M估计在单指数投资组合模型中的应用
2021-08-16陈亚男刘月娟
陈亚男,刘月娟,朱 睿
1.巢湖学院数学与统计学院,安徽合肥,238000;2.中山大学附属第七医院,广东深圳,518000
Markowiz均值-方差投资组合模型(以下简称M-V模型)虽然解决了投资组合的选择问题,但在实际应用中,M-V模型需要计算的信息量非常大,使得工作任务变得十分复杂困难[1]。为解决这一难题,Sharpe[2]提出了单指数模型,很大程度上简化了投资组合模型的计算过程。单指数投资组合模型具有数据采集便利性、计算简便性、实用性强等优点,研究者将此模型视为一种优化模型[3]。Ross提出套利定价模型,这一理论的提出使得现代投资组合理论更完善了。但不足的是传统的单指数模型使用的是最小二乘估计法(OLS),由于离群值(异常值)的存在,使用OLS估计结果误差较大[4]。Manskiel[5]研究了一般单指数模型中未知参数β的可识别条件。对单指数模型中未知参数β的估计,Gallant提出了半参数加权非线性最小二乘(WNLS)法,Stone[6]也研究了利用极大似然估计法对参数β进行估计。实际上,上述所提及方法的目标函数存在是非凸的可能性,需要求解线性数值优化问题,这样的话,计算起来非常困难。Manskiel研究了一种特殊的单指数模型:两值响应模型,提出了极大似化计分函数方法来估计β,且证明了估计是相合的。Powell等[7]提出了用密度加权平均导数估计(ADE)法。Hsieh等[8]所提出的极大似化计分函数方法在一定条件下依分布收敛某个正态分布的极大值点,但是收敛速度很慢。为了改进收敛速度,Horiwitz提出了β的基于光滑计分函数的极大计分估计,并建立了他的渐进正态性[9]。杨晓辉等[10]利用单指数模型进行了投资组合有效边界的绘制,但忽略了市场收益率的非正态性。李敏[11]提出用L-median估计量来估计股票收益率,在一定程度上克服异常值对参数的影响,但整体效果不佳。谢振中[12]将Bisquare估计量来估计回归参数,对传统的OLS估计进行改进。
上述这些对单指数模型中回归系数β的估计并非都考虑到数据中异常点对回归系数估计的影响。针对上述存在的问题,本文的思想是在单指数模型中引入鲁棒估计法,建立基于M-估计的单指数投资组合模型,可以求出的回归系数是对异常值不敏感的,这一处理使得数据中异常点对回归系数估计的影响有很大程度的减小。
1 预备知识
1.1 单指数模型
Sharpe[2]觉得无论何种股票,其收益率与其所在股票或证券市场的代表性指数收益率应该以某种线性关系呈现出来,即基本方程
Ri=αi+βiRm+ei,i=1,2,…,n
(1)
式(1)中,αi是独立于市场表现的随机变量,是股票i收益的组成部分;Rm表示市场指数收益率,也是一个随机变量;βi衡量Rm变化时Ri的期望变化,是一个常数;ei是误差项,其期望为0。
通过构建均值ei=E(ei)=0,i=1,2,…,n, 假设
(1)指数与特有收益(市场指数收益率)不相关,即
(2)
(2)股票仅通过对市场的共同反应而相互关联,即
E(eiej)=0orcov(ei,ej)=0,(i,j=1,2,…,n且i≠j)
(3)

=WT∑W
(4)
其中,W为单指数投资组合权重向量,∑为投资组合的协方差。
(5)
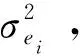
类似于M-V模型,本文定义单指数投资组合模型,即
=WT∑W
s.t.WTμ>r
(6)
基于OLS的单指数投资组合模型(以下简称模型Ⅰ)的实际经济意义为当市场不允许卖空时,使投资者所构建的投资组合模型能够在损失风险不变的情况下获得最大的利益或者在保证利益不变的情况下所承担的损失风险最小。
1.2 基于M估计的单指数投资组合模型的建立
1.2.1 鲁棒性
鲁棒估计是一种能有效处理不确定因素问题的手段,目标是找到具有不确定参数的优化问题的解,使得这个解对于满足不确定集的所有或者大多数参数来说都能达到很好的目标值,它不要求得知参数的分布。因此,本文利用鲁棒估计处理投资组合中收益率的不确定性。
1.2.2 M-估计量

(7)
如将M估计用于投资组合模型中,与风险、收益结合起来,便可构造投资组合风险的M-估计量
(8)
因此,损失函数ρ(·)也可以作为一种风险测度,来衡量投资组合的有效性。除了Huber提出的Huber损失函数之外,投资组合中还包含了以下常用的几种损失函数,即Lp损失函数、L1-L2损失函数、Tukey损失函数等。其中,Tukey损失函数具有良好的样本外性质,若将其用于鲁棒估计投资组合,必须满足两个条件:(1)Tukey损失函数必须是对称的,且最小值为0;(2)存在一个常数c,当c∈[0,c]时,Tukey损失函数严格增加;当c∈[c,+∞)时,Tukey损失函数为常数。
本文选择Tukey损失函数,m是最优投资组合下的M估计量,从而(8)式可以转化为以下优化问题来计算M估计量:
(9)
1.2.3 基于鲁棒估计单指数投资组合模型的建立
在研究单指数投资组合模型时,回归分析是不可或缺的一个环节,用以估计模型中的回归系数α和β,单指数投资组合模型中最常用的回归方法就是普通OLS,OLS估计最大的缺点就是不能很好地排除离群值(异常值)对回归残差乃至回归系数的影响。为减小这种由于离群值(异常值)的存在而导致回归系数的估计误差,本文把鲁棒估计的思想引入单指数模型的求解过程中,建立基于M估计的单指数投资组合模型,估计出不能明显感应到离群值存在的回归系数,减小离群值(异常值)对回归结果产生的影响,使得最终的投资组合模型达到更有效的投资效果。
其具体建模思想为:首先,用M-估计投资组合模型估计出回归系数;其次,将所估计出的回归系数带入单指数模型中,进而求解投资组合的最优解。按照这个思想分两步建立基于M估计的单指数投资组合模型(分成两步法):
目标函数1:
(10)
目标函数2:
ωTe=1,ωi≥0,i=1,2,…,n
(11)
当M估计选择Huber损失函数估计时,为基于M-Huber估计的单指数投资组合模型(以下简称模型Ⅱ);当M估计选择Tukey损失函数估计时,为基于M-Tukey估计的单指数投资组合模型(以下简称模型Ⅲ)。本文通过建立两个目标函数来解目标优化问题,首先第一个目标函数其次将可以用鲁棒估计单指数模型中所需参数;其次将第一个目标得出的结果用于第二个目标函数中求解优化问题。这种新的投资组合模型不仅减少Markowiz模型所带来的大量计算,又能够减小传统单指数模型中OLS不能减小的由于离群值(异常值)的存在而导致的估计误差。
2 实证分析
2.1 数据的选取与分析
为了能够更好地研究模型Ⅰ、Ⅱ、Ⅲ的有效性,本文主要对上证50指中10支股票的日收盘价进行研究分析。选择依据主要是:为了更好地体现分散投资的理念,股票尽量属于不同的行业;上市时间早,市场规模大,流通性能高,代表性强,用少量股票便可体现中国金融市场性质;股票历史数据缺失值不多于5个,以提供大量效果较好的股票数据。首先,对数据进行预处理,算出每只的日收益率rti,并进行统计分析,相关统计结果具体见表1。

表1 股票收益率统计描述
2.2 数据的正态性检验
由于M估计投资组合模型的建立是在股票收益率为非正态分布的基础上成立的,因此需要进一步验证数据是否服从正态分布,从股票收益率的柱状统计图和QQ图分析其正态性。由图1(左)可知,中国石化的偏度大于0,峰度大于5,表明中国石化股票数据右拖尾较长,并有尖峰、厚尾等特点。此外,统计量Jarque-Bera大于临界值,并且P值等于0,拒绝该样本收益率满足正态分布的假设。图1(右)中,样本收益率数据的Q-Q图很大程度上偏离直线y=x,这充分说明了样本收益率数据不服从正态分布。综合上述,对中国石化股票数据的分析,本文发现中国石化股票收益率具有波动集聚性和非正态性,故可用单指数模型来拟合收益率残差序列分布的尾部。同理,用Eviews软件画出余下9支股票收益率的柱状图和QQ图,经分析图中各类统计参数后得出均不服从正态分布,具体的统计参数分析见表2。
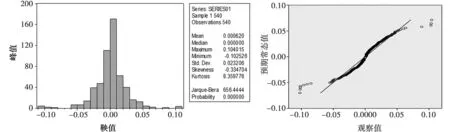
图1 中国石化指数收益率柱状统计图和QQ图
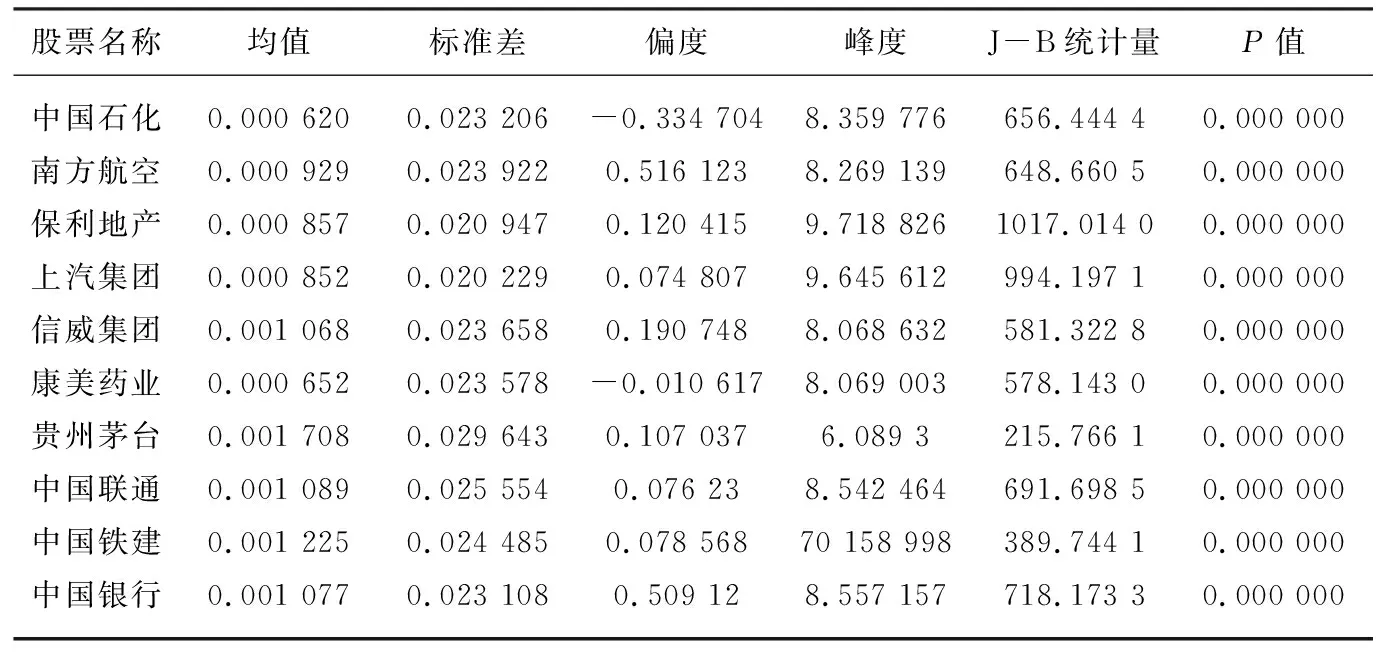
表2 10只股票收益率的统计量
2.3 模型Ⅰ、Ⅱ、Ⅲ的有效性分析
通过上面10只股票收益率分布以及相应统计量的分析,可以发现:由于离群值(异常值)的存在,股票收益率不服从正态分布。因此,本文将M估计投资组合模型运用到传统的单指数模型中,用于估计单指数模型中的参数,并将与最小二乘法(OLS)估计的参数进行对比分析,进而求解相应的投资组合问题,得到不同模型下的有效边界,对比分析模型Ⅰ、Ⅱ、Ⅲ的有效性。
2.3.1 模型Ⅰ、Ⅱ、Ⅲ的参数估计
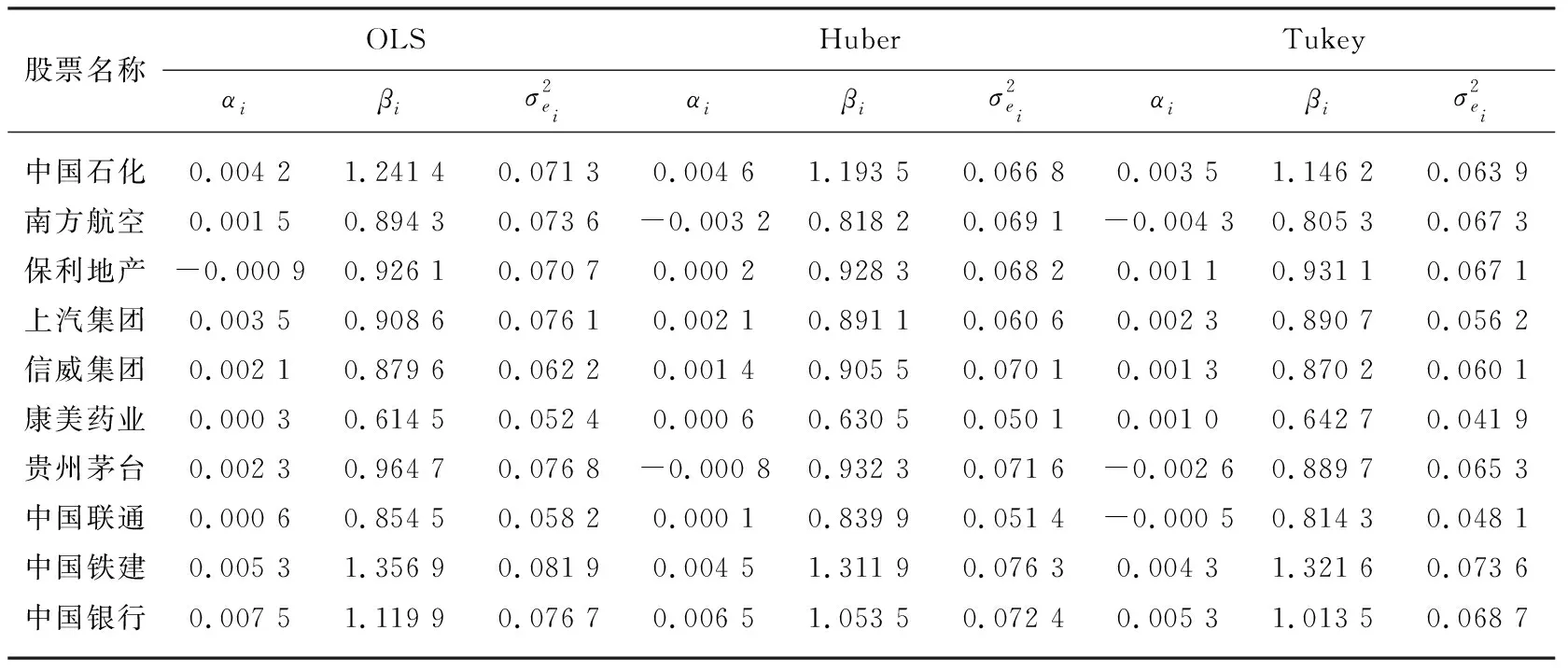
表3 不同估计方法下的参数估计值
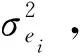
2.3.2 模型Ⅰ、Ⅱ、Ⅲ的有效前沿对比
将获得的数据代入模型Ⅰ、Ⅱ、Ⅲ中,求解第二个目标函数,通过规划求解得到模型Ⅰ、Ⅱ、Ⅲ的有效边界,见图2。

图2 在不同估计情况下的投资组合模型的有效边界
从图2可以看出,用三种不同的方法得到的有效边界在投资组合期望收益率比较小的时候,三种方法得到的投资组合的风险相差无几。但是随着投资组合期望收益率的增大,投资组合的风险变化的幅度有所不同。用OLS方法得到的投资组合的有效边界在最下方,用M-Tukey方法得到的投资组合的有效边界位于图中上方第一条线,而M-Huber法得到的有效边界始终介于OLS法与M-Tukey法得到的有效边界之间。这说明模型Ⅲ的投资效果最好,模型Ⅰ的投资效果最差,而模型Ⅱ的投资效果始终介于二者之间,即在投资组合风险不变的条件下,OLS方法下的单指数投资组合期望收益率最小;M-Huber方法下的单指数投资组合期望收益率有所提高,但是幅度不大;M-Tukey方法下的单指数投资组合期望收益率明显提高。
2.3.3 模型Ⅰ、Ⅱ、Ⅲ的稳健性分析
本文使用“滚动视野法”得到模型Ⅰ、Ⅱ、Ⅲ的权重箱线图。通过箱线图的分布情况来分析不同估计情况下的投资组合模型权重的稳健性,进而分析投资组合的稳健性。
图3中,图3(a)表示的是OLS估计下的单指数投资组合模型(模型Ⅰ)的权重分布,虽然每个资产的权重的分布相对较为均匀,但是由于股票收益率不是严格服从正态分布,有一部分的异常值的存在,使得求解投资组合模型的最优解时,仍然有较多的权重偏离中心位置。图3(b)表示的是在M-Huber估计下的单指数投资组合模型(模型Ⅱ)的权重分布,在这种估计方法下的投资组合的权重分布较为均匀,虽然相对于OLS估计方法下的投资组合模型的权重分布而言,偏离中心位置的权重减少了很多,但是仍然存在较多的权重偏离中心位置。图3(c)表示的是在M-Tukey估计方法下的单指数投资组合模型(模型Ⅲ)的权重分布,从图中可以看出,相对于前两种估计方法的投资组合模型的权重分布,M-Tukey估计方法下的单指数投资组合模型的最优解中,偏离中心位置的投资组合权重有着明显减少,但是资产1、资产4、资产7、资产8的权重分布的范围明显变大,并且资产8的权重出现右偏的情况。这说明M-估计可以很有效地降低投资组合收益率中离群值(异常值)的存在对投资组合模型最优解的影响,但是它在降低离群值(异常值)产生影响的同时,可能会导致其他问题出现,如某个资产的权重分布的范围可能变大,使得投资者的选择范围变大,不利于投资者做出投资决策。总而言之,M-Huber估计下的单指数投资组合与M-Tukey估计下的单指数投资组合的稳健性对回归估计偏离正态性的偏差相对不敏感。而传统的单指数投资组合(OLS)的稳健性对回归估计偏离正态性的偏差较为敏感。

图3 三种估计方法下的投资组合权重箱线图
2.3.4 模型Ⅰ、Ⅱ、Ⅲ的绩效指标比较
通过对三种不同估计方法下的单指数投资组合权重箱线图的研究分析,发现基于不同损失函数的M-估计的单指数投资组合模型相对于传统的单指数投资组合模型的稳健性都有着不同程度的改善,但是仍然是一种顾此及彼的改善。投资组合模型的有效性的衡量标准不唯一,主要有夏普测度、特雷诺测度、詹森测度、信息比率和 M2 测度等。如果投资者注重系统性风险,则以考虑詹森测度、特雷诺测度的排名为主,若注重总风险,则以考虑夏普测度为主。本文兼顾系统性风险和总风险,选择夏普测度和特雷诺测度作为主要的基金业投资组合模型评价指标。
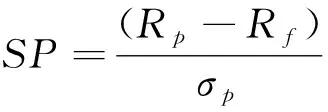
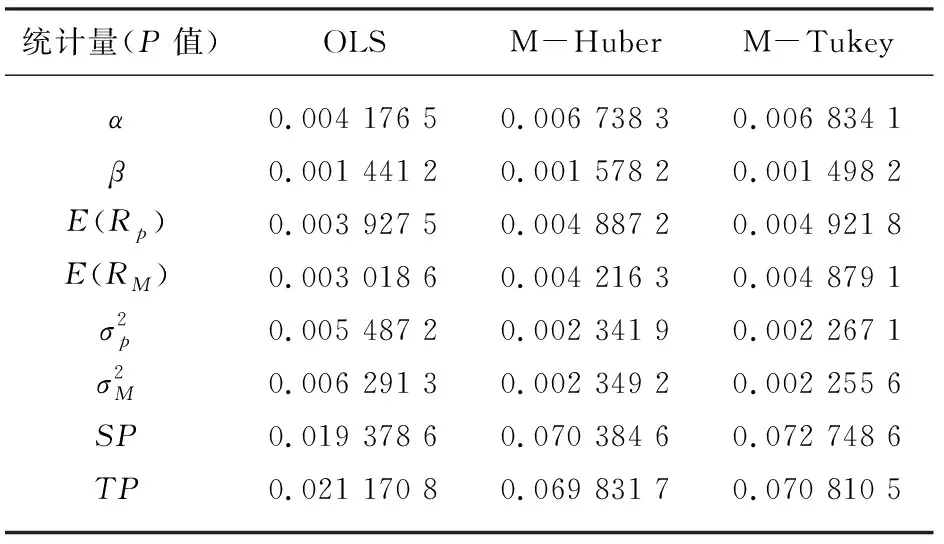
表4 模型Ⅰ、Ⅱ、Ⅲ的统计指标
考虑到给定一个收益率水平以及不允许卖空的条件,从表4中结果可得结论,模型I、II、III的夏普测度和特雷诺测度的比较如下:SPI=0.019 378 6 股票市场里资产收益率往往是偏离正态分布的,M-V模型的估计误差较大,所要计算的信息量也非常大。这时寻找合适的投资组合替代模型就显得尤为重要了。本文用鲁棒性较强的M-Huber估计和M-Tukey估计代替OLS,并引入到单指数模型中,构建基于M估计的单指数投资组合模型,不仅解决了Markowiz均值-方差投资组合模型的计算信息量大的问题,同时在很大程度上可以减少离群值对单指数模型中回归参数估计的影响,从而给投资者提供一种更为科学的投资决策,以达到在风险相同的情况下获得最大收益或在收益相同情况下风险最小的目的,这对投资者们进行投资组合选择具有现实指导意义。但投资者在使用本文模型进行投资时应使用最新数据,并结合实际市场动向,避开不可控因素后再进行投资。3 结 论
