基于GoogLeNet改进模型的苹果叶病诊断系统设计*
2021-08-13宋晨勇白皓然孙伟浩马皓冉
宋晨勇,白皓然,孙伟浩,马皓冉
(青岛农业大学机电工程学院,山东青岛,266109)
0 引言
2018年,苹果的全球贸易量达到了5 000 kt,年人均消费量8.2 kg,是消费量最大的水果之一[1]。近年来,由于病原体的变种以及苹果保护措施的不足,苹果病害的种类数量逐渐增加。而传统的基于知识库的专家系统在处理复杂多变的自然数据过程中有着局限性,随着农业信息化和物联网的发展,通过叶片外观和视觉症状识别苹果疾病的病变自动诊断系统将会在规模化农业生产中得到越来越多的关注。
从20世纪80年代开始,计算机视觉技术在作物病虫害识别领域中得到了广泛研究和发展[2-7]。张静等[2]采用叶片纹理特征提取识别黄瓜斑疹病和角斑病。随着计算机视觉技术和机器学习理论的逐渐完善,科研工作者运用判别式分析方法、匹配方法和机器学习方法进行植物病害分类识别,取得了良好效果。胡小平等[3]利用BP网络预测小麦条锈病的严重程度,获得了较高的准确率。以上研究在提取病斑图像的特征参数方面,大多是以提取单变量特征参数为主,因此在识别效率方面尚待提高。
伴随着数据的爆炸增长和计算机硬件的发展,深度学习在图像识别领域取得了巨大进步,扩大了精准农业领域的计算机视觉范围。大量的学者将深度学习理论应用到农作物病害识别的研究中,取得了良好的效果[8-15]。王细萍等[8]利用深层架构卷积神经网络和时变冲量学习相结合进行多阶段特征融合,并取得了良好的效果。杨国亮等[12]的研究通过参数指数非线性(PENL)函数改进残差网络,在一定程度上提高植物病害的识别准确度。这些研究取得了较好的效果,但没有考虑模型中大量的网络参数导致模型响应时间过长的问题。因此,设计出一种能优化低延迟和高识别率之间关系的识别模型在苹果农业实际生产具有重要意义。
本文以苹果为研究对象,利用机器学习理论,围绕苹果病害诊断进行了系统性研究,从减少网络参数数量和训练收敛时间着手,提出了基于深度学习的GoogLeNet改进模型,优化低延迟和高识别率之间关系,以期提高以苹果叶锈病和斑点落叶病为例的苹果病害的识别准确率,实现苹果病害实时、便利的图像自动识别,为苹果病害防治防控提供一种可行的诊断方法。
1 样本采集与处理
本文分析了数据集的特征,并使用基于几何变换和图像操作的数据增强方法,对数据集进行了预处理。数据增强整体过程如图1所示。
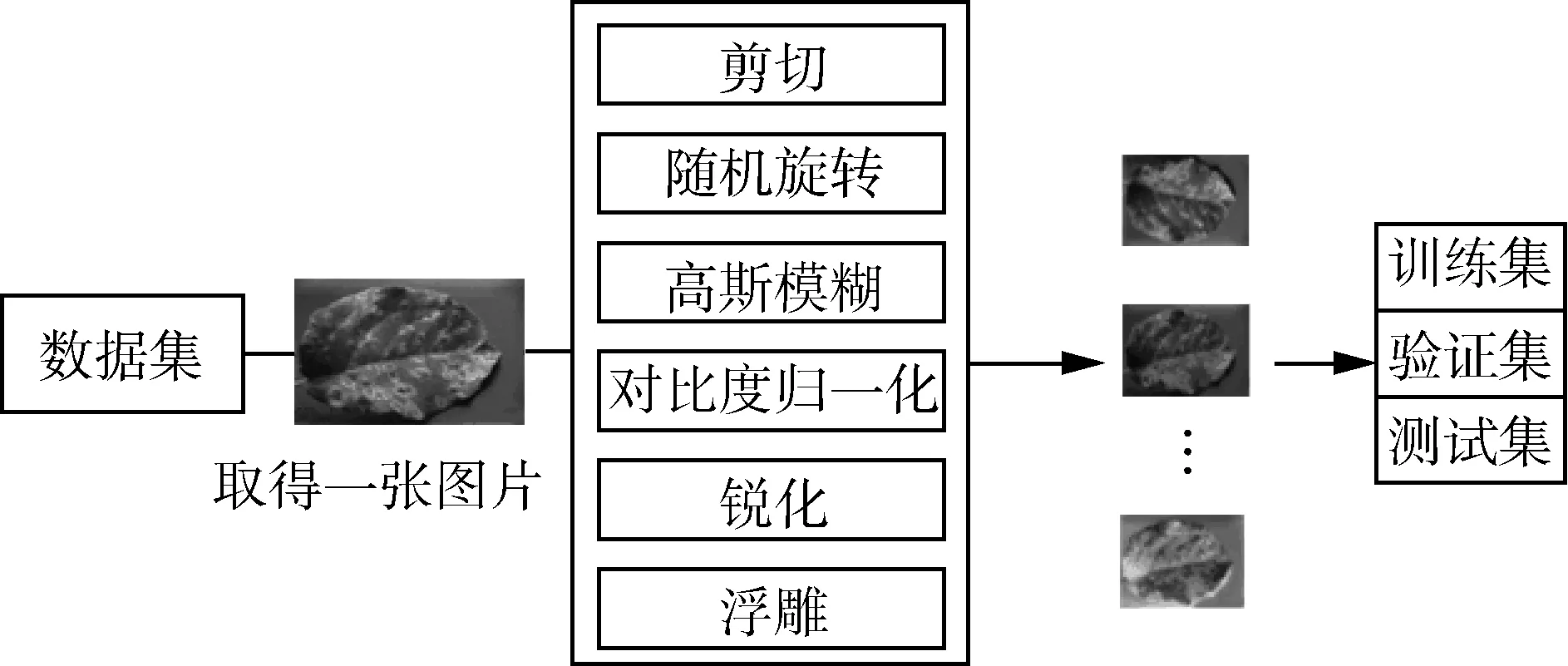
图1 数据增强整体过程Fig. 1 Data enhancement process
1.1 样本采集
通过人工拍摄,并借助百度图片、谷歌等不同网站来源共采集了100幅图像,其中包括不同时期的正常苹果叶片、苹果锈病叶片及苹果斑点落叶病叶片的图片,如图2所示。

(a) 正常苹果叶片

(b) 苹果锈病叶片

(c) 苹果斑点落叶病叶片图2 正常苹果叶片与有病状叶片图Fig. 2 Images of normal and diseased apple leaves
网络来源的所有图片都是通过Python脚本进行下载,下载图片全部经过人工筛选,并且请相关专家对筛选图像进行了多次评估,确保了样本标签的准确性。
1.2 图像处理
1.2.1 数据增强
随着训练数据集的扩展,深度卷积神经网络的性能将进一步提高[16]。为了扩大样本数量,保证模型训练对数据的需求,故对已采集图片进行数据增强处理。通过随机旋转、裁剪图像,锐化图像,随机噪声变换和模糊等变换,或改变图片对比度等方法扩展图像数据,具体方法如表1所示。苹果叶病图像数据增强情况如表2所示,增强图片具体示例如图3~图5所示。
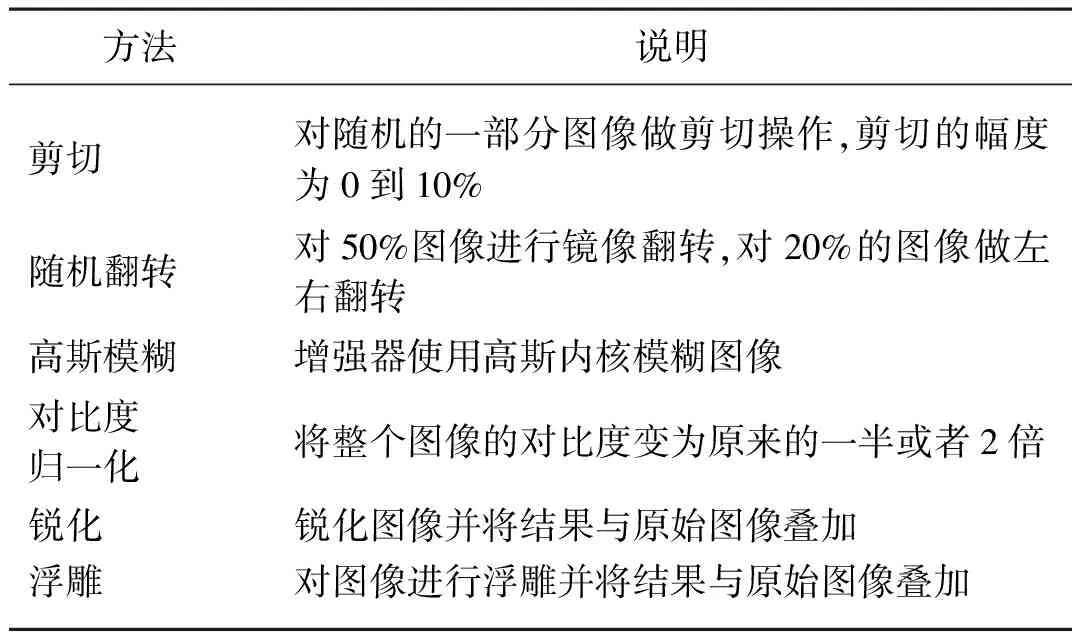
表1 图像数据增强方法说明Tab. 1 Description of image data enhancement methods

表2 苹果叶病原始图像数据和扩展后的图像数据分布情况Tab. 2 Number of apple leaf original images data andenhanced images data

(a) 原图
(b) 裁剪

(c) 旋转

(d) 锐化

(e) 模糊
(f) 噪声变换
(g) 改变对比度图3 经过不同方法处理的正常苹果叶片图像Fig. 3 Normal apple leaf image processed by different methods

(a) 原图

(b) 裁剪

(c) 旋转

(d) 锐化

(e) 模糊

(f) 噪声变换

(g) 改变对比度图4 经过不同方法处理的苹果锈病图像Fig. 4 Apple rust images processed by different methods

(a) 原图
(b) 裁剪

(c) 旋转
(d) 锐化

(e) 模糊
(f) 噪声变换
(g) 改变对比度图5 经过不同方法处理的苹果斑点落叶病图像Fig. 5 Images of apple spotted leaf disease processed by different methods
1.2.2 数据集制作
在数据增强之后共9 905张图像,其中将绝大部分数据用作GoogLeNet模型的训练和验证,少量数据用作模型测试,GoogLeNet模型和改进模型的训练集,验证集和测试集的比例约为50∶10∶1。数据集具体分配情况如表3所示。
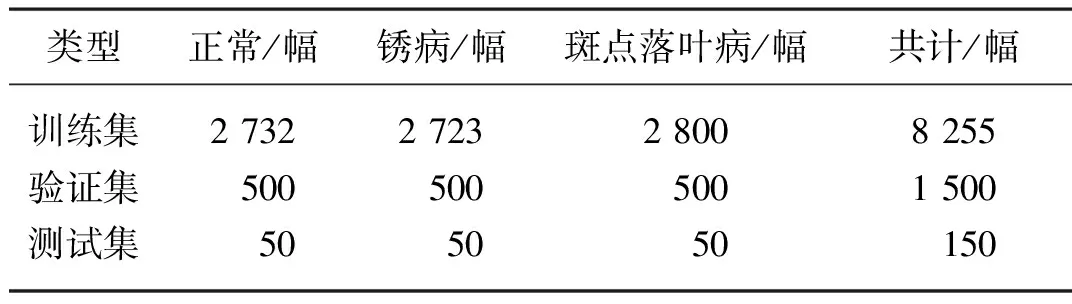
表3 GooLeNet模型的数据集分布情况Tab. 3 Data set distribution of GoogLeNet model
1.2.3 图像预处理
在划分数据集后,为了改善模型特征提取性能,必须对叶片图像进行预处理。首先对图像进行标准化操作,减少由于阳光强度变化引起的颜色变化,降低过拟合风险。并且在定位准确、图像完整的情况下根据叶片在图像中的位置直接进行标准切割,减少试验中图像因采集方式或者拍摄距离的差异所导致的误差。GoogLeNet改进模型使用299×299的标准切割图片,具体效果如图6所示。
图6 预处理后的299×299苹果叶片图
图片切割操作是由基于OpenCV框架的Python脚本自动计算,最后利用基于Tensorflow框架的Python脚本生成GoogLeNet改进模型的数据文件。
2 模型改进及测试
2.1 GoogLeNet模型介绍
GoogLeNet结构有22层,由于网络层次数量,神经元数量和训练数据的增加,GoogLeNet模型具有比以前的深度学习结构更多的特征[17]。GoogLeNet模型使用稀疏网络结构来改善过度拟合和过度占用内存的缺点,它使用金字塔模型来增加宽度,并提出“初始模块”的概念,“初始模块”的主要思想是指由一系列易获得的稠密子结构来近似和覆盖卷积网络的局部稀疏结构。GoogLeNet结构中共使用了11个初始模块,3个分类器。每个初始模块包括多个平行卷积层,并且采用最大池化层用于同时捕获不同的特征,并且将任意n×n的卷积核都分解成两个1×n,n×1的一维卷积核,如图7所示。1×1卷积核实现了卷积核跨通道的交互和信息整合,并通过卷积核通道数的降维或升维,使模型网络结构更紧凑,参数数量显著地减少[18]。
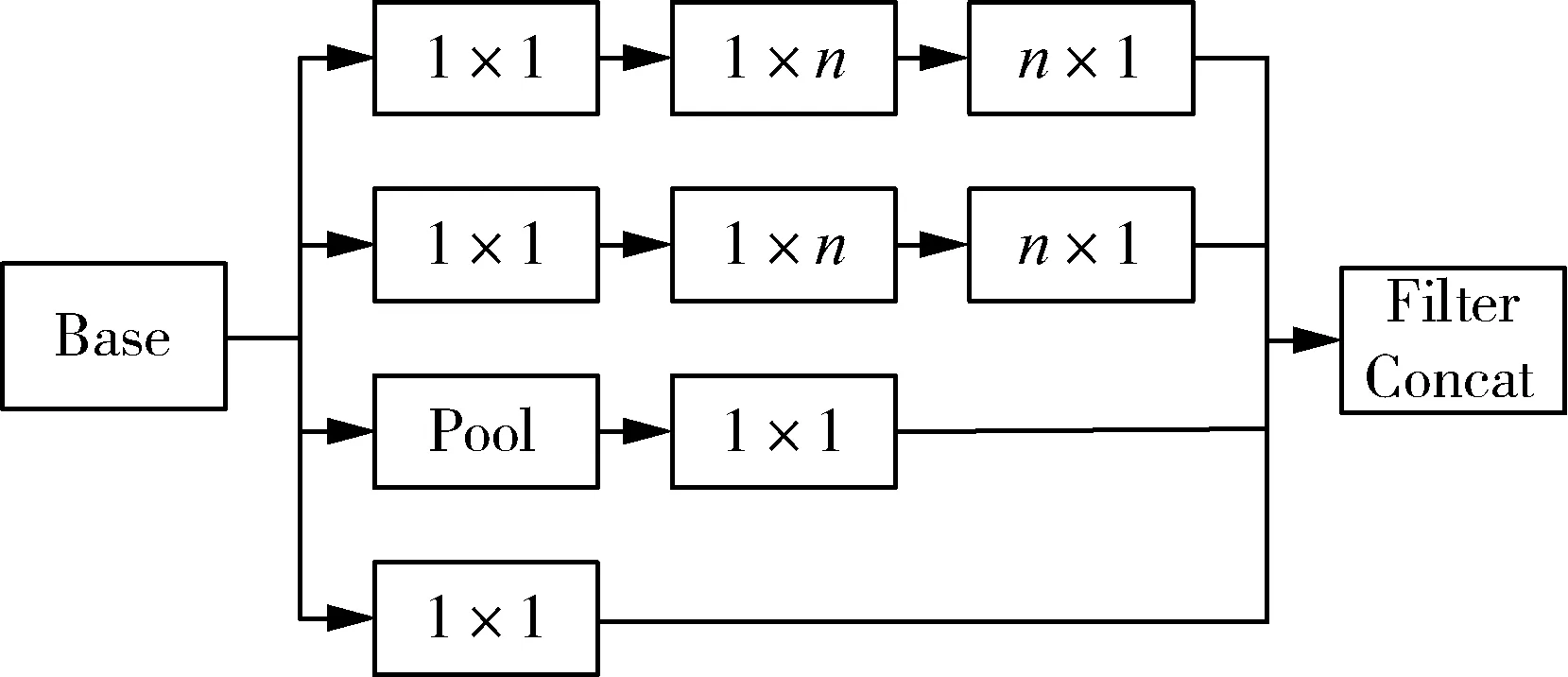
图7 1×n和n×1卷积核的Inception结构Fig. 7 Inception structure of 1×n andn×1 convolution kernels
2.2 GoogLeNet模型改进
为了使模型更适应样本数据集,通过综合衡量模型性能和参数数量寻找初始模块和分类器数量的最佳组合。GoogLeNet改进模型使用了1个分类器和4个初始模块,模型结构如图8所示。
模型采用随机梯度下降(Stochastic gradient descent,SGD)算法进行优化。模型的超参数设置如表4所示。其中 GoogLeNet改进模型的初始学习率都比原模型缩小10倍,分别为0.001,GoogLeNet改进模型批次容量为GoogLeNet模型的2倍。
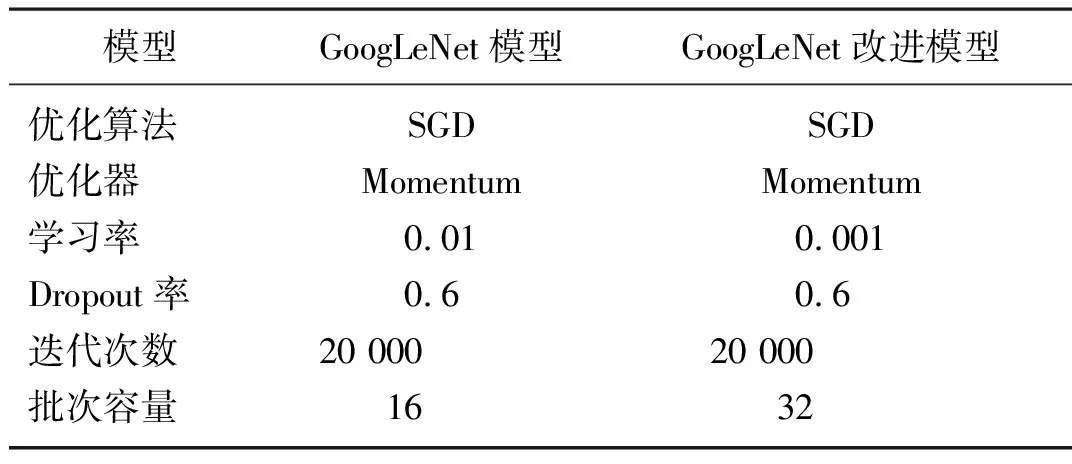
表4 GoogLeNet、GoogLeNet改进模型的超参数设置Tab. 4 Hyper-parameter settings ofGoogLeNet, improved GoogLeNet
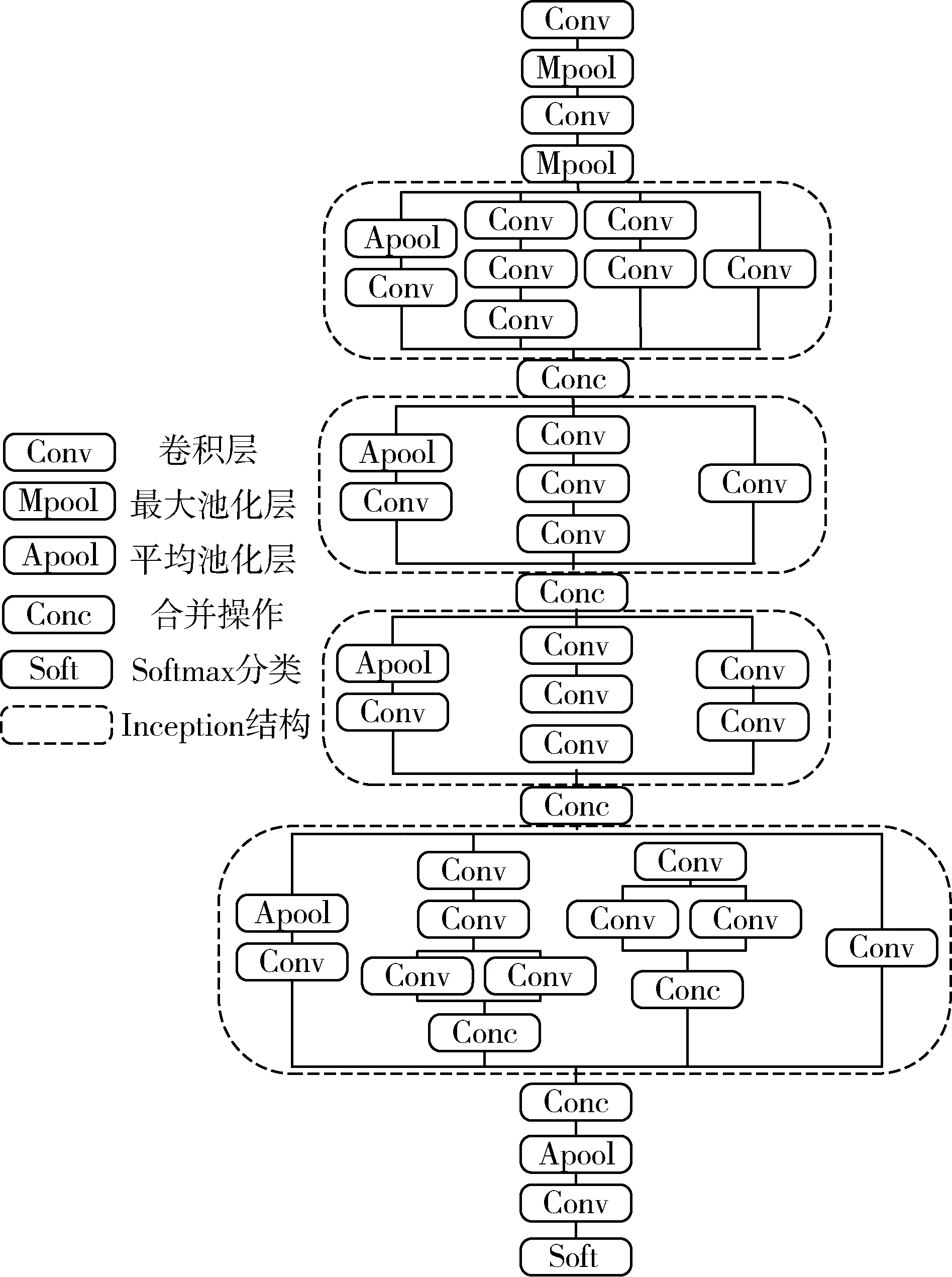
图8 GoogLeNet改进模型结构Fig. 8 GoogLeNet improved model structure
2.3 模型测试与分析
在计算机上通过Tensorflow框架,Pycharm开发环境和Python语言训练和测试模型。Tensorflow框架是Google用于数据流图的数值计算开源软件库,其已经成功实现了深度学习算法,实现了异构分布式系统上大规模高效率的学习。Tensorflow为模型培训,测试和调整参数提供了完整的工具包,部署模型可以在中央处理单元(CPU)和图形处理单元(GPU)上运行。NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销,将Tensorflow与cuDNN库集成可以大幅提高CNN模型训练速度。
GoogLeNet原模型的初始学习率为0.01,优化器动量为0.9,损失函数使用对数损失函数。为了使模型测试结果更有说服力,本研究分别使用准确率,精准率,召回率,F1值衡量模型的性能。准确率,即提取出的正确样本数与总样本数之比,经过第20 000次迭代后,GoogLeNet原模型验证集准确率为98.1%,损失值为0.77,如图9所示。GoogLeNet改进模型的验证集准确率为98.3%,损失值为0.04,如图10所示。
精准率是正确的正例样本数与预测为正例的样本数的比值,召回率是正确的正例样本数与样本中的正例样本数的比值,F1值为正确率和召回率的调和平均值。GoogLeNet模型与改进模型的精准率,召回率,F1值测试结果如表5所示。
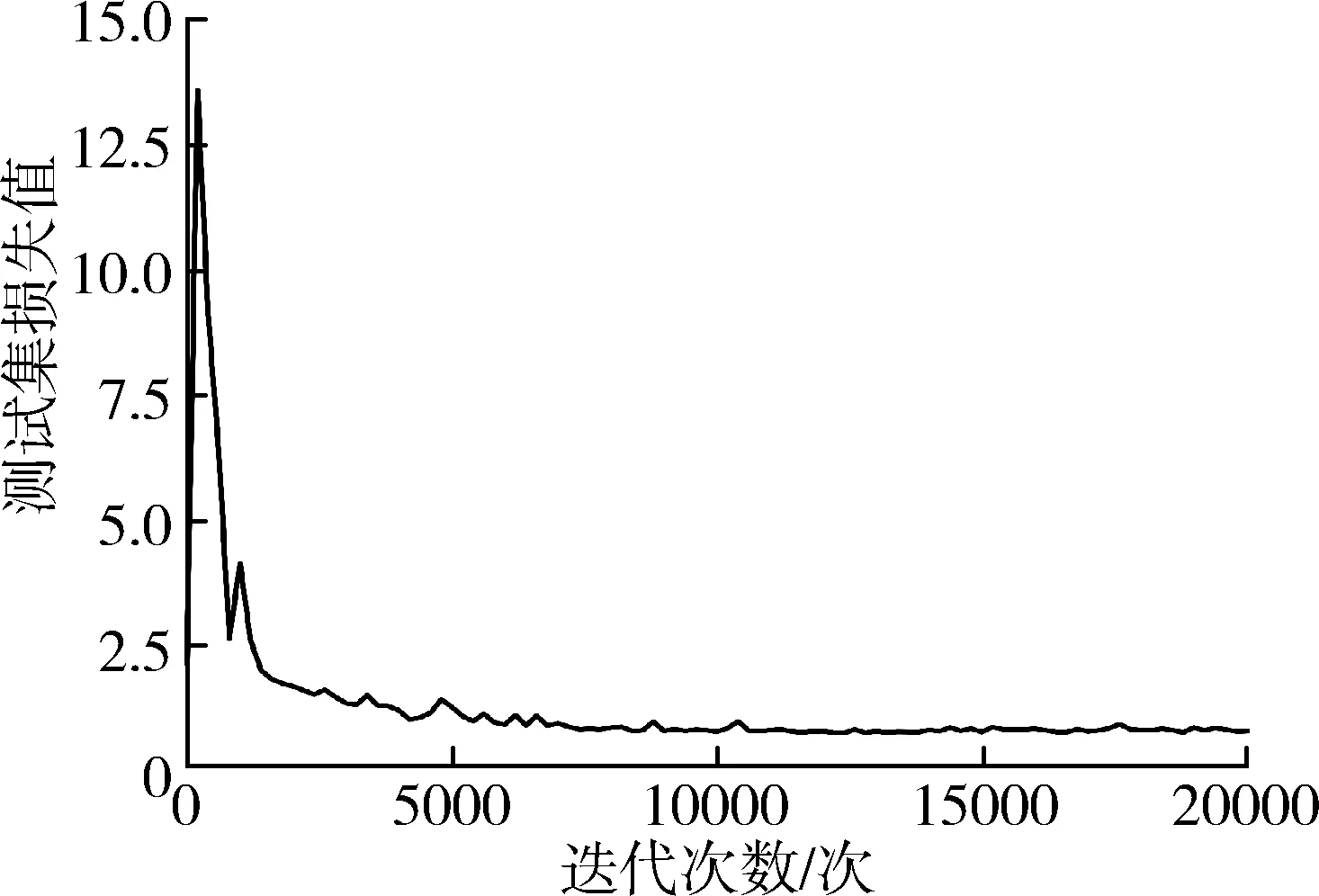
(a) 损失值曲线图
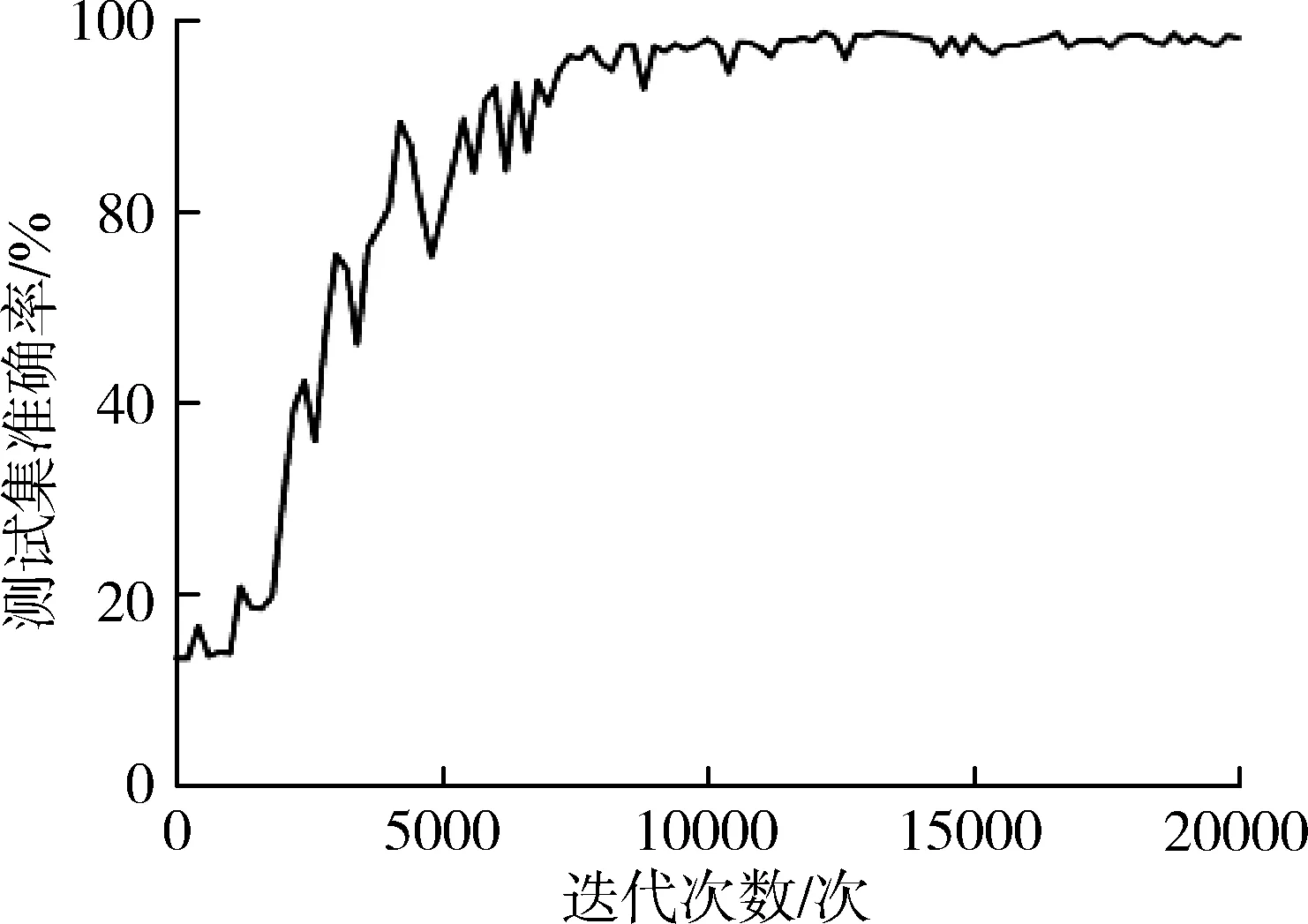
(b) 准确率曲线图图9 GoogLeNet模型的测试集损失值和准确率Fig. 9 Validation set loss and accuracy ofthe GoogLeNet model
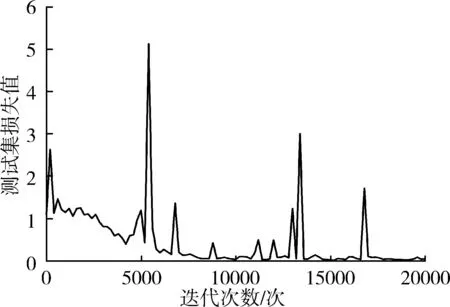
(a) 损失值曲线图
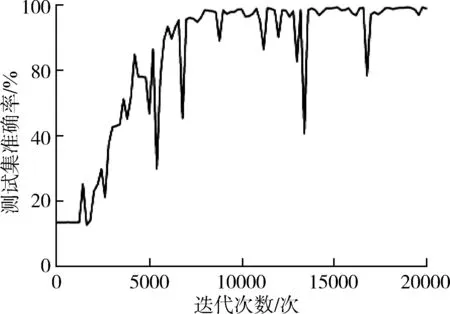
(b) 准确率曲线图图10 GoogLeNet改进模型的测试集损失值和准确率Fig. 10 Validation set loss and accuracy ofGoogLeNet improved model
GoogLeNet模型与改进模型的平均准确率只相差0.2%。在精准率方面,GoogLeNet改进模型比原模型提高了2.1%,召回率上,GoogLeNet改进模型比原模型提高了1.2%,在锈病上的召回率提高了4.0%,在F1值方面,GoogLeNet改进模型比原模型提高了1.7%,这表明改进模型有效地提升了模型的性能。

表5 GoogLeNet模型和GoogLeNet改进模型对比结果Tab. 5 Comparison results of GoogLeNet model andGoogLeNet improved model
在运行时间上,相同运行环境下,两个模型的运行时间差异却很明显,GoogLeNet模型的训练时间需要大约4.5 h,GoogLeNet改进模型的训练时间大幅减少,只需要大约2.5 h,减低了44.44%,并且GoogLeNet改进模型的模型参数仅为GoogLeNet模型的17.5%,表明模型运行时间的大幅降低得益于模型参数数量的减少,具体如表6所示。改进的GoogLeNet模型在保持模型识别性能的前提下降低了网络参数数量,提高了模型的训练和识别效率。

表6 GoogLeNet原模型以及改进模型的参数数量及分布Tab. 6 Number and distribution of parameters of theoriginal GoogLeNet model and the improved model
3 系统设计与实现
病害识别系统主要由用户登录模块、账号注册模块、图像识别模块、识别记录日志模块四个模块组成。病害识别系统设计具体流程如图11所示。
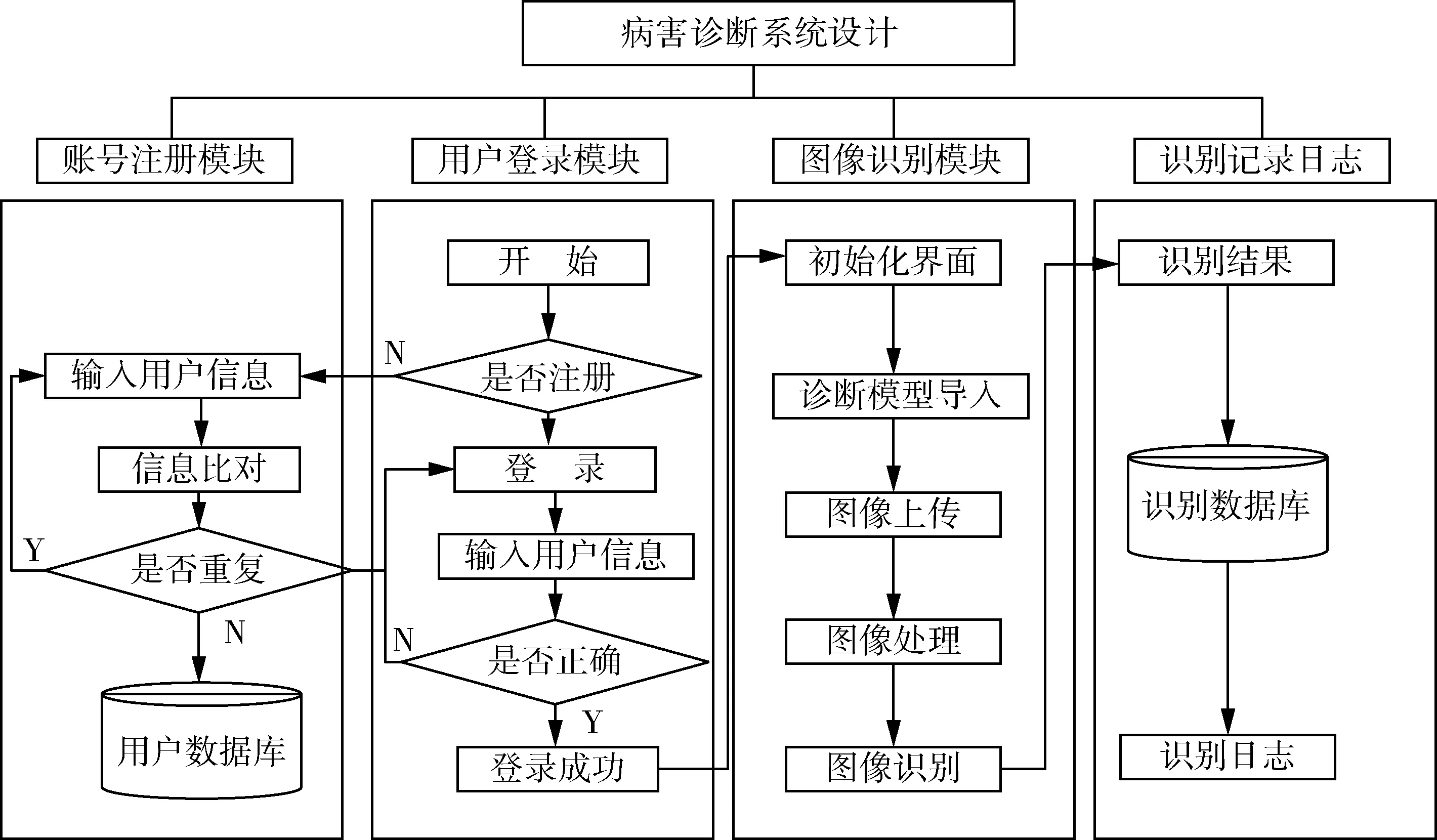
图11 病害识别系统设计图Fig. 11 Design diagram of disease identification system
3.1 系统技术与开发环境
病害识别系统技术路线由卷积神经网络和Torndao框架两部分构成,在模型构建上采用Tensorflow框架构建病害识别网络,Python语言进行样本标识和处理,使用sqlite3和peewee数据库存储数据。在网络视图上基于python、html、javascript和CSS(Cascading Style Sheets)构建网页服务端,使用Torndao框架进行系统前后端交互,系统技术路线如图12所示。
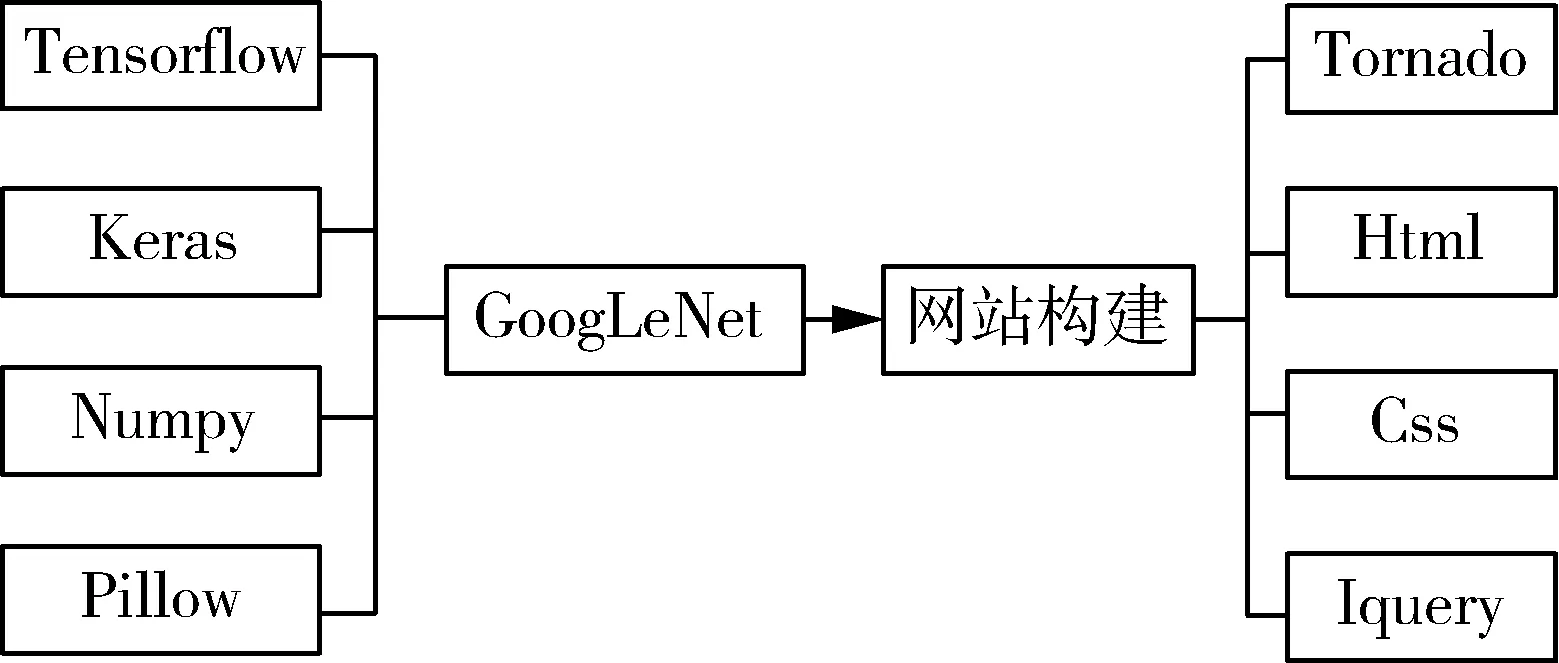
图12 苹果病害图像在线识别系统技术路线图Fig. 12 Apple disease image online recognitionsystem technical route
3.2 病害识别系统的具体实现
病害识别系统的用户登录模块使用render的方法引入编写的登录静态网页login.html,并将登录用户名字“loginUsername”和登录密码“loginPassword”分配给当前访问用户的用户名“Username”和密码“Password”变量,并通过json进行数据转换,默认返回响应码“200”则表示“登录成功”,如果默认返回响应码“500”则表示“用户名或密码错误”,并以同样的形式设置了账号注册模块。
在图像识别模块中,主要包括模型导入、图片上传及处理、图像识别、识别结果呈现等四个部分,具体实现流程为注册登录完成后界面会显示提取照片,手动输入需要辨别的苹果病害图像,网页中会显示图片中植物的病状,并且给出叶片患病的概率。在模型导入中将训练好的GoogLeNet模型参数文件使用load_weights函数导入,并使用compile函数编译参数文件。在图片上传部分中,网页前端使用form表单的形式进行上传,并在网站后端调用Image库读取图片数据,利用Image.new函数创建一幅给定模式和尺寸的图片,以适应图片识别模型的要求,判断获取上传图片的尺寸与创建图片是否一致,若不一致则使用Image.resize函数对图像进行填充或裁剪,并且将修改图片格式统一转换为RGB格式,最后利用paste函数将转换好的图片粘贴匹配到创建的图像上。最后得到的图片识别结果将会存放在本地文件夹件中,并在网页前端罗列出病害的可能性。
在识别记录日志模块中,网页将会记录每一次的病害识别结果,通过对识别结果的简单统计以帮助果农了解果树生长状况,减小经济损失。
3.3 系统测试
为了测试系统的稳定性和准确性,故从待测图片中随机挑选图片进行测试,测试界面及结果如图13所示,测试结果显示叶片患有苹果斑点落叶病的概率为80.1%。
通过对测试集150张图片进行评估,叶片测试的平均准确率达到了96.0%,详细测试结果如表7所示,图14是部分叶片测试过程的识别记录。经过评估,系统表现出了良好的稳定性,并且实现了对苹果叶病的准确识别。
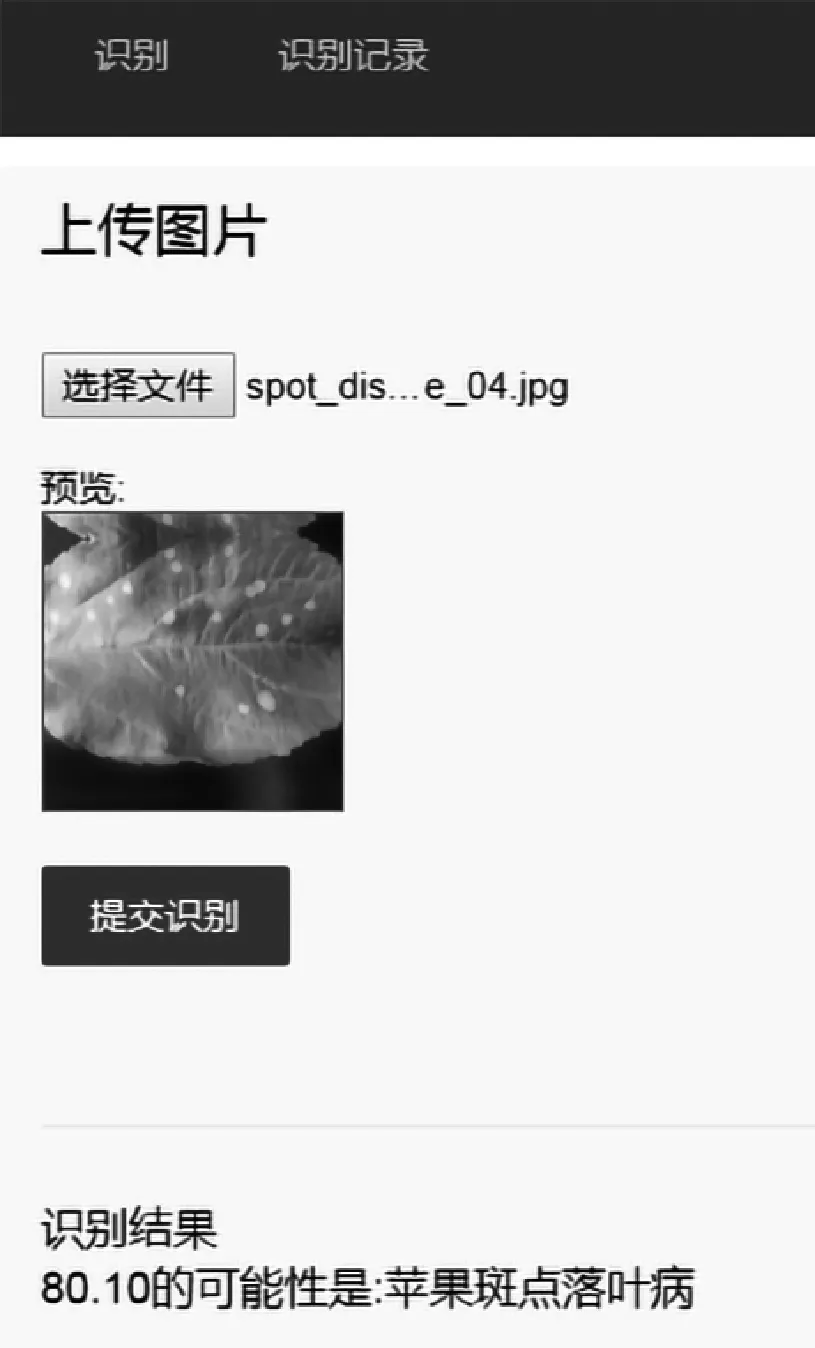
图13 预测分析界面Fig. 13 Analysis interface

表7 测试结果Tab. 7 Test results

图14 识别记录模块视图Fig. 14 View of the recognition record module
4 结论
本文对基于深度学习的卷积神经网络改进模型用于苹果叶病识别进行了研究并得到了以下的结论与成果。
1) 在识别苹果正常叶片、锈病叶和斑点落叶病叶片的过程中,本研究在GoogLeNet模型的Inception结构基础上建立了改进模型,并使用四种指标(准确率,精准率,召回率,F1值)综合衡量模型的性能。实验结果表明,GoogLeNet改进模型的精准率,召回率,F1值比原模型分别提高了2.1%,1.2%,1.7%,并且GoogLeNet改进模型的识别精准率达到98.3%,具有良好的稳定性和泛化能力,在苹果病害识别中具有明显优势。
2) 新模型减少了inception模块上的数量,在模型前段增加了卷积层和池化层的数量,极大的减少模型的参数数量,减小了模型过拟合的风险。实验结果表明GoogLeNet改进模型的训练时间比原模型减低了44.44%,并且GoogLeNet改进模型的模型参数仅为原模型的17.5%,模型文件占用的设备内存明显减少,提升了模型的响应速度。
3) 基于Tornado框架建立了苹果病害识别系统,建立了用户登录模块、账号注册模块、图像识别模块、识别记录日志模块四个模块,并对系统进行测试,结果表明叶片测试的平均准确率达到了96.0%,系统表现出良好的稳定性,并实现了对苹果锈病,斑点落叶病的准确识别。
