大规模城市环境下视觉位置识别技术的研究
2021-08-12王红君郝金龙岳有军
王红君 郝金龙 赵 辉,2 岳有军
1(天津市复杂系统控制理论及应用重点实验室 天津 300384)2(天津农学院 天津 300384)
0 引 言
近年来,位置识别在机器视觉和机器人领域中得到了极大的关注。2014年以来,国际机器人与自动化会议(ICRA)和国际计算机视觉与模式识别会议(CVPR)中多次设置视觉位置识别相关研讨会[1]。
位置识别可广泛应用于定位与地图构建(SLAM)、自动驾驶、机器人导航、增强现实和图片地理定位等技术。比如,在SALM技术中,位置识别可以应用于回环检测环节。回环检测是移动机器人抑制累计误差的关键,通过识别对同一位置的重新访问,机器人可以进行姿态和全局地图的优化,提高系统的精度和稳定性。
在大规模城市环境下,往往存在着光照变化(图1)、摄像机拍摄角度变化(图2)、移动物体(图3)、建筑物和地表外观改变(图4)等。然而传统图像特征如SIFT、SURF、BRIEF、FAST和ORB已经无法应对这种环境条件的剧烈变化。

图1 光照变化

图2 摄像机拍摄角度变化

图3 移动物体(人车等)

图4 建筑物和地表外观改变
近些年随着卷积神经网络的发展,各种CNN如AlexNet[2]、VGG[3]、GoogLeNet[4]和ResNet[5]等越来越多地被用来进行图像特征提取。这些方法被广泛应用于物体检测追踪、场景识别、人体动作识别和语义识别等领域。同样CNN也被应用到视觉位置识别中,2016年CVPR上Arandjelovic等[6]提出了一种可进行端到端训练的视觉位置识别网络NetVLAD。NetVLAD尝试解决了大规模视觉地点识别的问题,实验表明,其在Pittsburgh和Tokyo 24/7数据集上,效果明显优于传统的图像表示算法,并且超越了当时最先进的图像描述方法VLAD。
从FaceNet[7]与SENet[8]中得到启发提出一种基于SENet改进的ResNet[5]的视觉位置识别方法PlaceNet。通过引入注意力机制,使得ResNet拥有更高的精度。同时使用自建大规模数据集进行训练使得网络的鲁棒性更强。
1 相关理论
1.1 深度残差网络
深度残差网络(Deep Residual Network,ResNet)由He等[5]提出,并在ImageNet比赛分类任务上获得第一名。因为它结构简单但识别能力强,图像检测、分割和识别等领域的很多方法都是在ResNet50或者ResNet101的基础上完成的。ResNet 由若干个基础块或瓶颈模型组成,其结构如图5所示。不同数量的基础块或瓶颈模型组成了不同深度的ResNet。本文使用101层的ResNet来对图像进行特征提取。

图5 基础块与瓶颈模型的结构图
1.2 SENet
胡杰团队(WMW)在CVPR 2017上提出了压缩激励网络(Squeeze-and-Excitation Networks,SENet),利用SENet,一举取得最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%[8]。

图6 SE block结构图
1.3 FaceNet
2015年Schroff等[7]提出了FaceNet,其使用深度卷积网络进行人脸识别,实现了人脸识别系统的端到端学习。先将人脸图像通过卷积神经网络直接映射到特征空间,再通过三元组损失(Triplet Loss),使得相同身份的所有面部之间的欧氏平方距离变小,而来自不同身份的面部图像之间的欧氏平方距离变大。这样就可以通过人脸图像映射后的特征向量间的欧氏平方距离来判断是不是同一个人。图7为FaceNet的基本结构。

图7 FaceNet的基本结构
2 基于SENet改进的ResNet
本文使用ResNet的瓶颈模型来搭建PlaceNet。SENet的核心操作是压缩与激励。为了将SENet嵌入ResNet中,使用全局平均池化来进行压缩操作,使用两次全连接来进行激励操作。通过第一次全连接将通道数降到输入的1/16,然后使用ReLU激活函数激活后进行第二次全连接将输出恢复到原来的通道数,最后通过Sigmoid激活函数激活后经过Scale操作加权到输入的每一个通道上。改进后的瓶颈模型结构如图8所示。

图8 改进后的瓶颈模型结构
3 PlaceNet
与FaceNet类似,本文使用改进后的ResNet101进行视觉位置识别,实现了视觉位置识别的端到端学习。先通过改进后的ResNet101将图片映射到特征空间。再通过三元组损失使得不同地点特征向量间的标准欧氏距离变大,相同地点特征向量间的欧氏平方距离变小。这样就可以用图片特征向量间的欧氏平方距离来判断图片的相似度,进而再判断两幅图片的拍摄地是否相同。
PlaceNet的基本结构如图9所示,其中每一个Block的基本结构相同,只是其瓶颈结构重复次数和输出通道数不同。Block1到Block4的瓶颈结构重复次数分别是3、4、23和3,而输出通道数分别为256、512、1 024和2 048。
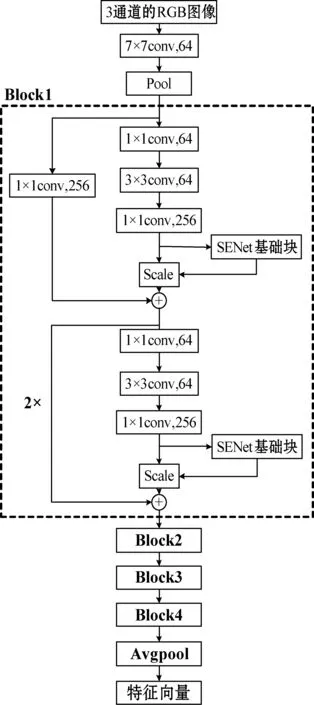
图9 PlaceNet的基本结构
整个视觉位置识别系统的结构如图10所示。通过PlaceNet对所有的数据库图片进行映射得到它们的特征向量,然后建立KD树。同样得到待查询图片的特征向量之后使用最邻近匹配获得最相似的匹配项,如果它们的特征向量间距小于阈值即匹配成功,反之则不成功。

图10 整个系统的结构
4 PlaceNet的训练
4.1 数据集
有关视觉位置识别的数据集并不多,其中一部分包含可训练图片较少,还有一部分私有不可获取。所以,本文选择自建数据集。从谷歌街景中使用Python爬虫在世界范围爬取了纽约、东京、吉隆坡三个城市100万幅街景图片。将同一地点按偏航角(Yaw)从0°到360°每隔5°爬取72组街景图片。东京数据集中的部分图片如图11所示。

图11 东京某地同Yaw角拍摄的3幅不同时间的图片
在数据集中每幅图片都包含GPS坐标信息,把GPS坐标距离小于等于10 m的图片看作同一地点拍摄的图片,大于10 m的为不同地方拍摄的图片,这样就可以选出可用于训练的图片三元组。选取东京街景数据集中拍摄偏航角为0°、90°、180°和270°四组图片共计62 450幅图片当作训练集。
4.2 损失函数
在PlaceNet的训练中选取损失函数的关键是要体现出图片之间的差异,用来监督训练,这种关联变量因数据集的特征而定,在自建的东京街景数据集上使用GPS坐标比较合适。使用Triplet损失函数[7]进行PlaceNet的训练,Triplet损失函数为:
(1)
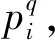
4.3 训练过程
在PlaceNet的训练中有一些重要参数需要根据数据集进行针对设置。将训练迭代次数设置为30万。采用指数衰减学习率,将初始学习率设置为2.0E-4,在迭代次数为13 000次时开始衰减。将输出特征向量维度设置为256。训练时的损失与TOP3精度随迭代次数变化的曲线如图12和图13所示。

图12 损失与随迭代次数变化曲线

图13 TOP3精度与随迭代次数变化曲线
5 实验与分析
5.1 实验平台与测试集
验证实验在一台图像处理服务器上进行,该服务器配备了64 GB的运行内存、48个2.20 GHz 的英特尔至强CPU、2张12 GB显存的GeForce GTX 1080Ti 显卡。在该实验平台上搭建深度学习环境Anaconda3以及深度学习框架TensorFlow进行实验。
测试集选取公共数据集SL(St Lucia Multiple Time of Day)[9]和自建数据集KL(Kuala Lumpur)。SL数据集采集于澳大利亚昆士兰州圣卢西亚郊区的一条道路,其查询数据库含有7 045幅车载摄像机拍摄的图片,待匹配图片集有6 709幅车载摄像机拍摄的图片。KL数据集为在谷歌街景爬取马来西亚吉隆坡的街景照片,其查询数据库含有9 574幅街景图片,待匹配图片集含有1 064幅街景图片。
5.2 可行性验证实验
如果前N个检索到的数据库图像中的至少一个与查询图像拍摄地的距离小于等于10 m,则认为查询图像被准确召回。然后针对不同的N值绘制准确召回的比例曲线。在KL和SL测试集上进行测试,得到两个曲线如图14和图15所示。

图14 本文方法在KL上准确召回率随N的变化曲线

图15 本文方法在SL上准确召回率随N的变化曲线
可以看出在KL和SL测试集上相同的候选项个数N下,嵌入SENet的PlaceNet比未嵌入SENet的PlaceNet有着更高的准确召回率。这说明了通过嵌入SENet把注意力机制引入的PlaceNet,提高了PlaceNet在视觉位置识别任务上的精度。
5.3 对比实验
同样在KL和SL测试集上进行测试,测试结果如图16和图17所示。

图16 不同方法在KL上准确召回率随N的变化曲线

图17 不同方法在SL上准确召回率随N的变化曲线
从图16可以看出在KL测试集上使用TokyoTM、pitts30k训练集的NetVLAD的准确召回率十分相近,在N=1到N=11时低于使用KL训练集的NetVLAD的召回精度。而嵌入SENet的PlaceNet准确召回率一直最高,在N=1时更是高出0.36。从图17可以看出在SL测试集上使用TokyoTM、pitts30k训练集的NetVLAD的准确召回率,前者比后者多约0.05,同时都低于使用KL训练集的NetVLAD的召回精度。而嵌入SENet的PlaceNet召回精度一直最高,且比使用TokyoTM、pitts30k训练集的NetVLAD的召回精度高出0.4。
从结果上来看在不同测试集上PlaceNet都比NetVLAD拥有更高的召回精度。在自建数据集KL上训练得到的NetVLAD模型的召回精度比NetVLAD在原有数据集训练得到模型的召回精度高,说明本文数据集更适用于视觉地点识别任务的训练。同时PlaceNet匹配一幅图片平均耗时1.9 ms而NetVLAD则需要300 ms,表明PlaceNet匹配效率更高。
6 结 语
在大规模城市环境下,为提高视觉位置识别的精度,本文提出一种新的视觉位置识别网络PlaceNet。实验表明,大规模城市环境下PlaceNet在面对光照变化、摄像机拍摄角度变化、存在移动物体、建筑物和地表外观改变时,仍然可以准确地进行视觉位置识别;在同样的大规模城市环境下,PlaceNet比NetVLAD拥有更高的精度和匹配效率。
