基于关联文本的知识图谱表示学习研究
2021-08-23潘亚宁孟玉雪
潘亚宁,孟玉雪
(华北理工大学人工智能学院,唐山063210)
0 引言
知识图谱存储的是实体和关系的结构化信息,通常由三元组的集合构成,每个三元组表示为(h,r,t)其中h、r、t分别表示头实体、关系和尾实体[1]。搜索引擎、问答系统以及推荐系统等都非常依赖现有的知识图谱(Knowledge Graph,KG),如Freebase、WordNet等,表示学习在这些应用中起到了至关重要的作用。最近的嵌入技术方面的工作已经大大提高了链接预测的准确性,但是大多数方法仅依赖知识图谱中的已知事实,它们的预测能力会受到数据库中不完整信息的限制,一种简单且有效的改进途径是从文本文档中合并其他信息来增强其嵌入[2]。
互联网上存在大量的文本数据,但是这些数据大多都是非结构化的,并且质量参差不齐。当前大多数表示学习方法只是简单地利用了知识图谱三元组数据,而忽略了这些文本。虽然最近的一些模型用到了文本信息,但仍未实现对这些信息的有效利用。也有一些方法试图将文本信息融合到知识图谱。如关系抽取旨在通过识别关联文本文档中提到的新三元组来扩展现有知识图谱。但大多数关系抽取方法都需要进行远程监督,其中数据库中每个现有的事实在文本中都用其提及来标记。基于启发式规则的技术通常以这种方式自动对齐现有知识图谱和文本[3]。但是这些方法的结果并不理想,因为句子中两个实体的同时出现并不一定意味着该句子说明了它们之间的关系。
对于数据格式多样化的自然语言,实体的描述文本中通常会包含的信息不仅仅是提到的三元组,还包括许多其他实体、关系的相关信息,例如实体的语义、属性等,这些信息可以间接指示实体之间的语义相似性。因此,可以通过使用文本嵌入对象的表示来捕捉此类信息。
1 模型介绍
在Word2Vec模型[4]中,实体的向量表示定义为实体名称中词向量的均值,这种方法不仅可以用于实体的名称还可以用于实体的描述,以实现实体嵌入之间共享类似的文本特征,如词的属性或关系。
结构嵌入可以反映知识图谱中实体和关系的结构信息,这些文本数据使得训练过程可以学习实体的文本信息。首先获取每个实体的关联文本文档,其中描述或定义了该实体。例如,欧洲的维基百科条目对实体的描述。这样的数据还可以从百科全书、字典等多种渠道获得。把从描述文本中的有意义的实词提取出来作为实体描述,词的向量化方法基于Word2Vec,将实体向量定义为实体名称汇总词向量的均值。这种方法的思想应用于实体描述,可以增强实体嵌入共享如词属性或词类别等文本特征。在语义上,存在某种关系的实体的嵌入会有更大的相似性。
模型的目标在于最大化正确三元组的得分函数,以此来更新和优化参数,最终得到实体和关系的嵌入表示。目标函数定义为:
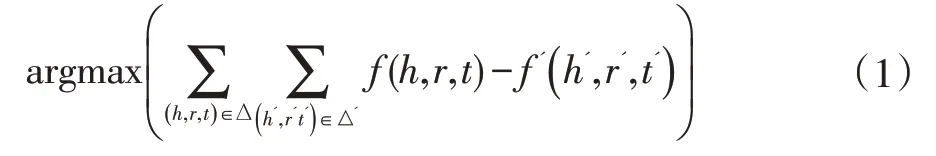
对于实体的描述信息,desc(ei)=wi,1,wi,2,…,令W表示单词向量的矩阵nw×d矩阵,nw表示总的单词数,d是实体和关系的嵌入维度,令B表示ne×nw的矩阵,Bi表示实体的描述信息中每个单词出现的次数,实体ei的嵌入表示为:

如果直接用上式表示实体,一个问题是描述文本中的所有词被同等对待,但是通常情况下,一些单词更有助于实体在特定关系下的特征表达。如白宫、共和党等词比商人等其他单词更能说明特朗普作为总统的属性(特朗普,president_of,美国)。因此,实体“特朗普”在预测“president_of”关系时,白宫、共和党等词的权重应该更大。当表达不同关系时,一些词相关性更大,需要根据关系为每个词设置不同的权重。引入nr×nw的矩阵I,Ijk表示词wk在预测关系rj时的重要性,ei表示为:

式中⊙表示逐个元素相乘。这样词向量到实体向量的总权重为词在文本中出现的频率和需要学习权重的组合。矩阵I中的参数数目nr×nw,即关系总数和单词总数的乘积。但是,利用式(3)计算实体的表示,对于某些数据集来说,参数数量可能会非常庞大。针对这个问题,考虑通过从较小数量的参数计算出Iij而不是将每个参数定义为独立参数来改进。为此,引入一个nr×d矩阵P,并定义单词wi在关系ri的权重如下:

这样就得到了实体ei在表达关系rj时基于描述信息的表示形式:
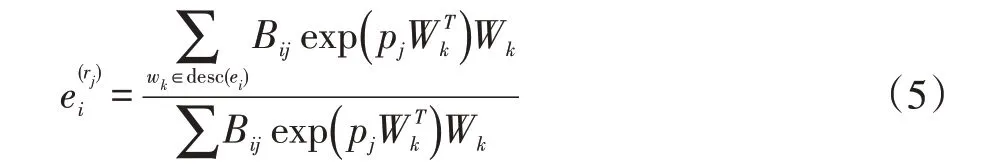
式中的运算是向量和矩阵乘法,蕴含了单词的加权平均的思想,与式(3)相比,需要训练的参数数量从nr×nw减少到了nr×d,实体文本信息嵌入的示意图如图1。

图1 基于实体文本信息的嵌入示意图
这个过程能自动学习单词与不同关系的关联,而无需远程监督。考虑到在同一关系下的实体将具有更大的相似性,因此将文本信息嵌入的评分函数定义为:
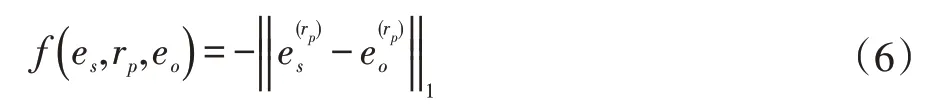
将文本信息部分的评分函数,结合知识图谱结构信息的TransE模型的评分函数,并增加一个权衡二者重要性的参数,总的评分函数如式(7)。

式中α为权重参数。通过损失函数优化模型参数,与TransE模型类似,通过最大间隔的方法增强模型区别正确三元组和错误三元组的能力。为此,模型的损失函数定义为:
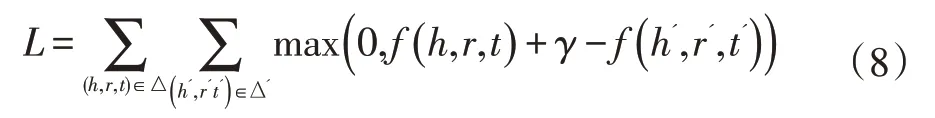
式中f(·)为评分函数,γ为超间隔参数,正确三元组和错误三元组损失函数的间隔大小。模型的训练参数θ=(E,R,I,P,α),其中E表示实体向量集,R表示关系向量集。采用负采样的方法加快模型训练速度,优化方法为AdaGrad,具体训练过程如下:

2 实验
2.1 数据
FB15k和WN18是表示学习最常用的两个数据集,这两个数据集以对称、反对称和逆关系为主。WN18是WordNet的一个子集,18表示数据集关系类型的数量,WN18中实体数量较多关系数较少。FB15k是Freebase的一个子集,有较多的关系类型,包含了1345种关系和1.5万多个实体[5],如表1所示。

表1 实验用的数据集
截取WN18数据集中的一部分如图2予以说明。WN18数据集中的第3090条三元组(07849336,_hypernym,07555863)的实际意思是词“yogurt”与词“solid_food”之间存在“hypernym”的关系,也就是三元组(yogurt,hypernym,solid_food)表示了与“酸奶”具有“上位词”关系的实体是“固体食品”。

图2 WN18数据集示例
对于实体描述词的向量化,使用对谷歌新闻数据集训练的Word2Vec向量。对于Freebase实体描述,使用与每个实体相关的维基百科页面的summary部分,并且删除其中的停用词。在Freebase中,一些实体的维基百科页面不可用,为此删除了所有没有描述的实体以及相关联的所有三元组。WN18数据集中不仅包含了三元组,也提供了实体的解释文本,可以作为实体的文本信息。
2.2 实验设置
所有实验均使用AdaGrad算法公式进行优化,采用(MR)Mean Rank和Hit@10指标来评估每个模型的链接预测性能。计算正确的三元组得分,同样地替换头实体或者尾实体得到错误三元组的得分,然后计算正确三元组得分的排名。MR定义为所有正确三元组排名的平均值,Hit@10则表示为正确三元组得分排名在前10的比例。所有的实验的训练次数均为200次,批次大小为1024,。根据验证性能选择学习率为0.01,权重α=0.85,嵌入维度d=100,间隔超参数γ=1.0。
链接预测:在给定三元组中两项情况下,预测第三项。
评估方法:得分平均排名(Mean Rank,MR)、平均倒数排名(Mean Reciprocal Rank,MRR)、前10命中率(Hit@10)。
MR:对于测试集的三元组数据每一条三元组,用实体集所有实体替换头实体或尾实体,其中原来正确三元组的评分在的排名即为MR。
MR:测试集三元组评分排名的倒数。
Hit@10:测试集三元组的评分排名在前10的比例。
2.3 结果与分析
替换正确三元组的头或者尾作为错误三元组,与原正确三元组一起构成测试集。这样做会生成假阴性样本,为此剔除测试集三元组中正确三元组的情况称为“Filter”,未剔除的称为“row”,最后得到的结果如表2所示。
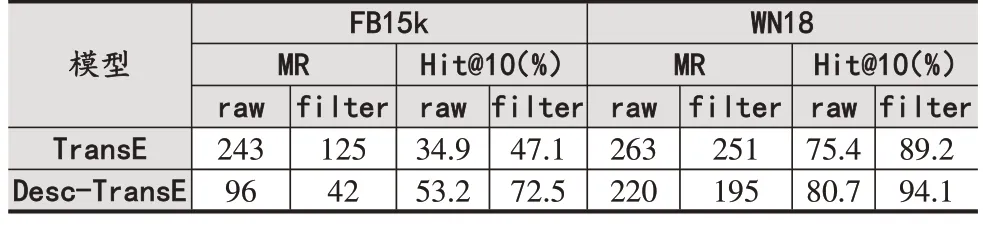
表2 实体预测的评估结果
(1)与仅利用知识图谱结构信息的TransE模型相比,引入文本信息的模型在各个指标上的结果都有一定程度的提升,在MR指标的效果尤为明显。由此可以肯定文本信息对知识图谱结构信息的补充作用,以及增强知识图谱表示学习的效果。
(2)对比模型在FB15k和WN18数据集的表现,在FB15k上的效果明显更佳。在WN18数据集上评分不如TransE模型的三元组,其头实体和尾实体的描述文本中平均有0.67个公共词,而评分比TransE基础模型好的三元组,头尾实体描述文本中平局有0.89个公共词。相比之下,FB15k中的三元组头尾实体平均公共词有20个,因此,更详细的实体文本描述能使得模型性能更好。
3 结语
针对知识图谱精确结构化数据在数量和范围的限制,提出一种从非结构化的实体描述文本中提取信息,以补充知识图谱信息的方法。实体的描述文本被视为一系列实体关联词,通过这些关联词的加权和生成实体基于文本信息的向量表示。为了更好地利用实体的文本描述语义信息,根据关系的不同为描述单词设置不同权重。将文本信息的表示与知识图谱三元组结构表示联合训练。最终得到了实体和关系的基于三元组的结构表示,文本信息能够使实体在不同关系中产生不同的表达。实验结果表明,有效利用实体描述文本的表示学习模型能够在链接预测任务中有更好的效果。
