Siamese-ELECTRA 网络结合对抗训练的FAQ 问答模型研究
2021-08-24王仲林王卫民朱乐俊
王仲林,王卫民,朱乐俊
(江苏科技大学 计算机学院,江苏 镇江 212003)
0 引言
基于常见问题集(Frequently Asked Questions,FAQ)的问答模型是智能客服系统核心技术之一[1],典型场景是:企业为了更好地服务于客户,维护着大量标准问题—标准答案对,当用户提出疑问时,服务者会根据经验和行业背景知识将用户问题映射到一个标准问题上,并返回对应的标准解答;如果当前FAQ 库中没有足够的用户咨询信息,服务者会记录用户问题并标记,准备好答案后补充到常见问题集。随着服务的持续运营,企业知识库中的历史数据规模不断增长,客服人员在成千上万条记录中寻找用户所需答案是一项重复性很高的工作,一方面十分耗费时间精力,另一方面若回答不及时容易引起客户不满。FAQ 问答模型可通过计算用户问题与标准问题之间的语义相似性,检索并返回与输入问题最相似的候选问题答案。与基于关键字的搜索引擎相比,FAQ 问答系统允许用户通过自然语言发问,能够更深刻理解专业场景中用户的意图,为其提供更为精确的答疑服务。在一定规模语料库支持下,经过良好训练的FAQ 问答模型能广泛应用各行各业,为其提供智能化的解决方案,在提高效率的同时大大降低了客服人力成本。
FAQ 问答模型的核心是文本相似度计算[2]。以往基于TF-IDF 的向量空间模型难以表征自然语言文本深层次的语义变化;基于文本特征的方法需要专家配置大量的词法句法模板;基于词向量、卷积神经网络、循环神经网络以及注意力机制的一般深度学习方法难以有效处理长依赖和多义词问题;而基于NLP 预训练模型句对分类任务的相似匹配算法,虽然能够自动提取到深层次的语义特征并充分对比句子之间的差异,但由于是句对耦合输入,一次推理仅能预测两个句子的关系,难以满足应用级别的FAQ 问答系统要求[3]。
针对上述问题,本文选取在较小参数量情况下表现更好的NLP 预训练模型ELECTRA,结合对抗训练算法FGM,提出一种基于迁移学习语言模型和对抗训练的FAQ 问答系统,通过训练一个Siamese 网络结构,模型将语义上相似问句的特征向量映射到相近的向量空间,最终通过向量距离公式快速计算出语义相似性得分。实验表明本文方法与多个已有模型相比表现更好。
1 相关工作
基于FAQ 的问答模型关键技术是如何计算用户问题和标准问题之间的相似程度,以此为出发点将已有方法分为基于向量空间模型的传统信息检索方法、基于知网等语义资源的相似性度量方法、基于人工构造文本特征的机器学习方法、基于词向量的深度学习方法,以及上述方法的混合搭配。
2003 年,秦兵等[4]综合利用向量空间模型的TF-IDF 方法和HowNet 的义原分类树,提出一种中文句子相似度的计算方法;2007 年,叶正等[5]在向量空间模型基础上提出一种基于分解向量空间和语义概念的问句相似度计算方法;2010 年,张琳等[6]提出一种基于多重信息的方法,即结合关键词信息、句子结构信息和语义信息的句子相似度计算;同年,卜文娟等[7]提出一种基于概念图的问句相似度计算方法;2014 年,郑诚等[8]改进了传统的VSM 模型,能更好地体现问题中词的权重,并引入LDA 模型。通过主题—词中词的概率分布计算词与词的相关度,提出通过词与词间相关度计算句子与句子间相似度的算法;2015 年,Wang等[9]通过定义问题的文法特征,应用学习排序的方法基于FAQ 训练了一个排序模型;2018 年,高旭杨[10]融 合word2vec 和BM25 打分,结合逻辑回归实现了一个证书服务领域的FAQ 问答系统;2019 年,莫歧等[11]提出一种联合分类与匹配的FAQ 问答模型,能够在充分利用标准问题信息的同时选择真正要区分的负例;2020 年,宋文闯等[12]针对长度较短的问句引入了问题元和词模思想,对用户问题进行分解,并与传统的相似度计算方法相融合,提出一个短文本相似度算法。
基于深度学习的方法在文本相似度计算领域成果显著,是当前业界的主流方案。2015 年,Feng 等[13]在其论文中将Siamese-CNN 网络应用到问答领域,提出并对比了4种不同的网络结构;2016 年,Neculoiu 等[14]提出的Siamese-RNN 网络可学习用于文本相似度计算的句嵌入;同年,Mueller 等[15]在AAAI 上发表了类似研究的文献。从传统的词向量技术word2vec、GloVe 到神经网络模型CNN、RNN、LSTM、Transformer 等,再到迁移学习理论在NLP 领域的应用,在大规模语料数据的支持下,深度学习技术己被证实超过了传统信息检索和统计机器学习方法在自然语言处理领域的表现;以BERT(Bidirectional Encoder Representa⁃tions from Transformers)为首的NLP 预训练模型[16],通过在海量无监督文本数据上预训练,然后到下游NLP 具体任务中的微调方式,取得了多达11 项NLP 任务的最佳结果。
综上所述,当前FAQ 问答领域研究的主要问题是如何基于最先进的NLP 预训练模型构建一个高效可用的FAQ问答系统。本文创新点如下:使用ELECTRA-Samll 模型,该模型只有BERT-Base 版约十分之一的参数体积,却达到与其相近的GLUE 分数;通过孪生网络结构训练模型,在模型层解耦了扩展问-标准问输入组合,提高了FAQ 问答系统预测效率;基于对抗训练算法,在嵌入层参数矩阵中添加对抗扰动,提高了模型的鲁棒性和泛化能力;引入了多重否定损失,配合孪生网络结构,只需正样本句对即可完成模型训练。
2 模型结构
在训练阶段,模型主要由一组权值共享的ELECRA 网络[17]构成,纵向来看,主要包括嵌入层、特征提取层、池化层、相似度计算层和目标函数层5 个部分。使用孪生网络结构的目的是在模型层(包括输入层、特征提取层和池化层)将句对组合分离,减少预测时的计算复杂度。为进一步提高模型的鲁棒性和泛化能力,本文在嵌入层基于对抗训练算法FGM[18]添加了梯度扰动;特征提取层选用NLP 预训练模型ELECTRA,其在相同体积情况下拥有比BERT 更好的效果。NLP 预训练模型输出向量较多,需要合理选择输出端的池化策略。为计算方便,训练过程中的相似度计算由向量点积完成。目标函数层采用多重否定损失[19],使用同一batch 中其他输入的响应作为当前输入的负响应,只需输入正例句对即可训练模型,如图1 所示。
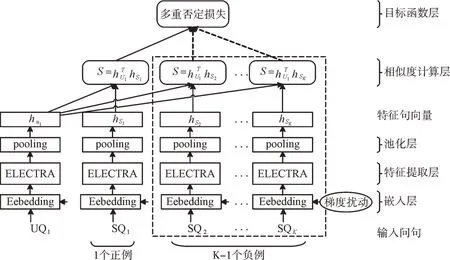
Fig.1 Overall structure of the model图1 模型整体结构
2.1 嵌入层
模型嵌入层即ELECTRA 模型的输入层,与传统的词向量加神经网络方法不同的是,NLP 预训练模型的输入层本身便包含了词向量矩阵,即嵌入层的参数在预训练阶段与模型一起从零开始训练,基于这种方式得到的词嵌入对预训练模型适配更好,依据上下文环境可以更好地表征多义词问题。此外,为了提升模型效果,本文基于FGM 算法对ELECTRA 模型嵌入层的参数矩阵添加了对抗扰动。
2.1.1 输入表示
与BERT 模型相同,ELECTRA 的输入由词嵌入、部分嵌入和位置嵌入3 部分叠加而成。如图2 所示,Token Em⁃beddings 表示词向量,第一个位置是[CLS]标志,一般用于下游分类任务;[SEP]标志是分隔符,用于将两个句子隔开;Segment Embeddings 的作用也是分开两个句子,增强区分效果;Position Embeddings 表示位置向量,引入的原因是Transformer 的自注意力机制丢失了输入的序列信息。
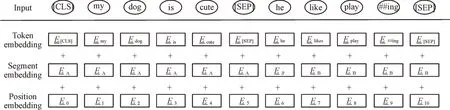
Fig.2 ELECTRA embedded layer input representation图2 ELECTRA 嵌入层输入表示
本文方法由于使用孪生网络结构解除了扩展问-标准问句对的耦合,所以每次输入模型只有一个句子,不需要使用[SEP]标记分隔双句。
2.1.2 对抗训练
神经网络的线性特点使其较容易受到线性扰动攻击,基于该特性构造的对抗样本会在不易察觉的情况下引起模型误判。对抗训练是防御对抗样本的一种方式,其基本思想是在原始输入样本中添加一个梯度扰动,得到对抗样本后以攻代守,用其训练模型。Madry 等[20]从优化的视角将对抗训练解释为一个寻找鞍点问题,即Min-Max 公式,如式(1)所示。
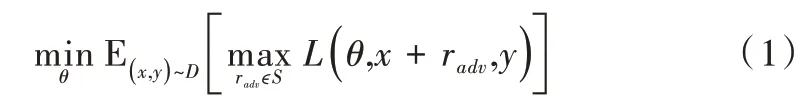
其中,L为损失函数,S为扰动的范围空间,D是输入样本的分布。右边的max 部分表示内部损失最大化,寻找最有效的扰动使模型出错;左边的min 部分表示外部经验风险的最小化,防御攻击,找到最鲁棒的模型参数。
式(1)中添加radv的目的是为了使L(θ,x+radv,y)增大,可以取梯度上升的方向。因此:

为了防止radv数值过大,通常要将其标准化后加约束ϵ。即:
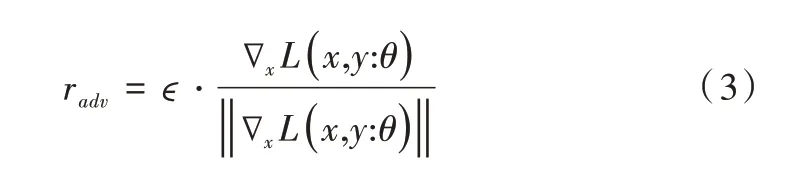
式(3)即为基于对抗训练算法FGM(Fast Gradient Method)添加的梯度干扰。针对每条样本构造出x+radv后,使用(x+radv,y)对模型参数θ进行梯度下降更新。
与CV 领域不同的是,输入神经网络的自然语言文本在最外层表示为离散的one-hot 向量,欧式距离恒为理论上不存在添加扰动的基础。因此,在NLP 任务中,对抗训练方法更多的是对嵌入层输出的连续向量添加干扰,作为一种类似正则化的方法使用。实践结果表明,该方法可以有效提高模型在NLP 任务上的效果。Ju 等[21]将对抗训练方法引入到QA 问答任务中,在CoQA 数据集上取得了很好的结果;Gan 等[22]在构建视觉语言表示学习模型时提出了大规模对抗训练方法,通过在预训练和微调阶段添加对抗干扰。模型在下游的图像和文本检索任务中得到不同程度的提升。
2.2 特征提取层
ELECTRA 是NLP 预训练模型的一种,基本结构与BERT 相同,同样是一个基于Transformer 的双向编码器模型,旨在通过联合调节所有层中的左右上下文来实现语句的深度双向表示[23]。只需要一个额外的输出层,就可以对预训练的网络进行微调,从而为NLP 任务创建最先进的模型,无需针对特定任务大量修改模型结构(见图3)。
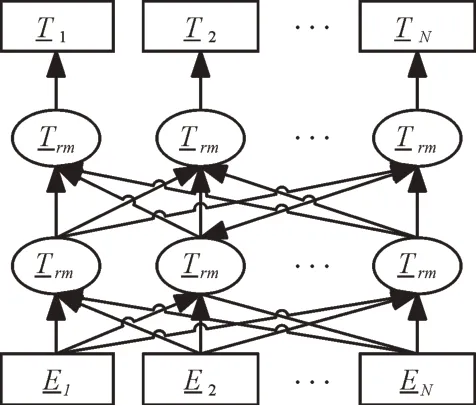
Fig.3 ELECTRA model structure图3 ELECTRA 模型结构
与其他NLP 预训练模型不同的是,ELECTRA 模型使用了类似生成对抗网络的新颖预训练方法,使模型能够以更快的速度在更小的体积上收敛。在参数量相同的情况下,ELECTRA 的效果要优于BERT,体积越小的版本中相差越明显。算法应用不仅要尽可能地提高预测精度,推理性能也非常重要。
如图4 所示,ELECTRA 模型的预训练由生成器和判别器两部分组成。生成器是一个基于遮蔽语言模型的体积较小的类BERT 结构,用于预测被[MASK]标记遮盖的标签;判别器同样是一个类BERT 结构,用于判断输入的字符是否被生成器替换过(即预测出的标签与原始语料不同),两边模型的嵌入层参数共享,左右两部分模型一起训练。不同于生成对抗网络的是,判别器梯度不会反向传播到生成器,训练的损失函数如下:
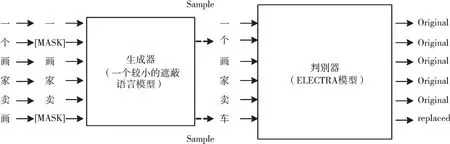
Fig.4 Pre-training process of ELECTRA model图4 ELECTRA 模型预训练过程

通过这种新颖的预训练任务和框架,ELECTRA 不仅可以和遮蔽语言模型(如BERT)一样利用大规模无监语料进行预训练,而且模型收敛速度更快,学习到的语义表示粒度更加细致。多种预训练模型的参数量和GLUE 分数对比如表1 所示。

Table 1 Comparison of NLP pre-training models表1 NLP 预训练模型对比
从表1可以看出,ELECTRA-Base与BERT-Base的参数量都为110M,却拥有更好的效果。ELECTRA-Small 仅有14M 参数,却有着接近BERT-Base 的性能,并且超过了66M 模型参数的蒸馏BERT(DistilBERT)。
2.3 池化层
ELECTRA 模型的多层Transformer 结构中,每层均可提取出向量,因此需要合理选择输出的池化方式。如图5 所示,主要有CLS 池化策略,即取CLS 标记对应的向量作为输出向量;平均池化策略,即平均最后一层所有位置的向量作为输出;最后n 层CLS 平均池化策略,即取最后n 层CLS向量做平均。为了获取信息更完整的句嵌入表示,本文在实验中选用平均池化策略。
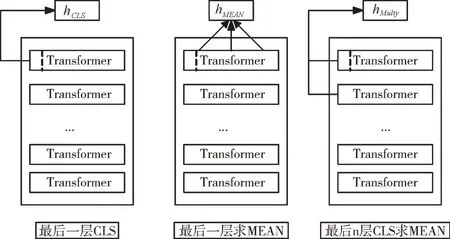
Fig.5 Output vector pooling strategy图5 输出向量池化策略
2.4 相似度计算层与目标函数层
FAQ 检索式问答的核心任务是如何根据用户问题找到与其语义最相似的标准问题。对于用户问题x最相似的标准问题是y的概率可设为P(y|x),该概率分布可写成:
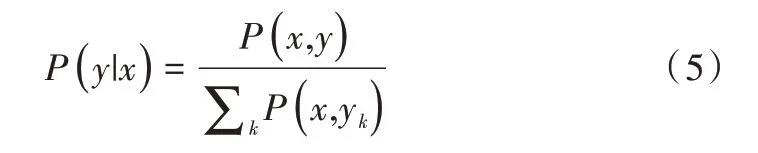
基于P(y|x)能够对可能响应x的候选标准问题y进行排序。使用神经网络模型来学习P(x,y)的联合概率,即:

对于任何给定的x,在模型训练完毕后分母都是一个常数,不会影响预测时的相似度排序。式(4)要求在每轮训练迭代中对所有可能的响应yk的概率进行求和,计算代价过高。可通过在语料库中均匀地采样K 个响应(包括y)来近似表示P(x):

结合式(6)和式(7),可以得到用于训练神经网络模型的近似概率公式:
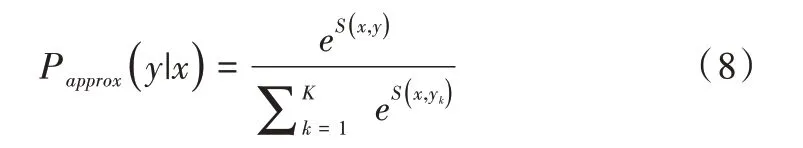
多重否定损失是Henderson 等在设计邮件智能回复系统时使用的损失函数。假设同一batch 中其他响应均为当前响应的负例,训练目标是使数据的近似均值负对数概率最小化,无需在数据集中添加负样本。
一个batch 中K个可能的响应将被用来近似P(x,y),包括一个正确的响应和K-1 个随机的否定(负例)。为提高效率和简化步骤,使用训练批次中随机梯度下降的其他样例响应作为负响应。对于一组批次大小为K的正例句对集合,将有K个用户问x=(x1,…,xK)及其对应的K个标准问y=(y1,…,yK)。当i ≠j 时,每个回答yj可当作xi的一个消极候选。训练梯度下降时是一个随机打乱过程,因此每个x的K-1 个负例在每轮迭代中都是不同的。
对于单个训练批次,如式(9)所示:
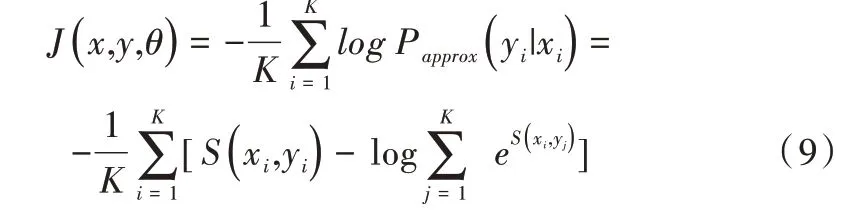
其中,θ代表神经网络的参数,S代表神经网络的计算。
3 模型预测
模型训练完成后,具有相似语义问句的特征向量将被强制映射到相近的向量空间中。预测时,经过ELECTRA模型的特征提取,一条问题语句被编码为一个特征表示向量。可以事先计算好检索库中所有标准问的句向量,获得集合S=(s1,s2,…,sn),当有用户咨询时,通过模型提取特征,可获得用户问的语义向量u,通过计算向量u和集合S中所有的句向量空间距离,可以快速获取当前用户问和所有标准问之间的相似性得分。基于该语义相似度得分可对候选问题进行相似度排序,返回最接近用户意图的候选标准问题。预测流程如图6 所示。
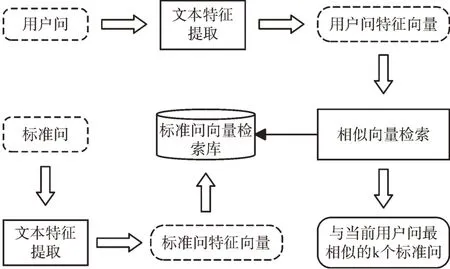
Fig.6 Model prediction process图6 模型预测流程
本文实验使用余弦距离计算特征向量的相似度,计算方法如式(10)所示,其中Ai,Bi分别代表向量A和B的各分量。

对于应用级别FAQ 问答系统,可以使用Facebook 开源的近似向量检索库Faiss,能够有效缩短标准问题召回时间。Faiss 框架为稠密向量提供高效相似度搜索和聚类,可为向量建立索引,并支持超大规模的相似向量检索,如表2所示。详细的评测结果可阅读文献[25-26]。

Table 2 Features of Faiss framework表2 Faiss 框架特性
4 实验
4.1 数据集和实验环境
实验数据源于某企业的智能客服项目,共38 251 条高质量的正样本(扩展问-标准问句对),提取出标准问题并去重后获得933 条标准问。在该数据集中,扩展问和标准问的对应关系为n:1,即对于每一条扩展问,只有一条与之相匹配的标准问题,如表3 所示。原始数据为Excel 格式,通过Python 的Pandas 库清洗和规整数据集,随机打乱顺序后转化成.tsv 格式。
实验中,随机采样6 000 条做测试集,其余32 251 条样本作为训练集参与训练。为充分展示NLP 预训练模型在中文FAQ 问答中的效果,仅对长度大于16 的问句进行去停用词处理,并清洗掉部分特殊字符。由于使用多重否定损失,不再需要向数据集中添加负样本。

Table 3 Examples of data表3 数据示例
实验环境如表4 所示。

Table 4 Experimental environment表4 实验环境
ELECTRA 中文版预训练权重[27]使用哈工大讯飞联合实验室发布的ELECTRA-small-Chinese 版本,PyTorch 版的权重需要通过Transformers 提供的转换脚本进行转换。
评价指标是模型在检索Topk个(k=1,3,…)最相似问题时的准确率(Accuracy),如式(11)所示。

4.2 实验结果与分析
模型在实验数据集上的对比结果如表5 所示,从表中可以看出,在文本相似度计算任务上,本文的Siamese-ELECTRA 模型要优于传统的词向量加CNN 或LSTM 方法。在微调阶段,对抗训练的引入对模型效果有一定提升。
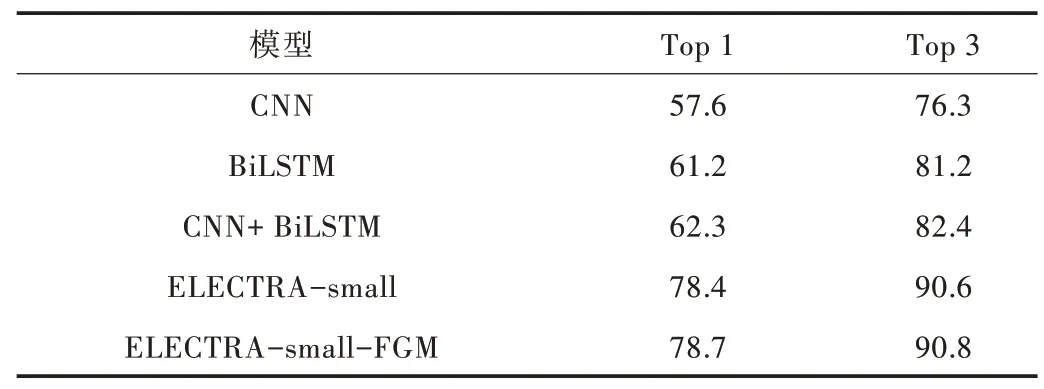
Table 5 Comparison of model effects表5 模型效果对比 (%)
此外,本文选取一组数据调整后调用模型服务进行预测,用于验证和分析所述问答模型效果,如表6 所示。
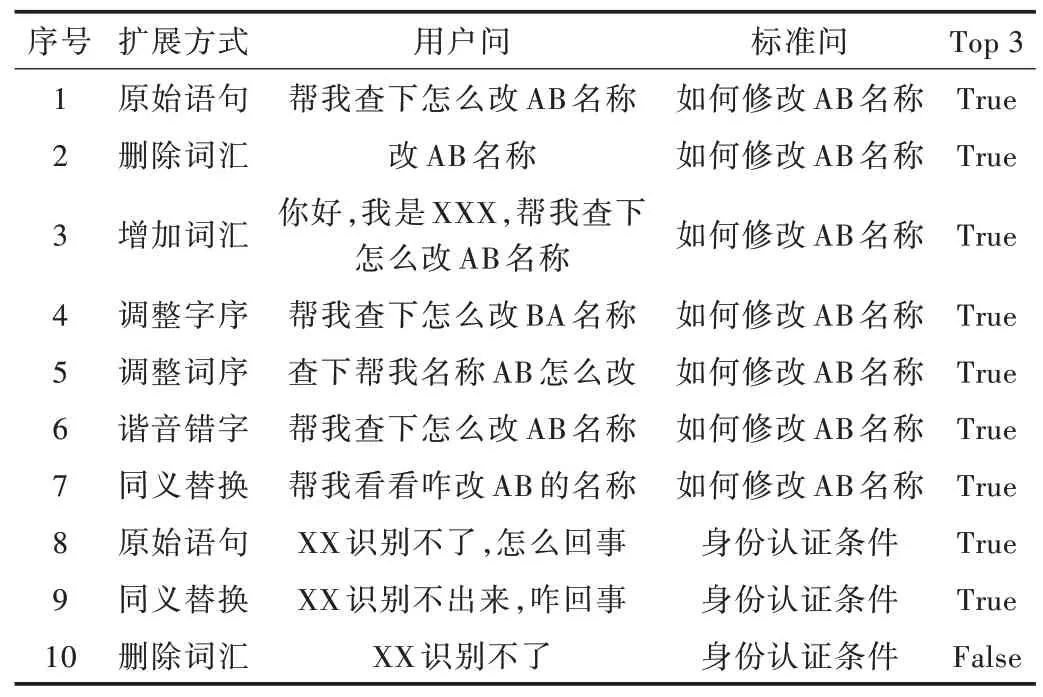
Table 6 Data analysis of forecast results表6 预测结果数据分析
通过表6 的数据分析可以直观看出本文模型的鲁棒性和泛化能力都较为出色,能够很好地适应一些常见扩展问法的调整。其中值得注意的是样例8、9 和10,这组样例的实验结果表明,对于语义距离较远的句对组合,模型可能存在一定的过拟合现象,对于这样的组合,搭建系统时需要特别进行检查和数据增强。
5 结语
本文基于Siamese-ELECTRA 网络、对抗训练算法FGM以及多重否定损失,提出一种新的FAQ 检索式问答模型。该模型利用ELECTRA 来提取问句丰富的语义特征,通过训练一个Siamese 网络结构,将语义上相似问句的特征向量映射到相近的向量空间,最终基于特征向量之间的距离快速找到最相似的候选标准问题。实验表明本文模型优于多个已有重要模型,但本文模型仍存在一些问题尚未解决,如多模型融合方法如何通过合并多个模型的检索结果提高最终重排序结果的精确度。此外,本文模型仅利用了问题与问题之间的信息,没有利用到问题与答案之间的信息,如何结合两部分内容来提高模型的表现是后续要研究的工作。
