知识图谱技术综述及在粮虫领域的应用
2021-08-24段梦诗
段梦诗,肖 乐
(河南工业大学信息科学与工程学院,河南郑州 450000)
0 引言
21 世纪人工智能经历了从知识到大数据的过渡,符号主义的人工智能强调知识对智能的作用,但因需要大量的语料库和规则库,一般只适用于专用领域而不适用于智能系统。机器学习、深度学习算法的兴起和发展能够更准确、深入地挖掘出数据背后的新知识,但也因为深度学习只能提取潜在特征,抽取不到语义特征,所以要将符号主义与联结主义相结合,即再次将知识与数据联结,知识图谱就是其中的一个重要表现。
知识图谱由许多大规模的语义网络组成[1]。相较于20 世纪七八十年代传统的语义网络,知识图谱更能适应互联网大数据时代应用需求,能够自动获取、构建大规模高质量的知识库。具体来说,知识图谱是用结构化的形式将客观世界中的实体、概念及其语义关系以图的形式呈现出来,使人们更加快速、准确地获得所需信息,这也是机器理解自然语言的关键一步[2]。
目前知识图谱在计算机视觉、语音处理和自然语言处理等领域产生了巨大的应用价值,在金融、医疗健康、教育、生物等领域有了巨大成就,然而知识图谱在农业上的应用却很少。根据联合国粮农组织2020 年的一项调查,预测由新冠肺炎(COVID-19)导致的经济萎缩将使全球饥饿人数增加8 300 万,甚至达到1.32 亿,若疫情得不到很好控制则会极大影响粮食生产,进而加剧全球粮食系统的脆弱性和供给不足。本文基于粮虫知识图谱构建应用系统,介绍了BiLSTM-CRF(Bi-directional Long Short-Term Memory,Conditional Random Fields)模型的实体命名抽取,并基于知识图谱的智能问答进行初步实现。该系统能够加强人们对农作物病虫害了解进而增加农作物生产,也可查询某种粮食或粮虫特征,为所需人员提供智能问答服务,在一定程度上缓解粮食存储压力,为可持续发展提供保障。
1 知识图谱构建过程
知识图谱构建是一个系统工程。首先对获取的数据进行三元组抽取,并对抽取的知识进行融合、加工、推理,实现自底向上的知识库构建,最终实现知识图谱与其他领域应用结合。知识图谱构建架构如图1 所示。
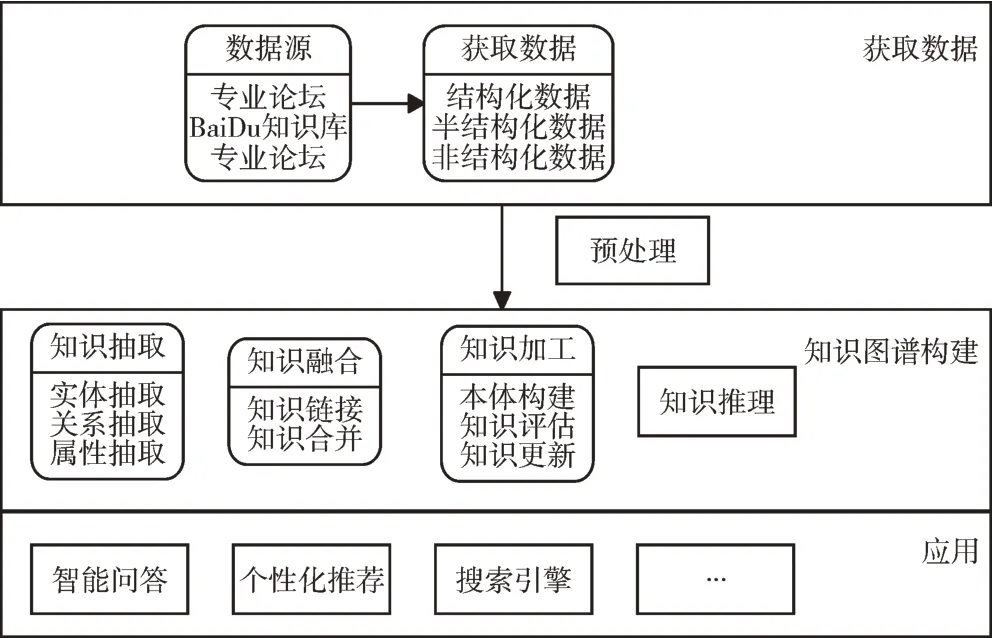
Fig.1 Knowledge map construction architecture图1 知识图谱构建架构
1.1 知识抽取
知识抽取是从非结构化和(半)结构化数据中获取实体、概念及其之间的语义关系[3],将其形成结构化格式,并按一定规则加入到知识图谱中。知识抽取是知识图谱最基本也是最重要的技术,抽取的正确率和完整度直接影响知识图谱的质量。知识抽取的关键技术分为实体抽取、关系抽取和属性抽取。
1.1.1 实体抽取
早在1991 年的顶级IEEE 会议上,人们就提出了基于规则和词典的实体抽取方法,如Rau 等[4]首次采用手工编写规则和启发式算法提取公司名称,Rujun 等[5]使用计算机自动识别实体并构建词典,然而固定规则模板表现出成本太高和耗时过长的缺点。为了寻找更好的特征表示方法,提高模型计算效率,研究者在2003 年的CoNNLL 会议上提出了统计机器学习的抽取方法,CRF[6]、SVM[7](Sup⁃port Vector Machine,支持向量机)等机器模型的出现使提取精度达到了95.0%以上,双向LSTM 和注意力机制模型的多种特征结合使词性也作为抽取的关键特征[8],中文实体抽取效果显著提升。随着深度学习的发展,Zhao 等[9]利用LSTM(Long Short-Term Memory,长短期记忆网络)得到上下文信息的输入信息,CRF 得到输出有关联的标注序列,有效使用过去和未来的标注来预测当前的标注;Ma 等[10]提出的Bi-LSTM+CRF+CNN 端到端的深度学习模型适合各种序列标注任务,解决了以前手工提取特征和数据预处理难题。
各种实体抽取模型比较如表1 所示。

Table 1 Comparison of entity extraction models表1 实体抽取模型比较
1.1.2 关系抽取和属性抽取
经过实体抽取之后得到的是一个个零碎结点,为了得到易于人们理解的自然语言,还需要一条线将这些节点关联起来,因此需要对文本语料进行关系抽取,形成所需的关系网络。属性抽取即抽取实体的属性,可看作属性与属性值或实体与属性值之间的一种关系,进而将属性抽取问题看作关系抽取问题。
早期采用人工构造规则和模板的关系抽取方法,主要用语言学知识对输入的种子进行分析并推理归纳出结果,但模板的编写工作量巨大且要求较高,人们通过选取特征向量选择适合的分类器进行类别判断。Gao 等[11]利用深层句法分析特征对中文维基百科构建关系推理模型;Gan等[12]在句法特征基础上结合词法特征、语义特征等关系特征,使准确率、F 值相比于传统的特征提取分别提高2.21%和4.98%,在抽取性能上有了明显提升。
基于监督学习的关系抽取技术不仅包括基于特征抽取还包括基于核函数抽取,Guo 等[13]将径向基核函数、卷积树核函数、多项式核函数等多核融合方式对中文文本进行关系抽取。监督学习虽然提高了抽取准确率,但需要大量的标注信息,而无监督学习很好地解决了这一问题。Liu等[14]首次使用距离和位置限制获取大量三元组,平均准确率为80.0%以上;Lin 等[15]提出在关系语句方面引入注意力机制,防止传播错误标签的语义信息进而提升学习效率。但无标签标注导致其模型的准确率、召回率、F 值都较低,需要对其结果进行分析和处理才能得到可靠的结果,所以该技术还不是很成熟。
半监督学习很好地将这两种方法进行结合,主要思想是使用少量标记数据并使用大量未标记数据。余丽等[16]通过Bootstrspping 自动挖掘词语特征和位置特征,召回率提高了23.0%;Qin 等[17]通过评估模型和实例使实验测试精确率达到了97%。半监督学习不仅降低了人工标记成本,还提高了数据的准确性,适用领域更广。
传统的机器学习算法在实体关系抽取过程中存在误差传播和标签错误等问题,随着深度学习的发展,深度学习和关系抽取相融合,模型有递归神经网络RNN[18-19]、CNN[20-21]、LSTM[22-23],之后利用这些模型与注意力机制[24]、图神经网络(GraphConvolutionalNetworks,GCN)等相结合。Fu 等[25]通过GCN 解决关系重叠问题和实体重叠问题,加强了实体之间的关联强度,其召回率、准确率、F值最佳情况下为60.0%,63.9%,61.9%;Zhang 等[26]结合双向LSTM和GCN 剪枝依存解析树获得向量组合来进行关系抽取。
每种抽取方法各有优缺点,从每个方法的分类出发对实体抽取模型进行比较,如表2 所示。
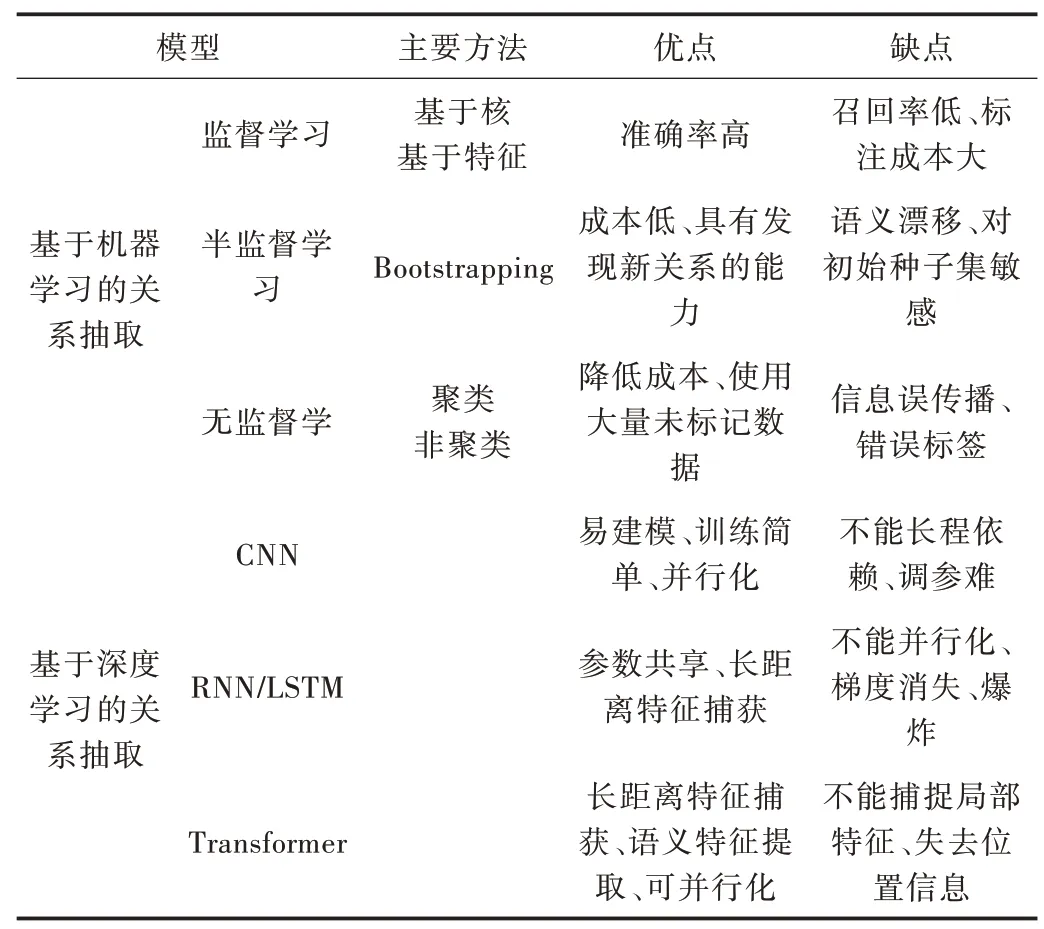
Table 2 Comparison of relation extraction models表2 关系抽取模型比较情况
1.2 知识融合
由于抽取的知识来源广泛,常常会出现来自不同数据源的知识重复、关联不明确、异构、噪音、不确定等特征,因此必须对知识进行融合。曾键荣等[27]采用近邻传播聚类算法构建多特征融合表示模型解决同名专家消歧;Li 等[28]利用LSTM 自动学习所有类型共指的全局表示;对于出现的一词多义现象,Geng 等[29]通过引入权重和相似度将数据处理为键值数据对形式,满足大数据环境下对实体需求的指代消解。
1.3 知识加工
抽取的知识要素经过实体链接之后还需进行加工处理才得到高质量数据。Pisarev 等[30]在叙词表基础上抽取并添加所需的本体,自动构建教育领域的动态本体;郑姝雅等[31]综合机器学习、自然语言处理等技术,从非结构化的用户生成文本内容中自动构建组织语义丰富的动态本体。信息和知识会随着科技的发展不断增长,人们的需求也会增多,而只有不断地对知识库进行更新才能顺应时代要求。
1.4 知识推理
知识推理通过计算机推理知识库中加工完成好的实体、属性和关系等要素,增加对隐含知识的挖掘。当实体关系比较复杂时,知识推理可以补充知识图谱内容,或进行完善、校验。如实体推理对于三元组(A,father,B)和(B,father,C),可以推出(A,grandfather,C),典型的推理模型如PTrans[32]、RTrans[33]以及RPE[34]模型都极大地提高了知识推理结果。Bellomarini 等[35]采用多种启发式方法达到解决递归和存在量化的终止问题,提供了一种大型知识图的自动化推理体系结构;陈海旭等[36]引用概率学提出了PSTransE 算法,使知识图谱的嵌入与路径知识推理结合,考虑了关键路径对推理结果的影响。随着图神经网络的出现,人们使用生成图神经网络(GP-GNN)对非结构化文本进行关系推理从而获得更准确的关系[37]。
以上对知识图谱技术中知识抽取、知识融合、知识推理进行了理论阐述,宏观知识的最终目标是应用于市场开发。国外常见的互联网知识图谱主要有FreeBase、DBpe⁃dia、BableNet、Schema、Wikidata 等,国内著名的中文知识图谱有OpenKG、CN-DBpedia 等。将这些知识图谱应用于实际项目,如谷歌、阿里电商等类似的人工智能搜索公司,实现智能语义搜索、个性化推荐、决策支持等功能。在金融、制造业、传媒、医疗等领域,知识图谱也是一个热门的工具,然而国内还没有公布有关农业专业领域知识图谱。本文以粮虫知识图谱课题为例,介绍了基于BiLSTM-CRF 模型的实体抽取,在粮食害虫知识图谱基础上初步实现智能问答,以案例形式对知识图谱的构建及应用进行阐述。
2 知识图谱在粮虫领域应用
知识图谱结合机器学习或深度学习算法能迅速组织和处理海量信息,从而实现智能搜索、问答、决策支持等智能粮虫应用。将知识图谱与粮虫信息结合构建粮虫信息图数据库,将粮虫信息文本数据先存储到关系型数据库中,再以半自动化的方式提取出三元组并将其存入图数据库。粮虫信息图数据库的构建为粮虫信息深层次的知识发现和数据挖掘研究、粮虫信息查询云平台提供了基础数据支持。
2.1 数据获取
针对百度百科等网页格式统一的网页,使用Python 编写爬虫获取该网页的html 源码,再使用BeautifulSoup 解析html 源码获取对应的数据,存入数据库。从各种输入数据中将数据提取为预定义形式,数据提取的输入输出定义如下,输入:从Internet 下载或抓取数据;输出:按照每个粮虫使用如下分类:英文名、危害方式、地区、形态特征分类、粮虫特征、生活习性、生活习性分类、粮种、粮虫、粮虫分类、粮虫识别、粮虫识别分类、经济意义、防治要点,进行分类并存储到关系型数据库中。
2.2 实体抽取
采用BiLSTM-CRF 网络模型进行实体抽取,使用BiL⁃STM 解决序列标注问题,但这都只考虑了序列输入的单词信息,没有考虑输出标签,而标签转移对提取序列标注问题至关重要。所以在BiLSTM 基础上引入CRF,有效利用句子级别的标注信息。CRF 的优点是能对隐含状态建模,学习状态序列特征,缺点是需手动提取序列特征。本系统采用BiLSTM 与CRF 结合,在BiLSTM 后边加一层CRF 以获得两者的优点。BiLSTM-CRF 模型不是输出独立的标签,而是输出有语义关联的标签序列。实体抽取模型如图2所示。

Fig.2 Entity extraction process图2 实体抽取流程
本实验采用5 种模型的标注方法对抽取的每个实体进行标注,B1-P 表示病虫害名首字,B2-P 表示病虫害名的第二个字,M-P 表示病虫害名的第三个字(非尾字),E 表示病虫害名的尾字,O 表示其他;以此类推,B1-G 表示病虫害名的第二个字,E-G 表示病虫害名的尾字。
对于抽取后的实体进行模型训练,只需表示出损失函数即可,采用负对数似然函数作为损失函数,公式如下:

y 为x 对应的真实标签数据。模型训练完成之后寻找最优路径即得分最高路径。模型准确率比较见表3。
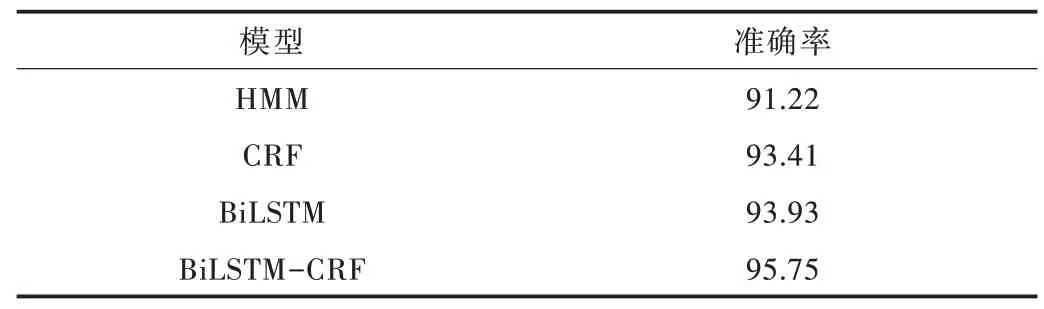
Table 3 Model Accuracy (%)表3 模型准确率 (%)
实验结果显示,基于BiLSTM-CRF 模型实体抽取准确率高于HMM 等模型。
2.3 可视化展示
首先通过命名体识别抽取出实体,之后采用远程监督的Bootstrapping 方法对关系进行抽取,使种子集合不断迭代找出三元组。在可视化图中点击任意一个实体可动态显示其三元组信息。本文一共提取3 250 个实体、4 467 个三元组。
在系统粮虫查询中输入实体“豌豆象”,将会把豌豆象的所属类别、虫种分布、危害物种等相关信息以图谱的方式呈现。实体查询结果如图3 所示。
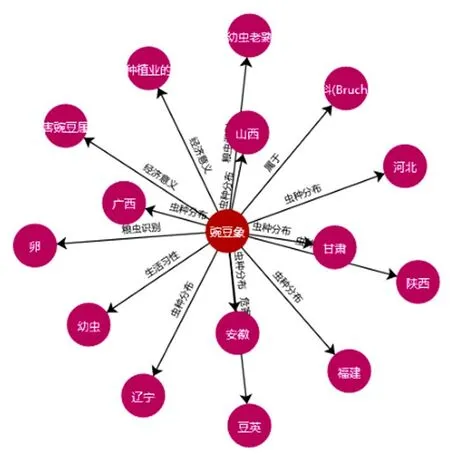
Fig.3 Entity query图3 实体查询
在关系查询中,输入“麦蛾”和“玉米象”两个实体,可将两个实体之间的关系都连接起来,关系查询结果如图4所示。

Fig.4 Relational query图4 关系查询
输入大谷盗并选择关系类别“危害粮种”,关系查询结果如图5 所示。
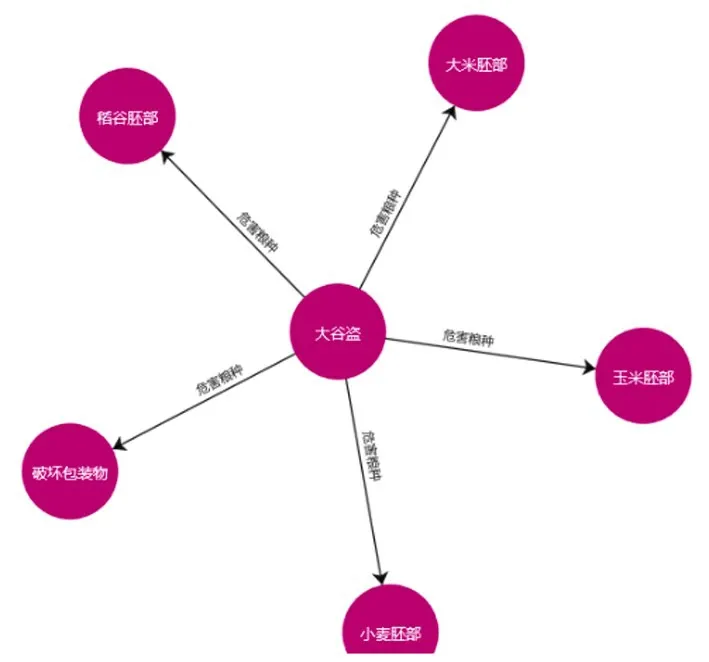
Fig.5 Relational query图5 关系查询
2.4 智能问答
基于知识图谱的自动问答可深层理解用户的语义信息和检索内容,将其映射到粮虫知识图谱的数据层,将搜索到的实体、属性或语义关系以知识图的方式呈现出来。即从知识图中找到一个或多个对应的答案实体,以描述客观事实问题。对于仅包含简单语义的问题,自动回答问题的过程等同于将问题转换为知识库中的事实三元组,以便加快用户搜索速度和提高查询准确率,如智能搜索“危害小麦的粮虫有什么”,将以动态图显示粮虫的类别。智能问答结果如图6 所示。

Fig.6 Intelligent Q&A图6 智能问答
2.5 小结
在大数据环境下基于知识图谱的应用越来越多,但是对于粮虫图谱的学术研究成果较少且不深入。后续目标要实现图谱的私人定制及图谱社区,为推动粮虫图谱应用打下基础。用户登录后输入希望图谱化展示数据或上传相关文件,系统根据数据自动构建图谱。图谱社区的目标主要是用户向系统公开自己的私人图谱,其他用户可对公开的图谱进行查询等操作,实现知识共享。目前,虽然出现了实体关系联合抽取方法,但准确率很低,所以主要困难仍是如何有效抽取出各种文本的高质量三元组。
3 结语与展望
知识图谱与自然语言处理在各个领域不断结合,不仅加快了用户的搜索时间,还提高了用户的体验感与系统的可解释性。本文构建了粮虫知识图谱,首先对获取的数据进行预处理,并对处理的数据进行实体、关系抽取;通过知识融合对抽取后的数据进行实体链接与合并。本文对粮虫知识图谱进行评估,对粮虫图谱应用进行了可视化展示。
基于粮虫构建知识图谱,通过查阅大量文献提出以下问题与研究方向:
(1)从Wikipedia 等大数据库中获取的数据,不仅来源于结构化数据,更多来源于半结构化和非结构化数据。同时,随着科技的发展,人们需求逐渐增多,产生的数据也会越来越多,如何准确智能地提高知识抽取效率并挖掘高质量的知识是未来研究方向。
(2)在远距离监督关系抽取中会产生信息误传播。为了减少错误标签,需不断改进相关算法,提出图结构或注意力机制模型,避免数据不平衡,但需要不断提高算法性能。
(3)在不同数据源中抽取“脏”数据或冗余数据时,有时为了保证融合的质量,融合效率可能不高,如何获得高质量的数据是未来研究趋势。
(4)目前大多数知识图谱只适用于特定领域,虽然已有基于开放领域的知识抽取,但与原有领域的专业化图谱比较还有很大区别,较差的移植性导致知识图谱构建平台的通用性很难实现。
(5)知识图谱未来的发展正如一个公式表示的:NLP+KG=NLU,自然语言处理将通过知识图谱终将走向自然语言理解。
