基于NLP的《民法典·侵权编》知识图谱构建
2021-08-23万萍潘千禧柳若辰
万萍,潘千禧,柳若辰
(嘉兴学院数理与信息工程学院,嘉兴314001)
0 引言
作为新中国第一部以法典命名的《中华人民共和国民法典》(简称《民法典》),于2020年5月28日,由十三届全国人大三次会议表决通过,自2021年1月1日起施行。《民法典》为民事主体合法权益的申张与保护,提供了全面法律保障,被法学界誉为“能够覆盖一个公民‘生老病死’全部生活的社会生活百科全书”,堪称新时代人民权利的“宣言书”,为新时代“依法治国”奠定了坚实的法律基础[1]。
守法必先知法,懂法才能尊法。《民法典》一千两百六十条的法条,对于非法学专业的普通公民而言,难以全面掌握;此外,法条严谨且富于逻辑的表达,也容易造成法律条文“晦涩难懂”,不利于法律普及。经过前期文献阅读和实践调研,我们认为通过对《民法典》法条进行知识图谱构建,以可视化知识图谱方式呈现的《民法典》,不仅使法条内容呈现更加直观,还使法律概念与法律关系的检索与查询更加便捷,提升广大公民对于法律内容的认知,有效降低《民法典》的推广普及难度。
考虑到《民法典》内容庞大,本文拟选取与现实生活联系最为紧密的《侵权责任》为分析对象,综合人工智能领域中自然语言处理技术,通过“Python编程+人工校验”相结合的技术路线,应用文本预处理[2]、命名实体识别[3]、知识图谱[4-5]等NLP(Natural Language Processing,自然语言处理)领域的算法和NoSQL数据库[6-7]领域的工具,对《民法典·侵权责任》的法条内容进行关键实体识别、句法依存关系分析与知识图谱构建。
1 文本预处理
《民法典·侵权责任》共包含10章,涵盖《民法典》第1164-1258条款,合计95条。考虑到通用分词工具并没有针对法律术语的分词字典,我们采用“jieba分词+人工校验”的方式,对《民法典·侵权责任》进行文本预处理,本阶段主要包括开发环境配置、jieba工具安装、停用词预处理和分词。
jieba是中分分词领域的优秀开源框架,可以通过简单编程,实现对中文文本基于精确模式、全模式和搜索引擎模式的分词。总体上说,jieba工具的API简明实用、配置简洁。借助Python自带的pip工具,在Windows中CMD环境下执行如下命令:

即可实现jieba工具的自动安装和配置。
考虑到法条中篇章分节与条目编号相对于分词意义不大,我们在预处理阶段将这些文字去除,之后将法条逐条放入laws列表。文本读入与laws列表生成的源代码如下:

经过以上代码处理,laws列表中只包含法条内容。借助jieba分词工具,可以进一步对laws列表中法条逐一进行分词,并得到分词集合,关键代码如下:

通过校验可以发现,jieba对于部分条目的分词结果不太理想,例如“行为人/因/过错/侵害/他/人民/事/权益/造 成/损 害/的/,/应 当/承 担/侵 权/责 任/。”中“/他/人民/事/权益/”显然不符合法条本义。因此,需要在自动分词的基础上,引入人工校验环节,遵循法律术语、概念的使用习惯,修正分词中出现的错误,进而得到《民法典·侵权责任》的分词字典,共计712个单词。
通过文本预处理,我们得到了较为符合司法实践的法条分词及分词词典。在此基础上,我们将结合法条上下文,应用关键词分析算法,对分词词典中的分词的重要性进行区分,提炼具有法学价值的核心概念,为知识图谱构建提供必要的铺垫。
2 关键实体识别
《民法典·侵权责任》中涉及大量法学概念、实体,它们是构建知识图谱的关键要素。我们需要在前面得到的分词词典基础上,进一步应用命名实体识别的思想、方法和技术,对语料中的法学术语、概念进行识别和提取。在这个阶段中,我们通过关键词提取算法,对分词在法条中的表意权重进行分析,得到法条中较为重要的命名实体。
与分词一样,命名实体识别也是自然语言处理中的基础任务,目的在于识别语料中人名、地名、组织机构名等具有实体指称的命名词语。传统命名实体识别侧重于对实体、时间、数字、人名、地名、组织、时期等的识别与提取。与传统不同,本文侧重于对具有法学指称的命名实体的识别。因此,分词是否能够表达法学领域概念,是否能够结合其他法学术语形成法学知识的表达,就成为界定法学实体的重要标准。考虑到法学实体界定属于法学领域,我们邀请领域法学领域专业人士,对分词列表进行分类,遴选出154个领域相关性较强的词汇(图1),作为知识图谱构建的核心法学实体。

图1 关键法学实体词云(《民法典·侵权责任》)
需要说明的是,对于分词是否属于具有法学指称的关键实体,存在“仁者见仁,智者见智”的各种见解。因此,我们采取兼顾经验与统计的原则,选取法务工作中涉及的专业词、高频词作为关键实体,进而以之为基点,对《民法典·侵权责任》做提纲挈领的图谱构建。
3 知识图谱构建
本部分在关键实体集合基础上,进一步探究实体之间的法学逻辑关系,通过逐一对法条进行句法依存分析,构建关键实体之间的三元组,最终形成可视化的知识图谱。
对于逻辑严谨、措辞考究的法律条目而言,“主语+谓语+宾语”是基本的表达句型,也是分析与理解其语言复合性的切入点。结合关键实体,逐条分析每款条文的句法依存关系,是构建法条内与法条间实体逻辑关系的关键。通过调用HanLP接口,逐一分析每款法条的句法依存关系,得到类似图2的句法树。

图2 句法依存关系示例(《民法典》第一千一百六十六条)
借助以上语法树结构,可以得到该法条清晰明确的推断逻辑,即“行为人”为主体,“侵权责任”为客体,“承担”是联系主、客体的关系,而“民事权益损害”是逻辑前提。
实体依存关系分析的目的在于提炼“实体-关系-实体”构成的三元组,通过这个三元组表达实体之间的逻辑关系。从前面对句法依存关系的分析可以看出,法条语法树中“主谓宾”结构天然适于构造这种三元组。基于此,通过对作为主语和宾语的关键实体以及作为谓语的分词的提取,就可以得到所有三元组构成的集合。
三元组数据的持久化与可视化可以借助Neo4J数据库及Py2neo框架。其中,Neo4J是一种常见的图数据库,以图的形式表达数据的实体、属性和关系,属于典型的NoSQL数据库;Py2neo是应用Python操作Neo4J数据库的三方库。通过将三元组中的实体存储为节点元素,将三元组中的关系存储为节点之间的边,就可完成从三元组到抽象图谱的构造。再通过调用Py2neo API,可以得到类似图3的可视化知识图谱。
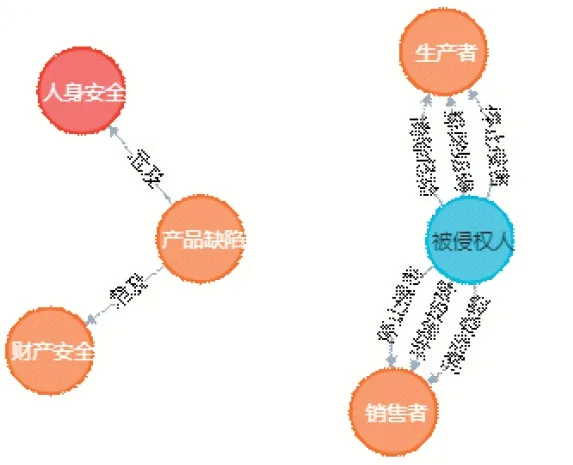
图3 知识图谱示例(《民法典》第一千二百五十条)
目前,我们针对《民法典·侵权责任》的知识图谱构建主要还是以法条为基本单位。但是,不同法律条目间也可能存在语义或是逻辑上的关联,对于这一点,由于涉及到更为困难的语义分析以及知识推理,预期于将来的工作中做进一步的深入研究和探讨。
4 结语
本文对《民法典·侵权责任》文本进行知识图谱构建,实现核心概念及其关系的可视化。首先,通过文本预处理与分词,生成文本的分词列表。由于法典文本的专业性,通用分词工具得到的分词结果不是完全合理,再通过对分词列表的人工校验,得到较为符合实际法务工作习惯的分词列表。其次,通过对分词列表进行甄别,结合统计与法务实践,遴选出司法实践中使用频率高、法律指称明确的关键实体。最后,以筛选出的关键实体为中心,逐条对法条进行句法分析,得到分词列表以外的实体与关键实体之间的关系,据此生成三元组结构,进而生成可视化图谱。
本文通过对法条文字的图谱构建,有助于提升对侵权责任中法学对象、关系和逻辑的理解与整体把握,促进民法典的宣传与普及。
