计算存储分离云原生关系型数据库技术进展
2021-08-24叶志伟蔡敦波
叶志伟,蔡敦波,钱 岭
(中移(苏州)软件技术有限公司 创新中心,江苏 苏州 215153)
0 引言
云计算是信息技术与服务模式的一次重要变革,用户可按需按量使用云服务提供商提供的基于计算、存储与网络资源池的基础设施即服务(Infrastructure-as-a-Service,IaaS)、平台即服务(Platform-as-a-Service,PaaS)和软件即服务(Software-as-a-Service,SaaS)。随着云计算技术的大规模应用,越来越多用户感受到云服务模式带来的便利,因而纷纷将信息系统建设到云上以支撑业务的快速推进。数据库作为信息系统的核心组件,通常需要用户投入专业的运维团队进行维护。Lehner 等[1]提出的数据库即服务(DataBase-as-a-Service,DBaaS)方法能解决用户在使用SaaS 时面临的数据库管理问题。云服务提供商为了让用户更方便地使用数据库,提供了数据库即服务。Gartner 在研究报告中预测,到2022 年将有75%的数据库被部署或迁移到云平台上,云是数据库市场的未来[2]。
根据中国信通院与大数据技术标准推进委员会[3]的研究,云服务商提供DBaaS 通常采用两种技术方式:一是借助虚拟化技术,在硬件资源池服务器中部署传统数据库实例,以镜像形式为用户提供数据库服务;二是在虚拟化技术基础上,利用计算存储分离的数据库架构优势,提供具有更好弹性及高可用的数据库服务。根据云原生计算基金会(Cloud Native Computing Foundation,CNCF)[4]的定义,云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建与运行可弹性扩展的应用。因此,以方式二提供DBaaS 服务的技术符合云原生技术理念,被称为云原生数据库技术。
本文对计算存储分离的云原生数据库技术的不同架构特点展开深入分析,介绍了不同架构的设计方法,旨在为设计者和开发者提供参考。
1 云上传统数据库面临的问题
传统数据库借助虚拟化技术可以简单实现云数据库服务,并且可以很好地兼容现有应用。林子雨等[5]在云数据库研究报告中列举了常见的公有云关系型数据库,如亚马逊AWS RDS 与微软Azure SQL 等产品。这些云上传统数据库架构如图1 所示,为了保证高可用性,通常部署成一主多从的结构。数据库实例运行在独立的虚拟主机或容器上,主实例对用户提供读写能力,从实例提供只读访问能力。每个数据库实例都拥有隔离的存储,数据库实例的存储以本地存储或云存储形式存在。本地存储是指直接挂载在数据库实例对应物理服务器上的存储设备,而云存储则是指云提供的IAAS 层存储服务。
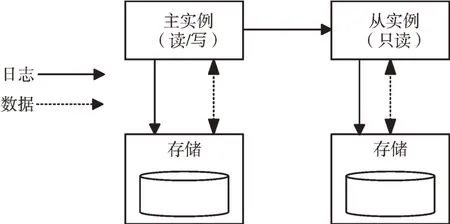
Fig.1 Master slave architecture of classic database图1 传统数据库主从架构
文献[6]指出DBaaS 凭借低价格、扩展性和灵活性及高效率方面的优势赢得了市场,但这种云上传统数据库架构无法很好地满足用户对DBaaS 的需求,在资源利用率、扩展性及可用性方面都存在问题。
在本地存储方案中,用户申请的数据库实例规格以及对应的存储规格是固定的。对于用户来说,无论用户使用多少资源都需要支付固定费用,存在资源浪费的情况。对于云服务提供商来说,高规格数据库实例搭配低容量存储,或者低规格数据库实例搭配大容量存储等场景,意味着物理服务器上资源的不合理分配,造成资源利用率低下。在云存储方案中,虽然存储以池化的方式提升了弹性,但该方案中实例对应的云存储为了提高可用性,也需要对数据进行3 副本备份,在一主多从场景中存在同一份数据3 倍实例数的数据拷贝,突出的写入放大问题对存储资源以及网络资源都造成了极大浪费。
在传统数据库架构中,每个数据库实例都有一份完整的数据库存储与之对应,该架构在DBaaS 弹性及扩展性方面无法满足用户需求。当业务负载加大,用户需要增加数据库实例进行横向扩展时,或通过纵向扩展对数据库实例规格进行升级时,与要升级的数据库实例相对应的存储也需要随之进行同步与迁移。用户的业务数据量在GB 或TB级别时,同步与迁移意味着分钟级或小时级的时间等待,这通常是用户无法接受的。
在可用性方面,传统数据库架构中,从实例通过异步方式接收主实例的数据库日志,并异步根据日志生成从实例对应的数据库数据,主从实例之间的数据不是强一致性的。当主实例发生故障时,从实例不仅会出现一定量的数据丢失,而且在数据未更新到最新版本前只提供只读服务。
2 云原生数据库技术
针对云上传统数据库面临的问题,业界从数据库技术架构层面开展了相关研究,以期使数据库更符合云原生特性。文献[7]介绍了以GoogleSpanner 为代表的分布式数据库技术,解决了大规模全球高性能数据库系统存在的性能与扩展性问题,但其不兼容现有数据库(如Oracle、MySQL、PostgreSQL、SQL Server 等)且成本昂贵的特性,使其较难在公有云市场进行推广。以AWS Aurora 为代表的基于计算存储分离技术架构实现云原生的数据库服务得到了公有云市场的普遍认可,本文主要关注公有云原生数据库技术。
亚马逊的AWS Aurora 系统是全球第一个运用计算存储分离架构的商用云数据库产品,之后,国内外知名的云服务商也都在公有云平台推出基于计算存储分离架构的云原生数据库产品,具体情况如表1 所示。
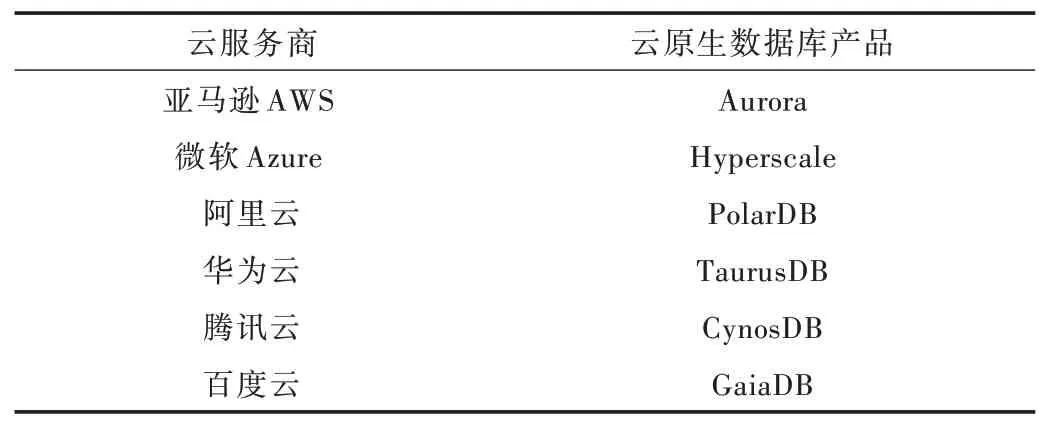
Table 1 Cloud service providers and their cloud native databases表1 云服务商及其云原生数据库产品
2.1 数据库计算存储分离
计算与存储分离技术是为了解决计算存储融合架构资源浪费且扩展不易的一种方法。马一力等[8]描述的计算存储分离计算机体系结构中,计算资源与存储资源通过网络动态组合,计算过程以数据为驱动,从而更好地实现按需驱动。在Hellerstein 等[9]描述的数据库系统架构中,计算是指消耗CPU 和内存资源的查询处理、事务管理、并发控制与日志处理等功能,存储是指消耗存储资源的日志与数据存储持久化相关功能。在云资源池中,用户对计算资源与存储资源的需求是不同的。对于计算实例,用户希望实例可根据负载状态进行弹性扩缩容,并在故障时实现快速切换,而对存储的需求是可以提供持久的数据可用及数据的快速获取。计算实例与存储之间通过高速的网络进行交互。具有计算存储分离架构的云原生关系型数据库为了降低网络交互时延,从而获得更好的性能,通常会把部分与数据持久化相关的计算能力下移至存储层加以实现,计算层实例不保存状态信息,并且不进行数据持久化相关计算。
计算存储分离架构能很好地满足云计算场景数据库服务对计算与存储的不同需求,解决了传统数据库在资源利用率、扩展性及可用性方面的问题。分离的计算层与存储层给计算存储网络传输带来了挑战,为此业界存在不同的计算能力下沉存储层方法。本章以亚马逊AWS Aurora、微软AzureHyperscale、阿里云PolarDB 及华为云TaurusDB为例,介绍在计算存储分离架构方向开展的技术研究。
2.2 亚马逊AWS Aurora
亚马逊是云数据库市场的先行者,其2014 年发布的Aurora 是世界上第一个将计算存储分离技术应用于数据库的商业云服务。
Verbitski 等[10]概括了Aurora 的计算存储分离架构,如图2 所示。Aurora 的计算层数据库实例提供查询处理、事务管理与缓存管理等功能,Aurora 的存储层提供日志存储以及根据日志生成数据库数据等功能,并能实现数据的持久化与多版本控制。共享存储的数据库数据以网络交互方式提供给计算层使用。
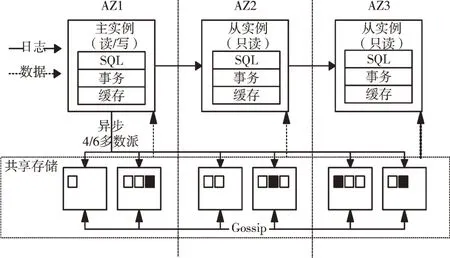
Fig.2 Decoupled compute-storage architecture of Aurora图2 Aurora 计算存储分离架构
在Aurora 架构中,系统的主要瓶颈在于网络IO,为此采用数据库实例与共享存储之间只传输日志而不传输数据的措施以提高网络性能。Aurora 的存储层基于“日志即数据库”理念,从日志生成对应的多版本数据库数据。文献[11]具体介绍了Aurora 在降低时延方面使用并发异步手段进行的日志传输与一致性处理方法。通过这些方法保证了Aurora 在性能方面相对于传统MySQL 有巨大的提升。
在扩展性方面,Aurora 计算层采用一主多从结构,主实例提供读写功能,从实例提供只读功能。由于底层的共享存储不用像传统架构一样进行数据的全量同步与迁移,计算层主实例与只读实例可进行弹性横向及纵向的扩缩容,而不用在意数据库现有业务数据量造成的影响。另外Au⁃rora 共享存储采用分布式架构,数据以分片形式错落分布在存储集群中,最大可扩容至64TB。
在可用性方面,共享存储层采用3 个可用区(Available⁃Zone,AZ)维护6 份数据的方式,保证在一个可用区故障且外加1 份备份故障(AZ+1)的场景下依旧能完成数据恢复,以提高服务的可用性。存储层的6 份数据采用写多数派方式保证日志写入的持久性,只要4 个副本数据完成写入即能保证日志持久化。之后存储层使用Gossip 协议进行日志同步,从而保证全部6 副本日志的一致。另外,如果主实例出现故障,从实例借助共享存储层的日志及数据可以轻松完成切换。
2.3 微软AzureHyperscale
微软Azure 数据库分支Hyperscale 借鉴了Aurora 系统,Antonopoulos 等[12]概括了如图3 所示的Socrates 计算存储分离架构。Socrates 架构中的计算层采用一主多从模式,主实例提供数据库读写能力,计算层实例实现事务管理、查询优化、并行处理及数据缓存等功能。Socrates 架构与Aurora架构最大的不同在于其将日志从共享存储的数据层进行了再分离。主实例将日志记录到日志服务中,供其他节点异步消费日志信息用于数据更新。共享存储层节点提供数据读取功能,并通过快照与备份功能实现数据的持久化。

Fig.3 Decoupled compute-storage architecture of Socrates图3 Socrates 计算存储分离架构
数据库日志与数据库中的数据在访问方式上存在很大差异。数据库日志的作用是为了保证数据库的持久性,并以顺序的方式频繁写入,但只在故障时才进行读取,且日志写入性能是数据库系统的瓶颈。数据库中数据的作用是为了保证数据库的可用性,数据库通常提供多版本的数据,数据的读时延和吞度量直接影响数据库的读性能。Socrates 根据日志与数据以上方面的差异,将日志与数据进行分离,从而分别提升日志层及数据层的性能。
2.4 阿里云PolarDB
阿里云PolarDB 利用PolarFS 作为存储层实现了计算存储分离架构,具体如图4 所示。PolarDB 的计算层实例保留了数据库事务管理、查询优化、并发控制与日志处理等计算功能,同样采用一主多从结构提供数据库读写功能。底层的PolarFS 可实现数据的多副本一致性同步,文献[13]介绍了PolarFS 这款高性能、低延迟读写的分布式共享存储式文件系统实现方法,计算层主实例利用PolarFS 分布式文件系统提供的类POSIX 文件接口libpfs 进行日志写入及数据读写,底层的PolarFS 通过3 副本与ParallelRaft 协议保证数据的高可用、持久性及一致性。
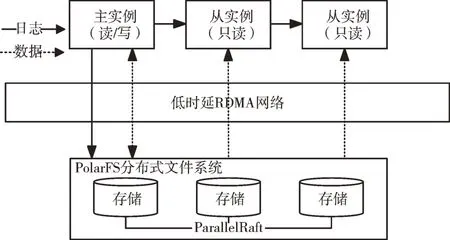
Fig.4 Decoupled compute-storage architecture of PolarDB图4 PolarDB 计算存储分离架构
与Aurora 只将日志传输到存储层并在存储层处理日志生成数据的方法不同,PolarDB 并没有对MySQL 内核作过多改动,其仍然将日志和数据都传输到存储层。PolarDB 将优化点放在用户态IO 优化及基于新网络硬件的优化以解决网络性能问题。PolarDB 通过SPDK 开发套件解决本地IO 处理性能问题,并引入远程直接存取技术(Remote Di⁃rect Memory Access,RDMA)解决计算层与存储层之间的网络性能问题。
文献[14]介绍了阿里云PolarDB 团队最近与ScaleFlux团队进行的联合研究,借助于ScaleFlux 的可计算存储,Po⁃larDB 将表扫描等与存储相关性强的计算任务下推到存储层实现,从而提升了数据库性能。
2.5 华为云TaurusDB
根据文献[15],华为云也实现了基于计算存储分离架构的TaurusDB 数据库,具体架构如图5 所示。计算层的数据库实例提供数据库事务管理、查询优化、并行处理等功能,采用一主多从架构,主实例对外提供数据库读写功能。计算层通过存储抽象层(Storage Abstraction Layer,SAL)提供的接口对日志进行读写。TaurusDB 的存储层分为日志存储与数据存储两部分。日志存储负责日志的持久化存储,并供从实例读取用于数据更新。数据存储以3 副本的方式完成数据分片存储,并接收计算层主实例的日志信息用于数据更新,同时对计算层提供多个版本的数据。
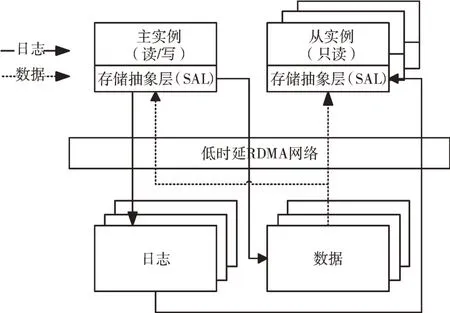
Fig.5 Decoupled compute-storage architecture of TaurusDB图5 TaurusDB 计算存储分离架构
TaurusDB 同样基于“日志即数据库”思想,以追加日志的方式完成写操作,并根据日志实现数据生成。TaurusDB将日志存储从数据存储中分离,以减少数据存储的负载,提升其性能。TaurusDB 同样使用RDMA 网络加速计算层与存储层之间的网络通信。TaurusDB 与Aurora 最大的区别在于存储层实现的复制算法及恢复算法的优化,该优化保证了TaurusDB 在3 副本情况下实现高可用及数据强一致性。
3 总结与展望
尽管所有基于计算存储分离架构的云原生数据库产品几乎都可分为计算层和存储层,但是计算层与存储层的功能边界可浮动,不同产品的功能分布也各不相同。亚马逊AWS Aurora 基于“日志即数据库”理念将存储层作为一个分布式数据存储系统加以实现;微软AzureHyperscale 将日志从计算与数据存储之间分离出来单独提供日志服务;阿里云PolarDB 则更注重软硬件结合的深度优化,提供低延时的分布式文件系统供数据库使用;华为云TaurusDB 将部分计算能力卸载到存储节点,通过优化算法实现更好的性能。
上述计算存储分离架构数据库产品都是一主多从架构,单主的实现方式可以兼容现有应用的数据库服务,但在数据库写能力扩展方面有所欠缺。引入分布式技术实现多主架构,支持分布式事务、分布式查询优化,结合分布式存储可提升数据库服务的写横向扩展能力。文献[16]所述的数据库基于全局事务日志一致性协议,初步实现了MySQL 多主数据库架构。
除架构层面的优化外,新硬件性能的提升同样能提升云原生数据库性能。新计算硬件与存储硬件的发展,对数据库性能优化可起到很大帮助。如文献[17]引入如GPU、FPGA 等异构计算硬件,优化了数据库的计算能力;文献[18]引入非易失性存储器技术,通过RDMA-NVM-SSD 三层存储架构实现数据库,从而提升数据库的数据处理及恢复性能。
DBaaS 的发展将增加数据库业务的复杂度以及数据库实例规模,DBaaS 的运维工作将成为云服务商的一项挑战。面对该挑战,业界目前的研究方向是自动化管控平台及智能化运维服务。基于计算存储分离架构的数据库能够提供Serverless 服务。数据库管控平台可针对不同负载压力情况对计算实例实现按需启动、空载停机及自动弹性扩缩容。借助于机器学习、人工智能等技术,云上数据库能够实现负载的自动感知预测,完成数据库服务的自动优化,使数据库更加自动化和智能化。如文献[19]和文献[20]介绍了基于深度强化学习实现数据库参数的自动调优,而文献[21]更是提供了一种全自动数据库的原型实现方法。
