一种相似度剪枝的离群点检测算法
2018-09-07丁天一方胜良
丁天一,张 旻,方胜良
(电子工程学院,合肥 230037) E-mail:tianyi_ding@126.com
1 引 言
离群点检测是数据挖掘和知识发现的一个重要研究领域,其目的是有效识别出数据集中的异常数据,以及挖掘出数据集中有意义的潜在信息[1].离群点检测有着非常广阔的应用前景,特别是在欺诈检测、医疗诊断、市场分析、气象分析、网络入侵检测等领域,离群信息往往比常规模式更具价值[2-4].因此,离群点检测已经引起了越来越多国内外学者的关注,所提出的算法也层出不穷.
现有的离群点检测方法大致上可分为以下几类:基于统计学的离群点检测方法,基于距离的离群点检测方法,基于聚类的离群点检测方法和基于密度的离群点检测方法等[1].基于统计学的离群点检测方法是通过拟合给定数据集的生成模型,识别该模型低概率区域的对象来检测离群点,依赖于给定数据的全局分布,当给定数据分布不均匀时,很难确定一个合适的模型;基于距离的离群点检测方法可以处理多维数据,也不需要用户事先知道数据分布模型,但是当数据集包含不同密度的区域时,该方法不能很好地识别离群点;基于聚类的离群点检测算法通过考察对象与簇之间的关系检测离群点,将不属于任何簇或者属于较小的簇的对象作为离群点,离群点是作为聚类算法的副产物而被发现的,高度依赖于聚类算法的有效性;基于密度的局部离群点检测方法不将离群点看作一种二元性质,而是衡量一个对象的离群程度,能够在数据分布不均匀的情况下准确地发现离群点.Breunig等人提出了局部离群因子的概念,这是一种基于密度的局部离群点检测方法,通过赋予每一个数据对象一个表征它离群程度的量化指标来进行离群点检测[5].后续出现了很多新的改进方法,以期取得更好的离群点检测结果.文献[6]针对不确定数据集进行离群点检测,设计了一种基于密度的不确定数据局部离群因子检测算法;文献[7]提出了一种基于偏离的局部离群点检测算法,通过对数据集进行数据块的划分,计算每个数据块中数据对象的离散程度,发现可能存在的局部离群点;文献[8]提出的NLOF算法利用邻域查询优化方法降低邻域查询的复杂度,并通过DBSCAN对数据集进行预处理,提高离群点检测精度;文献[9]提出了一种基于方形对称邻域的局部离群点检测方法,通过扩张方形邻域建立候选异常点集合,并引入记忆思想和新的离群度度量方法.上述的离群点检测算法都在各自的应用背景下取得了一定检测效果.然而,随着数据集的涌现,不规则形状数据集和复杂分布的多维数据集给离群点检测带来了更大的难题,以上算法对于此类问题的检测精度较低,需要一种更加有效的离群点检测方法.
本文首先介绍了LOF算法的相关概念,然后分析利用构造相似度矩阵的方法进行离群点挖掘的合理有效性,并将基于相似度矩阵的非离群点剪枝与局部离群点检测算法相结合,提出了一种新的离群点检测算法.最后,采用人工数据集和UCI数据集,实验验证了本文算法的有效性.
2 局部离群点检测算法
LOF算法为每一个数据对象赋予一个表征该数据对象离群程度的局部离群因子,用于衡量每一个数据点的离群程度.具有较大局部离群因子的数据点其密度小于它周围数据点的密度,因此这样的数据对象被判别为离群点.相反,具有较小局部离群因子或者局部离群因子接近于1的数据点,在此算法下被判别为正常点[10,11].LOF算法的一些基本概念如下[5,8].
定义1.(对象p的第k距离,k-distance(p)) 对于任意的自然数k,定义p的第k距离为p与某个对象o之间的距离,记为k-distance(p),这里的对象o属于数据集D并且满足以下条件:
1)至少存在k个对象o′∈D{p}满足d(p,o′)≤d(p,o);
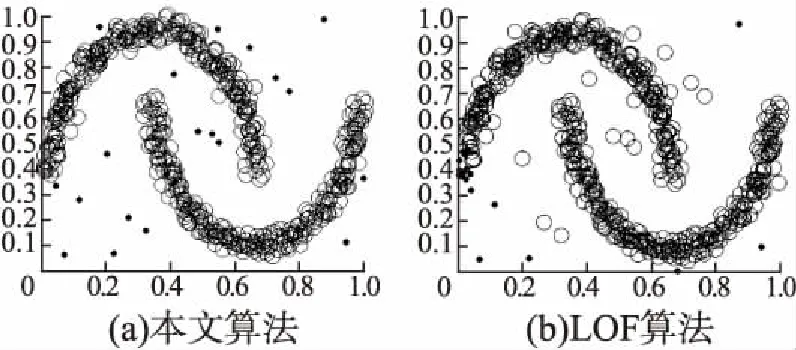
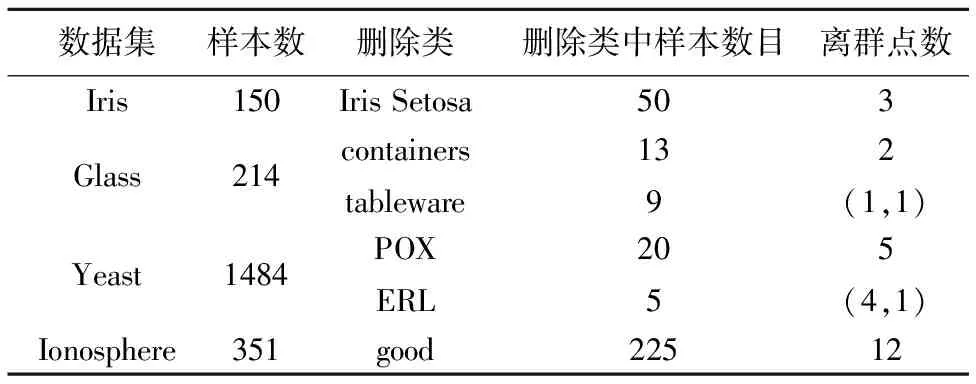
2)至多存在k-1个对象o′∈D{p}满足d(p,o′) 其中,d(p,o)表示对象p和对象o之间的距离.换言之,k-distance(p)是对象p与其第k个最近邻之间的距离. 定义2.(对象p的第k距离邻域,Nk-distance(p)) 已知数据对象p的k-distance(p),对象p的第k距离邻域是所有与p的距离不超过k-distance(p)的数据对象的集合,即: Nk-distance(p)={q|d(p,q)≤k-distance(p)} (1) 式(1)中,Nk-distance(p)在本文中为便于描述简记为Nk(p). 定义3.(对象p相对于对象o的可达距离,reach-dist(p,o)) 对于给定的自然数k,对象p相对于对象o的可达距离为: reach-dist(p,o)=max{k-distance(o),d(p,o)} (2) 定义4.(对象p的局部可达密度,lrdk(p)) 对象p的局部可达密度是对象p与它的第k距离邻域Nk(p)的平均可达距离的倒数,计算公式为: (3) 定义5.(对象p的局部离群因子,LOFk(p)) 对象p的局部离群因子表征对象p为离群点的程度,局部离群因子越大,对象p为离群点的可能性越大;反之,则越小.计算公式为: (4) 本文提出的算法主要分为两个阶段,首先,通过构造相似度矩阵的方法对数据集进行预处理,找到与其他数据相似度较小的对象,以此作为初步的离群点候选集,完成对非离群点的剪枝;然后,针对得到的离群点候选集,采用LOF算法计算离群点候选集中每个数据对象的局部离群因子,将所有对象的局部离群因子大小进行排序,进而获得最终的离群点检测结果. 合理的相似度矩阵构造方法可以有效地得到复杂分布数据之间的相似度,反映数据集原有的基本特征.离群数据往往是与其他数据相似度较小的点,寻求一种合适的相似度矩阵的构造方法,能够有效地找到数据集中与其他数据相似度较小的一部分对象,完成对非离群点的剪枝,得到离群点候选集. 为了能够有效地反映出不规则形状数据集和复杂分布的多维数据集的特征,需要确定一种有效的相似度计算方法,以提高离群点检测的精确度.本文采用了如下的相似度函数: (5) 其中,‖xi-xj‖表示点xi与xj之间的欧氏距离,σi=d(xi,xk),表示样本点xi到其第k个最近样本点的欧氏距离.文献[12]指出,k的选择是与数据规模无关的,通过对于合成数据和图像数据的实验确定了k的最佳取值为k=7,此时即使对于高维数据也能得到很好的结果,这是一个经验值.这样,对于数据集中的每一个样本点,都计算了一个局部尺度参数,可以根据样本点xi与xj相邻数据的统计特性自动调整点到点之间的距离,于是点xi与xj的距离从xi的角度可以看作是d(xi,xj)/σi,而从xj的角度可以看做是d(xi,xj)/σj[12]. 式(5)的相似度函数基于高斯核函数提出,可以将样本间的相似度计算从基于欧氏距离的原始特征空间映射到高维特征核空间,通过非线性映射将数据从线性不可分变成线性可分,能够放大有用的特征以便更好地区分数据. 同时,该方法在以高斯核函数作为样本之间相似性度量方式的基础上,将每个样本点的邻域信息引入到高斯核函数的相似度计算中,以样本点与其近邻的距离作为该点的局部尺度参数代替全局单一尺度参数,通过两个样本点各自的局部分布情况来改进它们之间的相似度,使得在同一密集区的样本点相似度更高,稀疏区的样本点则相似度较小[12]. 图1 多尺度数据集Fig.1 Multiscale data set 图1是一个多尺度数据集,由弧形的密集簇和一组稀疏簇组成,其中样本点A和C位于较为紧密的弧形数据簇中,而样本点B位于稀疏簇中.假设AB和AC的距离相等,如果仅用欧氏距离表示两者之间的相似度,则wAB=wAC,即AB与AC之间相似度相等,而客观情况是样本点A和C位于同一流形上的密集簇,样本间的相似度应该大于位于不同密集程度的样本点A和B的相似度,显然在这种情况下仅凭欧氏距离不能正确地衡量样本间的相似度.如果采用式(5)的方法,通过引入邻域信息,有σC>σB,则σAσC>σAσB,从而得到wAC>wAB,更真实准确地反映出了复杂分布数据的内在结构特征. 由此,通过式(5)计算得到了样本间的相似度矩阵W,其矩阵形式表示如式(6)所示. (6) 为了能够筛选出与其他样本相似度较小的对象,下一步,需要根据式(5)计算得到的相似度矩阵对数据集进行非离群点剪枝. (7) 然后,将度矩阵D中的所有元素d11,d22,…,dnn按照从小到大排列,选取相似度值较小的一部分样本作为数据集的离群点候选集. 基于相似度矩阵的非离群点剪枝策略可以有效地适应不规则形状、非均匀分布的数据集,还原出数据集的基本特征,更好地区分原始数据和离群数据,使后续的局部离群点检测更具针对性,从而提高离群点检测的精确度. 输入:数据集X={x1,x2,…,xn},近邻个数k,离群点候选集样本个数c,离群点个数m 输出:数据集X的离群点集合 Step1.利用式(5)建立相似度矩阵W; Step2.计算相似度矩阵W的度矩阵D; Step3.将度矩阵D中的所有元素按照从小到大排列; Step4.选取度矩阵中相似度值较小的前c个数据对应的样本作为离群点候选集; Step5.从离群点候选集任取一个对象p,计算对象p的第k距离k-distance(p)和第k距离邻域Nk-distance(p); Step6.根据式(2)计算对象p相对于对象o的可达距离reach-dist(p,o); Step7.根据式(3)计算对象p的局部可达密度lrdk(p); Step8.根据式(4)计算对象p的局部离群因子LOFk(p); Step9.重复Step 5~ Step 8,直至计算得到离群点候选集中所有对象的局部离群因子; Step10.对离群点候选集中所有对象的局部离群因子的值由大到小排序,输出排序后前m个对象作为数据集X的离群点集合. 本文算法主要分为两个阶段,则其时间复杂度主要由两部分组成.首先,构造样本的相似度矩阵,时间复杂度为O(N2),根据计算得到的相似度矩阵对数据集进行非离群点剪枝,时间复杂度为O(N)+O(NlogN),其中,N为数据集中的样本个数;其次,计算离群点候选集中所有对象的局部离群因子,时间复杂度为O(M2),对离群点候选集中所有对象的局部离群因子排序,时间复杂度为O(MlogM),其中,M表示剪枝后的离群点候选集中样本个数.综上,本文算法的时间复杂度为O(N2)+O(N)+O(NlogN)+O(M2)+O(MlogM),即O(N2)+O(M2).通常情况下,离群点个数远远小于样本个数,因此离群点候选集中样本个数也远远小于样本个数,即M< 为了验证本文算法对于不规则形状数据集离群点检测的有效性,实验选取了两组分布复杂的人工数据集进行仿真实验,每组人工数据集中含有少量随机分布的离群点,实验数据如图2所示.第一组人工数据集有500个点以及20个离群点,共520个点;第二组人工数据集有312个点以及18个离群点,共330个点. 图2 人工数据集Fig.2 Artificial datasets 实验分别采用本文算法和LOF算法对人工数据集进行离群点检测,将离群点候选集样本个数c设置为离群点数m的1.5倍,LOF算法的近邻个数k设置为9,得到两组数据集的实验结果如图3和图4所示.图中分别用点和圆圈表示进行离群点检测后得到的离群点和原始数据. 第一组人工数据集有20个离群点,LOF算法检测出5个离群点,本文算法检测出17个离群点.第二组人工数据集有18个离群点,LOF算法检测出2个离群点,本文算法检测出16个离群点.从图3和图4中的实验结果可以看出,本文算法可以较好地完成不规则形状数据集的离群点检测.相比于LOF算法,本文算法具有较高的离群点检测精确度,可以更好地反映出数据集的原有特征. UCI数据集常用于分类、聚类等算法的有效性验证,数据中的离群点是未知的,不能直接用于离群点检测算法的验证实验.所以,在实验之前需要对数据进行处理,本文参照文献[13]的方法,删除原始数据集中某一类的数据,仅保留该类极少量的点,如表1所示,“删除类中样本数目”表示原始数据集中此类别数据的样本个数,“离群点数”表示删除此类样本的大部分数据后余下的样本个数,由于余下的这些样本偏离于其它类别,且数量较少,可视为离群点,括号内的数字表示存在两个删除类时,每个删除类中余下的离群点数.文章分别采用本文提出的算法,文献[13]提出的LCDO算法,文献[14]提出的LOAS算法和LOF算法对处理后的UCI数据集进行离群点检测,实验结果如表2所示. 图3 第一组数据集实验结果Fig.3 Experimental results of the first data set 图4 第二组数据集实验结果Fig.4 Experimental results of the second data set 表1 UCI数据集Table 1 UCI datasets 表2 四种算法在UCI数据集上的离群点检测结果对比Table 2 Comparison of outlier detection results of the four algorithms on UCI datasets 从表2实验结果看出,LOF算法对于UCI数据集的离群点检测结果较差;在Glass数据集和Yeast数据集的离群点检测实验中,本文算法、LOAS算法和LCDO算法均可有效检测出离群点;在Iris数据集和Ionosphere数据集的离群点检测实验中,本文算法取得了最好的检测结果,性能更优.因此,本文提出的算法对于复杂分布数据的离群点检测是有效的. 本文将相似度矩阵的构造方法引入到离群点检测中,提出了一种基于相似度剪枝的离群点检测算法.该算法通过基于相似度矩阵的非离群点剪枝,有效地找到与其他数据相似度较小的一部分对象作为离群点候选集,使得离群点检测对象更具针对性.然后,通过LOF算法计算离群点候选集中对象的局部离群因子,得到最终的检测结果.实验结果表明,该算法在人工数据集和真实数据集的实验均取得了较好的结果,有效地提高了离群点检测的精确度,可以更好地适应不规则形状数据集和复杂分布的多维数据集.下一步,将重点研究参数与运行结果之间的关系,确定最优的离群点候选集样本个数c与近邻个数k选择方法.3 一种相似度剪枝的离群点检测算法
3.1 相似度矩阵构造

3.2 基于相似度矩阵的非离群点剪枝策略

3.3 算法描述
3.4 算法复杂度分析
4 实验结果与分析
4.1 人工数据集仿真实验

4.2 UCI数据集仿真实验


5 结束语
