面向分布式环境的分层数据采集技术研究
2021-08-12项倩红林华明
项倩红,陈 烘,林华明
(1.杭州市保密技术测评中心,浙江 杭州 310026; 2.浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
数据采集[1]是大数据处理过程不可或缺的环节。在分布式环境下,待处理的数据通常来自各种应用源,如流数据、Rest服务端点、应用程序输出、文件系统等。传统的数据采集方式[2]主要存在以下不足:一是数据格式多元且采集接口多,采集管道不易扩展;二是模型间的耦合度高,需消耗较高的开发与维护成本;三是一旦数据出现异常就难以及时排查与定位,尤其是针对多源异构数据的采集,系统持久层接口通常暴露于外端,容易造成访问不可控的现象[3]。因此,在高生产率的大数据时代,如何有效采集数据,为流计算引擎提供稳定的数据流具有重要研究意义[4]。
迄今为止,国内外研究者已经提出了许多数据采集方法。文献[5]立足于情景感知技术,提出了一种基于情景感知的远程用户体验数据采集方法,但该方法仅适用于采集与情景耦合度较高的数据。文献[6]构建了高效的分布式大数据采集系统,运用基于标签书节点权重的数据提取方法,以提高数据采集的有效性与鲁棒性。文献[7]提出一种基于MapReduce模型的城市大数据采集方案,在大规模动态环境下可有效地降低信息损失量和执行时间。文献[8]提出一种Sink轨迹固定传感器网络的高数据采集机制,在兼顾数据采集效率与能耗的前提下,运用基于二维染色体编码的遗传算法实现数据采集。文献[9]设计了一套基于Kafka的分布式大数据采集系统,实现了分布式环境下大数据的采集。文献[10]总结了多源提取模式、协议转换模式、多目的模式等常见的数据采集与流模式。
本文将Flume作为基础的数据采集架构。它具有高可用特点,可将分布于不同机器、不同节点的数据通过简单地配置收集于系统之中。但Flume是基于用户指定阈值的静态负载均衡方式,主要依赖人为监控节点负载状况而无法自动根据实际负载进行调控,容易导致部分节点负载过高而其余节点仍处于空闲状态的情况。同时,在分布式环境下,各节点间的高发异常将会导致进程中断而无法继续采集数据,难以实现自动恢复。文献[11]提出一种基于Flume的MySQL数据库数据采集系统,采用星型拓扑结构实现数据传输的高效性。文献[12]设计并实现了基于Storm的新型数据流处理系统,通过修改执行器来收集并判断每个工作节点是否负载。文献[13]综合考虑负载均衡度与任务完成时间,提出基于禁忌搜索的负载均衡方法,可有效提升了负载均衡的性能。文献[14]提出一种基于改进混合蛙跳算法的云工作流负载均衡调度优化方法,可有效地均衡节点间的负载,但该方法更适用于具有较强关联性任务的调度。
针对上述问题,本文采用基于Flume的流式数据分层采集模型,并提出分层采集进程监控方法和基于分组的双层哈希负载均衡方法,主要为了解决以下三个方面的问题。
1)数据集成问题:本文针对分布式环境下的多源异构数据,基于Flume搭建数据采集模型,统一了数据采集接口,并且易于扩展。
2)高耦合度问题:通过对模型分层,实现各层之间相互独立,解耦后的模型结合分层采集进程监控方法,保证了数据传输的稳定性与可靠性,可有效降低运营与维护成本。
3)负载均衡问题:提出基于分组的双层哈希负载均衡方法,以弥补Flume默认负载均衡机制的不足,从而提高系统的负载均衡能力。
1 分层数据采集模型
1.1 分层数据采集
基于Flume架构的分层数据采集模型,兼备了实时流式传输模式、多源提取模式、多目标模式[10]等诸多优点,从而实现数据的多源提取、多目标系统存储,并为流计算引擎提供实时计算流,其模型架构如图1。
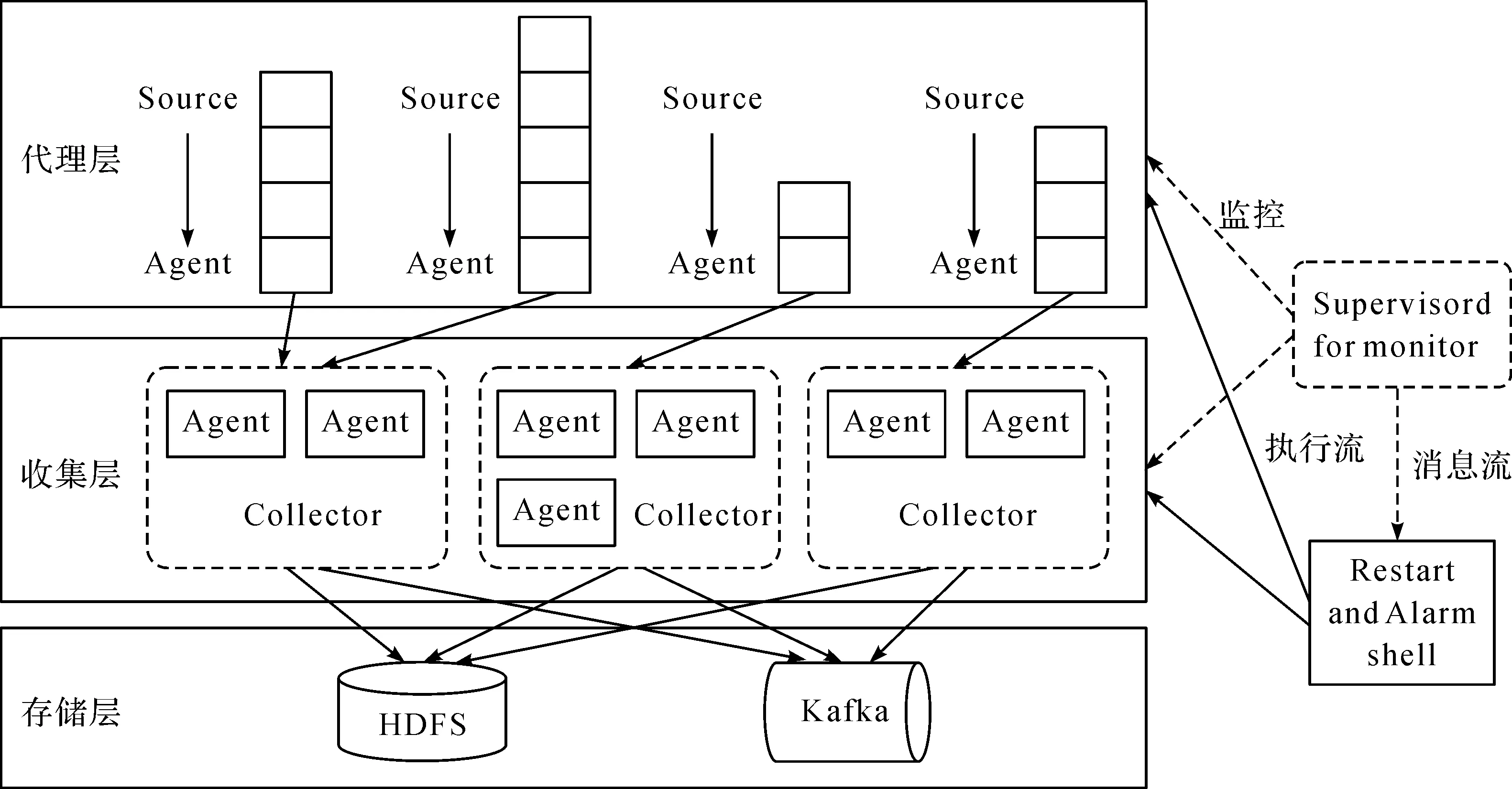
图1 基于Flume的分层数据采集模型架构Figure 1 Layered data collection model architecture based on Flume
上述模型以Agent作为最小的运行单元,自上而下分别为代理层、收集层与存储层。各层级的含义与作用如表1。

表1 模型结构说明
代理Agent的内部数据流如图2所示,Source、Sink与Channel三大组件组成一个代理。其内部数据流组成见表2。

图2 Agent内部数据流Figure 2 Agent internal data flow
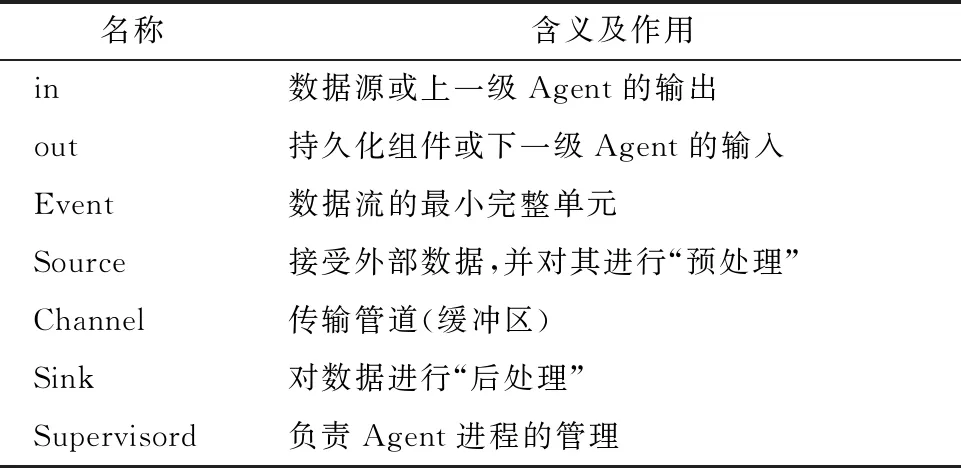
表2 Agent内部数据流组成说明
上述所提的分层采集模型架构主要有以下优势:一是每个代理能最大化地利用本地存储器以最小化延迟;二是所有节点均具有原子性,相互间不依赖,能实现无共享架构;三是可运用负载均衡方式向Agent提供无差别服务;四是针对代理层Agent而言,持久层集群的升级是透明的,Collector会将数据缓存至本地,当完成升级时再将数据注入至持久层;五是三层均可通过添加机器节点来实现线性扩容。具体来说,代理层的每个代理可独立一层,本身支持线性扩展,可构建稳定的分布式系统。
1.2 分层管道模型设计
收集层的Collector由上一代理层中的多个Agent汇聚而成,其中的代理通过负载均衡提供所需的服务。但由于收集层的Agent数量远少于代理层,为保证数据传输的可靠性不仅要设计高效的负载均衡方法,还需设计可靠的数据传输管道[15]。
相应的,流数据分层采集模型也划分为代理层、收集层和存储层。代理层主要负责各数据源的数据采集,以SpillableMemoryChannel[16]作为管道,兼备了MemoryChannel与FileChannel两者的优势,解决了该层代理需随数据源增加而不断扩展的问题。收集层主要借助FileChannel实现数据可靠传输,并汇集上一层采集的数据。其分层管道结构如图3。

图3 分层管道结构图Figure 3 Hierarchical pipeline structure diagram
其中,第一层负责数据源数据的采集,以Spillable Memory Channel作为管道以确保具备较高的可靠性与稳定性。收集层主要负责集成代理层所采集的数据,借助File Channel来传输数据,并通过负载均衡的方式来提供无差别服务。
2 分层采集进程监控方法
Flume框架通过点到点传输以确保高可用性[17]。但由于Flume内置缺乏高效的进程级高可用机制,主要存在以下问题:一是虽然Collector提供的是无差别的服务,但仍存在某一类型的代理都不可用的情况;二是Agent进程因异常无法恢复而终止数据采集[18]。
本文提出了分层采集进程监控方法,主要通过以下两个方面来确保进程级高可用[19]。
1)Supervisord[20](进程管理工具)实时监控Agent进程情况,一旦代理进程中断,Supervisord将立即进行重启,以解决Agent进程的自动恢复问题。
2)本文提出分层采集进程监控算法,借助Supervisord对代理进行监控,一旦发现某类型的Collector有近一半的Agent中断时立即启动报警机制。
Supervisord可对进程的状态进行监控,当程序出现异常时即进行自动重启。利用Supervisord的事件特性对所有代理进行监控,并通过Listener对进程状态进行监听。而分层采集进程监控算法正是运用Supervisord的事件特性进行预警,记录运行的异常,其算法的伪代码如算法1,见表3。
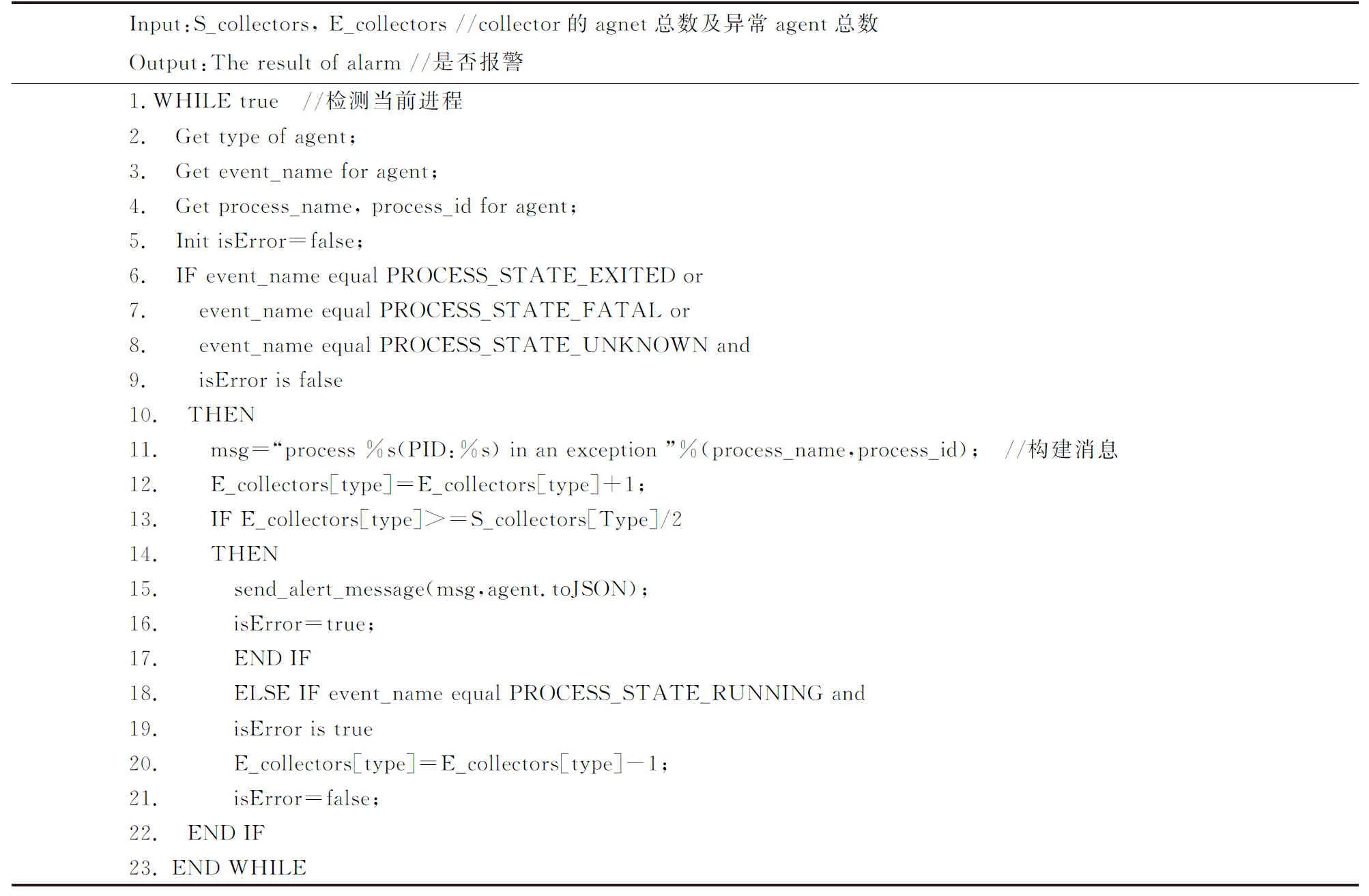
表3 算法1,分层采集进程监控算法
3 基于分组的双层哈希负载均衡方法
负载均衡[21]在理论研究与实际应用中均具有重要意义,在流数据采集时需重点考虑写入请求不均衡而导致系统并发量降低或者部分节点出现超负载等问题[22]。由于Flume是基于用户指定阈值的负载均衡方式,不能准确代表各节点的实际负载情况,会导致部分节点负载过高排队等候,而其余节点处于空闲状态造成资源浪费。除此之外,当用户阈值设置过高,批量提交写请求时,若部分节点的请求未能得到及时响应,则易导致整体响应超时;当阈值设置过低,又会造成部分节点性能有所降低[23]。
因此,本文提出一种集成静态与自适应负载均衡优势于一体的双层哈希负载均衡方法。在第一层,实现代理层Agent到Collector的映射;在第二层,实现Collector到Agent的映射。不同层之间通过不同的哈希算法来解决以下4个关键问题:
1)不变性问题:确保同一个请求在不同的时间均可落入相同的Collector;
2)分散性问题:将请求尽量分散到不同的Collector上,以避免部分Collector出现异常而无法提供正常服务;
3)可靠性问题:解决因内存溢出而导致数据丢失的问题,以确保数据进行可靠传输;
4)隔离性问题:将不同机型、配置、类型的机器进行相互隔离。
本文采用加权一致哈希算法,其结构如图4。

图4 代理层Agent到Collector的哈希图Figure 4 Hash graph from Agent layer Agent to Collection
Collector A-Collector D均是负载均衡的,并且不同组代理的配置有所不同,其承受负载的能力也均不相同。若Collector的Agent数量多、配置高,便相应增加权重,使其能响应更多的请求;相应的,当Agent数量少、配置低时,应相应降低权重,减少请求分配,如算法2所示,见表4。

表4 算法2,加权一致哈希算法
针对Collector到Agent的映射过程,当请求过多时,易出现节点过载超时现象;当连接过少时,将出现节点空闲现象。因此,本文主要解决自适应和大批量两个问题,即系统能自动地均衡节点间的负载,解决了负载不均衡的问题,系统间的处理效能也随之提高[23]。
针对上述问题,本文采用最少活动数方法,如算法3(表5)。这是一种自适应负载均衡方法,主要以活动数作为判断是否过载的标志。

表5 算法3,最少活动数算法
4 性能测试
为验证基于Flume架构的分层哈希负载均衡算法的有效性,将运用基于分组的双层哈希负载均衡方法和Flume默认的负载均衡方法进行对比实验(以下简称L方法与D方法),以数据迁移率、吞吐量、节点平均耗时作为评价指标。
4.1 实验环境设置
为保证对比实验的公平性,本文所设置实验的配置环境均如表6,我们将6个存储节点分为三组。组间设置600 000个数据项,且各数据项均分配相同的权重。

表6 各节点配置
4.2 实验结果分析
4.2.1 数据迁移率
将Ave(节点平均数)、Max(节点最大数据项)、Min(节点最小数据项)、Change(节点数目改变后需迁移数据项)四项指标作为对比数据迁移率的评价指标。经过多次重复实验,实验结果如表7。

表7 测试结果
实验结果表明:运用D方法时,Max与Min值分别为100 700和99 093,数据项目之差为1 607,占1.6%,小于2%,表明D方法能较好地将节点均匀地分布至各存储节点上。但其数据项迁移数为552 034,迁移率高达90%以上。运用L方法,Max与Min值分别为113 201和90 203,数据项目之差为22 998,迁移率降低至2%。
从图5可以看出,在经常发生节点故障或扩缩容的分布式环境中,相比于D方法而言,L方法能保持较低的迁移率。表明在分布式环境下,运用基于分组的双层哈希负载均衡方法,能构造稳定的数据采集方式,为流计算引擎提供实时、稳定的数据流。

图5 数据迁移率结果图Figure 5 Data migration rate result grap
4.2.2 吞吐量
为了验证L方法与D方法在节点过载时的性能,持续地对节点发送数据使得部分节点过载,实验结果如图6。

图6 吞吐量测试结果图Figure 6 Throughput test result graph
实验结果表明,L方法与D方法在前几分钟负载均较轻时,吞吐性能接近。但当节点逐步过载运行约4 min时,运用两种方法系统的吞吐量均呈现出先有所下降后趋于平稳;L方法的吞吐量最多比D方法高32%。即相较于Flume默认的负载均衡方法,运用基于分组的双层哈希负载均衡方法系统的有效性与稳定性更好。
4.2.3 节点平均耗时
此外,为了对比运用L方法与D方法对节点耗时的影响,我们设置不同的阈值进行对比实验。实验结果如图7。

图7 节点平均耗时测试结果图Figure 7 Time consuming test result graph
从图7可以看出,随着任务数的增加,L方法与D方法的耗时均逐步增长;但运用D方法所需的耗时远小于L方法,表明运用基于分组的双层哈希负载均衡方法能较好地均衡节点间的负载,从而缩短了各节点的耗时。此外,当L方法的阈值分别设置为30%、50%、70%、100%观察节点的耗时,阈值为70%时耗时最短,当阈值设置过高或过低均会延长耗时。这表明当用户阈值设置过高,批量提交写请求时,部分节点的请求未能得到及时响应,导致整体响应超时;当阈值设置过低,又会造成部分节点性能有所降低。
5 结 语
针对分布式环境下,传统数据采集方法的模型耦合度高、采集接口不统一、稳定性与可靠性难以保障等问题,本文对Flume数据采集模型进行研究。首先,使用基于Flume的分层数据采集模型,实现模型间分层解耦,并统一了数据采集接口;其次,提出了分层采集进程监控方法,以弥补Flume内置缺乏高效的进程级高可用机制的不足;最后,在此基础上提出了一种基于分组的双层哈希负载均衡方法,来动态地调节各节点间的负载。实验结果表明,从数据迁移率、吞吐量、节点平均耗时等指标均可看出,基于分组的双层哈希负载均衡方法能较好地均衡节点间的负载,提高了数据采集的有效性和可靠性,可为流计算引擎提供稳定的数据流。
