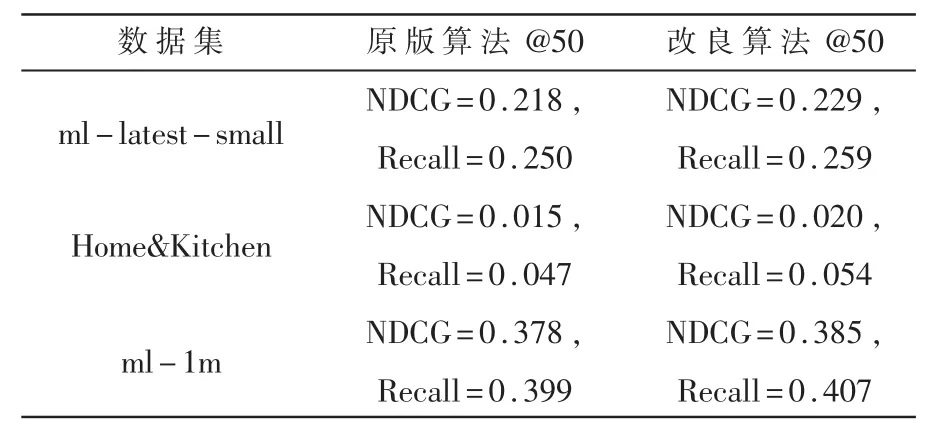
表3 神经协同过滤算法的改良效果
可见,经改良后的神经协同过滤算法在三个测试数据集上都获得了较为明显的性能提升。
3.4.3 贝叶斯个性化排序算法的改良效果
为了验证本文所述改良方案的泛化性,本文在贝叶斯个性化排序算法上进行了拓展实验。由于其与神经协同过滤算法均属于排序预测算法,故其评价指标设计与神经协同过滤相同,在此不再赘述。对于BPR算法,同样设置截断于@50来验证其性能是否获得了提升,结果如表4所示。
由表4结果可见,改良后的BPR算法同样获得了较为明显的性能提升,这表明了该改良方案可被应用于MF、NCF以外的其他推荐算法当中,具有不错的泛化能力。

表4 贝叶斯个性化排序算法的改良效果
4 结论
本文提出了一种基于深度网络的推荐系统改良方案,该方案从用户为项目做出的评分挖掘用户对该物品的态度,并将原本用户与项目之间彼此独立的偏置项改良为一个联合偏置,在评分预测问题和排序推荐问题上都有效地提升了推荐性能。
